1.了解Orcale数据库
- Orcale数据库的优点
- 性能非常的好
- 安全性高,满足ISO标准
- 对分布式的支持非常好
2.orcale数据库的安装
-
安装前的准备
- 保证有足够的磁盘空间
- 保证有足够的内存空间(关闭软件:360,防火墙)
- 两个压缩文件一起解压缩到一个目录下面
-
解锁scott用户
- 首先使用管理员登录(system)
- 输入登录密码 system/orcl;或者conn sys as sysdba 超级管理员
- 解锁scott用户 alert user scott account unlock;
3.Oracle数据库服务
-
打开服务器的窗口
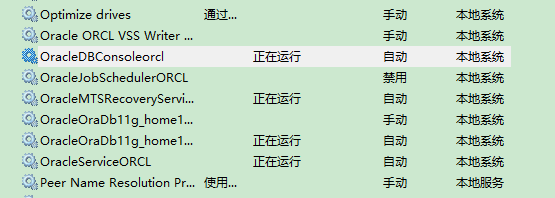 fuwu.png
fuwu.png- 打开服务窗口->控制面板->服务->Oracle
- OracleOraDB11g_home1TNSListener:监听器服务,如果启动了监听器服务之后,用户就可以使用客户端连接Oracle数据库
- OracleServiceORCL:Oracle核心服务,如果需要访问Oracle数据,就必须要启动该服务.
4.连接Oracle数据库
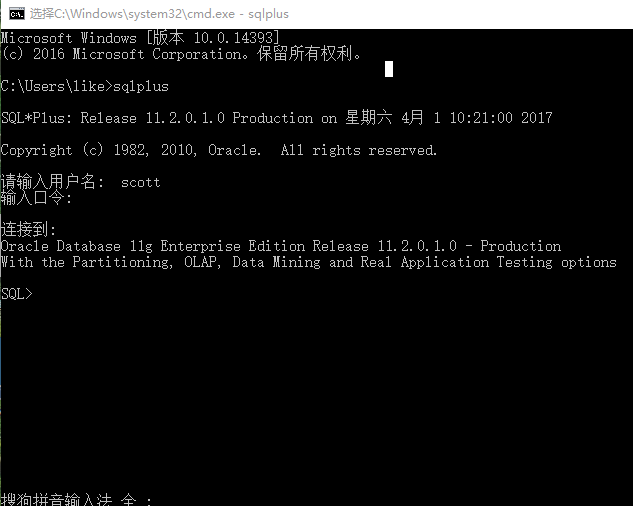
- 使用SQLPlus工具连接Oracle数据库
- SQLPlus是Oracle数据库自带的一个命令行的管理工具
- 输入命令和密码后,如果看到SQL就表示登录成功了
- 使用SQL-Developer工具
工具启动之后:

- 创建一个新的连接
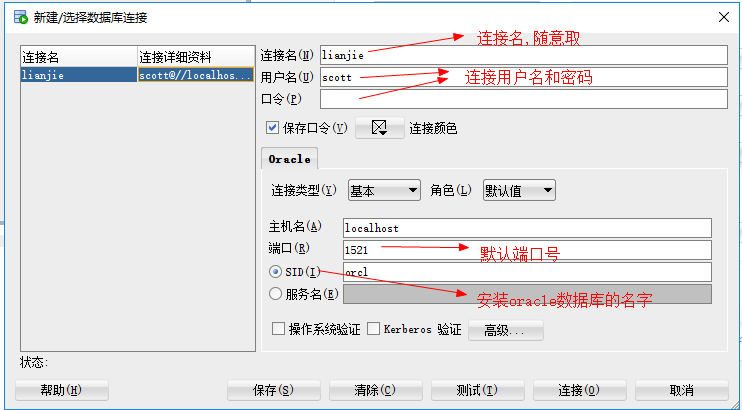
注意:如果没有启动监听器服务OracleOraDB11g_home1TNSListener的话,就会连接失败
5.使用JDBC访问数据库
- 导入数据库的驱动包
- 注册驱动(在JDBC4.0之后可以自动加载驱动了,可以省略这一步)
- 获取数据库连接对象
- 获取到执行SQL语句的对象
Statement对象 - 执行查询
- 处理结果集
- 释放资源(
Connection;Statement;ResultSet)
-
代码:
package com.itheima.jdbc; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public class Demo1 { public static void main(String[] args) { // jdk1.7自动资源回收 // 放在小括号中的流对象和连接对象对象可以自动回收 try ( // 获取数据库的连接对象 Connection conn = DriverManager.getConnection( "jdbc:oracle:thin:@localhost:1521:orcl", "scott", "tiger"); // 创建Statement对象 Statement stmt = conn.createStatement(); // 执行查询 ResultSet rs = stmt.executeQuery("select * from emp"); ) { // 遍历结果集 if (rs != null) { while (rs.next()) { System.out.println("员工编号" + rs.getInt("empno") + "员工姓名:" + rs.getString("ename")); } } } catch (SQLException e) { e.printStackTrace(); } } } -
结果
员工编号7369员工姓名:SMITH 员工编号7499员工姓名:ALLEN 员工编号7521员工姓名:WARD 员工编号7566员工姓名:JONES 员工编号7654员工姓名:MARTIN 员工编号7698员工姓名:BLAKE 员工编号7782员工姓名:CLARK 员工编号7788员工姓名:SCOTT 员工编号7839员工姓名:KING 员工编号7844员工姓名:TURNER 员工编号7876员工姓名:ADAMS 员工编号7900员工姓名:JAMES 员工编号7902员工姓名:FORD 员工编号7934员工姓名:MILLER
