AuTO: 数据中心规模自动流量优化的扩展深度强化学习
本文为SIGCOMM 2018 论文。
笔者翻译了论文的关键内容,如需转载,请联系笔者。
摘要:
数据中心中的流量优化(TO,例如流调度,负载平衡)是难以在线决策的问题。此前,流量优化的启发式方法依赖于运维人员对工作负载和环境的理解。因此,设计和实现适当的TO算法至少几个星期的时间。 近期,应用深度强化学习(DRL)技术解决复杂的在线控制问题取得成功。受此鼓舞,我们研究DRL是否可以用于自动流量优化无需人工干预。 但是,我们的实验表明,在当前数据中心规模下,当前DRL系统的延迟无法处理数据流级流量优化,因为小流(占流量的大部分)通常在做出决定之前完成。
利用数据中心流量的长尾分布,我们开发了一个两级DRL系统(AuTO),模仿动物的外围和中枢神经系统,以解决可扩展性问题。 外围系统(PS)位于终端主机,收集数据流信息,并为小流制定具有最小延迟的本地TO决策。PS的决策由中央系统(CS)通知,中央系统汇聚和处理全局数据流信息。CS进一步为长流做出各自的TO决策。使用CS&PS,AuTO是一个端到端的自动流量优化系统,可以收集网络信息,从过去的决策中学习,并执行操作以实现运维人员定义的目标。 我们使用流行的机器学习框架和商用服务器实现AuTO,并将其部署在由32服务器构成的测试平台上。 相比于现有方法,AuTO将TO时间从数周减少到约100毫秒,同时实现卓越的性能。例如,与现有方案相比,它将平均流量完成时间(FCT)减少了48.14%.
如图1所示,强化学习中,环境(environment)是代理的周边情形,代理可以通过观察,动作和对动作的反馈(奖励)与之交互[55]。 具体地说,在每个时间步骤t中,代理观察状态st,并选择动作at。 然后环境状态转换为st+1,代理收到奖励rt。 状态转变和奖励是随机的和马尔可夫的[36]。 学习的目的是最大化预期的累积折扣奖励E[Σt=0∞γtrt] ,其中γt属于区间(0,1]是折扣因子。
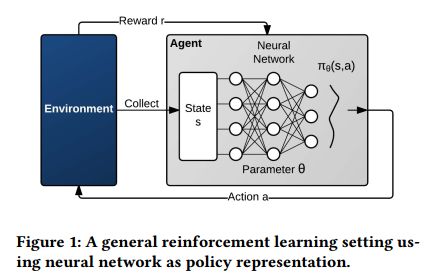
强化学习代理基于策略采取动作,策略是在状态 s时采取动作 a的概率分布: π(s,a)。 对于大多数实际问题,学习状态-动作对的所有可能组合是不可行的,因此函数近似[31]技术通常用于学习策略。 函数逼近器 πθ(s,a)由 θ参数化,其大小比所有可能的状态-动作对的数量小得多(因此在数学上易于处理)。 函数逼近器可以有多种形式。最近,深度神经网络(DNN)已被证明可以解决类似于数据流调度的实际的大规模动态控制问题。因此,我们同样使用DNN作为AuTO中函数逼近器的表示。
利用函数逼近,代理通过在每个时间段/步骤t中用状态st,动作at和相应的奖励rt更新函数参数θ来学习。我们专注于一类更新算法,它通过对策略参数执行梯度下降来学习。学习涉及更新DNN的参数(链路权重),以便可以最大化上述目标。
代理的DNN训练采用了众所周知的REINFORCE算法的变体[56]。 该变体使用等式(1)的修改版本,其减轻了算法的缺点:收敛速度和方差。为了减轻这些缺点,蒙特卡罗方法[28]用于计算经验回报vt,和用于减少方差的基线值(每个服务器的经验奖励的累积平均值)[51]。 由此产生的更新规则(公式(2))被应用于策略DNN,因为它的方差管理和保证收敛至少达到局部最小值[56]:
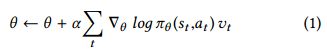

作为例子,我们将数据中心的数据流调度问题形式化表示为深度强化学习(DRL)问题,并描述一个使用基于等式(2)的PG算法的解决方案。
