JAVAWEB开发之mybatis详解(二)——高级映射、查询缓存、mybatis与Spring整合以及懒加载的配置和逆向工程
mybatis基础知识回顾
1. mybatis是什么?
- mybatis是一个持久层框架,是Apache下的开源项目,前身是ibatis,是一个不完全的ORM框架,mybatis提供输入和输出的映射,需要程序员自己手动写SQL语句,mybatis重点对SQL语句进行灵活操作。
- 适用场合:需求变化频繁,数据模型不固定的项目,例如:互联网项目。
2.mybatis架构:
- SqlMapConfig.xml(名称不固定),配置内容:数据源、事务、properties、typeAliases、settings、mappers配置。
- SqlSessionFactory:会话工厂,作用是创建SqlSession,实际开发中以单例模式管理SqlSessionFactory。
- SqlSession:会话,是一个面向用户(程序员)的接口,使用mapper代理方法开发是不需要程序员直接调用Sqlsession的方法。它是线程不安全的,最佳使用场合是方法体内。
3.mybatis开发DAO的方法
3.1 原始DAO开发方法,需要程序员编写Dao接口和实现类,此方法在当前企业中还有使用因为ibatis用的就是这种原始的Dao开发方式。
3.2 mapper代理方法,程序员只需要编写mapper接口(相当于DAO接口),mybatis自动根据mapper接口和mapper接口对应的statement自动生成代理对象(接口实现类对象),注意使用mapper代理方法开发需要遵循以下规则:
- mapper.xml中namespace是mapper接口的全限定名。
- mapper.xml中statement的id为mapper接口的方法名。
- mapper.xml中statement输入类型(parameterType)和mapper接口方法输入参数类型一致。
- mapper.xml中statement输出类型(resultType)和mapper接口方法返回结果类型一致。
resultType和resultMap都可以完成输出映射:
resultType映射要求SQL查询的列名和输出映射pojo类型的属性名一致。
resultMap映射时对SQL查询的列名和输出映射pojo类型的属性名做一个对应关系。
4.动态SQL:
#{}和${}完成输入参数的属性值获取,通过OGNL获取parameterType指定的pojo的属性名。
#{}:占位符号,好处是防止SQL注入。
${}: SQL拼接符号,无法防止SQL注入。
if、where以及foreach的使用。
mybatis重点高级知识清单
1.使用resultMap完成高级映射(重点)
—|学习商品订单数据模型(一对一、一对多、多对多)
—|resultMap实现一对一、一对多、多对多
—|延迟加载
2.查询缓存(重点)
—|一级缓存
—|二级缓存
3.mybatis和Spring的整合(重点)
4.mybatis逆向工程(常用)
商品订单数据模型

技巧总结:学会在企业中如何去分析陌生表的数据模型
1.学习单表记录了什么东西(去学习理解需求)
2.学习单表重要字段的意义(优先学习不能为空的字段)
3.学习表与表之间的关系(一对一、一对多、多对多)
通过表的外键分析表之间的关系。
注意:分析表与表之间的关系是建立在业务意义基础之上的。

用户表user:记录了购买商品的用户
订单表orders:记录了用户所创建的订单信息
订单明细表orderdetail:记录了用户所创建订单的详细信息
商品信息表items:记录了商家提供的商品信息。
分析表与表之间的订单关系:
(1) 用户表user和订单orders:
user—>orders: 一个用户可以创建多个订单 多对多
orders—>user: 一个订单只能由一个用户创建 一对一
(2) 订单表orders和订单明细表orderdetail:
orders—>orderdetail: 一个订单可以包括多个订单明细 一对多
orderdetail—>orders: 一个订单明细只能属于一个订单 一对一
(3)订单明细orderdetail和商品信息items
orderdetail—>items: 一个订单明细只能对应一个商品信息 一对一
items—>orderdetail: 一个商品对应多个订单明细 一对多
一对一查询
需求
查询订单信息关联查询用户信息
sql语句
查询语句:
先确定主查询表:订单信息表
再确定关联查询表:用户信息
通过orders关联穿用户使用user_id一个外键,根据一条订单数据只能查询出一条用户记录就可以使用内连接
SELECT
orders.*, user.username, user.sex
FROM
orders,
user
WHERE
orders.user_id = user.id;
使用resultType实现
创建PO类
创建基础表单的PO类

