Kanggle入门程序-预测Titanic生存率
如何预测Titanic生存率的流程
- 简介
这是kaggle上入门推荐的测试例子,我将经历在著名的泰坦尼克号数据集上创建一个机器学习模型的全过程,这个模型已经被全世界的许多初学者所使用。 它提供关于泰坦尼克号旅客命运的信息,根据经济状况(等级),性别,年龄和生存情况进行总结。 在这个挑战中,我们被要求预测泰坦尼克号上的乘客是否会幸存下来。
接下来我将介绍自己在学习这个完整的数据处理、模型建立过程的一些主要步骤,即可以复制到其他模型建立的通用步骤 与心得体会。因为我也是学习入门,这里只介绍每一个步骤的一个示例,这些代码是参考kaggle上一位大牛的模型,我只是理解,学习他的建立步骤,最后会附上他的代码链接,有需要可以去下载运行。 - 学习流程
2.1 导包
这是一个典型的二分类问题,也就是乘客只有两种选择,生和死,所以我只导入线性分类的包。
# 线性运算
import numpy as np
# 数据处理
import pandas as pd
# 数据可视化
import seaborn as sns
%matplotlib inline
from matplotlib import pyplot as plt
from matplotlib import style
# 算法
# Algorithms
from sklearn import linear_model#线性模型
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier#随机森林
from sklearn.linear_model import Perceptron#感知器
from sklearn.linear_model import SGDClassifier#随机梯度下降
from sklearn.tree import DecisionTreeClassifier#决策树分类器
from sklearn.neighbors import KNeighborsClassifier#k-邻近分类器
from sklearn.svm import SVC, LinearSVC#线性SVC
from sklearn.naive_bayes import GaussianNB#高斯朴素贝叶斯2.2 数据分析
这里先导入数据,然后利用pandas的函数简单的观察数据含有哪些特征,它们的一些统计数据,例如均值,标准差,百分位数等。
train_df=pd.read_csv('train.csv')#读取数据
train_df.info()#数据列信息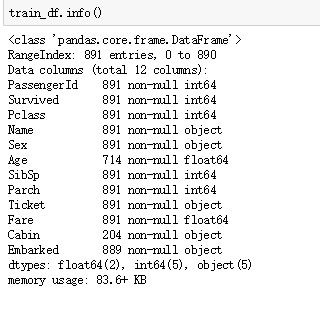
train_df.describe()#mean 平均值,std标准差,min 最小值,25%百分位数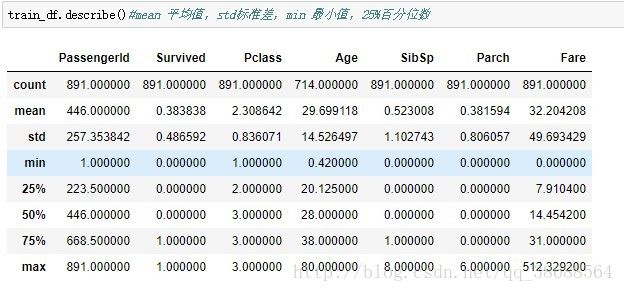
train_df.head()#显示前5行数据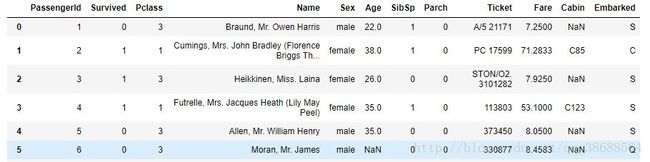
2.3 统计缺失值程度
total = train_df.isnull().sum().sort_values(ascending=False)
percent_1 = train_df.isnull().sum()/train_df.isnull().count()*100
#计算缺失值百分比,大致判断处理的复杂度,以及该数据是否有用的必要
percent_2 = (round(percent_1, 1)).sort_values(ascending=False)#降序排列
missing_data = pd.concat([total, percent_2], axis=1, keys=['Total', '%'])#连接函数concat
missing_data.head(5)
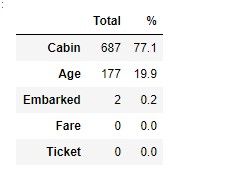
2.4 分析各个变量与生存率之间的关系(这里只介绍一个示例)
- 例如:Age 和 Sex
survived = 'survived'
not_survived = 'not survived'
fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(10, 4))#1行2列,两个图
women = train_df[train_df['Sex']=='female']
men = train_df[train_df['Sex']=='male']
ax = sns.distplot(women[women['Survived']==1].Age.dropna(), bins=18, label = survived, ax = axes[0], kde =False)
#displot函数的 bins:使用切分数据片段的数量或者在何位置切分数据片段,尝试更多或更少的数据片段可能会显示出数据中的其他特征,值越大切分越细
#kde:核密度估计(kernel density estimaton)每一个观察都被一个以这个值为中心的正态( 高斯)曲线所取代sns.kdeplot(x,shade=True)直接调用
#DataFrame.dropna(axis=0, how='any',#有nan就去除,all所有才去除 thresh=None,#至少包含多少非Nan值 subset=None, inplace=False)删除空值的行
ax = sns.distplot(women[women['Survived']==0].Age.dropna(), bins=40, label = not_survived, ax = axes[0], kde =False)
ax.legend()
ax.set_title('Female')
ax = sns.distplot(men[men['Survived']==1].Age.dropna(), bins=18, label = survived, ax = axes[1], kde = False)
ax = sns.distplot(men[men['Survived']==0].Age.dropna(), bins=40, label = not_survived, ax = axes[1], kde = False)
ax.legend()
_ = ax.set_title('Male')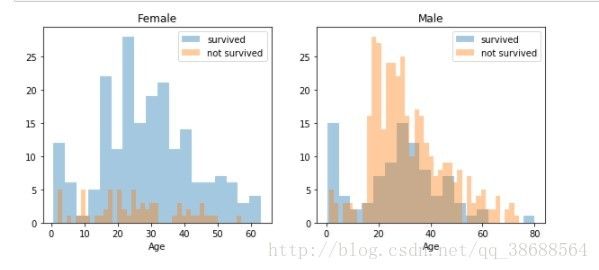
3.数据处理
3.1 删无用数据
train_df['Ticket'].describe()
#count 891
#unique 681
#top 1601
#freq 7
#Name: Ticket, dtype: object
#我们可以看到Ticket有681个数据都是不同的,所以它没有太大的价值,去除
#其他还有一些诸如name等一类属性也可以去掉,这里只是示例
train_df = train_df.drop(['Ticket'], axis=1)
test_df = test_df.drop(['Ticket'], axis=1)3.2 缺失值的处理(换NaN值)
data = [train_df, test_df]
#Age有很多缺失值,我将创建一个包含随机数的数组,这些随机数是根据平均年龄值计算的,与标准差和is_null相关。
for dataset in data:
mean = train_df["Age"].mean()
std = test_df["Age"].std()
is_null = dataset["Age"].isnull().sum()
#print(is_null)
# compute random numbers between the mean, std and is_null
rand_age = np.random.randint(mean - std, mean + std, size = is_null)
# fill NaN values in Age column with random values generated
age_slice = dataset["Age"].copy()
age_slice[np.isnan(age_slice)] = rand_age
dataset["Age"] = age_slice
dataset["Age"] = train_df["Age"].astype(int)3.3 特征转换(数值化)
#把性别转成数值形式,这一步要把所有非数值想办法转成数值形式,这样机器学习模型才能处理
genders = {"male": 0, "female": 1}
data = [train_df, test_df]
for dataset in data:
dataset['Sex'] = dataset['Sex'].map(genders) 3.4 分类数据
#首先我们将它从float转换成正常的数字。
#然后,我们将创建新的“AgeGroup”变量,将每个年龄分组为一个组。
data = [train_df, test_df]
for dataset in data:
dataset['Age'] = dataset['Age'].astype(int)
dataset.loc[ dataset['Age'] <= 11, 'Age'] = 0
dataset.loc[(dataset['Age'] > 11) & (dataset['Age'] <= 22), 'Age'] = 1
dataset.loc[(dataset['Age'] > 22) & (dataset['Age'] <= 33), 'Age'] = 2
dataset.loc[(dataset['Age'] > 33) & (dataset['Age'] <= 44), 'Age'] = 3
dataset.loc[(dataset['Age'] > 44) & (dataset['Age'] <= 55), 'Age'] = 4
dataset.loc[(dataset['Age'] > 55) & (dataset['Age'] <= 66), 'Age'] = 5
dataset.loc[ dataset['Age'] > 66, 'Age'] = 6
train_df['Age'].value_counts()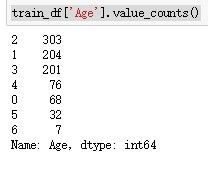
3.5 增加新特征
由于年龄和票类别有关联,我们将其组成一个特征
data = [train_df, test_df]
for dataset in data:
dataset['Age_Class']= dataset['Age']* dataset['Pclass']4.模型建立
4.1 八种分类模型(这里只展示预测率最高的和最低的两种)
# Random Forest
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_prediction = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
print(round(acc_random_forest,2,), "%")
#输出值94.05 %# stochastic gradient descent (SGD) learning
sgd = linear_model.SGDClassifier(max_iter=5, tol=None)
sgd.fit(X_train, Y_train)
Y_pred = sgd.predict(X_test)
sgd.score(X_train, Y_train)
acc_sgd = round(sgd.score(X_train, Y_train) * 100, 2)
print(round(acc_sgd,2,), "%")
#62.85 %4.2 模型比较
results = pd.DataFrame({
'Model': ['Support Vector Machines', 'KNN', 'Logistic Regression',
'Random Forest', 'Naive Bayes', 'Perceptron',
'Stochastic Gradient Decent',
'Decision Tree'],
'Score': [acc_linear_svc, acc_knn, acc_log,
acc_random_forest, acc_gaussian, acc_perceptron,
acc_sgd, acc_decision_tree]})
result_df = results.sort_values(by='Score', ascending=False)
result_df = result_df.set_index('Score')
result_df.head(9)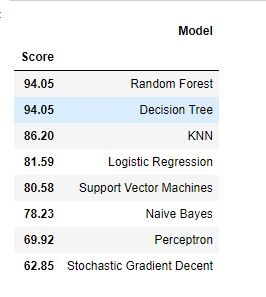
4.3 交叉检验
- K-fold交叉验证: K倍交叉验证随机地将训练数据分成称为折叠的K个子集。让我们把我们的数据分成4倍(K = 4)。我们的随机森林模型将进行4次训练和评估,每次使用不同的折叠次数进行评估,而剩余的3次将进行训练。 下面的图片显示了这个过程,使用4倍(K = 4)。每行代表一个培训+评估过程。在第一行中,模型在第一,第二和第三子集上训练,并在第四个子集上评估。在第二行中,模型在第二,第三和第四子集上训练,并在第一个子集上进行评估。 K-fold交叉验证重复这个过程,直到每一次fold作为一个评估折叠。 交叉-V。 我们的K-fold交叉验证示例的结果将是一个包含4个不同分数的数组。然后我们需要计算这些分数的均值和标准差。 下面的代码使用我们的随机森林模型进行K倍交叉验证,使用10倍(K = 10)。因此它输出一个有10个不同分数的数组。
from sklearn.model_selection import cross_val_score
rf = RandomForestClassifier(n_estimators=100)
scores = cross_val_score(rf, X_train, Y_train, cv=10, scoring = "accuracy")
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard Deviation:", scores.std())
#输出
Scores: [0.77777778 0.83333333 0.76404494 0.82022472 0.86516854 0.86516854
0.84269663 0.79775281 0.87640449 0.84090909]
Mean: 0.8283480876177507
Standard Deviation: 0.036199077907485025.调优模型
5.1 删除贡献率最低一些特征
- - 查看特征重要性
- - 随机森林的另一个很棒的特点就是它可以很容易地衡量每个特征的相对重要性。 Sklearn通过查看多少树节点使用该特征,然后通过取平均来减少不纯度(在森林中的所有树上)来衡量特征的重要性。 它对训练后的每个特征自动计算得分,并将结果进行缩放,使得所有重要性的总和等于1.我们将在下面看到:
importances = pd.DataFrame({'feature':X_train.columns,'importance':np.round(random_forest.feature_importances_,3)})
importances = importances.sort_values('importance',ascending=False).set_index('feature')
importances.head(15)
#输出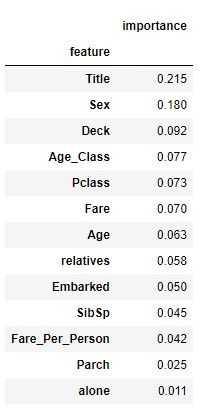
结论: Alone and Parch在我们的随机森林分类器预测过程中不起重要作用。 因此,我将从数据集中删除它们,并再次训练分类器。 我们也可以删除更多或更少的功能,但是这需要更详细地调查我们模型的功能效果。 但我认为只删除单独和Parch就可以了。
#删除
train_df = train_df.drop("alone", axis=1)
test_df = test_df.drop("alone", axis=1)
train_df = train_df.drop("Parch", axis=1)
test_df = test_df.drop("Parch", axis=1)
#再次训练
# Random Forest
random_forest = RandomForestClassifier(n_estimators=100, oob_score = True)
random_forest.fit(X_train, Y_train)
Y_prediction = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
print(round(acc_random_forest,2,), "%")
#92.03 %# 另外还有一种评估随机森林分类器的方法,它可能比我们以前使用的分数准确得多
#叫袋外误差,out-of-bag samples
print("oob score:", round(random_forest.oob_score_, 4)*100, "%")
# oob score: 82.6 %5.2 超参优化
#这一步我也不太懂,先把代码放着 ,大家自行去搜索
param_grid = { "criterion" : ["gini", "entropy"], "min_samples_leaf" : [1, 5, 10, 25, 50, 70], "min_samples_split" : [2, 4, 10, 12, 16, 18, 25, 35], "n_estimators": [100, 400, 700, 1000, 1500]}
from sklearn.model_selection import GridSearchCV, cross_val_score
rf = RandomForestClassifier(n_estimators=100, max_features='auto', oob_score=True, random_state=1, n_jobs=-1)
clf = GridSearchCV(estimator=rf, param_grid=param_grid, n_jobs=-1)
clf.fit(X_train, Y_train)
clf.bestparams
#测试新参数
# Random Forest
random_forest = RandomForestClassifier(criterion = "gini",
min_samples_leaf = 1,
min_samples_split = 10,
n_estimators=100,
max_features='auto',
oob_score=True,
random_state=1,
n_jobs=-1)
random_forest.fit(X_train, Y_train)
Y_prediction = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
print("oob score:", round(random_forest.oob_score_, 4)*100, "%")
#oob score: 83.05 %5.3 进一步检验
#Confusion Matrix:混淆矩阵
#混淆矩阵为您提供了许多有关模型完成情况的信息,
#但是还有更多的方法,比如计算分类器的精度。
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
predictions = cross_val_predict(random_forest, X_train, Y_train, cv=3)
confusion_matrix(Y_train, predictions)
#array([[492, 57]
[ 90, 252]], dtype=int64)
#492是正确分类成未存活的数量,57是错误分类成未存活的数量
#90是错误分类成存活的数量,252是正确分类成存活的数量#precision and recall:精确度和召回率
from sklearn.metrics import precision_score, recall_score
print("Precision:", precision_score(Y_train, predictions))
#Precision: 0.8155339805825242精确度
print("Recall:",recall_score(Y_train, predictions))
#Recall: 0.7368421052631579#召回率#F-Score是精确度和召回率的调和平均数
from sklearn.metrics import f1_score
f1_score(Y_train, predictions)
#0.77419354838709666.心得体会
- 总结一下 :从这个简单地机器学习模型的建立,我发现80%的精力要花在在数据的处理上,包括观察数据特征个数,数据的统计信息,缺失值的处理,增删改特征使其符合机器学习模型的需要,也就是使特征数值化,然后就是简单地调用分类模型去拟合数据,生成模型。在模型建立好后,就是检验模型的准确度,算法都封装好了一些参数,直接调用就可以。然后再去重新选择参数,训练模型。之后要进一步提高模型的准确度,就是调整超参数,再利用得到的参数重新训练模型,再评价我们训练出来的模型效果。
- 1)判断问题属于分类,回归,聚类等,确定需要建立何种模型
- 2)数据分析
- - - -总体特征,平均值,方差,min,max,百分位数
- - - -各个变量-目标值关系,根据先验知识初步找到有用和贡献小的特征
- 3)数据处理
- - - -1.删无用-删除没有太大贡献的特征,如name
- - - -2.处理NaN-处理缺失值
- - - -3.转换特征-将数据类型,非数值型数据转换成数值类型,如S-0,C-1
- - - -4.创建分类-将一些可以归类的数据规成一类,如年龄划段
- - - -5.新增特征-将一些有关联的特征划成一类,如Age-Pclass
-4)模型建立
- - - -调用各种模型去匹配
- - - -比较最优
- - - -检验训练程度,找到最优,有可能结果都比较低,这就是模型选择或者特征选择有问题,需要重新进行以前的工作
- 5)优化模型
- - - -特征二次选择-这里可能会发现以前特征选择不是很合适,去除最不合适的,这里可能还要考虑特征是否过多等一些信息
- - - -超参优化-进一步优化模型
- - - -进一步检验-混淆函数,精确度-召回率,F-Score
7.参考文献
这里可以下载到大牛的代码,使用notebook写的,数据也有,有兴趣去看一下,也感谢这位大牛的开源代码,对我学习提供的帮助。https://www.kaggle.com/niklasdonges/end-to-end-project-with-python