KNN模型项目实战
1.定义问题
这个项目通过分析批发销售数据集(Wholesale customers data)来判断销售商品来源于哪个渠道。
- FRESH:新鲜商品年度支出
- MILK::牛奶商品年度支出
- GROCERY:杂货商品年度支出
- FROZEN:冷冻品年度支出
- DETERGENTS_PAPER: 清洁剂和纸制品的年度支出(百万美元)(连续)
- DELICATESSEN: 熟食产品年度支出(百万美元)
- CHANNEL: 销售渠道,horeca(酒店/餐厅/咖啡厅)或Retail(零售渠道8) ;horeca取1,Retail取2
8)REGION:销售地区,Lison, Oporto or Other;Lison取1,Oporto取2,Other取3
- 导入数据
本数据从UCI机器学习仓库下载(http://archive.ics.uci.edu/ml/datasets/Wholesale+customers#)
import pandas as pd
from sklearn import model_selection
import numpy as np
from sklearn import neighbors
import matplotlib.pyplot as plt
import numpy as np
from sklearn import neighbors
from sklearn import metrics
wholesale=pd.read_csv(r’C:\Desktop\python_work\Wholesale
customers data.csv’,sep=’,’,encoding=‘utf8’)
print(wholesale.head())
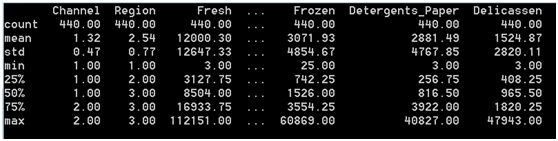
describe = wholesale.describe()
print(describe.round(2))

#将数据集拆分为训练集和测试集
predictors = wholesale.columns[1:]
x_train,x_test,y_train,y_test = model_selection.train_test_split(
wholesale[predictors],wholesale.Channel,test_size = 0.25,random_state = 1234)
#寻找合理的近邻个数k
import numpy as np
from sklearn import neighbors
import matplotlib.pyplot as plt
K =np.arange(1,np.ceil(np.log2(wholesale.shape[0])))
accuracy = []
for k_01 in K:
k = int(k_01)
cv_result = model_selection.cross_val_score(neighbors.KNeighborsClassifier(n_neighbors=k, weights = ‘distance’), x_train, y_train, cv = 10 , scoring=‘accuracy’)
accuracy.append(cv_result.mean())
arg_max = np.array(accuracy).argmax()
plt.rcParams[‘font.sans-serif’] = [‘Microsoft YaHei’]
plt.rcParams[‘axes.unicode_minus’] = False
plt.plot(K, accuracy)
plt.scatter(K, accuracy)
plt.text(K[arg_max],accuracy[arg_max], ‘最佳k值为%s’ %int(K[arg_max]))
plt.show()
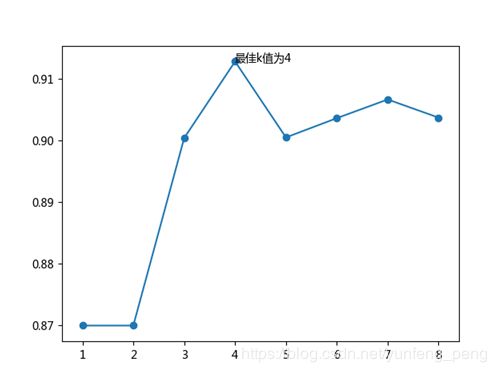
从图中可以看出最佳k值为4。
3.理解数据
#重新构建模型,并将最佳的近邻个数设置为4
import numpy as np
from sklearn import neighbors
knn_class = neighbors.KNeighborsClassifier(n_neighbors = 4,weights = ‘distance’)
knn_class.fit(x_train, y_train)
predict = knn_class.predict(x_test)
#构建混淆矩阵
cm = pd.crosstab(predict,y_test)
print(cm)

从混淆矩阵图中主对角线上来看,绝大多数的样本都被正确分类,混淆矩阵图中,每一行代表真实的样本类别,每一列代表预测的样本类别,以第一列为例,实际来自渠道1的样本有72个,预测来自渠道1的样本有62个,说明渠道1类别的覆盖率为62/72=0.8611
#模型整体的预测准确率
print(metrics.scorer.accuracy_score(y_test,predict))
#分类模型的评估报告
print(metrics.classification_report(y_test,predict))

如上图所示,前两行代表因变量y中的各个类别值, 最后三行表示微平均、宏平均和加权平均。第一列precision表示模型的预测精度,计算公式为“预测正确的类别个数/该类别预测的所有个数”;第二列recall表示模型的预测覆盖率,计算公式为“预测正确的类别个数/该类别实际的所有个数”;第三列fl_score是对precision和recall的加权结果;第四列为类别实际的样本个数。