一对一查询映射的pojo
创建pojo包括 订单信息和用户信息,resultType才可以完成映射
创建OrderCustom作为自定义pojo,继承 SQL查询中列最多的POJO类
public class OrderCustom extends Orders {
//补充用户信息
private String username;
private String sex;
private String address;
//提供对应的setter和getter方法
......
}mapper.xml
mapper.java
public interface OrdersMapperCustom {
//一对一查询,查询订单关联查询用户,使用resultType
public List findOrderUserList() throws Exception;
} 测试代码
@Test
public void testFindOrderUserList() throws Exception{
SqlSession sqlSession = sqlSessionFactory.openSession();
//创建mapper代理对象
OrdersMapperCustom ordersMapperCustom = sqlSession.getMapper(OrdersMapperCustom.class);
// 调用方法
List list = ordersMapperCustom.findOrderUserList();
System.out.println(list);
} 使用resultMap实现一对一
resultMap映射思路
resultMap提供一对一关联查询映射和一对多关联查询映射,一对一映射思路:将关联查询的信息映射到pojo中,如下:
在Orders类中创建一个user属性,将关联查询到的信息映射到User属性中。如下所示:
public class Orders {
private Integer id;
private Integer userId;
private String number; //商品编号
private Date createtime;
private String note;
//关联用户信息
private User user;
.....mapper.xml
resultMap定义

mapper.java
// 一对一查询,查询订单关联查询用户,使用resultMap
public List findOrderUserListResultMap() throws Exception; 小结
resultType:要自定义pojo 保证SQL查询列名要和pojo的属性对应,这种方法相对较简单,所以应用广泛。
resultMap:使用association完成一对一映射需要配置resultMap,过程有点复杂,如果要实现延迟加载就只能使用resultMap来进行实现,如果为了方便对关联信息的解析,也可使用association将关联信息映射到pojo中方便解析。
一对多查询
需求
查询所有订单信息及订单下的订单明细信息
SQL语句
主查询表:订单表
关联查询表:订单明细
SELECT
orders.*,
user.username,
user.sex ,
orderdetail.id orderdetail_id,
orderdetail.items_num,
orderdetail.items_id
FROM
orders,
USER,
orderdetail
WHERE orders.user_id = user.id AND orders.id = orderdetail.orders_id
需要将订单明细内容设置到对应的订单中
resultMap进行一对多映射思路
resultMap提供collection完成关联信息映射到集合对象中。
在orders类中创建集合属性orderdetails:
public class Orders {
private Integer id;
private Integer userId;
private String number; //商品编号
private Date createtime;
private String note;
//关联用户信息
private User user;
//订单明细
private List orderDetails;
//
...... mapper.xml
resultMap定义
mapper.java
// 一对多查询,查询订单关联查询订单明细,使用resultMap
public List findOrderAndOrderdetails() throws Exception; 测试代码
//一对多查询使用resultMap
@Test
public void testFindOrderAndOrderdetails() throws Exception{
SqlSession sqlSession = sqlSessionFactory.openSession();
//创建mapper代理对象
OrdersMapperCustom ordersMapperCustom = sqlSession.getMapper(OrdersMapperCustom.class);
//调用方法
List list = ordersMapperCustom.findOrderAndOrderdetails();
for (Orders orders : list) {
System.out.println(orders.getUser().getUsername()+" "+orders.getOrderDetails().size());
}
System.out.println(list);
} 一对多查询[复杂]
需求
查询所有用户信息,关联查询订单及商品信息,订单明细信息中关联查询查商品信息。
SQL语句
主查询表:用户信息
关联查询:订单、订单明细、商品信息
SELECT
orders.*,
user.username,
user.sex ,
orderdetail.id orderdetail_id,
orderdetail.items_num,
orderdetail.items_id,
items.name items_name,
items.detail items_detail
FROM
orders,
USER,
orderdetail,
items
WHERE orders.user_id = user.id AND orders.id = orderdetail.orders_id AND items.id = orderdetail.items_id
pojo定义
在User.java中创建映射的属性:集合List orderlist;
在Orders中创建映射属性:集合List orderdetails;
在Orderdetail中创建商品属性:pojo Items items;



