Hive实现分组排序、分组求取topN或者分页的实现方法
使用到的语法:ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)
简单的说row_number()从1开始,为每一条分组记录返回一个数字,这里的ROW_NUMBER() OVER (ORDER BY xlh DESC) 是先把xlh列降序,再为降序以后的每条xlh记录返回一个序号。
表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)实例.
语法:row_number() over (partition by 字段a order by 计算项b desc ) rank
--这里rank是别名
partition by:类似hive的建表,分区的意思;
order by :排序,默认是升序,加desc降序;
这里按字段a分区,对计算项b进行降序排序
实例一、
要取top10品牌,各品牌的top10渠道,各品牌的top10渠道中各渠道的top10档期
1、取top10品牌
select 品牌,sum(income) as num from table_name group by 品牌 order by num desc limit 10;
2、 取top10品牌下各品牌的top10渠道
select
a.*
from
(
select 品牌,渠道,sum(income) as num, row_number() over (partition by 品牌 order by num desc ) rank
from table_name
where 品牌限制条件
group by 品牌,渠道
)a
where
a.rank<=10
3、 取top10品牌下各品牌的top10渠道中各渠道的top10档期
select
a.*
from
(
select 品牌,渠道,档期,sum(income) as num, row_number() over (partition by 品牌,渠道 order by num desc ) rank
from table_name
where 品牌,渠道 限制条件
group by 品牌,渠道,档期
)a
where
a.rank<=10
实例二:
初始化数据:
create table employee (empid int ,deptid int ,salary decimal(10,2));
insert into employee values(1,10,5500.00);
insert into employee values(2,10,4500.00);
insert into employee values(3,20,1900.00);
insert into employee values(4,20,4800.00);
insert into employee values(5,40,6500.00);
insert into employee values(6,40,14500.00);
insert into employee values(7,40,44500.00);
insert into employee values(8,50,6500.00);
insert into employee values(9,50,7500.00);
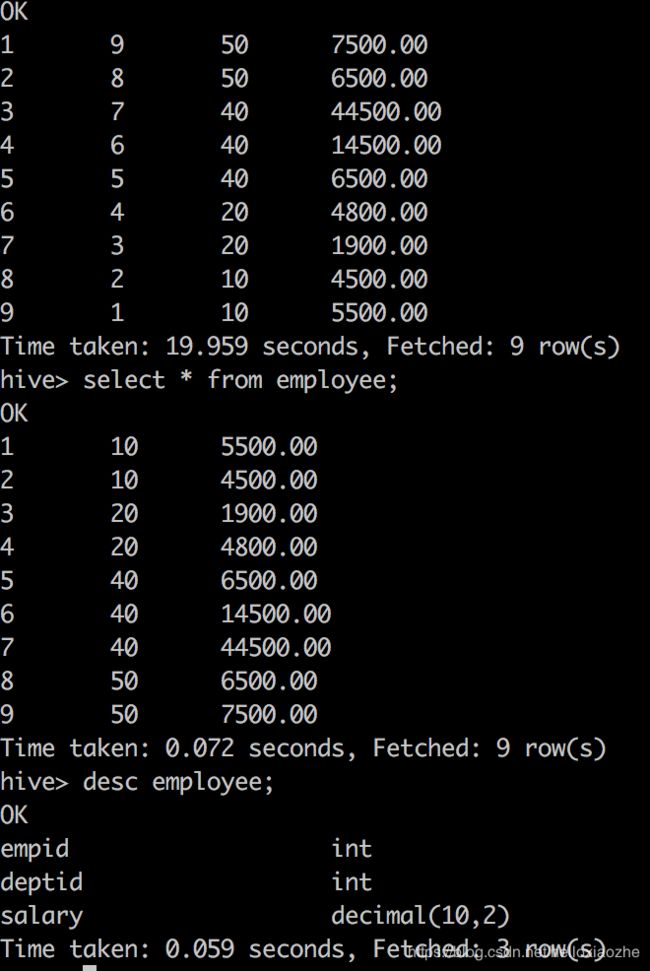
显示数据:
hive> select * from employee;
1 10 5500.00
2 10 4500.00
3 20 1900.00
4 20 4800.00
5 40 6500.00
6 40 14500.00
7 40 44500.00
8 50 6500.00
9 50 7500.00
Time taken: 4.078 seconds, Fetched: 9 row(s)
hive> desc employee;
empid int
deptid int
salary decimal(10,2)
Time taken: 0.042 seconds, Fetched: 3 row(s)
(1)需求:根据部门分组,显示每个部门的工资等级
