西瓜书《机器学习》第三章部分课后题
目录
- 题目3.2
- 题目3.3
- TensorFlow版本
- 造轮子版本
- 题目3.5
- 题目3.6
- Acknowledge
题目3.2
试证明,对于参数 w \bm{w} w,对率回归的目标函数(3.18)是非凸的,但其对数似然函数(3.27)是凸的。
答案可参考:https://blog.csdn.net/icefire_tyh/article/details/52069025
题目3.3
编程实现对率回归,并给出西瓜数据集 3.0 α 3.0 \alpha 3.0α上的结果。
TensorFlow版本
代码参考自:https://blog.csdn.net/qq_25366173/article/details/80223523
import tensorflow as tf
import matplotlib.pyplot as plt
data_x = [[0.697, 0.460], [0.774, 0.376], [0.634, 0.264], [0.608, 0.318], [0.556, 0.215], [0.403, 0.237], [0.481, 0.149], [0.437, 0.211],
[0.666, 0.091], [0.243, 0.267], [0.245, 0.057], [0.343, 0.099], [0.639, 0.161], [0.657, 0.198], [0.360, 0.370], [0.593, 0.042], [0.719, 0.103]]
data_y = [[1], [1], [1], [1], [1], [1], [1], [1], [0], [0], [0], [0], [0], [0], [0], [0], [0]]
W = tf.compat.v1.get_variable(name="weight", dtype=tf.compat.v1.float32, shape=[2, 1])
b = tf.compat.v1.get_variable(name="bias", dtype=tf.compat.v1.float32, shape=[])
x = tf.compat.v1.placeholder(name="x_input", dtype=tf.compat.v1.float32, shape=[None, 2])
y_ = tf.compat.v1.placeholder(name="y_output", dtype=tf.compat.v1.float32, shape=[None, 1])
ty = tf.compat.v1.matmul(x, W) + b
y = tf.compat.v1.sigmoid(tf.compat.v1.matmul(x, W) + b)
loss = tf.compat.v1.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=ty, labels=y_))
trainer = tf.compat.v1.train.AdamOptimizer(0.04).minimize(loss)
with tf.compat.v1.Session() as sess:
steps = 500
sess.run(tf.compat.v1.global_variables_initializer())
for i in range(steps):
sess.run(trainer, feed_dict={x : data_x, y_ : data_y})
for i in range(len(data_x)):
if data_y[i] == [1]:
plt.plot(data_x[i][0], data_x[i][1], 'ob')
else:
plt.plot(data_x[i][0], data_x[i][1], '^g')
[[w_0, w_1], b_] = sess.run([W, b])
w_0 = w_0[0]
w_1 = w_1[0]
x_0 = -b_ / w_0 #(x_0, 0)
x_1 = -b_ / w_1 #(0, x_1)
plt.plot([x_0, 0], [0, x_1])
plt.show()
运行结果如下:
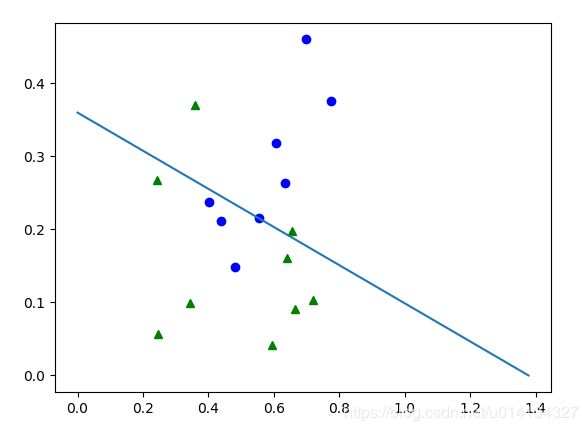
TensorFlow快速入门:
(1)令人困惑的TensorFlow!