mapper.xml
resultMap定义
mapper.java
// 一对多查询,查询订单关联查询订单明细以及商品信息,使用resultMap
public List findUserOrderDetail() throws Exception; 多对多查询
需求1:
查询显示字段:用户账号、用户名称、用户性别、商品名称、商品价格(最常见)
企业开发中常见明细列表,用户购买商品明细列表,
使用resultType将上边查询列映射到pojo输出。
需求2:
查询显示字段:用户账号、用户名称、购买商品数量、商品明细(鼠标移上显示明细)
使用resultMap将用户购买的商品明细列表映射到user对象中。
实现方法和一对多一样。
延迟加载
使用延迟加载的意义
在进行数据查询时,为了提高数据库查询性能,尽量使用单表查询,因为单表查询比多表关联查询速度快。
如果查询单表就可以满足需求,一开始先查询单表,当需要关联信息时,再关联查询。当需要关联信息时才进行查询就叫做延迟加载。mybatis中resultMap提供延迟加载功能,通过resultMap配置延迟加载。

延迟加载实现
实现思路
需求:查询订单及用户信息,一对一查询
刚开始只查询订单信息,当需要用户信息时调用Orders类中的getUser()方法执行延迟加载,向数据库发出SQL。
mapper.xml
resultMap
mapper.java
// 一对一查询,查询订单延迟加载用户信息,使用resultMap
public List findOrderUserListLazyLoading() throws Exception; 测试代码
//一对一查询 延迟加载
@Test
public void testFindOrderUserListLazyLoading() throws Exception{
SqlSession sqlSession = sqlSessionFactory.openSession();
//创建mapper代理对象
OrdersMapperCustom ordersMapperCustom = sqlSession.getMapper(OrdersMapperCustom.class);
// 调用方法
List list = ordersMapperCustom.findOrderUserListLazyLoading();
//这里执行延迟加载,要发出SQL
User user = list.get(0).getUser();
System.out.println(user);
} 
一对多查询延迟加载
resultType、resultMap、延迟加载使用场景总结
延迟加载:延迟加载实现的方法多种多样,在只查询单表就可以满足需求,为了提高数据库查询性能使用延迟加载,再查询关联信息。
注意:mybatis提供的延迟加载的功能用于Service。
resultType:
作用:将查询结果按照sql列名和pojo属性名的一致性映射到pojo中。
场合:常见一些明细记录的展示,将关联信息全部展示到页面上时,此时可直接使用resultType将每一条记录映射到pojo中,在前端页面遍历list(list中是pojo即可)
resultMap:使用association和collection完成一对一和一对多高级映射。
association:
作用:将关联查询信息映射到一个pojo类中。
场合:为了方便获取关联信息可以使用association将关联订单映射为pojo,比如:查询订单关联查询用户信息。
collection:
作用:将关联查询信息映射到一个list集合中。
场合:为了方便获取关联信息可以使用collection将关联信息映射到list集合中,比如:查询用户权限范围模块和功能,可以使用collection将模块和功能列表映射到list中。
查询缓存
缓存的意义
将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)去查询,从缓存中进行查询,从而提高查询效率,解决了高并发系统的性能问题。

mybatis持久层缓存
mybatis提供一级缓存和二级缓存

mybatis一级缓存是一个Sqlsession级别,SqlSession只能访问自己的一级缓存数据,二级缓存是跨SqlSession的,是mapper级别的缓存,对于mapper级别的缓存 不同的SqlSession是可以共享的。
一级缓存
原理