5.sqlplus的常用命令
- 格式化命令
| 命令 | 说明 |
|---|---|
| set line n | 设置每一行的字符数,默认是每一行显示80个字符 |
| set pagesize n | 设置每一页的记录数,默认是显示14行数据,包括了(标题,分隔线,空行) |
| set feedback off/on | 隐藏查询状态信息/不隐藏;就是是否隐藏数据库给回的反馈信息. |
| col 列名 for 格式 | 设置某一列的格式,如果该列的数据类型是数值型,可以设置数字的格式,例如col sal for $999,999,999,如果该列数据是字符串,那么就可以用来设置字符串的宽度;例如col dname for a50; |
- 如果在sqlPlus中设置命令,该命令只在当前的窗口中有效,如果要设置全局属性,就可以在glogin.sql文件中进行设置

- 其他命令
| 命令 | 说明 |
|---|---|
| show all | 查询系统中的所有参数 |
| show xxx | 查询系统中的指定的参数 |
| conn 用户名/密码 | 切换用户 |
| -- /**/ | 单行注释和多行注释 |
| / | 用来执行缓冲区里面最后一条sql语句 |
| ed | 将缓冲区中最后一条sql语句读取到一个文本文件中,用户可以对sql语句进行编辑,编辑并保存后sqlplus会把编辑后的sql语句重新放回到缓冲区中 |
| spool 文件路径[apoend] | 假脱机命令:他的作用是把spool命令到spool off之前的命令保存到一个文件中;如果加上了append,就不会覆盖原来的文件,如果不加上就会覆盖原来的文件 |
| spool off | 他的作用是把spool命令到spool off之前的命令保存到一个文件中 |
| host cls | 清屏 |
| exit | 退出sqlPlus |
6.DDL语句 (数据库定义语言)
6.1 创建表
-
语法格式:
create table 表名 ( 列名 数据类型 [primary key], 列名 数据类型 [not null], .... constraint 约束名 约束类型(列名), constraint 约束名 约束类型(列名) ); 说明:Oracle数据库的约束类型 unique;foreign key;check;primary key;not null; 注意:在Oracle数据库中是没有auto_increment关键字的如果要实现主键列的自增长, Oracle提供了一个序列的对象-
创建表示例
-- 创建tb_user表 create table tb_user ( id number(4) primary key, name varchar2(20) not null, gender nchar(1) default '男', deptno number(4), constraint uni_user_name unique(name), constraint chk_user_gender check(gender in ('男','女')), constraint fk_user_dept foreign key(deptno) references dept(deptno)
);
-
- Oracle的数据类型
| 数据类型 | 说明 |
|---|---|
| Number(p,s) | 数值型(包括了整数和小数)参数p:数值的长度;参数s:数值的小数位数; 例如number(5,2);Number(5,-2) 表示的是7位整数9999900 Number(5) 9999表示的是整数 |
| varcahr2(n) | 可变长度的字节型,按照字节进行计算, 最大长度是4000字节,例如varchar2(4) 例如创智播客有8个字节 |
| nvarchar2(n) | 可变长度的字符型,按照字符进行计算,最大长度是2000个字符,一个中文2个字符 |
