分类数据可视化 - 统计图
barplot() / countplot() / pointplot()
1. barplot()
#柱状图 - 置信区间估计
#置信区间:样本均值 + 抽样误差
示例1:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context('paper')
#加载数据
titanic = sns.load_dataset('titanic')
print(titanic.head())
sns.barplot(x = 'sex', y = 'survived', hue = 'class', data = titanic,
palette = 'hls',
order = ['male', 'female'], #筛选类别
capsize = 0.05, #误差线横向延申宽度
saturation = 8, #颜色饱和度
errcolor = 'gray', errwidth = 2, #误差线颜色、宽度
ci = 'sd' #置信区间误差 --> 0-100内值、 'sd' 、None
)
#计算数据
print(titanic.groupby(['sex', 'class']).mean()['survived'])
print(titanic.groupby(['sex', 'class']).std()['survived'])

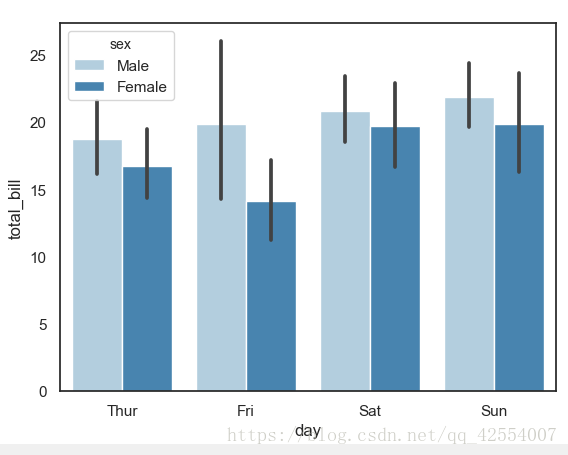
示例2:
tips = sns.load_dataset('tips')
sns.barplot(x = 'day', y = 'total_bill', hue = 'sex', data = tips,
palette = 'Blues', edgecolor = 'w')
tips.groupby(['day','sex']).mean()
示例3:
#加载数据
crashes = sns.load_dataset('car_crashes').sort_values('total', ascending = False)
#创建图表
f, ax = plt.subplots(figsize = (6,15))
#设置第一个柱状图
sns.set_color_codes('pastel')
sns.barplot(x = 'total', y = 'abbrev', data = crashes,
label = 'Total', color = 'b', edgecolor = 'w')
#设置第二个柱状图
sns.set_color_codes('muted')
sns.barplot(x = 'alcohol', y = 'abbrev', data = crashes,
label = 'Alcohol-involved', color = 'b', edgecolor = 'w')
ax.legend(ncol = 2, loc = 'lower right')
sns.despine(left = True, bottom = True)

2、countplot()
#计数柱状图
#x/y --> 以x或者y轴绘图(横向,竖向)
#用法和barplot相似
sns.countplot(x = 'class', hue = 'who', data = titanic, palette = 'magma')

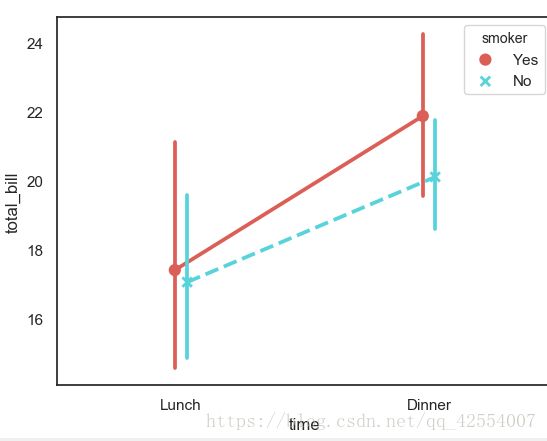
sns.pointplot(x = 'time', y = 'total_bill', hue = 'smoker', data=tips,
palette = 'hls',
dodge = True, #设置点是否分开
join = True, #是否连线
markers = ['o','x'],linestyles = ['-','--'],#设置点样式、线型
)
#计算数据
tips.groupby(['time','smoker']).mean()['total_bill']
3.pointplot()
#折线图 - 置信区间估计