第一次发出一个查询sql,sql查询结果写入SqlSession一级缓存中,缓存使用的数据结构是一个map
key: hashcode+sql+sql输入参数+sql输出参数 (作为SQL的唯一标识)
value: 用户信息。
同一个sqlSession再次发出相同的sql,就从缓存中取数据,不再查询数据库。如果两次中间出现commit操作(修改、添加、删除),此SqlSession中的一级缓存数据全部清空,下次再去缓存中就会查询不到数据再从数据库查询,从数据库查询到后再写入缓存。
每次查询都先从缓存进行查询。
注意:清空时会清空当前sqlsession缓存区域中的全部内容。
一级缓存配置
mybatis默认支持一级缓存不需要配置
注意:mybatis和Spring整合后进行mapper代理开发,不支持一级缓存,mybatis和Spring整合,Spring按照mapper的模板去生成mapper代理对象,模板中在最后统一关闭sqlsession。
一级缓存测试
//一级缓存
@Test
public void testCache1() throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//第一次查询用户id为1的用户
User user = userMapper.findUserById(1);
User userX = userMapper.findUserById(2);
System.out.println(user);
//中间修改用户要清空缓存,目的防止查询出脏数据
/*user.setUsername("测试用户2");
userMapper.updateUser(user);
sqlSession.commit(); */
//第二次查询用户id为1的用户
User user2 = userMapper.findUserById(1);
User userX2 = userMapper.findUserById(2);
System.out.println(user2);
sqlSession.close();
}测试可以发现,当前SQLSession只要执行任意一个commit(),id为1和2的用户都会在缓存中被清空,所以说,commit后会清空当前sqlsession缓存区域中的全部内容。
二级缓存
二级缓存原理

二级缓存的范围是mapper级别(mapper同一个命名空间),mapper以命名空间为单位创建缓存数据结构,结构为map
每次查询先看是否开启二级缓存,如果开启先从二级缓存中数据结构中取缓存数据。
如果从二级缓存中没有取到,再从一级缓存中进行查找,如果一级缓存也没有,从数据库查询。
mybatis二级缓存配置
在核心配置文件SqlMapConfig.xml中全局设置中加入
cacheEnabled: 对此配置文件下的所有cache进行全局性开/关设置。允许值true/false,默认为true。
然后在Mapper的映射文件中添加一行:
查询结果映射的pojo序列化
mybatis二级缓存需要将查询结果映射的pojo实现 java.io.serializable接口,如果不实现则抛出异常:org.apache.ibatis.cache.CacheException: Error serializing object. Cause: java.io.NotSerializableException
二级缓存可以将内存中的数据写到硬盘,存在对象的序列和反序列化,所以要实现java.io.serializable接口。如果结果映射的pojo中还关联了别的pojo,那么它和它所关联的pojo也都要实现java.io.serializable接口。

二级缓存的禁用
对于变化频率较高的sql,需要禁用二级缓存:
在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
刷新缓存
如果SqlSession操作commit操作,对二级缓存进行刷新(全局清空)
设置与commit相关statement(insert,update,delete等标签)的flushCache属性是否刷新缓存,默认值是true,如果设置了为false,即使后台数据库发生了变化,只要缓存没有过期,也只会读取缓存中数据 就会获取不到最新数据。
测试代码
//二级缓存的测试
@Test
public void testCache2() throws Exception {
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
SqlSession sqlSession3 = sqlSessionFactory.openSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
UserMapper userMapper3 = sqlSession3.getMapper(UserMapper.class);
//第一次查询用户id为1的用户
User user = userMapper1.findUserById(1);
System.out.println(user);
sqlSession1.close();
//中间修改用户要清空缓存,目的防止查询出脏数据
/*user.setUsername("测试用户2");
userMapper3.updateUser(user);
sqlSession3.commit();
sqlSession3.close();*/
//第二次查询用户id为1的用户
User user2 = userMapper2.findUserById(1);
System.out.println(user2);
sqlSession2.close();
}mybatis自带的cache参数属性(了解)
mybatis的cache参数只适用于mybatis维护缓存。
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
如下例子:
这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会导致冲突。可用的收回策略有, 默认的是 LRU:
LRU – 最近最少使用的:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
如下例子:
这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会导致冲突。可用的收回策略有, 默认的是 LRU:
LRU – 最近最少使用的:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
mybatis和ehcache缓存框架整合
mybatis二级缓存通过ehcache维护缓存数据。
分布缓存
将缓存数据进行分布式管理

mybatis和ehcache思路
通过mybatis和ehcache框架进行整合,既可以将缓存数据的管理托管给ehcache。
在mybatis中提供了一个cache接口,只要实现cache接口就可以把缓存数据灵活的管理起来。

mybatis中的默认实现

下载和ehcache整合的jar包

ehcache对cache接口的实现类

在calsspath下配置ehcache.xml
整合ehcache
在mapper.xml下添加ehcache配置
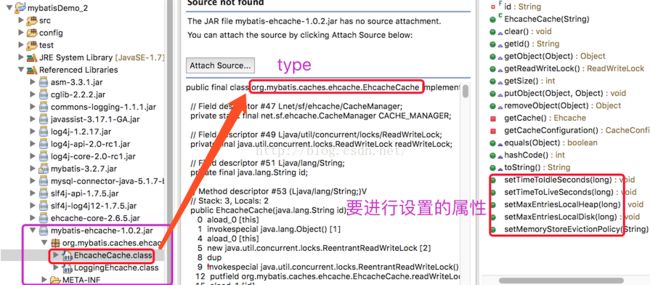
二级缓存的应用场景
对于查询频率高,变化频率低的数据建议使用二级缓存。
对于访问多的查询请求且用户对查询结果的实时性要求不高,此时可采用mybatis二级缓存技术降低数据库的访问量,提高访问速度,业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。
实现方法如下:通过设置刷新时间间隔,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新时间间隔flushInterval,比如设置30分钟、60分钟、24小时等,根据需求而定。
mybatis局限性
项目代码
完整代码已经上传GitHub(https://github.com/LX1993728/mybatisDemo_2)
OrdersMapperCustom.java
package test.lx.mybatis.mapper;
import java.util.List;
import test.lx.mybatis.po.OrderCustom;
import test.lx.mybatis.po.Orders;
import test.lx.mybatis.po.User;
/**
* 订单自定义的mapper接口
*
* @author liuxun
*
*/
public interface OrdersMapperCustom {
// 一对一查询,查询订单关联查询用户,使用resultType
public List findOrderUserList() throws Exception;
// 一对一查询,查询订单关联查询用户,使用resultMap
public List findOrderUserListResultMap() throws Exception;
// 一对一查询,查询订单延迟加载用户信息,使用resultMap
public List findOrderUserListLazyLoading() throws Exception;
// 一对多查询,查询订单关联查询订单明细,使用resultMap
public List findOrderAndOrderdetails() throws Exception;
// 一对多查询,查询订单关联查询订单明细以及商品信息,使用resultMap
public List findUserOrderDetail() throws Exception;
}
OrdersMapperCustom.xml
and username like '%${userCustom.username.trim()}%'
and sex = #{userCustom.sex}
#{id}
select LAST_INSERT_ID()
INSERT INTO USER(username,birthday,sex,address) VALUES(#{username},#{birthday},#{sex},#{address})
delete from user where id=#{id}
update user set username = #{username},birthday=#{birthday},sex=#{sex},address=#{address} where id=#{id}
mybatis和Spring的整合
mybatis和Spring整合的思路
1.让Spring管理SqlSessionFactory
2.让Spring管理mapper对象和DAO
使用Spring和mybatis整合开发mapper代理对象以及原始Dao接口
自动开启事务,自动关闭sqlSession
3.让Spring管理数据源(数据库连接池)
创建整合工程

