SQL Server索引优化——重复索引
SQL Server索引优化——重复索引
在写完《SQL Server 索引优化——无用索引和索引缺失》系列后,就想着写点关于发现重复索引的内容,刚好在Kimberly的博文中发现了这篇,就偷懒了,直接将其翻译过来。
一直以来,对重复索引都有许多困惑,我想的最多是如何使用sp_helpindex(或者SSMS)展示索引所包含的内容。索引到底包含什么?索引的架构是怎样的?这些通常都不是我们所看到的那样。这是我最初重写sp_helpindex的动力所在,但即使这样,我仍然感到很多困惑。在今天的博文中,我将首先准确的解释哪些索引是相同的,哪些不同,并且说明一些工具中的错误。
因此,从索引的架构开始……(一切从内部开始)
聚集索引是数据。聚集索引的键(我通常称其为聚集键),定义了数据的存储顺序的方式(不一定准确,硬盘上的物理顺序,而非逻辑顺序)。而且,不,我并不打算在此展开来说索引内部的所有内容……仅仅几点体现。
非聚集索引是重复的数据(类似于书后面的索引)。这些重复的数据可以被用于帮助检索真实数据(就像书后面的索引一样),或者被用于响应请求(例如,如果你单单是为了查询某姓的人有多少,那么一个包含姓的索引可以用来计算,而不是去查询实际的数据)。因此,索引有一些非常强大的用途。但是,唉,这不是一篇关于索引使用或者索引策略的文章——这里都是关于内部的(理解索引的架构)。所以我们要开门见山了。
一个非聚集索引总是这样的:
-
键(这是定义索引顺序的)
-
叶级实体(这是索引中真正数据存储的地方+查找值+所有包含列)——然而所有这些列仅存储一次(且它们总是被存储在这里一次,即使你引用的一列是查找值的一部分,SQL Server也不会重复存储它)。
*那么什么是查找值(lookup value)?
查找值是SQL Server 用来指向真实数据的行。如果一个表有聚集索引,那么查找值就是聚集键(包括所有定义聚集键的列)。如果一个表没有聚集索引(它是一个堆heap),那么SQL Server 使用被称为RID作为查询值。一个RID是一个8字节的结构,组成比例为2:4:2字节,其为文件编号分2字节,4字节分给页编号,2字节分给槽(slot)编号。虽然RID(和其历史)很有趣——但它和这里没有一点关系(它们是如何工作的,或者它们的架构是怎样的),但如果当它们存在于一个索引中,我仍然称其为RID。
现在,让我们将这些和一个(或两个)相对简单的例子结合起来。
USE WideWorldImporters;
GO
CREATE TABLE Test(
TestID INT IDENTITY,
[Name] CHAR(16)
);
GO
CREATE UNIQUE CLUSTERED INDEX TestCL ON Test(TestID);
GO
CREATE INDEX TestName ON Test([Name]);
GO
sp_helpindex Test;
GO输出结果如下:
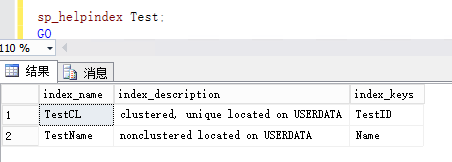
嗯,这看起来是正确的,但是却有很大的误导性。索引TestName同时也包含TestID。不是在页级别,而是在树干中(排序目的)。因此真实的应该显示Name,TestID。但是,如果你加上下面的,会让你更困惑:
CREATE UNIQUE INDEX TestNameUnique ON Test([Name]);
EXECUTE sp_helpindex Test;
