Java爬虫框架(二)--模块设计
一、 模块
1. Scheduler
Scheduler负责启动爬虫,停止爬虫,监控爬虫的状态。
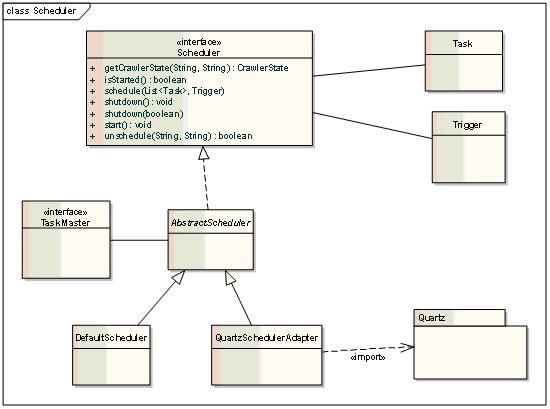
Scheduler在调度爬虫时,借助于Quartz,设置爬虫在某个时刻启动。同一个名字的爬虫是stateful的。
Task:初始化任务。
Trigger: 触发器,描述何时触发爬虫。
开放Scheduler远程API,可以通过爬虫配置管理平台管理和监控爬虫。
2. Task Master

TaskMaster:管理Task的执行过程,提交Task给WorkerThreadPool执行。
TaskController:独立线程,控制何时停止TaskMaster,DelayController和它自己
ExecutionState:描述TaskMaster当前状态
TaskQueue:存放未爬取的所有Task。可以是基于内存的,也可以是持久化的。不同的实现。
DelayTaskQueue:有些网站,如果连续访问,会禁止爬取,遇到这种情况,我们会暂时停止对该网页的爬取,我们需要一个DelayTaskQueue存放被延迟的Task。
DelayController:独立线程,不停的检测DelayTaskQueue中的Task是否过了限制期,过了限制期,移入到TaskQueue中等待爬取
Task:描述一个爬取任务。
HTMLTask:网页爬取任务
DBTask:DB爬取任务
DelayPolicy:定义Task的延迟策略,比如对同一个域名的网站,采取每隔5秒钟的爬取一次的方案。如果发现遭到限制,对同一个域名的网站,采取停歇10分钟的策略。
考虑到对将来对数据爬虫的支持,抽象了统一接口。数据库对Task,Fetcher,parser,Handler,Worker都有自己的实现。
3. Fetcher
网页的直接爬取者。根据传入的Task,爬取对方的网页。
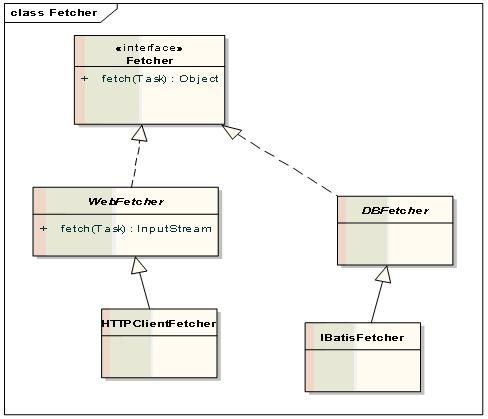
WebFetcher爬取的网页直接作为输入流传回。
HTTPClientFetcher:用HTTPClient4.0实现的WebFetcher,底层用的是java NIO.
4. Worker
Worker负责Task的具体执行,从爬取到处理的整个流程. TaskMaster将Worker提交到线程池中,有线程池调度并发执行。
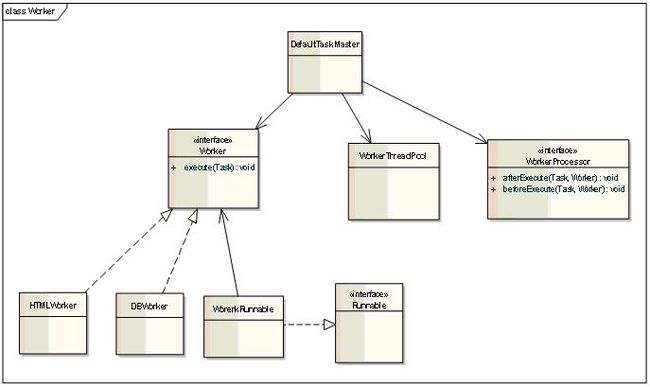
Worker:整个爬取的执行流程
HTMLWorker:处理HTML网页的爬取
WorkerThreadPool:线程池,供Worker执行使用
WorkerProcessor:监听器。在worker执行前,执行后调用。可以做一些日志,错误处理等等。
5. Parser
Parser将爬虫爬取的内容解析为规范的数据格式,提取有用的信息,便于系统进一步处理。

Parser:将传入的content解析成Data,或者利用传入的handler可以一边parse一边调用handler处理。
Data:Parser解析后的数据结构
Content:Fetcher到的Content
RegexParser:对传入的字符串进行正则匹配,提取想要的字符串。
SaxParser:主要是通过回调方式实现
DomParser:将XML转成Document返回
HTMLParser:组合模式,可以综合使用RegexParser,DomParser等完成任务。
ParseContext:传给Parser的上下文环境。可供扩展使用。
6. Filter
Filter可以对解析好的新Task,进行过滤。

7. Handler
Handler对解析好的内容进行进一步处理,异步化处理和爬取解析。处理主要是将爬取的数据入库和索引。
一、 Task队列
Task队列,存放还没有被处理的新任务。

二、 Visited表
Visited表的判断其实是TaskFilter的一种,只是TaskFilter用了VisitedTable来存储已经爬取过的任务。
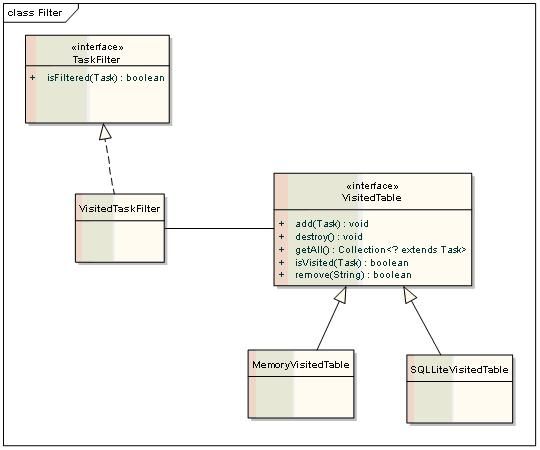
VisitedTaskFilter:判断Task是否已经被处理过
VisitedTable:存储已经被爬取过的任务
转自: http://ldd600.iteye.com/blog/1151957