文章目录
- ARM 汇编语言
- ARM 汇编程序结构
- 汇编指令
- 寄存器
- 处理器寻址方式
- 立即寻址
- 寄存器寻址
- 寄存器移位寻址
- 寄存器间接寻址
- 基址寻址
- 多寄存器寻址
- 堆栈寻址
- 块拷贝寻址
- 相对寻址
- 子程序参数传递
ARM 汇编语言
- 一门语言通常有自己的关键字、代码规范、子程序调用、注释等,汇编语言也一样
- 汇编语言:将一系列与处理器相关的汇编指令用某种语法和结构组织在一起的程序语言形式
- 用特定汇编语法规范编写的汇编代码,可被完整地编译或嵌入其他高级语言
- Android 中的 ARM 汇编使用 GNU 汇编格式,现在开始学习 GNU ARM 汇编的一般语法格式及特点
ARM 汇编程序结构
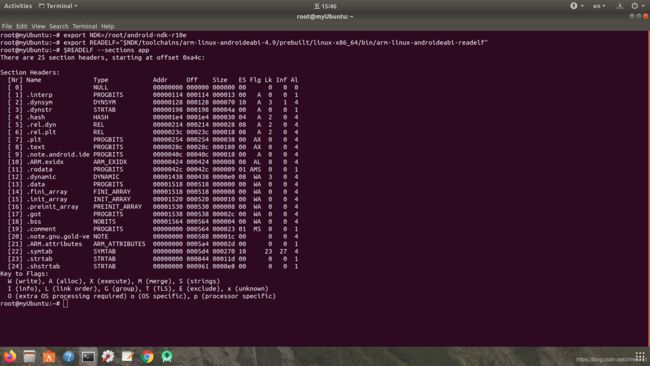
- 编译器在编译阶段会在内部将程序代码编译成与机器相关的汇编指令,上一节的 hello.c 的汇编代码就是一个完整的 ARM 汇编程序
- 现在编写一个新的程序 app.c,代码:
#include
int add(int a, int b, int c, int d)
{
return a + b + c + d;
}
int main(int argc, char const *argv[])
{
printf("add: %d\n", add(1, 2, 3, 4));
return 0;
}
- 执行如下命令,生成 app.s 汇编代码:
- 系统、NDK 版本、CC 环境变量设置等信息见上一节
.text
.syntax unified
.cpu arm1022e
.eabi_attribute 6, 4 @ Tag_CPU_arch
.eabi_attribute 8, 1 @ Tag_ARM_ISA_use
.eabi_attribute 15, 1 @ Tag_ABI_PCS_RW_data
.eabi_attribute 16, 1 @ Tag_ABI_PCS_RO_data
.eabi_attribute 17, 2 @ Tag_ABI_PCS_GOT_use
.eabi_attribute 20, 1 @ Tag_ABI_FP_denormal
.eabi_attribute 21, 1 @ Tag_ABI_FP_exceptions
.eabi_attribute 23, 3 @ Tag_ABI_FP_number_model
.eabi_attribute 24, 1 @ Tag_ABI_align_needed
.eabi_attribute 25, 1 @ Tag_ABI_align_preserved
.eabi_attribute 18, 4 @ Tag_ABI_PCS_wchar_t
.eabi_attribute 26, 2 @ Tag_ABI_enum_size
.file "app.c"
.globl add
.align 2
.type add,%function
add: @ @add
.fnstart
.Leh_func_begin0:
@ BB#0: @ %entry
.pad #16
sub sp, sp, #16
str r0, [sp, #12]
str r1, [sp, #8]
str r2, [sp, #4]
str r3, [sp]
ldr r0, [sp, #12]
ldr r1, [sp, #8]
add r0, r0, r1
ldr r1, [sp, #4]
add r0, r0, r1
ldr r1, [sp]
add r0, r0, r1
add sp, sp, #16
bx lr
.Ltmp0:
.size add, .Ltmp0-add
.cantunwind
.fnend
.globl main
.align 2
.type main,%function
main: @ @main
.fnstart
.Leh_func_begin1:
@ BB#0: @ %entry
.save {r4, r5, r11, lr}
push {r4, r5, r11, lr}
.setfp r11, sp, #8
add r11, sp, #8
.pad #24
sub sp, sp, #24
ldr r2, .LCPI1_6
.LPC1_0:
add r2, pc, r2
ldr r3, .LCPI1_2
ldr r12, .LCPI1_3
ldr lr, .LCPI1_4
ldr r4, .LCPI1_5
ldr r5, .LCPI1_0
str r5, [r11, #-12]
str r0, [sp, #16]
str r1, [sp, #12]
mov r0, r3
mov r1, r12