GO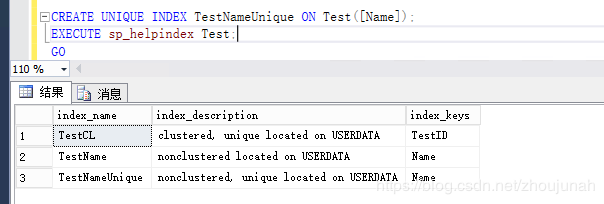
此时,第二、第三索引看起来没有什么不同(当然,除了第三索引需要值是唯一的——如描述中所写)。但是,对于“index_keys”,他们看起来一样。然而,实际上,它们是不同的(从整个树的来看)。所以,这就是我倾向于区分“叶”级和非叶级别索引的原因(当我描述它们的时候)。当你将包含列扔进去的时候,会变得更复杂(2005+)。
因此,你将如何去区分它们的不同呢?不幸的是,在SQL Server中,没有工具(或者甚至据我所知的第三方工具),可以通过UI展示这个。但是,你可以使用替换的sp_helpindex开始。《SQL Server 索引优化——sp_helpindex 改写脚本》一文给出了改写脚本,更为详尽的可以参阅Kimberly各版本sp_helpindex改写脚本。使用这个,你可以看到输出的内容更详细。
输出展示如下(尤其注意最后两列)

现在,我们获得了一些眉目。我们可以明显区分出两个索引的不同。一个非唯一的非聚集索引需要将查找值放入树中。唯一的非聚集索引,则不需要这样做。
下一步,我们进行更具有挑战性的例子:
USE WideWorldImporters;
GO
CREATE TABLE Member
(
MemberNo INT IDENTITY,
FirstName VARCHAR(30) NOT NULL,
LastName VARCHAR(30) NOT NULL,
RegionNo INT
);
GO
CREATE UNIQUE CLUSTERED INDEX MemberCL ON Member(MemberNo);
GO
CREATE INDEX MemberIndex1
ON Member(FirstName,RegionNo,MemberNo)
INCLUDE(LastName);
GO
CREATE INDEX MemberIndex2
ON Member(FirstName,RegionNo)
INCLUDE(LastName);
GO
CREATE INDEX MemberIndex3
ON Member(FirstName,RegionNo)
INCLUDE(MemberNo,LastName);
GO
CREATE UNIQUE INDEX MemberIndex4
ON Member(FirstName,RegionNo)
INCLUDE(MemberNo,LastName);
GO首先,我们使用sp_helpindex来查看索引情况
EXECUTE sp_helpindex Member;输出如下:
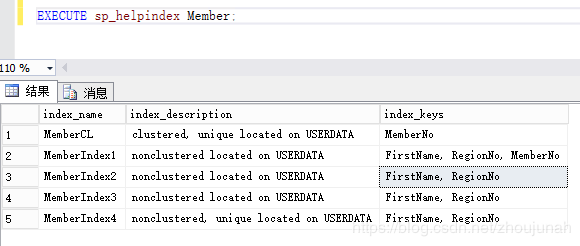
单独看sp_helpindex的结果,看起来第一个非聚集索引和第2、3、4个索引不同,而第2、3、4个索引是相同。实际上并非如此。接下来我们使用改进的sp_helpindex来查看:
EXECUTE sp_helpindex_SQL2016 Member;
从这里,你可以看到4个非聚集索引的叶节点列是相同的,第4个非聚集索引和其他三个非聚集索引的树结构有一点不同。最终,非聚集索引1,2,3是相同的,4和其他三个不同。它们的不同之处在哪里(除非聚集索引4保证唯一性的事实外),超出了该文的范围。但是,是的,有(在这个案例中相对较小的)不同。因为我只寻找相同的索引所以只有1 2 3满足这个要求。
并且,当你的聚集索引有多列,和\或有更复杂的包含列,事情将变得更为复杂。
话虽如此,如何找到重复的索引呢?