加入的jar包
1.mybatis3.2.7自身的jar包
2.数据库驱动包
3.spring3.2.0
4.spring和mybatis整合包
从mybatis的官方下载Spring和mybatis整合包

log4j.properties(略)
SqlMapConfig.xml
mybatis配置文件:别名、settings、数据源都不在这里进行配置
applicationContext.xml
1.数据源(dbcp连接池)
2.SqlSessionFactory
2.mapper或DAO
整合开发原始Dao接口
配置SqlSessionFactory
在applicationContext.xml中配置SqlSessionFactory
开发原始DAO
public class UserDaoImpl extends SqlSessionDaoSupport implements UserDao {
public User findUserById(int id) throws Exception {
// 创建SqlSession
SqlSession sqlSession = this.getSqlSession();
// 根据id查询用户信息
User user = sqlSession.selectOne("test.findUserById", id);
return user;
}
}配置原始DAO
测试原始DAO接口
public class UserDaoImplTest {
// 会话工厂
private ApplicationContext applicationContext;
//创建工厂
@Before
public void init() throws IOException{
// 创建Spring容器
applicationContext = new ClassPathXmlApplicationContext("spring/applicationContext.xml");
}
@Test
public void testFindUserById() throws Exception{
UserDao userDao = (UserDao) applicationContext.getBean("userDao");
User user = userDao.findUserById(1);
System.out.println(user);
}
}整合开发mapper代理方法
开发mapper.xml和mapper.java

使用MapperFactoryBean
使用MapperScannerConfigurer(扫描mapper)
测试mapper接口
public class UserMapperTest {
// 会话工厂
private ApplicationContext applicationContext;
//创建工厂
@Before
public void init() throws IOException{
// 创建Spring容器
applicationContext = new ClassPathXmlApplicationContext("spring/applicationContext.xml");
}
@Test
public void testFindUserById() throws Exception {
UserMapper userMapper = (UserMapper) applicationContext.getBean("userMapper");
User user = userMapper.findUserById(1);
System.out.println(user);
}
}mybatis逆向工程(Mybatis Generator)
什么是mybatis的逆向工程
mybatis官方为了提高开发效率,提供自动对表单生成SQL,包括:mapper.xml,mapper.java, 表名.java(po类)

在企业开发中通常是在设计阶段对表进行设计、创建。
在开发阶段根据表结构创建对应的po类。
mybatis逆向工程的方向:由数据表—>java代码
逆向工程使用配置
运行逆向工程 方法:
逆向工程运行所需要的jar包

xml配置
需要使用配置的地方
需要注意的是:涉及到路径时,一定要写绝对路径,相对路径有时是不起作用的。
1.连接数据库的地址和驱动
xml配置使用详解
java程序
通过Java程序生成mapper类、po类public class GeneratorSqlmap {
public void generator() throws Exception{
List warnings = new ArrayList();
boolean overwrite = true;
//指定 逆向工程配置文件
File configFile = new File("generatorConfig.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config,
callback, warnings);
myBatisGenerator.generate(null);
}
public static void main(String[] args) throws Exception {
try {
GeneratorSqlmap generatorSqlmap = new GeneratorSqlmap();
generatorSqlmap.generator();
} catch (Exception e) {
e.printStackTrace();
}
}
} 使用逆向工程生成代码
第一步:配置generatorConfig.xml

第二步配置执行Java程序
执行Java程序后,所生成的代码已经在当前项目中
第三步:将生成的代码拷贝到项目工程中
mybatis逆向工程源代码
此完整代码已上传GitHub(https://github.com/LX1993728/Mybatis_generatorSqlMapCustom)
generatorConfig.xml
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.mybatis.generator.api.MyBatisGenerator;
import org.mybatis.generator.config.Configuration;
import org.mybatis.generator.config.xml.ConfigurationParser;
import org.mybatis.generator.exception.XMLParserException;
import org.mybatis.generator.internal.DefaultShellCallback;
public class GeneratorSqlmap {
public void generator() throws Exception{
List warnings = new ArrayList();
boolean overwrite = true;
//指定 逆向工程配置文件
File configFile = new File("generatorConfig.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config,
callback, warnings);
myBatisGenerator.generate(null);
}
public static void main(String[] args) throws Exception {
try {
GeneratorSqlmap generatorSqlmap = new GeneratorSqlmap();
generatorSqlmap.generator();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Spring与mybatis整合源代码
代码已上传GitHub (https://github.com/LX1993728/spring_mybatis)


package test.lx.mybatis.dao;
import java.util.List;
import test.lx.mybatis.po.User;
/**
* 用户DAO
*
* @author lx
*
*/
public interface UserDao {
// 根据id查询用户信息
public User findUserById(int id) throws Exception;
}package test.lx.mybatis.dao;
import java.util.List;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.support.SqlSessionDaoSupport;
import test.lx.mybatis.po.User;
public class UserDaoImpl extends SqlSessionDaoSupport implements UserDao {
public User findUserById(int id) throws Exception {
// 创建SqlSession
SqlSession sqlSession = this.getSqlSession();
// 根据id查询用户信息
User user = sqlSession.selectOne("test.findUserById", id);
return user;
}
}
SqlMapConfig.xml
package test.lx.mybatis.dao;
import java.io.IOException;
import java.io.InputStream;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Before;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import test.lx.mybatis.po.User;
public class UserDaoImplTest {
// 会话工厂
private ApplicationContext applicationContext;
//创建工厂
@Before
public void init() throws IOException{
// 创建Spring容器
applicationContext = new ClassPathXmlApplicationContext("spring/applicationContext.xml");
}
@Test
public void testFindUserById() throws Exception{
UserDao userDao = (UserDao) applicationContext.getBean("userDao");
User user = userDao.findUserById(1);
System.out.println(user);
}
}package test.lx.mybatis.mapper;
import java.io.IOException;
import org.junit.Before;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import test.lx.mybatis.po.User;
public class UserMapperTest {
// 会话工厂
private ApplicationContext applicationContext;
//创建工厂
@Before
public void init() throws IOException{
// 创建Spring容器
applicationContext = new ClassPathXmlApplicationContext("spring/applicationContext.xml");
}
@Test
public void testFindUserById() throws Exception {
UserMapper userMapper = (UserMapper) applicationContext.getBean("userMapper");
User user = userMapper.findUserById(1);
System.out.println(user);
}
}package test.lx.mybatis.mapper;
import static org.junit.Assert.*;
import java.util.List;
import org.junit.Before;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import test.lx.mybatis.po.Items;
import test.lx.mybatis.po.ItemsExample;
/**
* 切记:
* 不管是查询还是更新,只要涉及到多条记录 不带withBlobs后缀的方法 默认都不会对大文本字段进行操作
* 接口方法名中包含Selective的 表示有选择性的进行操作(只查询、更新、添加为参数复制过的属性对应的字段)
* 接口方法名中包含Example的 表示可以带有条件筛选
*
* @author liuxun
*
*/
public class ItemsMapperTest {
private ApplicationContext applicationContext;
private ItemsMapper itemsMapper;
@Before
public void setUp() throws Exception {
// 创建Spring容器
applicationContext = new ClassPathXmlApplicationContext("spring/applicationContext.xml");
itemsMapper = (ItemsMapper) applicationContext.getBean("itemsMapper");
}
// 自定义条件筛选数量查询
@Test
public void testCountByExample() {
ItemsExample itemsExample = new ItemsExample();
ItemsExample.Criteria criteria = itemsExample.createCriteria();
criteria.andPriceBetween(300.f, 10000.f);
int count = itemsMapper.countByExample(itemsExample);
System.out.println(count);
}
// 自定义条件删除
@Test
public void testDeleteByExample() {
ItemsExample itemsExample = new ItemsExample();
ItemsExample.Criteria criteria = itemsExample.createCriteria();
criteria.andNameLike("%冰箱%"); // 使用like相关属性时 参数外要包括 %%
itemsMapper.deleteByExample(itemsExample);
}
// 根据主键进行删除
@Test
public void testDeleteByPrimaryKey() {
itemsMapper.deleteByPrimaryKey(6);
}
// 表示插入全部字段,若某字段对应属性没有复制,默认插为NULL(自增主键例外)
@Test
public void testInsert() {
Items items = new Items();
items.setName("电视机");
items.setPrice(3000.f);
items.setDetail("乐视高清");
itemsMapper.insert(items);
}
// 选择性插入,插入记录时只对赋值属性对应的字段进行插入
@Test
public void testInsertSelective() {
Items items = new Items();
items.setName("电冰箱");
items.setPrice(2500.f);
items.setDetail("三年包换");
itemsMapper.insertSelective(items);
}
// 自定义条件查询多条记录,包含大文本字段
@Test
public void testSelectByExampleWithBLOBs() {
ItemsExample itemsExample = new ItemsExample();
ItemsExample.Criteria criteria = itemsExample.createCriteria();
criteria.andNameIsNotNull();
List list = itemsMapper.selectByExampleWithBLOBs(itemsExample);
for (Items items : list) {
System.out.println(items.getDetail());
}
}
// 自定义条件查询多条记录,不对大文本字段进行查询
@Test
public void testSelectByExample() {
ItemsExample itemsExample = new ItemsExample();
ItemsExample.Criteria criteria = itemsExample.createCriteria();
criteria.andNameIsNotNull();
List list = itemsMapper.selectByExample(itemsExample);
for (Items items : list) {
System.out.println(items.getDetail()); // 大文本字段值为null
}
}
// 按照主键值进行查询单条记录
@Test
public void testSelectByPrimaryKey() {
Items items = itemsMapper.selectByPrimaryKey(1);
System.out.println(items.getDetail());
}
// 自定义条件更新(为POJO赋值过的属性对应的字段),不对PO类中的大文本字段进行更新
// 如果PO类对象中的一些属性未赋值,不做任何改变,只更新赋值过的属性 即有选择性的更新
@Test
public void testUpdateByExampleSelective() {
// 此处方法名后缀Selective:表示只对参数record中设置过的属性对应的字段进行更新 没有设置过的不做任何改变
// record:封装更新后的结果值
// example: 封装 筛选更新记录条件
ItemsExample example = new ItemsExample();
ItemsExample.Criteria criteria = example.createCriteria();
Items record = new Items();
record.setPrice(2500.f);
criteria.andNameLike("%机%");
itemsMapper.updateByExampleSelective(record, example);
}
// 根据外键强制全部更新数据(没有赋值的映射为NULL) 包含大文本字段
@Test
public void testUpdateByExampleWithBLOBs() {
}
// 根据外键强制全部更新数据(没有赋值的映射为NULL) 不包含大文本字段
@Test
public void testUpdateByExample() {
}
// 根据外键有选择性的更新数据 不包含大文本字段 必须为参数items设置主键值
@Test
public void testUpdateByPrimaryKeySelective() {
}
// 根据外键全部更新数据(没有赋值的映射为NULL) 包含大文本字段 必须为参数items设置主键值
@Test
public void testUpdateByPrimaryKeyWithBLOBs() {
}
// 根据外键有全部更新数据(没有赋值的映射为NULL) 不包含大文本字段 必须为参数items设置主键值
@Test
public void testUpdateByPrimaryKey() {
}
}