| date | 日期型 |
| timestamp | 时间类型 |
| char(n) | 固定长度的字符型 char(1)表示的是一个字节 |
| nchar(n) | 固定长度的字符型,按照字符进行计算;nchar(1)表示的是一个字符 |
| CLOB | 大文本数据类型;按照字节进行计算,最大可以存储4GB的字节 |
| NCLOB | 大文本数据类型,按照字符进行计算,最大可以存储2GB的字符 |
| BLOB | 二进制的数据类型 |
- 复制表
- 语法格式:
create table 表名
as
select 列名 form 表名[where 条件]
- 语法格式:
- 代码:
-- 创建一个emp表的备份表(复制表的结构和数据)
create table emp_bak
as
select * from emp;
-- 复制表的结构
create table emp_bak2
as
select * from emp where 1=2;
-
修改表
添加列
-
语法:alter table 表名 add(列名,数据类型 [not null]...)
alter table tb_user add(sal number(7,2)); 修改列的类型
-
alter table 表名 modify(列名 数据类型[not null])
alter table tb_user modify(sal number(10,2)); 删除列
-
语法:alter table 表名(列名);
alter table tb_user drop(sal);
修改列的名字
-
-语法 alter tbale 表名 rename column 列名 to 新列名
alter table tb_user rename column gender to sex;
- 删除表
- 语法格式: drop table 表名[purge]
- 说明:如果没有指定purge参数,那么删除的表就会保存到回收站中
drop table emp_bak2; 把表放到回收站里面
drop table emp_bak purge; 永久性的删除表
7.DML(数据操作语言)
-
添加数据
- 语法格式:insert into 表名(列名...) values (值...)
insert into tb_user values(1,'狗娃','男',10); - 注意:在Oracle中,一个insert语句只能够插入一条数据.
- 语法格式:insert into 表名(列名...) values (值...)
-
复制数据
- 语法结构:insert into 表名 select 列名 form 表名(注意没有as)
insert into emp_bak select * from emp; - 注意:复制数据的时候,两张表的字段数量和类型必须要相同
- 语法结构:insert into 表名 select 列名 form 表名(注意没有as)
-
修改数据
-
语法结构:update 表名 set 列1=值1;列2=值2....where 条件
update emp_bak set ename='狗哥' where empno=7902;
-
-
删除数据
语法格式:delete from 表名 where 条件;
删除表的所有数据:truncate table 表名
delete与truncate的区别:
delete命令:是先查询,然后在删除;truncate命令是直接把表销毁了直接截断,然后重新创建了一个新的表.有外键的情况下,delete删除不了,truncate是可以直接删除的.
trancate命令比delete的执行效率要高
8.DQL(数据库查询语言)
-
多表查询
- 多表查询就是同时对两个表或者是两个以上的表进行查询.
- 注意事项:
1).执行多表查询的时候,一个表的数据会和另外一个表的数据进行一个组合,会产生新的数据,这种现象叫做笛卡尔积.select * from emp e,dept d
2).笛卡尔积会产生很多的垃圾数据.