很好……开始时,我用一种简单的方法让您使用我改进的sp_helpindex版本的检查重复索引,但是后来我发现了包含列的一个问题。我已经展示了它们的定义(存储)架构。但是,从使用上来说,包含列的顺序无关紧要。结果两个拥有不同顺序的包含列将变为两个不同的索引(技术上,或者存储上,它们确实不同)。然而确实没有什么不同(从使用上来看)。因此我需要写代码来调整它(发现真正的重复索引)。
现在,这里有一些快速的代码可以让您更接近它。当我做客于London Immersion Event时,我也写了一些。然而,在考虑了一些有趣的异常之后,我在这里对它进行了进一步的调整。这段代码将发现绝对的重复(结构的顺序完全相同)。为了使用它,你首先需要根据《SQL Server 索引优化——sp_helpindex 改写脚本》一文创建sp_helpindex_SQL2016过程,然后需要架构名和表名,脚本如下:
IF(OBJECT_ID('tempdb..#FindDupes',N'U')) IS NOT NULL
DROP TABLE #FindDupes;
GO
CREATE TABLE #FindDupes
(
index_id INT,
is_disabled BIT,
index_name sysname,
index_description VARCHAR(210),
index_keys VARCHAR(2126),
included_columns NVARCHAR(MAX),
filter_definition NVARCHAR(MAX),
columns_in_tree NVARCHAR(2126),
columns_in_leaf NVARCHAR(MAX)
);
GO
DECLARE @SchemaName sysname,
@TableName sysname,
@ExecStr NVARCHAR(MAX);
SELECT @SchemaName=N'dbo',@TableName=N'Member';
SELECT @ExecStr='EXECUTE sp_helpindex_SQL2016 '''
+QUOTENAME(@SchemaName)
+N'.'
+QUOTENAME(@TableName)
+N'''';
INSERT INTO #FindDupes
EXECUTE(@execStr);
SELECT t1.index_id, COUNT(*) AS 'Duplicate Indexes w/Lower Index_ID',
N'DROP INDEX '
+ QUOTENAME(@SchemaName, N']')
+ N'.'
+ QUOTENAME(@TableName, N']')
+ N'.'
+ t1.index_name AS 'Drop Index Statement'
FROM #FindDupes AS t1
INNER JOIN #FindDupes AS t2
ON t1.columns_in_tree = t2.columns_in_tree
AND t1.columns_in_leaf = t2.columns_in_leaf
AND ISNULL(t1.filter_definition, 1) = ISNULL(t2.filter_definition, 1)
AND PATINDEX('%unique%', t1.index_description) = PATINDEX('%unique%', t2.index_description)
AND t1.index_id > t2.index_id
GROUP BY t1.index_id, N'DROP INDEX ' + QUOTENAME(@SchemaName, N']')
+ N'.'
+ QUOTENAME(@TableName, N']')
+ N'.' + t1.index_name;
GO接下来,我们给出发现重复索引的存储过程,这个过程也是建立在《SQL Server 索引优化——sp_helpindex 改写脚本》一文中各过程的基础上,创建如下脚本,先创建sp_helpindex_SQL2016相关过程,脚本如下:
/*============================================================================
File: sp_FindDupesIndexes_SQL2016.sql
摘要: 在一个数据库中运行它,将获得该数据库下的所有重复索引和删除重复索引的脚本
Date: 2019.2
SQL Server 2016 Version
------------------------------------------------------------------------------
============================================================================*/
USE master;
go
IF OBJECTPROPERTY(OBJECT_ID('sp_FindDupesIndexes_SQL2016'), 'IsProcedure') = 1
DROP PROCEDURE sp_FindDupesIndexes_SQL2016;
go
CREATE PROCEDURE [dbo].[sp_FindDupesIndexes_SQL2016]
(
@ObjName NVARCHAR(776) = NULL -- 输入表名,检验该表的重复索引
-- 输入 NULL 检验该数据库所有重复索引
)
AS
SET NOCOUNT ON;
DECLARE @ObjID INT, -- 表对象编号
@DBName sysname, --数据库名称
@SchemaName sysname, --架构名称
@TableName sysname, --表名
@ExecStr NVARCHAR(4000);
-- 检查输入数据库是否存在
SELECT @DBName = PARSENAME(@ObjName,3);
IF @DBName IS NULL
SELECT @DBName = DB_NAME();
ELSE
IF @DBName <> DB_NAME()
BEGIN
RAISERROR(15250,-1,-1);