str r2, [sp, #8] @ 4-byte Spill
mov r2, lr
mov r3, r4
bl add(PLT)
ldr r1, .LCPI1_1
ldr r2, [sp, #8] @ 4-byte Reload
add r1, r1, r2
str r0, [sp, #4] @ 4-byte Spill
mov r0, r1
ldr r1, [sp, #4] @ 4-byte Reload
bl printf(PLT)
ldr r1, .LCPI1_0
str r0, [sp] @ 4-byte Spill
mov r0, r1
sub sp, r11, #8
pop {r4, r5, r11, pc}
.align 2
@ BB#1:
.LCPI1_0:
.long 0 @ 0x0
.LCPI1_1:
.long .L.str(GOTOFF)
.LCPI1_2:
.long 1 @ 0x1
.LCPI1_3:
.long 2 @ 0x2
.LCPI1_4:
.long 3 @ 0x3
.LCPI1_5:
.long 4 @ 0x4
.LCPI1_6:
.long _GLOBAL_OFFSET_TABLE_-(.LPC1_0+8)
.Ltmp1:
.size main, .Ltmp1-main
.cantunwind
.fnend
.type .L.str,%object @ @.str
.section .rodata.str1.1,"aMS",%progbits,1
.L.str:
.asciz "add: %d\n"
.size .L.str, 9
.ident "clang version 3.5 "
汇编指令
- 汇编语言能实现什么功能,完全由其子程序的功能决定,而子程序中几乎都是处理器指令。归根结底,一个程序中,除了里面的数据,最重要的就是汇编指令
- ARM 处理器使用基于精简架构的处理器指令集(Reduced Instruction Set Computer, RISC),其特点是所有指令的长度都是相同的。如,ARM 指令集采用 32 位指令,Thumb 指令集采用 16 位指令。这和 Inter x86 的变长指令不同。这样的好处:程序执行时处理器取指令的速度相对较快,执行效率更高
- ARM 中定义的每条汇编指令都有特定含义。如,
add 表示加法,sub 表示减法。以 app.s 中的 add() 子程序(片段)为例: sub sp, sp, #16
str r0, [sp, #12]
str r1, [sp, #8]
str r2, [sp, #4]
str r3, [sp]
ldr r0, [sp, #12]
ldr r1, [sp, #8]
add r0, r0, r1
ldr r1, [sp, #4]
add r0, r0, r1
ldr r1, [sp]
add r0, r0, r1
add sp, sp, #16
bx lr
- sub:减法指令。第一条指令
sub sp, sp, #16 中,sub 是汇编减法指令,出现在汇编语句前面,后跟结果对象 sp、原操作对象 sp、目的操作对象数值 16,所做的工作为将 sp 寄存器减 16 字节的结果存入 sp 寄存器(即四个 4 字节空间),目的是存储后面指令执行的中间结果。即开辟栈空间
- str:存数据指令。第二条指令
str r0, [sp, #12],用于将 r0 寄存器的内容存入 sp 寄存器加 12 字节的位置。ARM 指令操作的数据长度为 32 位,即 4 字节。第二至五条指令所做的工作是将 r0 ~ r3 寄存器中的内容存入第一条指令开辟的栈空间
- ldr:取数据指令。执行的操作与
str 相反。第六条指令 ldr r0, [sp, #12],即读取 sp 寄存器加 12 字节位置的数据存入 r0 寄存器
- add:加法指令。第八条指令
add r0, r0, r1,即将 r0 与 r1 寄存器中的数据相加,将结果存入 r0 寄存器;第十三条指令 add sp, sp, #16 与第一条指令相反,为关闭那 16 字节的栈空间
- bx:带状态切换的跳转指令,用于跳转到 lr 寄存器指定的位置并执行代码,通常表示子程序结束并返回
- ARM 中程序的返回结果存在 r0 寄存器。从整体上看上述代码,相当于执行了如下操作:
int add(int r0, int r1, int r2, int r3) {
return r0 + r1 + r2 + r3;
}
- 可看出,上述汇编代码不够精简,在 r0 ~ r3 间进行的一次临时保存为多余操作。之所以如此,是因为没为编译器启动代码优化。可为编译器指定参数
-O(大写)来确定代码的优化等级。开启 -O3 优化等级后 add() 子程序的汇编代码:

- 可看出,优化后的代码中汇编指令全用加法完成,没多余部分
- 前面所学为汇编指令的基本语义,汇编指令的具体格式和规范将在下一节学习
寄存器
- 很多汇编指令要指定源操作对象与目标操作对象,操作的对象很多时候是寄存器。如,
add r0, r1, r0 指令用于将 r1 寄存器的值和 r0 寄存器的值相加,结果存入 r0 寄存器
- 寄存器是处理器特有的高速存储部件,可用于暂存指令、数据和地址。高级语言中用的变量、常量、结构体、类等数据到了 ARM 汇编语言中,就是用寄存器保存值或内存地址。寄存器数量有限,32 位的 ARM 微处理器共有 37 个 32 位寄存器,其中 31 个为通用寄存器(Inter x86 32 位才 8 个,64 位才 16 个),6 个为状态寄存器
- ARM 处理器支持的运行模式:
- 用户模式(usr):ARM 处理器正常的程序执行状态
- 快速中断模式(fiq):用于高速数据传输或通道处理
- 外部中断模式(irq):用于通用的中断处理
- 管理模式(svc):操作系统使用的保护模式
- 数据访问终止模式(abt):当数据或指令预取终止时进入该模式,可用于虚拟存储及存储保护
- 系统模式(sys):运行具有特权的操作系统任务
- 未定义指令中止模式(und):当未定义的指令执行时进入该模式
- ARM 处理器的运行模式即可通过软件改变,也可通过外部中断或异常处理改变。不同模式下,处理器使用的寄存器不尽相同,可供访问的资源也不一样。以上模式除了用户模式,都是特权模式。特权模式下,处理器可任意访问受保护的系统资源。现在只关注 ARM 程序逆向分析技术涉及的用户模式
- 32 位用户模式下,处理器可访问的寄存器为不分组寄存器 R0 ~ R7、分组寄存器 R8 ~ R14、程序计数器 R15(PC)、当前程序状态寄存器 CPSR
- ARM 处理器有两种工作状态,即 ARM 状态和 Thumb 状态,处理器可在这两种状态间随意切换。处理器处于 ARM 状态时,会执行 32 位对齐的 ARM 指令;处于 Thumb 状态时,会执行 16 位对齐的 Thumb 指令。Thumb 状态下对寄存器的命名与 ARM 状态下有所差异,它们的关系:
- Thumb 状态下的 R0 ~ R7 与 ARM 状态下的 R0 ~ R7 相同
- Thumb 状态下的 CPSR 与 ARM 状态下的 CPSR 相同
- Thumb 状态下的 FP 对应 ARM 状态下的 R11
- Thumb 状态下的 IP 对应 ARM 状态下的 R12
- Thumb 状态下的 SP 对应 ARM 状态下的 R13
- Thumb 状态下的 LR 对应 ARM 状态下的 R14
- Thumb 状态下的 PC 对应 ARM 状态下的 R15
- 到了 arm64-v8a 时代,一切有了全新面貌。AArch64 用 32 位固定长度的指令集,有如下特性:
- 引入异常等级的概念,有 EL0 ~ EL3 四种异常等级
- 提供基于 5 位寄存器说明符的简洁解码表
- 指令语义与 AArch32 中大致相同
- 提供 31 个可随时访问的通用 64 位寄存器 x0 ~ x30
- 提供无模式 GP 寄存器组
- 提供程序计数器(PC)和堆栈指针(SP)非通用寄存器
- 提供可用于大多数指令的专用零寄存器 XZR/WZR
- 异常等级与 armeabi 的处理器运行模式类似,等级越高,拥有的特权越高。我们的应用一般运行于 EL0 等级,操作系统内核运行于 EL1,EL2、EL3 留给安全监控软件和虚拟化软件用。对应用来说,EL0 没有权限进行 AArch64 和 AArch32 状态的切换,这就是我们的 AArch64 指令无法转换为 AArch32 与 T16 指令的原因
- AArch64 和 AArch32 的主要差异:
- AArch64 支持 64 位操作数的指令,大多数指令可具有 32 位或 64 位的参数
- AArch64 地址假定为 64 位,主要的目标数据模型是 P64 和 LLP64
- AArch64 的条件指令远少于 AArch32 架构
- AArch64 没有任意长度的加载/存储多重指令,增加了用于处理寄存器对的 LD/ST 指令
- 虽然 AArch64 与 AArch32 的寄存器数目通常都为 32 个,但在使用上有很大不同:
- AArch64 的寄存器名变为 x0 ~ x30。x0 ~ x7 用于传递参数与计算结果;x8 为直接结果位置寄存器;x9 ~ x15 为临时寄存器;x16、x17 为内部过程调用寄存器(也可作为临时寄存器 IP0 和 IP1);x18 为临时寄存器;x19 ~ x28 为调用备份寄存器;x29 为帧指针寄存器;x30 作为过程链接寄存器 PLR 使用