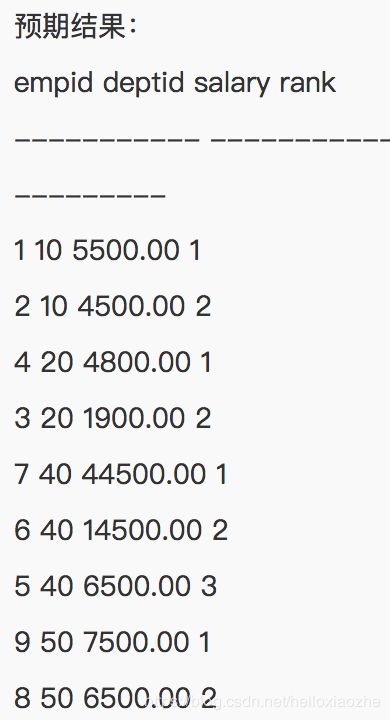
实现的HSQL脚本:
hive> SELECT *, row_number() OVER (partition by deptid ORDER BY salary desc) rank FROM employee;
OK
1 10 5500.00 1
2 10 4500.00 2
4 20 4800.00 1
3 20 1900.00 2
7 40 44500.00 1
6 40 14500.00 2
5 40 6500.00 3
9 50 7500.00 1
8 50 6500.00 2
Time taken: 25.019 seconds, Fetched: 9 row(s)
(2)根据部门分组,求出每个部门的工资等级排名top 2的数据
SELECT
*
FROM
(
SELECT
*, row_number() OVER(PARTITION BY deptid
ORDER BY salary DESC
) rank
FROM
employee
) a
WHERE
a.rank <= 2;
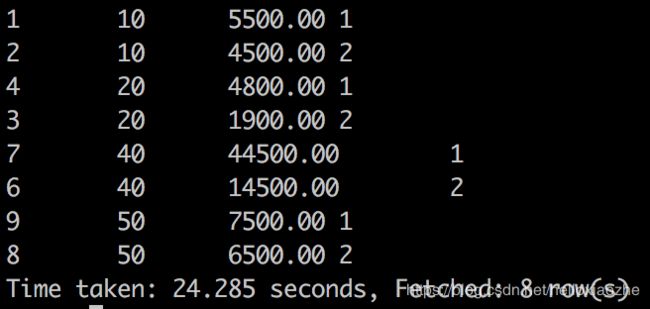
(3)根据部门分组,求出每个部门的工资等级排第二名的那条数据
SELECT
*
FROM
(
SELECT
*, row_number() OVER(PARTITION BY deptid
ORDER BY salary DESC
) rank
FROM
employee
) a
WHERE
a.rank = 2;
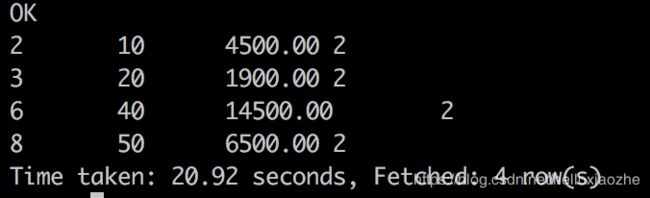
按照empid降序排列,并按照排列顺序给出编号:
SELECT
row_number() over(ORDER BY empid DESC) AS rnum ,
employee.*
FROM
employee
(4)hive中一般取top n时,row_number(),rank,dense_ran()这三个函数就派上用场了,
先简单说下这三函数都是排名的,不过呢还有点细微的区别。
通过代码运行结果一看就明白了。
除Row_number外还有rank,dense_rank
以下是语法:
rank() over([partition by col1] order by col2)
dense_rank() over([partition by col1] order by col2)
row_number() over([partition by col1] order by col2)
功能差不多,但是有细微的差别
row_number的排序不允许并列,即使两条记录的值相等也不会出现相等的排序值
rank排序时出现相等的值时会有并列,即值相等的两条数据会有相同的序列值
dense_rank排序的值允许并列,但会跳跃的排序,像这样:1,1,3,4,5,5,7.
select empid,
deptid,
salary,
rank()over( order by deptid desc ) rank,
dense_rank() over( order by deptid desc ) dense_rank,
row_number()over( order by deptid desc) row_number
from employee
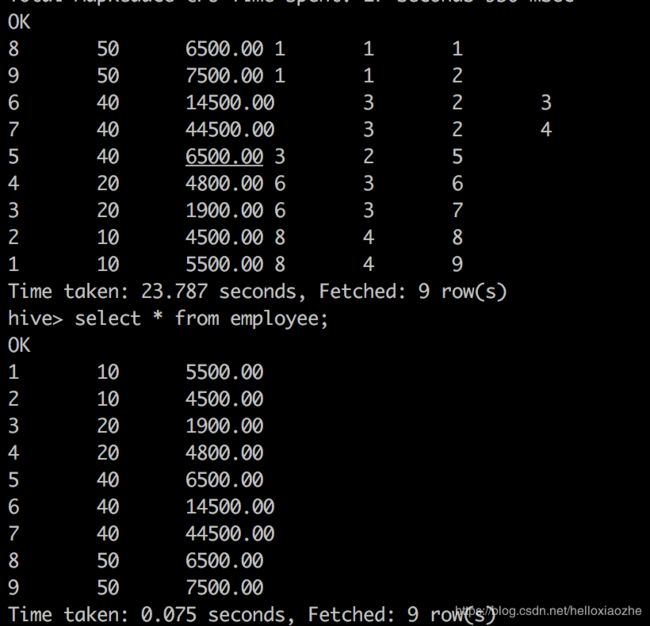
从结果看出
rank() 排序相同时会重复,总数不会变
dense_rank()排序相同时会重复,总数会减少
row_number() 会根据顺序计算
正好听到一个需求,求sal前50%的人
(5)基于row_number函数也很容易实现分页:
SELECT
*
FROM
(
SELECT
row_number() over(ORDER BY empid DESC) AS rnum ,
employee.*
FROM
employee
) t
WHERE
rnum >= 1
AND rnum <= 5;

参考:https://www.2cto.com/net/201803/733548.html
http://blog.sina.com.cn/s/blog_6676d74d0102vm2c.html