-- select * from sys.messages where message_id = 15250
RETURN (1);
END;
IF @DBName = N'tempdb'
BEGIN
RAISERROR('WARNING: This procedure cannot be run against tempdb. Skipping tempdb.', 10, 0);
RETURN (1);
END;
-- 检查架构是否存在,并初始化架构名
SELECT @SchemaName = PARSENAME(@ObjName, 2);
IF @SchemaName IS NULL
SELECT @SchemaName = SCHEMA_NAME();
-- 检查表是否存在,并初始化表编号
IF @ObjName IS NOT NULL
BEGIN
SELECT @ObjID = OBJECT_ID(@ObjName);
IF @ObjID IS NULL
BEGIN
RAISERROR(15009,-1,-1,@ObjName,@DBName);
-- select * from sys.messages where message_id = 15009
RETURN (1);
END;
END;
CREATE TABLE #DropIndexes
(
DatabaseName sysname,
SchemaName sysname,
TableName sysname,
IndexName sysname,
DropStatement NVARCHAR(2000)
);
CREATE TABLE #FindDupes
(
index_id INT,
is_disabled BIT,
index_name sysname,
index_description VARCHAR(210),
index_keys NVARCHAR(2126),
included_columns NVARCHAR(MAX),
filter_definition NVARCHAR(MAX),
columns_in_tree NVARCHAR(2126),
columns_in_leaf NVARCHAR(MAX)
);
-- OPEN CURSOR OVER TABLE(S)
IF @ObjName IS NOT NULL
DECLARE TableCursor CURSOR LOCAL STATIC FOR
SELECT @SchemaName, PARSENAME(@ObjName, 1);
ELSE
DECLARE TableCursor CURSOR LOCAL STATIC FOR
SELECT SCHEMA_NAME(uid), name
FROM sysobjects
WHERE TYPE = 'U' --AND name
ORDER BY SCHEMA_NAME(uid), name;
OPEN TableCursor;
FETCH TableCursor
INTO @SchemaName, @TableName;
-- For each table, list the add the duplicate indexes and save
-- the info in a temporary table that we'll print out at the end.
WHILE @@fetch_status >= 0
BEGIN
TRUNCATE TABLE #FindDupes;
SELECT @ExecStr = 'EXEC sp_helpindex_SQL2016 '''
+ QUOTENAME(@SchemaName)
+ N'.'
+ QUOTENAME(@TableName)
+ N'''';
--SELECT @ExecStr
INSERT #FindDupes
EXECUTE (@ExecStr);
--SELECT * FROM #FindDupes
INSERT #DropIndexes
SELECT DISTINCT @DBName,
@SchemaName,
@TableName,
t1.index_name,
N'DROP INDEX '
+ QUOTENAME(@SchemaName, N']')
+ N'.'
+ QUOTENAME(@TableName, N']')
+ N'.'
+ t1.index_name
FROM #FindDupes AS t1
JOIN #FindDupes AS t2
ON
--t1.columns_in_tree = t2.columns_in_tree
-- AND t1.columns_in_leaf = t2.columns_in_leaf
(PATINDEX('%'+t2.index_keys+'%',t1.index_keys)>0 OR PATINDEX('%'+t1.index_keys+'%',t2.index_keys)>0)
AND ISNULL(t1.filter_definition, 1) = ISNULL(t2.filter_definition, 1)
AND PATINDEX('%unique%', t1.index_description) = PATINDEX('%unique%', t2.index_description)
AND t1.index_id > t2.index_id;
FETCH TableCursor
INTO @SchemaName, @TableName;
END;
DEALLOCATE TableCursor;
-- DISPLAY THE RESULTS
IF (SELECT COUNT(*) FROM #DropIndexes) = 0
RAISERROR('Database: %s has NO duplicate indexes.', 10, 0, @DBName);
ELSE
SELECT * FROM #DropIndexes
ORDER BY SchemaName, TableName;
RETURN (0); -- sp_FindDupesIndexes_SQL2016
go
EXECUTE sys.sp_MS_marksystemobject 'sp_FindDupesIndexes_SQL2016';
go文章来源,译Kimberly的博客
如果喜欢,可以扫码关注SQL Server 公众号,将有更多精彩内容分享: