视频检索——BLSTM(论文翻译、理解)
视频检索BLSTM方法论文翻译
- 摘要
- 1 介绍
- 2 相关工作
- 3 自监督时序哈希
- 3.1 时序感知的哈希函数
- 3.2 二进制的LSTM
- 3.3 学习目标
- 3.4 框架细节
- 4 二进制优化
- 4.1 二进制求导
- 4.2 算法细节
- 5 实验
- 5.1 数据集
- 5.2 实验设置
- 5.3 结果分析
- 6 结论
Play and Rewind: Optimizing Binary Representations of Videos by Self-Supervised Temporal Hashing
Hanwang Zhang, Meng Wang, Richang Hong, Tat-Seng Chua
摘要
本文致力于用哈希方法将视频编码为简短的二进制码,以支持高效的基于内容的视频检索(CBVR),这是支持网络访问数量日益膨胀的视频的一项关键技术。现有的视频哈希函数基于三个互不相关的步骤:帧合并,松弛学习和二值化,这就无法充分利用视频帧在联合的二进制优化模型中的时序信息,导致严重的信息丢失。本文提出了一种新颖的无监督视频哈希框架,叫做自监督时序哈希(SSTH),能够以一种端到端的哈希学习方式捕获视频的时序性质。SSTH的哈希函数是一个RNN编码器,RNN配有本文提出的二进制LSTM(BLSTM),能够为视频生成二进制码。哈希函数由一种自监督方式学习得到,其中提出了一个RNN解码器来重建视频(正序和倒序)。为了二进制编码优化,本文用一个反向传播机制来应对BLSTM的不可导,它使得高效的深层网络学习免于二值化损失。在YouTube和Flickr的两个真实的用户视频数据集上实验,SSTH的表现均优于目前最优的哈希方法。
PS:关于哈希学习
1 介绍
基于内容的检索是很多多媒体应用的关键,以视觉内容为基础的大数据索引与查询。基于内容的图片检索目前已经得到大量研究,与之不同的视频检索尚未受到足够的注意。然而随着移动视频捕捉设备的普及,视频越来越多……(其他背景略去)。
视频不光光是一些帧。然而,目前视频分析工作通常会通过丢弃帧序列的时序特征,将多个帧级特征合并为单个视频的特征。当使用诸如CNN响应和运动轨迹之类的高维帧级特征时,这种帧包退化效果很好,因为在合并后,以高维编码的特定时序信息可以保留下来。但是,对于大规模的CBVR,其中需要将这些高维特征进行哈希处理(或进行索引处理)转变为简短的二进制代码时,由帧合并引起的时序信息丢失将不可避免地导致视频的次优编码(就是说不是最好的编码)。时序信息丢失通常发生在哈希函数学习的过程中,也就是帧合并的后一步;与主要的视频外观(例如,对象,场景和短期运动)相比,细微的视频动态(例如,长期事件演化)在哈希处理过程中急剧的特征降维时,更可能被当成噪声被丢弃。
我们认为造成上述缺陷的主要原因是时序合并和哈希码学习步骤都无法充分利用视频的时序本质。为此,我们提出了一种新的CBVR视频哈希方法,称为自监督时序哈希。 简而言之,SSTH是一种将m帧视频编码为单个k位二进制码的端到端系统。 本文着重介绍使得SSTH有效且与其他视频哈希方法不同的三个关键特征:
自监督
大多数现有的无监督哈希方法都不具备时序感知能力,因此失去长期的视频动态。因此,我们探索了另一种无监督哈希方法:如何利用视频的帧顺序自监督二进制代码学习?为此,我们在编码器-解码器RNN框架内提出了一种称为“播放和倒带”的策略——在RNN哈希函数对视频进行编码之后(即“播放”),当且仅当同时成功地编码了视频的外观和动态效果时,输出的哈希码才能以特定的顺序解码这些帧(即“倒带”)。
时序感知
SSTH的哈希函数通过使用RNN精确地对帧的时间顺序进行编码,RNN在序列建模中特别有效。我们提出了一个新的循环模块,称为二进制长短时间记忆网络(BLSTM),其中视频在 t 时的二进制编码是在 t-1 时编码的函数。带有BLSTM的RNN以原则性的方式统一了时序建模和视频哈希方法,这样二进制编码有望捕获整个视频的长期动态。
优化的视频二进制表示
由于二进制编码学习的问题本质上是NP难,因此现有的视频哈希方法通常遵循三个阶段的过程:合并,松弛和二值化。步骤之间互不相关使得这些方法不理想。在提出的SSTH框架中,我们将时序建模和二进制编码学习转换为一个联合模型。我们开发了一种二进制反向传播机制,该机制可以解决SSTH的二进制性质而不会产生任何松弛。 这样,SSTH可以视为一个用于优化从视频到二进制编码转换的端到端无监督学习框架。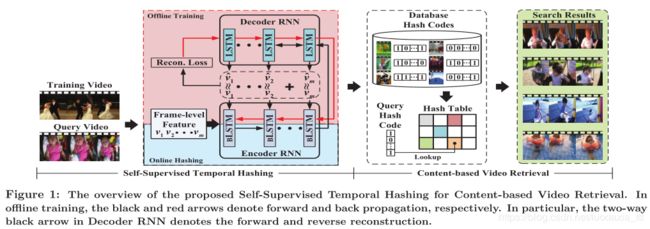 在离线训练阶段,训练视频由一系列帧级特征(深层CNN提取)表示。带有BLSTM的编码器RNN遍历该序列,生成一组哈希码,然后解码器RNN对其进行解码,以正向和反向顺序重建帧级特征序列。在优化过程中,重构误差会通过整个编码器/解码器RNN反向传播。在线检索阶段,可以将编码器RNN视为时间感知哈希函数,该函数为数据库视频和查询视频生成二进制哈希码。最后,将数据库哈希码索引到哈希表中以进行实际检索。
在离线训练阶段,训练视频由一系列帧级特征(深层CNN提取)表示。带有BLSTM的编码器RNN遍历该序列,生成一组哈希码,然后解码器RNN对其进行解码,以正向和反向顺序重建帧级特征序列。在优化过程中,重构误差会通过整个编码器/解码器RNN反向传播。在线检索阶段,可以将编码器RNN视为时间感知哈希函数,该函数为数据库视频和查询视频生成二进制哈希码。最后,将数据库哈希码索引到哈希表中以进行实际检索。
本文的贡献如下:
1)我们提出了一种新颖的无监督视频哈希框架,称为自监督时序哈希(SSTH)。据我们所知,SSTH是第一个原则上的视频哈希深度框架。它是一种优化的端到端方法,可以解决常规视频哈希方法中的缺点,例如对时间性质的忽视以及对合并,松弛和二值化的分离。
2)我们开发了一种名为二进制LSTM(BLSTM)的新型LSTM变体,它充当了时序感知哈希函数的基础。我们还开发了有效的反向传播机制,可以直接解决BLSTM二进制优化所面临的难题,而无需任何松弛。
3)我们通过结合前向和反向帧重建改进了传统的一阶编码器-解码器RNN。我们的策略是一种新颖的无监督学习目标,可以更好地对数据的时间性质进行建模。
值得一提的是,尽管SSTH是为视频哈希开发的,但实际上它是一个灵活且通用的框架,可以扩展以处理其他信号序列(如音乐和文本)的哈希问题。
2 相关工作
略
3 自监督时序哈希
在本节中,我们对提出的自监督时序哈希(SSTH)框架进行公式推导。首先,我们介绍提出的时序感知哈希函数,该函数为视频序列生成单个压缩的二进制编码。然后,我们提出了一种新型循环单元BLSTM,它是哈希函数的基础。最后,我们引入提出的用于哈希学习的自监督策略及其深度架构。
3.1 时序感知的哈希函数
假设一个由m帧构成的视频序列表示为矩阵V=(v1,…,vm)∈R(d×m),其中第 t 帧用一个特征向量vt∈R(d)表示。我们的目的是找到一个哈希函数H:V∈R(d×m)→ bm∈{±1}k,(也就是把矩阵V映射到k位二进制码bm,±1序列加一再除以2就变成01序列了),k<
很自然地想到用RNN来满足上述时序感知的要求,循环单元的第 t 次输出bt可以用一个非线性函数 f 来表示,函数的输入包括上一次循环单元的输出bt-1和当前帧vt。
![]()
因此,视频V的结果二进制编码可以通过循环生成
![]()
以RNN风格来设计 f 对哈希函数而言是关键的。长短时间记忆网络(LSTM)近来在序列学习任务上很厉害,因为它能够处理深度RNN的梯度消失、爆炸问题。问题是原始的LSTM只能生成实值隐藏变量,不能生成二进制码,也就是
![]()
为修改LSTM使其能够生成二进制编码,最直接的方法就是用一个符号函数对实值隐藏变量进行二值化,即bm=sign(hm),其中
(sign(x)=1 if x ≥ 0 else -1)。但是,我们认为它本质上还是基于帧合并的,其中合并函数是RNN:尽管合并是时序感知的,哈希码本身并不能直接捕获视频的时间特性。
3.2 二进制的LSTM
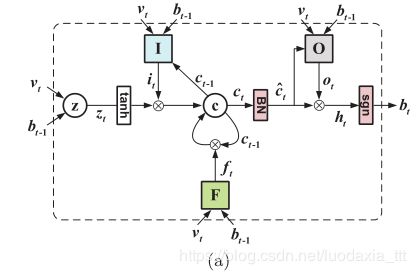
为了设计一种哈希函数,该哈希函数不仅继承LSTM的数值稳定性,而且还生成二进制代码,我们提出了一种LSTM的新颖变种,称为Binary LSTM(BLSTM)。如图2(a)所示,BLSTM遵循与LSTM类似的数据流。首先,通过对当前特征 vt 和上一个二进制代码 bt-1 的线性组合进行tanh压缩来计算输入变量zt。然后,用 ct-1 应该忘掉多少旧知识和 zt 应该记住多少新知识的和来更新 ct 。注意这种累积的记忆更新设计使导数可以按总和分配,因此,随着时间的推移进行反向传播时,错误不会迅速消失。然后,对记忆进行批量归一化(BN)。最终,哈希编码 bt 就是 ht 应该输出多少当前知识的二值化结果。前面提到的行为忘记、记住、输出分别由三个门限变量F、I、O控制。它们是逐个元素地应用的,因此,如果门限为1,则可以保留门限变量中的值,如果门限为0,则可以丢弃值。所有门限变量:it,ft 和 ot 都用sigmoid函数σ作为通过概率的估计。BLSTM的详细实现公式如下:
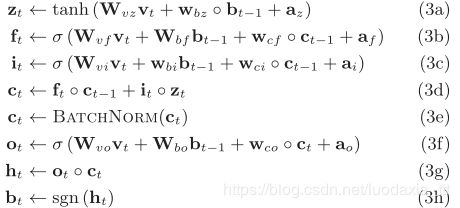
○ 表示按元素乘。
接下来谈谈相比LSTM而言,BLSTM的两个新颖之处。
二值化
使得BLSTM生成±1的二进制输出。不同于流行的vanilla LSTM中的 ht ← ot ○ tanh(ct),在进入符号函数之前我们移除了对 ct 的tanh压缩,如等式(3g)所示。直观上看,因为sgn只关心 ht 的符号,所以没必要将输入压缩为[-1,+1]。实际上,由于tanh的梯度始终不为零,输入中的任何细微变化都会修改记忆单元 ct 中的大多数条目。因此,像我们将在第4.1节中讨论的那样,当删除 ct 之前的tanh时,小的输入更改将不会修改记忆单元的值,只要它们的符号已经确定,例如| ct | > 1。这样,BLSTM可以被认为是一种稀疏模型,可以为数据变动和有效训练提供更好的解决能力。
批归一化
这在消除深度神经网络中的分层协方差偏移方面很有效。他让 ct 归一化为均值为零、方差为1的高斯分布,然后经过一个线性变换:ct ← ( ct - μt )/ σt , ct = γ1 ct + γ2 ,其中 ct 是 ct 的一项, μt 和 σt 是小批量训练数据在 t 时刻的均值和无偏方差。在测试时, μt 和 σt 是从整个训练数据中估计出来的。用矩阵 Ct 表示小批量训练数据,BN近似了约束C
![]()
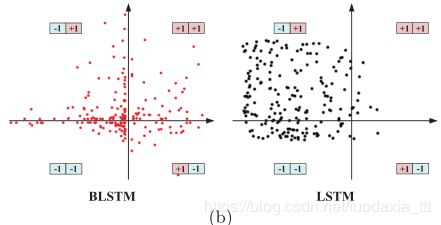
分别表示结果编码 Bt =sgn( Ot ○ Ct )的去相关性(即每一位应尽可能独立)和平衡性(即每一位应尽可能平衡地分割数据)。实际上,这些约束条件可以最大化二进制编码中的信息熵,即BN帮助BLSTM产生信息性二进制编码,如图(2b)所示。
3.3 学习目标
我们使用视频序列的时序作为哈希学习的自监督。本质上,学习目标属于RNN编解码器框架中的无监督序列学习。我们按以下方式实现该框架。首先,具有BLSTM的编码器RNN遍历视频序列 (v1,…,vm) 得出一串哈希码bm。 然后,由两个独立的带有LSTM的RNN组成的解码器:正向和反向重建RNN,分别将哈希码以正向顺序 (v1,…,vm)加上波浪线 ~ 和逆序 (vm,…,v1) 加上帽 ^ 重建输入帧的特征。具体来说,我们对解码器LSTM的输出采用线性重构:
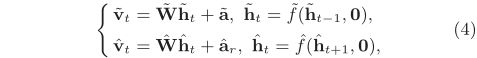
其中W和a是正向、反向重构的参数。两个 f 分别是是正反向LSTM的函数,h0 = bm 或者 hm = bm 表示解码器从哈希码开始,0 强调了解码器RNN不采用任何输入特征,阻止解码器学习直接来自输入的细微重构。结果,编码器被要求去生成能够保留足够信息用来重构的二进制编码。
提出的正向和反向RNN专注于学习视频不同方面的动态特性。一方面,前向RNN试图记住长期事件的演变,因为从第一帧开始的重建将鼓励记忆不要忘记太多关于早期帧的信息。 另一方面,反向RNN更有可能捕获视频语义(例如,对象和运动变化)之间的短期时间关系,因为如果记忆拥有关于最近帧的足够信息的话,从最后一帧开始(刚刚看过的帧)的重建将会是一项相对容易的任务。 基于以上分析,SSTH的总体损失函数可以表示为:
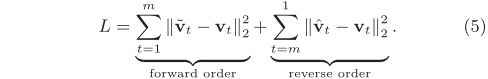
然而,由于深度嵌套的二进制码(b1,…,bm)是不可微的,因此最小化上述损失函数是有挑战性的。稍后,我们将介绍一种基于二进制代码反向传播的有效二进制优化方法。
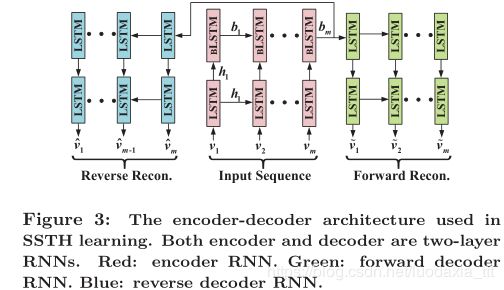
3.4 框架细节
SSTH的详细架构如图3所示。编码器和两个解码器均采用两层结构,以增强模型的表达能力。 在编码器方面,第一层是常规的vanilla LSTM,其中输出隐藏变量h用作第二层BLSTM和下一个LSTM的输入。具体而言,h的维数是2k,即二进制编码长度的两倍。通过这样做,可以将编码器的第一层LSTM视为帧的高级特征提取器。在对哈希码bm进行编码(即最后一帧的BLSTM输出)之后,我们将其直接输入到两个解码器RNN的第一层。
在解码器方面,第一层和第二层的维数分别为k和2k。具体而言,线性变换将第二层的2k维隐藏变量重构为d维的帧级特征。请注意,这与[27]不同,后者将两层编码器的输出对齐到两层解码器的输入。原因是我们要限制解码器获取其他来源的信息,例如编码器的第一个隐藏层,以鼓励哈希码保留更高级别的视频动态信息。还应注意,编码器LSTM-BLSTM,正向和反向解码器LSTM-LSTM的可训练参数彼此独立,因为三个RNN负责不同的目的。
4 二进制优化
带有BLSTM的SSTH训练本质上是NP难的,因为它涉及对哈希码的二进制优化,这需要组合搜索空间。然而,通过舍弃二进制约束的近似解将导致较大的量化损失。在本节中,我们提出直接解决具有挑战性的二进制优化问题。我们首先介绍如何求sgn二值化的导数,然后详细介绍学习算法。
4.1 二进制求导
由于BLSTM中sgn函数的导数几乎在任何地方都是零,因此无法对BLSTM应用精确的反向传播。 在这里,我们提出一种近似方法,通过估计sgn函数的导数。
实际上,可以将sgn生成的二进制编码视为二进制分类结果,其中分类器响应为ht。因此,sgn(ht)是一组隐藏的分类器,它们共同为最终目标做出预测,例如,在我们的案例中为重建损失。基于此观点,我们的关键思想是设计一个委托分类器 d,该分类器通过允许一定的损失来近似原始分类器sgn。在不失一般性的前提下,我们仅考虑等式(3h)中 ht 的单个条目h:
- 当h≥0,我们通过允许一定的分类误差,用 d (h) 来近似sgn(h)=1:
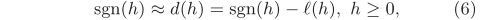
其中 l(h) ≥0是损失函数。由于h≥0,我们可以将其视为正标签+1的得分。实际上,当 l(h) =1 (1·h≤0)时,d (h)=sgn(h),即如果响应h和标签+1一致则损失为零。但是,这样的0-1损失是无用的,因为我们限制了h≥0。 “软化”这种“硬的”(???)的0-1损失的主流方法是使用带有余量的铰链损失函数:l(h)=max(0,1-1·h),这在大余量的分类器如SVM中应用广泛。具体而言,当0≤h≤1时,它允许对理想响应+1的某种违反 1 −(+1)·h。(6)可以改写为:
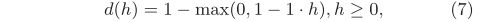
- 当h < 0时,类似于以上分析,我们可以将其视为否定标记-1的得分。通过使铰链损耗达到理想的二进制响应-1,sgn(h)= -1可以近似为:
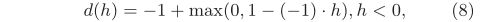
当−1≤ h <0时,允许违反1 + h。
结合等式(7)和等式(8),sgn(h)的近似结果可以写成:
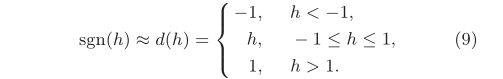
至此。我们可以将sgn(h)的导数定义为:
![]()
图4说明了我们如何使用铰链损耗来近似sgn函数。
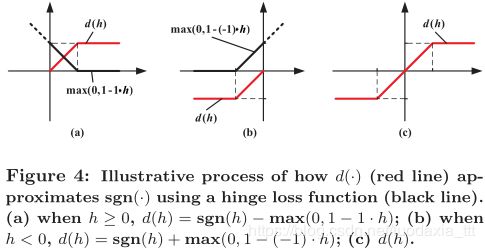
导数d’(h)表达了BLSTM的简单反向传播规则:当梯度回传到sgn函数时,我们仅允许其神经响应在[-1,+1]之间的梯度通过。直观地,如果隐藏值h相对于余量没有很好地分开,则此规则使得BLSTM能够更新,从而让哈希函数的二进制化更加准确。实际上, d’ 可以被认为是一个“直通式估计器”,这在SGD中已用于离散神经元。虽然 d’ 不是sgn的精确梯度,但是可以实现SGD的收敛。
4.2 算法细节
得益于式(10)中引入的sgn函数的导数,我们现在准备研究正向传播(FP)和反向传播(BP)来训练深度RNN。由于篇幅所限,我们仅概述关键组件FP和BP:BLSTM。

用于BLSTM的FP算法说明。为了简化符号,我们将BLSTM分为四个步骤:
- 从式(3a)到(3d),由α参数化的子例程BLSTMHEAD。注意输入vt 可以是视频特征或者LSTM的第一层。
- 式(3e),由γ参数化的子例程BatchNorm,用来做批归一化。
- 从式(3f)到(3g),由β参数化的子例程BLSTMTAIL。
- 式(3h),二值化。

BLSTM反向传播的说明。输入∇bm =∂L/ ∂bm 是式(5)的损失函数L对哈希编码bm 的导数。第2行是根据式(10)的二值化BP。然后,从第3行到第9行,我们假定三个梯度子例程可用:BLSTMheadBP,BLSTMtailBP和BatchNormBP。注意4、6和9行是使用链规则更新的模型参数的梯度。
将FP和BP应用于一小段训练视频后,我们使用SGD更新具有动量(momentum)和动态学习率(lr)的模型参数{α,β,γ}。将帧长度表示为 l,将帧级特征维数表示为d,将哈希码位数表示为k,将SGD批处理大小表示为B,很容易看出,对于FP和BP,算法复杂度需要O(Bdkl),而哈希码的生成需要O(1/2 Bdkl)。 因此,训练和测试时间与帧长、位数、采样大小成线性关系。具体而言,表1列出了在TITAN X GPU上训练/测试LSTM和BLSTM之间的时间消耗比较。由于引入了批次归一化,我们只需要为BLSTM提供一些开销。
5 实验
由于SSTH是一种新颖的自监督视频哈希框架,因此我们的实验目标是回答以下三个研究问题:
RQ1:SSTH为什么要按照我们的提议进行设计?它的不同部分如何影响性能?
RQ2:与其他视频哈希方法相比,SSTH的性能如何?
RQ3:SSTH的泛化能力怎么样,例如,训练较少的数据和跨数据集的性能?
5.1 数据集
我们使用两个具有挑战性的大型视频数据集进行无监督的训练和检索。
FCVID。这是复旦-哥伦比亚视频数据集。FCVID是用于视频分类的最大数据集之一,具有通用领域中的准确人工注释。该数据集包含根据239个类别人工注释的91,223个Youtube视频,涵盖了诸如事件(例如“尾巴聚会”),对象(例如“熊猫”)和场景(例如“海滩”)之类的广泛主题。平均视频时长约为167秒。它的训练/测试拆分为45,611 / 45,612。 我们将训练拆分用于无监督学习,并将测试拆分用于检索。
YFCC。这是Yahoo Flickr Creative Common数据集,这是有史以来发布的最大的公共多媒体数据集。Flickr正式发布了80万个视频,但是,过滤掉无效的网址和损坏的视频文件,我们仅收集了700882个视频。平均视频时长约为37秒。我们还为社区提供了一个大型视频场景数据集,该视频场景数据集是从YFCC中选择的100,000个视频,并根据MIT SUN secene层次结构的第三层中主流的80个场景进行了手动注释,例如室内(例如,“咖啡”商店”)和户外(例如“高尔夫球场”)。我们使用未标记的600882视频进行无监督学习,其余100,000标记的视频进行检索。
请注意,与FCVID(专业人士拍摄大量YouTube视频)不同,YFCC视频主要来源于Flickr休闲用户的手机拍摄。因此,YFCC视频的视觉质量要低得多,因此对视频内容的理解更具挑战性。对于每个视频,我们统一采样25帧作为视频序列。我们的SSTH是一个非常深的RNN,展开后具有75层(即25层编码器,25层前向解码器和25层反向解码器)。尽管我们将帧数设置为25,作为训练时间和GPU内存的折中,但我们相信更高的帧频将使得模型更强大。对于每一帧,我们使用VGG-fc19提取4096维CNN特征作为帧级表示。请注意,我们并未使用诸如密集轨迹[31]之类的运动功能,因为我们打算研究它们是否可以通过对序列进行建模来捕获视频动态。
5.2 实验设置
5.2.1 评估指标
我们在前K个检索的视频(AP @ K)中采用了平均精度,以评估检索性能。用R表示为数据库中相关视频的数量。在任意排名位置 j(1≤j≤K)处,Rj 为前 j 个结果中相关视频的数量,如果第 j 个视频相关,则 Ij = 1,否则为0,则AP@K定义为
![]()
对于每个类标签,我们将属于该标签的每个测试视频视为查询查询,并将其余测试数据视为数据库;然后,我们使用查询视频的AP@K的平均值(mAP@K)作为标签的性能指标。 我们还略微滥用了mAP @ K,将其作为所有特定标签的mAP@K的平均值。
5.2.2 搜索协议
我们采用了两种在二进制代码搜索中广泛使用的搜索协议。我们评估了代码长度k∈{8,16,32,64,128,256}。
汉明排序: 根据与查询视频的汉明距离(或相似度)对视频进行排名。尽管汉明排名的搜索复杂度仍然是线性的,但是在实践中它是非常快的,因为汉明距离的计算可以通过快速位异或操作完成,并且由于整数距离,排序时间是恒定的。
哈希表查找: 使用视频哈希码构建查找表,并返回与查询视频汉明半径较小的(例如2)的表中所有项。因此,搜索是在固定时间内执行的,但是,当代码长度大于32时,单个表将不够用,因为它将需要超过O(232)的空间才能将表存储在内存中。我们采用了多索引哈希(MIH)表,该表为每个代码子段构建一个表。所有表汇总各个项,然后对每一项进行汉明排名。通过这样做,搜索时间显着减少到亚线性。我们根据经验[19]中的建议,将位大小为{8,16,32,64,128,256}的子串长度设置为{1,1,1,2,4,8}。
值得一提的是,以上两种搜索协议侧重于哈希码的不同特性。排序可以更好地衡量学习的汉明空间,即代码可以线性扫描整个数据,因此可以达到的更高的精度上限。另一方面,查找强调了大规模搜索的实用速度,但是该协议的一个普遍问题是它可能不会返回足够的项以进行推荐,因为由于稀疏的汉明空间,查询查找可能会丢失项。在我们的实验中,如果查询没有返回视频,我们会将其视为AP值为零的失败查询。
5.2.3 方法对比
为了验证提议的SSTH的体系结构设计,我们比较了以下可能的体系结构,这些体系结构也可以看作是时间感知的哈希方法:LSTM,LSTM-sgn,Enc-sgn,SSTH-F/R,SSTH-1/2,ITQ,SubMod,MFH,DH (详见原文吧。)
尽管还有其他视频哈希算法,但它们要么基于监督哈希,要么基于专门的非二进制哈希码,因此不适用于我们的可比实验。 对于DH和SSTH等深层模型,我们使用了带有Theano实现的TITAN X GPU。 所有深度模型的最小批量大小设置为50,训练30次。
5.3 结果分析
5.3.1 框架研究(RQ1)
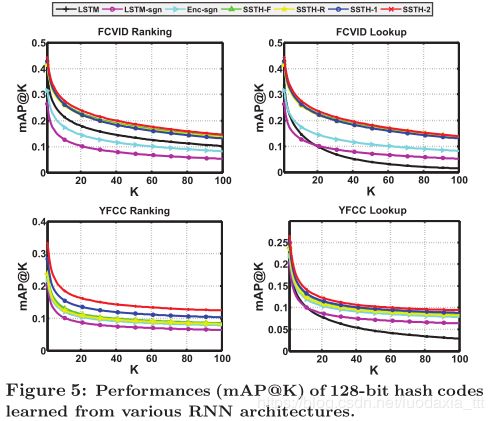
图5显示了SSTH的可能设计如何影响整体性能。由于篇幅所限,我们仅报告128位代码的结果。从这两个数据集的结果,我们可以得出以下观察结果:
1)使用LSTM查找表时,只有LSTM会导致相当大的性能下降,因为它是唯一的具有较大量化损失的两阶段方法。相反,我们没有观察到使用二进制反向传播(联合框架)的其他模型的性能显着下降。
2)通过天真的为LSTM添加sgn函数,LSTM-sgn达到了最差的结果,这是因为缺少第3.2节中讨论的批处理规范化:如果没有批处理规范化,则隐藏变量很可能不平衡和相关,例如一些隐藏变量可能不在[-1,1]范围内。因此,零梯度将导致哈希码过早地成形。
3)诸如SSTH-F / R / 1/2之类的时间哈希模型优于Enc-sgn,后者仅在编码器的末尾部署了二值化。这证明了等式(1)中定义的时间感知设计的有效性。
4)通过结合正向和反向重建,SSTH-1优于SSTH-F和SSTH-R;
5)通过添加更多层,SSTH-2可以增强SSTH的表达能力。因此,基于以上观察,我们证明了SSTH特殊设计的有效性。
5.3.2 与主流方法对比(RQ2)
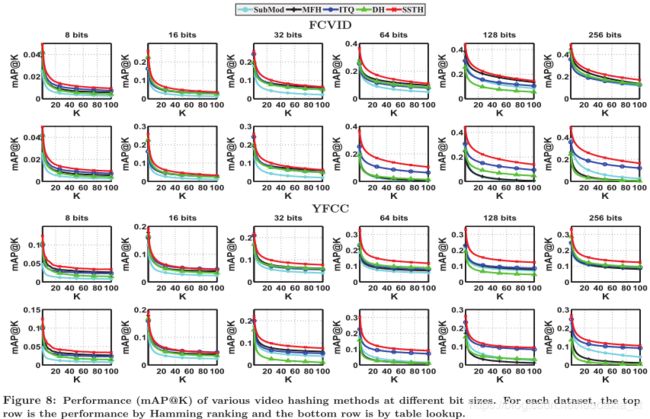
图8显示了SSTH与最新的视频哈希方法相比的性能。 我们可以看到SSTH在两个数据集上始终表现最佳。 具体来说,我们有以下观察结果:
-
与诸如SubMod,MFH和ITQ的基于池的哈希方法相比,SSTH准确地对视频的时间信息进行建模。 例如,在FCVID上,仅使用128位,SSTH即可达到24.5%的mAP @ 20,这与使用256位的最具竞争力的MFH的25.1%相当。
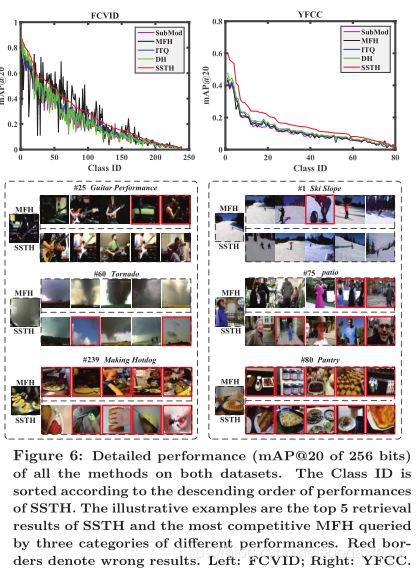
图6详细说明了在两个数据集上使用256位的各种方法的mAP@20。我们可以看到,对时间信息进行建模有助于区分涉及人为行为的概念,例如FCVID中的“吉他演奏”。更有趣的是,我们可以观察到SSTH在YFCC的场景检索任务上始终优于基于合并的方法。这表明视频的时间信息不仅对于事件至关重要,而且对于识别场景也是必不可少的。以图6中的YFCC“滑雪坡”为例,像MFH这样基于池的方法将不可避免地将“雪”的帧误分类为“滑雪坡”,而SSTH成功捕获了信息丰富的“滑雪”运动。 -
但是,我们应该注意,基于合并的方法(例如MFH)也很强大,尤其是对于不太可能由时序信息区分的视频类别。如图6所示,对于FCVID中的“龙卷风”类别而言,仅捕获视觉外观的MFH似乎足够了。而SSTH过分强调了云的运动。作为另一个示例,SSTH过度适合YFCC“露台”中单个自拍照的运动,因此比MFH表现差。我们还为所有方法找到了一些困难的案例。一个例子是与食物相关的事件,例如FCVID“制作热狗”,其中MFH偏向于“食物”的一般概念,而SSTH则更喜欢“制作”的动作,例如“指甲油”和“切土豆”。另一个示例是YFCC“ Pantry”,其中MFH和SSTH都偏向于“华夫饼”的外观。
- DH也试图捕获时间信息,但其性能要比SSTH甚至是某些基于合并的方法(例如MFH和ITQ)差很多。原因类似于以前的实验中Enc-sgn的表现比SSTH差的原因:尽管DH利用RNN来建模帧的时间顺序,但由于哈希码不是像公式(1)定义那样是时序感知的,因此它本质上是基于合并的哈希方法。
- 如图8所示,当使用哈希表查找执行检索时,宽松的方法(SubMod,MFH和DH)使用较长的哈希码(例如128位和256位)会导致性能显着下降。这证明了ITQ和SSTH中采用的二进制优化对于最小化二值化损失的有效性。
5.3.3 泛化能力(RQ3)
泛化能力对于哈希学习方法特别重要,因为与训练数据相比,用户提供的查询通常是域外的。因此,重要的是要调查SSTH在给定的训练数据有限的情况下如何执行,以及SSTH如何推广到跨数据集检索任务,例如,在FCVID上进行训练但在YFCC上进行测试,反之亦然。
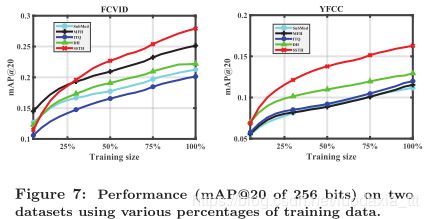
图7显示了所有方法的mAP@20,它们在两个数据集上使用256位,这些数据集以不同百分比的训练数据进行训练。显然,当使用更多的训练数据时,所有方法都会获得更好的性能。特别是,所提出的SSTH的泛化能力明显优于其他技术。例如,仅使用一半的训练数据,SSTH就可以在FCVID上获得与最具竞争力的MFH相似的性能,并且胜过YFCC上的所有方法。我们认为这是由于SSTH的深层结构的强大表达能力所致。表2列出了所有散列方法的跨数据集性能。我们可以看到,在使用FCVID进行培训但在YFCC上进行测试时,它们的性能均下降了很多。这表明当训练数据相对较小(例如约5万个FCVID)时,由于训练/测试数据集的差异,数据驱动的哈希模型的实际使用受到限制。但是,如果训练数据足够,例如大约60万个YFCC,我们可以观察到,除SubMod之外,所有方法均比FCVID训练获得了更好的性能增益;特别是,在使用所有位大小时,SSTH可以实现持续增加的增益。这表明SSTH体系结构的表达能力很强。 SubMod实现最差泛化的原因可能是二进制代码选择过程严重偏向特定数据集。总而言之,基于以上观察,我们认为SSTH在现实世界的CBVR中具有巨大的潜力,因为它具有在无监督的Web学习视频中进行无监督学习的泛化能力。
6 结论
在本文中,我们提出了一种新颖的视频哈希框架,称为自我监督的时间哈希(SSTH)。与通常基于帧池化的现有视频哈希方法形成鲜明对比的是,SSTH准确地对视频时序信息进行建模,并在不需要松弛的情况下直接优化了二进制代码学习问题。通过在两个大型消费者视频数据集上进行的广泛实验,我们证明了SSTH的有效性归因于其三种杰出的设计:BLSTM,自监督学习策略和二进制反向传播。
据我们所知,SSTH是第一个无监督的深度视频哈希模型。SSTH本质上是用于任何顺序多媒体数据的二进制表示学习的通用端到端框架。按照这种观点,可能的未来方向是将SSTH应用于其他时间多媒体应用程序,其中可以按时间跟踪图像和文本,例如多媒体用户配置文件和新闻事件预测。此外,如果标签可用,我们还可以将SSTH扩展到监督和半监督哈希框架。