3)如果需要消除笛卡尔积只需要添加一个连接条件就可以了:一个表的外键列=另外一个表的主键列;select * from emp e,dept d where e.deptno = d.deptno;
-
多表查询分类
- 一般分为内连接查询和外连接查询
- 内连接:也称之为等值连接,执行多表查询的时候,只有满足条件的数据才会被查询出来,这个条件也被称之为等值查询.
- 外链接:外连接一般是分为左外连接和右外连接
1)左外连接:左边的表是主表,无论条件是否满足,主表的数据都会被查询出来.
语法结构:select 列名 ..from 表1 left join 表2 on 表1.列名=表2.列名
常用的写法:select * from emp e left join dept d on e.deptno = d.deptno;
Orcale特有的写法:select 列名 from 表1,表2 where 表1.列名=表2.列名(+)
注意:没有+号的表就是主表
2)右外连接:右表的表是主表,无论条件是否满足,主表的数据都会被查询出来.
常用的写法:select * from emp e right join dept d on e.deptno = d.deptno;
Oracle特有的写法:select * from emp e,dept d where e.deptno(+) = d.deptno;
-
子查询
子查询:在一个查询中嵌套另外一个查询.
select * from emp where sal > (select avg(sal) from emp);-
如何判断select语句中子查询的位置?
按照子查询返回的结果进行判断:1)单行单列的结果:可以作为一个where条件来使用:就是子查询结果为一个结果, 单行单列常见的情况是在查询聚合函数中 -- 查询工资大于10部门最高工资的员工信息 select max(sal) from emp where deptno=30;--2850 select * from emp where sal > (select max(sal) from emp where deptno=30); 注意:子查询一定要放在圆括号里面. 2)返回一个单行多列的结果集:可以作为where条件 -- 查询职位和部门编号与scott用户的职位和部门编号相同的员工信息 -- 查询SCOTT用户的职位和部门编号 select job,deptno from emp where ename='SCOTT'; select * from emp where (job,deptno)=(select job,deptno from emp where ename='SCOTT'); 3)多行单列:可以作为一个where条件 --查询所在地是NEW YORK的员工信息;子查询结果为多行单列 select deptno from dept where loc='NEW YORK'; select * from dept where deptno in (select deptno from dept where loc='NEW YORK'); 4)多行多列:可以放在from的后面,作为一个临时表 --查询所有员工的姓名、职位、工资、部门平均工资。 select avg(sal) from emp group by deptno -- 查询所有员工的姓名,职位,工资,部门的平均工资 select ename,job,sal,a.avgSal from (select avg(sal) avgSal from emp where deptno = emp.deptno) a,emp 5)问题:子查询是否可以放在select的后面呢?是可以的,但是很少使用 --查询所有员工的姓名、职位、工资、部门平均工资。 select ename,job,sal,(select avg(sal) from emp e1 where e1.deptno=e2.deptno) from emp e2
-
分组查询
语法结构:select 分组字段或者是聚合函数 from 表名 where 条件 group by 分组字段 having 分组条件.
-
where条件与having条件的区别:
1).where条件在分组前就可以确定
2)having条件是分组后才可以确定的条件.--需求:查询每一个部门工资小于2000的员工人数;查询前就知道结果了 select deptno,count(*) from emp where sal<2000 group by deptno --需求:查询每一个部门工资小于2000的员工人数,但是人数必须要大于1个人:只有查询后才知道结果 select deptno,count(*) from emp where sal<2000 group by deptno having count(*)>1 select语句 select; from; gorup by; order by; having; where
-
执行的顺序:from > where > group by > having > select >order by
//注意:由于select比having后执行,所以having处的count(*)不可以使用别名,但是order by可以使用别名 select deptno,count(*) as con from emp where sal<2000 group by deptno having count(*)>1 order by con desc;
9.总结
- 数据库的安装
- 数据库的服务
- 数据库的连接
- DDL;DML;DQL