- AArch64 的 x0 ~ x30 寄存器都为 64 位,每个寄存器可通过 W0 ~ W30 访问低 32 位。读 32 位寄存器 Wn 时,不影响高 32 位的值;写 Wn 时,高 32 位全部清零
- AArch64 在运行态下没有与 CPSR 对应的寄存器,要分别访问每种状态标志。处于异常等级 EL0 的程序,只能访问 N(负数)、Z(零)、C(进位)、V(溢出)四个状态标志
- 除了通用寄存器,arm64-v8a 还提供 32 个 128 位 NEON 浮点寄存器 V0 ~ V31,它们可作为半精度寄存器 H、单精度寄存器 S、双精度寄存器 D 使用
处理器寻址方式
- 指通过指令中给出的地址码字段寻找真实操作数地址的方式
- 虽然 ARM 采用精简指令集,但指令间组合的灵活度却比 x86 高。x86 支持七种寻址方式,ARM 支持九种
立即寻址
- 最简单的寻址方式
- 大多数处理器都支持这种方式
- 立即寻址指令中,后面的地址码部分为立即数(即常量或常数)
- 立即寻址多用于给寄存器赋初值
- 立即数只能用于源操作数字段,不能用于目的操作数字段
- 示例:
MOV R0, #1234
- 上述指令执行后,R0=1234
- 立即数以“#”为前缀,表示十六进制数值时以“0x”开头,如“#0x20”
寄存器寻址
- 操作数的值在寄存器中,指令执行时直接从寄存器中取值进行操作
- 示例:
MOV R0, R1
- 上述指令执行后,R0=R1
寄存器移位寻址
- ARM 指令集特有的寻址方式
- 与寄存器寻址类似,只是在操作前要对源寄存器操作数进行移位操作
- 支持以下五种移位操作:
- LSL:逻辑左移,移位后对寄存器空出的低位补 0
- LSR:逻辑右移,移位后对寄存器空出的高位补 0
- ASR:算术右移,移位过程中符号位不变。若源操作数为正数,则移位后对空出的高位补 0,否则补 1
- ROR:循环右移,移位后将移出的低位补到空出的高位
- RRX:带扩展的循环右移,操作数右移 1 位,移位空出的高位用带 C 标志的值填充
- 示例:
MOV R0, R1, LSL #2
- 上述指令的功能是将 R1 寄存器左移 2 位,即
R1 << 2 后赋值给 R0 寄存器。执行后,R0=R1*4
寄存器间接寻址
- 由地址码给出的寄存器是操作数的地址指针,所需的操作数保存在由寄存器指定的地址的存储单元中
- 示例:
MOV R0, [R1]
- 上述指令的功能是将 R1 寄存器的值作为地址,取出此地址中的值赋给 R0 寄存器
基址寻址
- 指将地址码给出的基址寄存器与偏移量相加,形成操作数的有效地址,所需的操作数保存在有效地址指向的存储单元中
- 多用于查表、数组访问等操作
- 示例:
LDR R0, [R1, #-4]
- 上述指令的功能是将 R1 寄存器的值减 4 作为地址,取出此地址中的值赋给 R0 寄存器
多寄存器寻址
- 一条指令最多可完成 16 个通用寄存器值的传送
- 示例:
LDMIA R0, {R1, R2, R3, R4}
LDM 是数据加载指令,指令的后缀 IA 表示每次执行加载操作后,R0 寄存器自增 1 个字。在 ARM 指令集中,1 个字表示一个 32 位的值。这条指令执行后,R1=[R0],R2=[R0+#4],R3=[R0+#8],R4=[R0+#12]
堆栈寻址
- ARM 处理器特有的寻址方式
- 要用特定的指令完成
- 堆栈寻址指令有:LDMFA/STMFA、LDMEA/STMEA、LDMFD/STMFD、LDMED/STMED。LDM 和 STM 为指令前缀,表示多寄存器寻址,即一次可传送多个寄存器的值。FA、EA、FD、ED 为指令后缀
- 示例:
STMFD SP!, {R1-R7, LR} @将 R1 ~ R7、LR 寄存器入栈,多用于保存子程序现场
LDMFD SP!, {R1-R7, LR} @将数据出栈,放入 R1 ~ R7、LR 寄存器,多用于恢复子程序现场
块拷贝寻址
- 用于将连续地址数据从存储器的某一位置复制到另一位置
- 块拷贝寻址指令有:LDMIA/STMIA、LDMDA/STMDA、LDMIB/STMIB、LDMDB/STMDB。LDM 和 STM 同上。IA、DA、IB、DB 为指令后缀
- 示例:
LDMIA R0!, {R1-R3} @从 R0 寄存器指向的存储单元中读取 3 个字,分别放入 R1 ~ R3 寄存器
STMIA R0!, {R1-R3} @将 R1 ~ R3 寄存器的内容存储到 R0 寄存器指向的存储单元
相对寻址
- 以程序计数器 PC 的当前值为基地址,以指令中的地址标号为偏移量,将二两相加,得到操作数的有效地址
- 示例:
BL NEXT
...
NEXT:
...
- BL NEXT 表示跳转到 NEXT 标号处执行。此处的 BL 采用的就是相对寻址,标号 NEXT 即偏移量
子程序参数传递
- 子程序用于在代码中完成一个独立的功能,功能上等同于高级语言中的函数
- armeabi 中的参数传递有如下约定:
- R0 ~ R3 这四个寄存器用于传递子程序调用的第一到四个参数,多出的参数通过堆栈传递
- R0 寄存器同时用于存放子程序的返回结果,若数据大于 32 位,则将结果存入 R0 和 R1 寄存器
- 被调用的函数在返回前无须恢复这些寄存器的内容
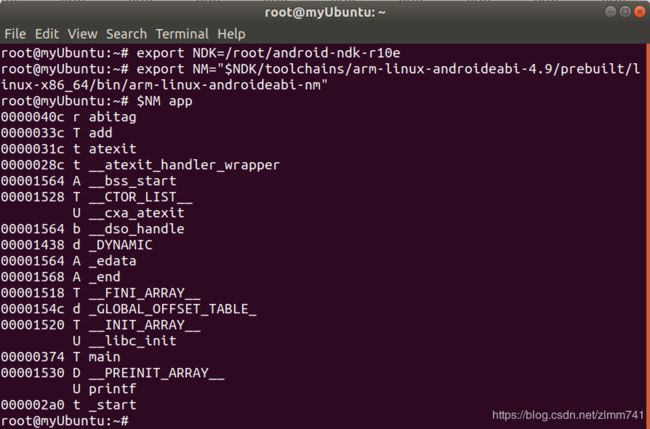
- 前面 app.s 中的 add() 子程序可验证这些约定
- 对于浮点数,armeabi 没提供浮点指令,软模拟的浮点指令为
softvfp
- 示例代码:

- 编译(指定 arch 为 armv5te,这是 armrabi 默认使用的处理器):
- 编译后 add_double() 的代码:
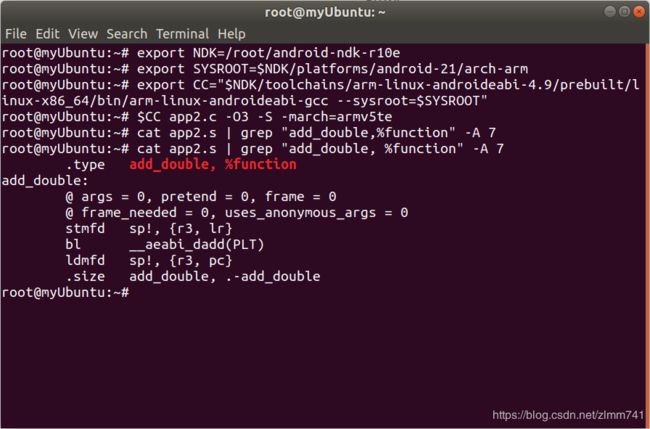
- 可看出,用
softvfp 指令进行软模拟时,若两个浮点数据相加,add_double() 中的浮点数加法由 __aeabi_dadd() 完成,内部的实现由编译器完成。mul_double() 中的乘法,在方法内部由 __aeabi_dmul() 实现
- Thumb 模式下的代码,其参数传递也遵循这个规则,但用的指令不同。执行如下命令,将代码编译成 Thumb 模式并查看其 add_double(),内容如下:

- Thumb 模式不支持 32 位的 stmfd 和 ldmfd 指令,而使用 push 和 pop 代替
- armeabi-v7a 中的参数传递与 armeabi 基本一致,只在浮点指令参数传递上不同。armeabi-v7a 支持硬件浮点指令,具体的浮点运算都交给浮点指令
