kaggle实战之数据可视化
本篇教程的是参考kaggle的一篇笔记,https://www.kaggle.com/benhamner/python-data-visualizations/notebook代码是基于python3的,需要pandas、matplotlib、seaborn基础,数据是使用鸢尾花的150组数据,鸢尾花数据下载地址http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data。
鸢尾花数据描述:一共有150组鸢尾花数据,一共有三种种类,分别是Iris-virginica、Iris-setosa、Iris-versicolor每种鸢尾花都是50组数据,每一组鸢尾花一共有四个属性分别是萼片长度(SepalLengthCm)、萼片宽度(SepalWidthCm)、花瓣长度(PetalLengthCm)、花瓣宽度(PetalWidthCm),单位都是cm。
1、导入相关库查看前5行数据
#encoding:utf-8
import pandas as pd
#由于seaborn库会输出很多警告,我们将忽视警告的输出
import warnings
warnings.filterwarnings("ignore")
import seaborn as sns
import matplotlib.pyplot as plt
#设置seaborn的风格
sns.set(style="white",color_codes=True)
if __name__ == "__main__":
#使用pandas读取鸢尾花数据
data = pd.read_csv("iris.csv")
#查看前5行数据,默认n=5
print(data.head())
2、统计数据种类的分布情况
print(data["Species"].value_counts())
通过pandas来统计某一列的数据分布情况,通过上面的数据可以发现,一共有三种不同种类的鸢尾花,每种种类的都是50个。
3、根据鸢尾花的萼片长度和宽度属性绘制散点图
#设置绘图的种类,scatter表示散点图,x轴使用萼片的长度,y轴使用萼片的宽度
data.plot(kind="scatter",x="SepalLengthCm",y="SepalWidthCm")