数据流调度问题 我们考虑连接多个服务器的数据中心网络。为简单起见,我们采用以前工作在数据流调度中的大交换机假设[4,14],其中网络是非阻塞的,具有全折半带宽和适当的负载平衡。 使用这个假设,数据流调度问题简化为决定数据流发送顺序的问题。 我们考虑使用严格优先级排队来实现数据流的抢占式调度的实现。 我们在每台服务器为数据流建立K个优先级队列[23],并强制执行严格优先排队。交换机中同样配置K个优先级队列,类似于[8]。 每个数据流的优先级可以动态更改以启用抢占。每个流的数据包都标有其当前优先级数字,并在整个数据中心设施中放入相同优先级的队列。
形式化
动作空间:代理提供的动作是活跃数据流到优先级的映射:对于每个活跃数据流,在时间步骤t,其优先级为pt(f)属于空间[1,K]。
状态空间:大交换机(big-switch)假设使得状态空间极大简化。由于路由和负载平衡不是我们所关心的问题,状态空间只包括数据流状态。在我们的模型中,状态表示为当前时间步骤t时,整个网络中所有的活跃数据流集Fat,以及所有已完成的数据流集合Fdt。 每个数据流由其五元组标识[8,38]:源/目标IP,源/目的端口号和传输层协议。活跃数据流有一个额外的属性,即它的优先级;已完成数据流有两个额外的属性:流完成时间(FCT)和流大小。
奖励:奖励是向代理反馈的所采取的动作的好坏的度量。 奖励可在数据流完成后获得,因此,通过在时间步骤t时已完成数据流集合Fdt上计算得到。每个已完成数据流f的平均吞吐量*Tputf *= Sizef/FCTf。 我们将奖励建模为两个连续时间步之间的平均吞吐量的比值。

它表示先前的动作是否导致更高的每数据流吞吐量,或者降低了整体性能。 目标是最大化整个网络的平均吞吐量。
DRL算法 我们使用由等式(2)指定的更新规则。 代理中的DNN为每个新状态计算概率向量,并通过评估导致当前状态的动作来更新其参数。 评估步骤将先前的平均吞吐量与当前步骤的对应值比较。基于比较,产生适当的奖励(负面或正面),并将其添加到基线值。 从而,我们可以确保函数逼近器随时间得到改善,并且可以通过在梯度方向上更新DNN权重收敛到局部最小值。 遵循公式(2)更新确保对未来的类似状态,差的数据流调度决策被抑制,而好的数据流调度决策的可能性变得更高。当系统收敛时,该策略为服务器集群实现了足够的数据流调度机制。
以数据流调度的DRL问题为例,我们使用流行的机器学习框架(Keras/TensorFlow,PyTorch和Ray)实现了PG算法。 我们简化了DRL代理使其只有1个隐藏层。 我们使用两台服务器:DRL代理位于一台服务器,另一台服务器使用RPC接口向代理发送模拟数据流信息(状态)。 我们将模拟服务器的发送速率设置为1000数据流每秒秒(fps)。我们测量模拟服务器上的不同实现的处理延迟:完成数据流信息发送和接收动作之间的时间。服务器是运行64位Debian 8.7服务器的华为Tecal RH1288 V2服务器,配备4核Intel E5-1410 2.8GHz CPU,NVIDIA K40 GPU和Broadcom 1Gbps网卡。
如图2所示,即使是小的数据流到达率(1000fps)和只有1个隐藏层,所有实现的处理延迟都超过60毫秒。在此期间,任何7.5MB以内的数据流都将在1Gbps链路上完成。供参考,使用众所周知的搜索应用程序和数据挖掘应用程序的数据流trace(收集于微软数据中心[3,8,26])7.5MB的数据流分别大于99.99%和95.13%的数据流。也就是说,大多数DRL动作都是无用的,因此当动作到达时,数据里已经完成了。

总结 目前,DRL系统的性能还不足以为数据中心规模的数据流做出在线决策。 他们即使对于简单的算法和较低的数据流负载,也无法避免过长的处理延迟。
最近的研究[3,11,33]表明数据中心中大多数数据流很短,但大多数字节是属于长流的。 通过这样的长尾分布,我们的关键想法是将大多数短流程操作委托给终端主机,并制定DRL算法,以便为长流生成长期(亚秒)TO决策。
我们将AuTO设计为两级系统,模仿动物的外周和中枢神经系统。 如图3所示,外围系统(PS)在所有终端主机上运行,收集数据流信息,并为小流制定具有最小延迟的本地TO决策。 中央系统(CS)对可以容忍更长处理延迟的长流做出各自的TO决策。 此外,PS的决策由CS通知,CS聚合并处理全局数据流信息。
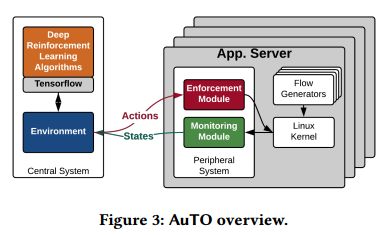
AuTO可扩展性的关键在于使PS能够在仅使用本地信息对短流做出全局通告的TO决策。PS有两个模块:实施模块和监控模块。
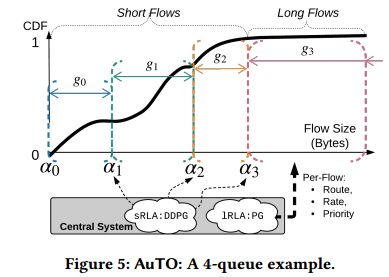
实施模块 为实现上述目标,我们采用多级反馈排队(MLFQ,在PIAS中引入[8])在没有集中的每数据流控制的情况下调度数据流。具体地,在每个终端,PS在每个数据包的IP的DSCP字段中打标签,如图4所示。有K优先级Pi(1≤i≤K),和(K-1)个降级阈值αj(1≤j≤K-1)。 我们将所有交换机配置为基于DSCP字段执行严格的优先级排队。在主机端,当一个新的流程被初始化时,它的数据包被标记为P1,在网络中给予他们最高优先级。 随着更多字节的发送,该流的数据包将标记为较低的优先级Pj(2≤j≤K),从而在网络中使用较低的优先级对它们进行调度。 优先级从Pj-1到Pj的降级阈值是αj-1。

使用MLFQ,PS具有以下属性:
- 仅依靠本地信息(发送字节和阈值)做出立即做出决策。
- 它可以适应全局数据流变化。 为了可扩展,CS不能直接控制小流。 相反,CS使用长时间内的全局信息优化和设置MLFQ阈值。 因此,PS中的阈值可以被更新是以适应数据流变化。 相比之下,PIAS [8]需要数周的数据流trace才能更新阈值。
- 它自然地将短流和长流分开。 如图5所示,短流在最初的几个队列中完成,长流进入最后一个队列。 因此,CS可以集中处理长流,以确定路由,速率限制和优先级。
监控模块 为了使CS生成阈值,监控模块收集所有已完成数据流的流大小和完成时间,以便CS更新数据流大小分布。 监控模块还报告正在进行的已经降到最低优先级的长流,以便CS可以做出各自决策。
MLFQ的挑战之一是在终端为K个优先级队列计算最佳降级阈值。 之前的工作[8,9,14]提供了用于优化降级阈值{α1,α2,...,αK-1}的数学分析和模型。 Bai等人在文献 [9]中也建议每周/每月用收集的数据流级trace重新计算阈值。 AuTO更进一步,提出了一种优化α值的DRL方法。 与以前的将深度学习用于处理数据中心问题的工作不同[5,36,60],AuTO是独一无二的,因为其目标 是在连续动作空间中优化实数值。 我们将阈值优化问题形式化表示为DRL问题,并尝试探索DNN用于建模复杂数据中心(计算MLFQ阈值)的能力。