- 但 armeabi-v7a 下的 gcc 在编译时仍用软浮点模式完成浮点计算,而 Clang 编译器在 armeabi-v7a 架构下默认指定的处理器是 Cortex-A8(第一款 armeabi-v7a 架构处理器),在浮点指令方面用的是 neon 协处理器,可执行如下命令切换为 Clang 编译器,然后查看被编译成 armeabi-v7a 架构的汇编指令:
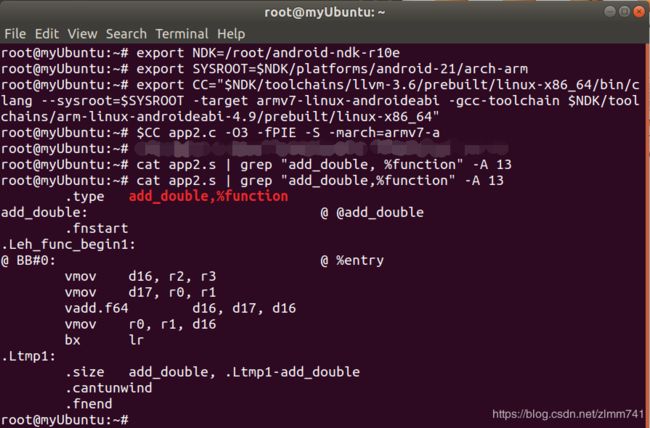
- 在进行浮点运算时,用的是 v 系列的浮点指令
vmov 和 vadd.f64,而在寄存器的使用上,由于浮点数是 64 位的,使用相邻两个寄存器保存一个浮点数复数形式的值。add_double() 中,用 v0 和 v1 存放第一个浮点数,用 v2 和 v3 存放第二个浮点数,用 vmov 指令将两个相邻通用寄存器的值复制到浮点寄存器 d16 和 d17 中,然后用 vadd.f64 指令将其相加,将计算结果 d16 中的值复制到 r0 和 r1 中。此过程和 armeabi 的返回值传递约定吻合
- armeabi-v7a 架构下的 Thumb-2 指令集,其参数传递和返回值存储与 armeabi 一致
- 到了 arm64-v8a,参数的大小与指令的寻址空间发生了很大变化,参数传递的约定也有了扩展
- arm64-v8a 的参数传递约定:
- 对 32 位的整型参数,前八个用 w0 ~ w7 寄存器传递,超出的参数用堆栈传递
- 对 64 位的整型参数,前八个用 x0 ~ x7 寄存器传递,超出的参数用堆栈传递
- 对浮点数计算,前八个用 d0 ~ d7 寄存器传递,超出的参数用堆栈传递
- 调整 CC 环境变量,指定 Clang 编译器生成 arm64 系列的汇编代码,然后查看 add2() 的汇编代码:

- add2() 中共有九个参数,前八个通过 w0 ~ w7 传递,中间的计算结果用 w9 寄存器保存,第九个参数通过访问 sp 寄存器获取
- 接着执行如下命令,查看 mul_double() 的汇编代码:
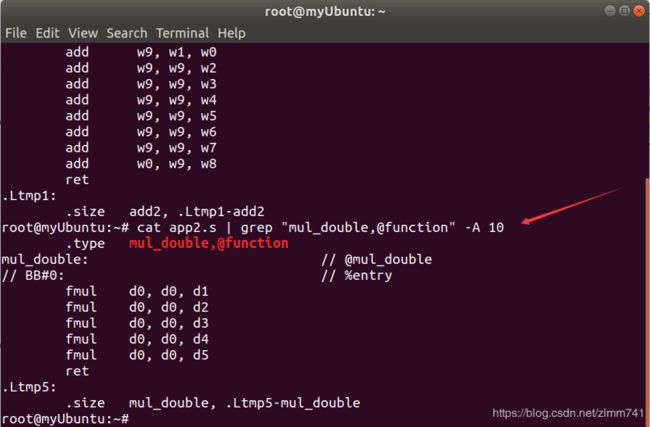
- 浮点运算采用全新的 f 系列浮点指令完成
- mul_double() 中有六个浮点参数,由 d0 ~ d5 寄存器传入,计算结果由 d0 返回