plt.show()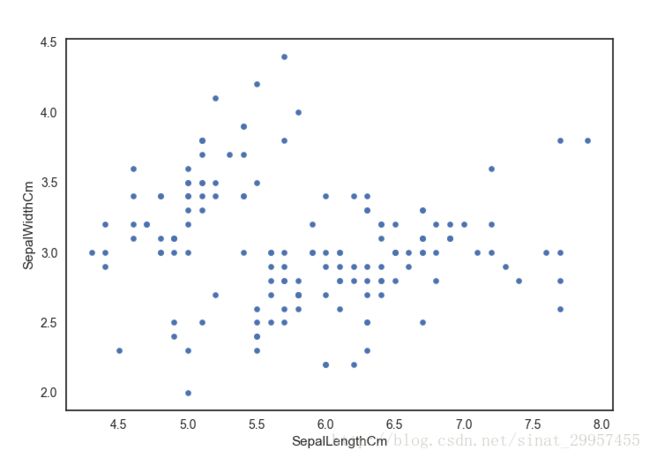
4、使用seaborn绘制散点图
sns.jointplot(x="SepalLengthCm",y="SepalWidthCm",data=data,size=6)
plt.show()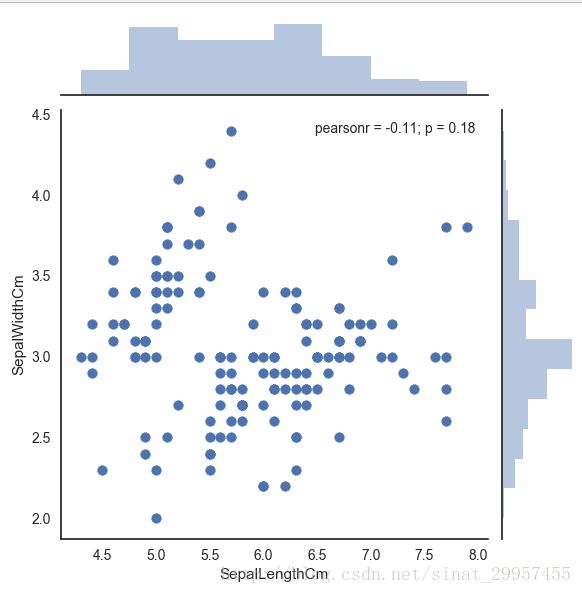
5、对于不同种类的鸢尾花使用不同颜色进行标记
face = sns.FacetGrid(data,hue="Species",size=5)
face.map(plt.scatter,"SepalLengthCm","SepalWidthCm")
face.add_legend()
plt.show()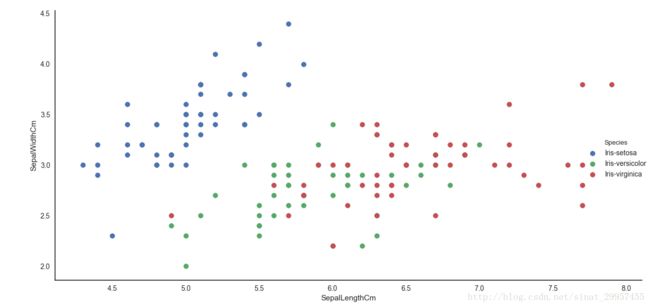
6、绘制箱形图
根据鸢尾花的长度绘制箱形图
sns.boxplot(x="Species",y="SepalLengthCm",data=data)
plt.show()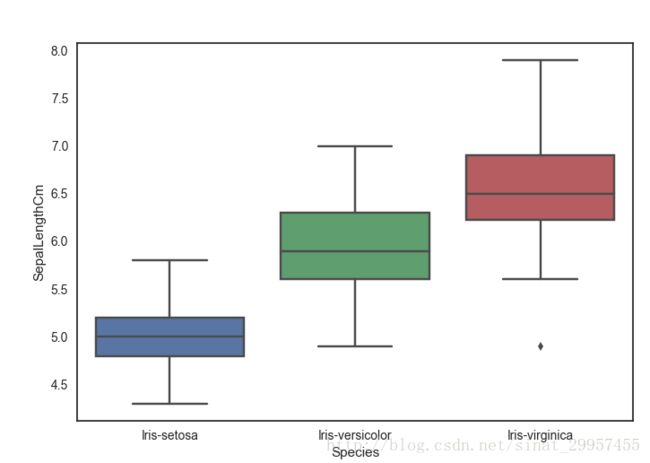
7、在箱形图的基础上绘制点
ax = sns.boxplot(x="Species",y="SepalLengthCm",data=data)
#在箱形图的基础上进行描点,设置jitter为True保证点不会落在同一条直线上
ax = sns.stripplot(x="Species",y="SepalLengthCm",data=data,jitter=True,edgecolor="gray")
plt.show()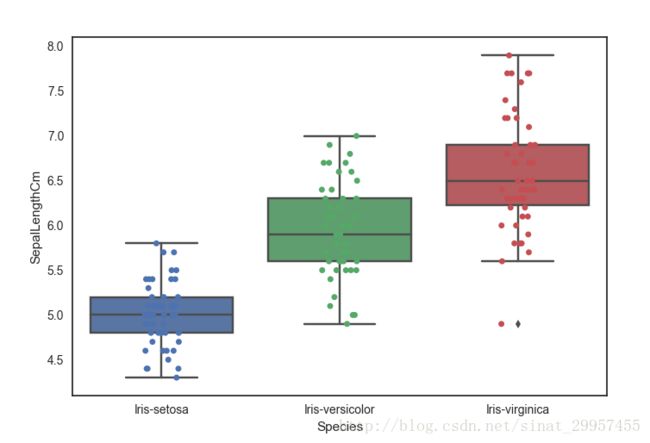
8、绘制小提琴图
小提琴图又称核密度图,它是结合了箱形图和核密度图的图,将箱形图和密度图用一个图来显示,因为形状很像小提琴,所以被称作小提琴图。
sns.violinplot(x="Species",y="SepalLengthCm",data=data,gridsize=6)
plt.show()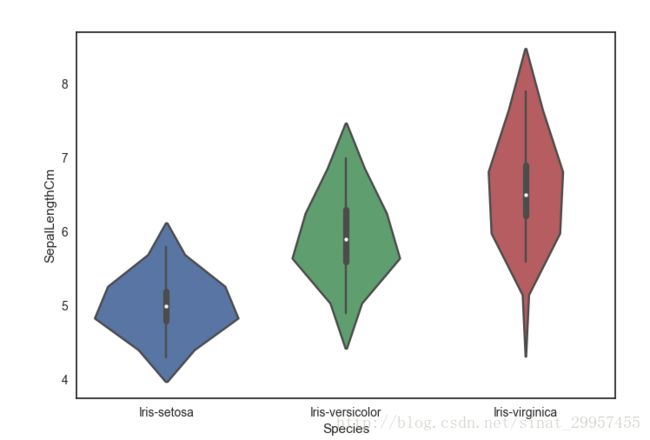
9、绘制核密度估计图
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,用于研究单变量关系。
face = sns.FacetGrid(data,hue="Species",size=6)