代理遵循由向量θ参数化的策略πθ(a|s),并通过经验改善它。但是,REINFORCE和其它常规PG算法只考虑随机策略πθ(a|s)=P [a|s;θ],它根据由θ参数化的动作集A的概率分布由状态s中选择动作a。 PG不能用于值优化问题,因为值优化问题计算实数值。因此,我们使用确定性策略梯度的变体(DPG)[53],用于近似最优值{a0, a1, ..., an},对于给定状态s,使得ai =μθ(s) (i = 0, ..., n)。图6总结了随机和确定性政策之间的主要区别。 DPG是一种确定性策略的actor-critic[12]算法,它维护一个参数化的actor函数μθ用于表示当前的策略,以及一个使用Bellman方程式(如Q-learning [41])更新的critic神经网络Q(s,a)*。我们使用公式(4,5,6)描述该算法:actor对环境进行采样,并根据公式(4)其更新其参数θ。公式(4)的结果来自于事实:该策略的目标是最大化预期累积折现奖励公式(5),并且其梯度可以用下面的等式(5)表示。更多详情请参阅[53]。


深度确定性策略梯度(DDPG)[35]是DPG算法的扩展,其使用深度学习技术[41]。我们使用DDPG作为我们优化问题的模型,并在下面解释它如何工作。与DPG相同,DDPG也是一种actor-critic[12]算法,它维护着四个DNN。两个DNN(critic QθQ(s,a)和actor Qθu(s,a),分别具有权重θQ和θu),它们使用大小为N的小批量样本训练。样本中的项目代表经经历转换元组(si, ai, ri, si+1),而actor与环境互动。 这两个DNN使用随机样本训练,样本存储在缓冲区中,以避免导致DNN分支的相关状态[41]。另外两个DNN(目标critic u'θ和目标critic Q'θQ'(s,a)),分别用于平滑更新actor和critic网络(算法(1)[35])。更新步骤使actor-critic网络的训练稳定,并在连续空间动作中实现最先进的结果[35]。 AuTO使用DDPG优化阈值以实现更好的数据流调度决策。
actor:actor有两个完全连接的隐藏层,分别有600和600个神经元,输出层有K-1输出单元(每个阈值一个)。 输入层的输入是状态(每个服务器700个特征(ms = 100))。输出时间t时终端服务器的MLFQ阈值。
critic:critic包括三个隐藏层。因此,相比之下,其网络比actor网络复杂一些。 因为critic应该“批评”actor网络的不良决策,并“赞美”actor网络的好的决策,critic网络应该将actor的输出作为其输入。 然而,如[53]所示,critic的输出不是直接输入,而只能输入critic网络的隐藏层。 因此,critic有两个与actor相同的隐藏层和一个额外的隐藏层,用于连接actor的输出和它第二个隐藏层的输出,导致一个额外的隐藏图层。 这个隐藏层最终将被送入由1单元组成的输出层,其输出是观察/接收状态的近似值。
对于lRLA,我们也使用Keras来实现PG算法,其是完全连接的NN,包含10个隐藏层,每层300个神经元。 RL代理采用状态(136个功能每服务器(nl = 11,ml = 10))作为输入,并输出所有活跃数据流的动作的概率。
评估结果总结
- 同质:对于具有固定数据流大小分布和负载的数据流,AuTO生成的阈值会收敛,并且标准启发式方法相比,表现出相似或更好的性能,平均FCT降低高达48.14%。
- 空间异构:我们将服务器分为4个集群; 每个集群配置为生成具有不同数据流大小分布和负载的数据流。 在这些实验中,AuTO生成的阈值也会收敛,且平均FCT减少高达37.20%。
- 空间和时间异构:建立在上面的场景之上,我们定期更改每个集群的数据流大小分布和负载。对于时变数据流大小分布和负载,AuTO展示学习和适应行为。 相比固定的启发式方法(仅适用于某些组合的数据流设置),AuTO在所有组合下表现出稳定的性能改进。
- 系统开销:当前的AuTO实现可以在平均10毫秒内响应状态更新。就CPU利用率和吞吐量下降而言,AuTO还表现出最小的终端主机开销。