face.map(sns.kdeplot,"SepalLengthCm")
face.add_legend()
plt.show()
10、绘制双变量的散点图
对角线是直方图,其它的部分是两个变量之间的散点图
#删除id列
sns.pairplot(data.drop("id",axis=1),hue="Species",size=2)
plt.show()
#将对角线的直方图替换成核密度估计曲线图
sns.pairplot(data.drop("id",axis=1),hue="Species",size=2,diag_kind="kde")
plt.show()
11、使用pandas绘制每一个变量的箱形图
data.drop("id",axis=1).boxplot(by="Species",figsize=(12,6))
plt.show()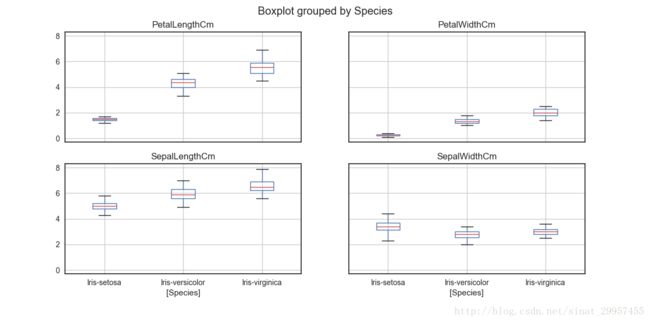
12、绘制安德鲁斯曲线
安德鲁斯曲线将每个样本的属性值转化为傅里叶序列的系数来绘制曲线,将不同种类的鸢尾花用不同的颜色标记来可视化聚类数据,属于相同类别的样本曲线通常更加接近并构成了更大的数据结构。
from pandas.tools.plotting import andrews_curves
andrews_curves(data.drop("id",axis=1),"Species")
plt.show()
13、平行坐标
from pandas.tools.plotting import parallel_coordinates
parallel_coordinates(data.drop("id",axis=1),"Species")
plt.show()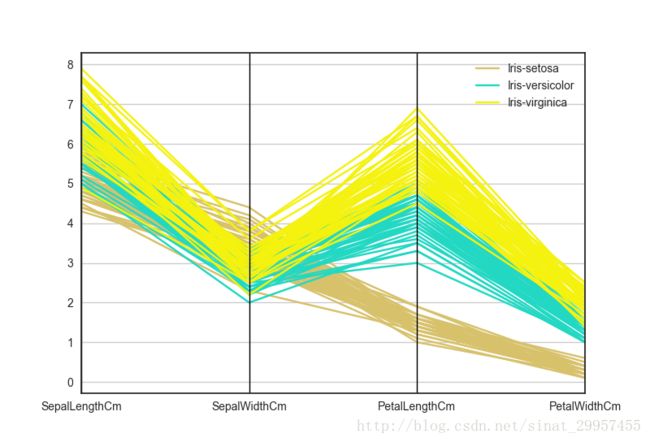
14、径向坐标可视化
radviz图也是一种多维的可视化图。它是基于基本的弹簧压力最小化算法,它将数据集的特征映射到二维目标空间单位圆中的一个点,点的位置由系在点上的特征决定。将实例投入到圆的中心,特征会朝园中此实例的位置(实例对应的归一化数值)“拉”实例。
from pandas.tools.plotting import radviz
radviz(data.drop("id",axis=1),"Species")
plt.show()