(2)令人困惑的 TensorFlow!(II)
造轮子版本
import numpy as np
import math
import matplotlib.pyplot as plt
data_x = [[0.697, 0.460], [0.774, 0.376], [0.634, 0.264], [0.608, 0.318], [0.556, 0.215], [0.403, 0.237],
[0.481, 0.149], [0.437, 0.211],
[0.666, 0.091], [0.243, 0.267], [0.245, 0.057], [0.343, 0.099], [0.639, 0.161], [0.657, 0.198],
[0.360, 0.370], [0.593, 0.042], [0.719, 0.103]]
data_y = [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
def combine(beta, x):
x = np.mat(x + [1.]).T
return beta.T * x
def predict(beta, x):
return 1 / (1 + math.exp(-combine(beta, x)))
def p1(beta, x):
return math.exp(combine(beta, x)) / (1 + math.exp(combine(beta, x)))
beta = np.mat([0.] * 3).T
steps = 50
for step in range(steps):
param_1 = np.zeros((3, 1))
for i in range(len(data_x)):
x = np.mat(data_x[i] + [1.]).T
param_1 = param_1 - x * (data_y[i] - p1(beta, data_x[i]))
param_2 = np.zeros((3, 3))
for i in range(len(data_x)):
x = np.mat(data_x[i] + [1.]).T
param_2 = param_2 + x * x.T * p1(beta, data_x[i]) * (1 - p1(beta, data_x[i]))
last_beta = beta
beta = last_beta - param_2.I * param_1
if np.linalg.norm(last_beta.T - beta.T) < 1e-6:
print(step)
break
for i in range(len(data_x)):
if data_y[i] == 1:
plt.plot(data_x[i][0], data_x[i][1], 'ob')
else:
plt.plot(data_x[i][0], data_x[i][1], '^g')
w_0 = beta[0, 0]
w_1 = beta[1, 0]
b = beta[2, 0]
print(w_0, w_1, b)
x_0 = -b / w_0 #(x_0, 0)
x_1 = -b / w_1 #(0, x_1)
plt.plot([x_0, 0], [0, x_1])
plt.show()
运行结果如下:
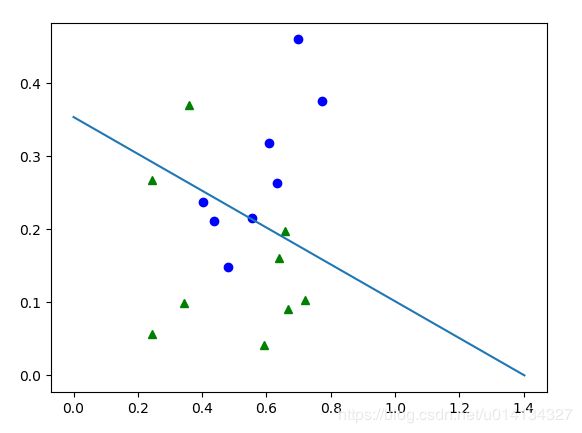
(有兴趣自己造轮子且喜欢尝试优化代码的同学可以参考吴恩达关于向量化的公开课视频:deeplearning.ai,网易公开课)
题目3.5
编程实现线性判别分析,并给出西瓜数据集 3.0 α 3.0 \alpha 3.0α上的结果。
import numpy as np
import math
import matplotlib.pyplot as plt
data_x = [[0.697, 0.460], [0.774, 0.376], [0.634, 0.264], [0.608, 0.318], [0.556, 0.215], [0.403, 0.237],
[0.481, 0.149], [0.437, 0.211],
[0.666, 0.091], [0.243, 0.267], [0.245, 0.057], [0.343, 0.099], [0.639, 0.161], [0.657, 0.198],
[0.360, 0.370], [0.593, 0.042], [0.719, 0.103]]
data_y = [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
mu_0 = np.mat([0., 0.]).T
mu_1 = np.mat([0., 0.]).T
count_0 = 0
count_1 = 0
for i in range(len(data_x)):
x = np.mat(data_x[i]).T
if data_y[i] == 1:
mu_1 = mu_1 + x
count_1 = count_1 + 1
else:
mu_0 = mu_0 + x
count_0 = count_0 + 1
mu_0 = mu_0 / count_0
mu_1 = mu_1 / count_1
S_w = np.mat([[0, 0], [0, 0]])
for i in range(len(data_x)):
# 注意:西瓜书的输入向量是列向量形式
x = np.mat(data_x[i]).T
if data_y[i] == 0:
S_w = S_w + (x - mu_0) * (x - mu_0).T
else:
S_w = S_w + (x - mu_1) * (x - mu_1).T
u, sigmav, vt = np.linalg.svd(S_w)
sigma = np.zeros([len(sigmav), len(sigmav)])
for i in range(len(sigmav)):
sigma[i][i] = sigmav[i]
sigma = np.mat(sigma)
S_w_inv = vt.T * sigma.I * u.T
w = S_w_inv * (mu_0 - mu_1)
w_0 = w[0, 0]
w_1 = w[1, 0]
tan = w_1 / w_0
sin = w_1 / math.sqrt(w_0 ** 2 + w_1 ** 2)
cos = w_0 / math.sqrt(w_0 ** 2 + w_1 ** 2)
print(w_0, w_1)
for i in range(len(data_x)):
if data_y[i] == 0:
plt.plot(data_x[i][0], data_x[i][1], "go")
else:
plt.plot(data_x[i][0], data_x[i][1], "b^")
plt.plot(mu_0[0, 0], mu_0[1, 0], "ro")
plt.plot(mu_1[0, 0], mu_1[1, 0], "r^")
plt.plot([-0.1, 0.1], [-0.1 * tan, 0.1 * tan])
for i in range(len(data_x)):
x = np.mat(data_x[i]).T
ell = w.T * x
ell = ell[0, 0]
if data_y[i] == 0:
plt.scatter(cos * ell, sin * ell, marker='o', c='', edgecolors='g')
else:
plt.scatter(cos * ell, sin * ell, marker='^', c='', edgecolors='b')
plt.show()
运行结果如下:

放大投影部分,效果如下:
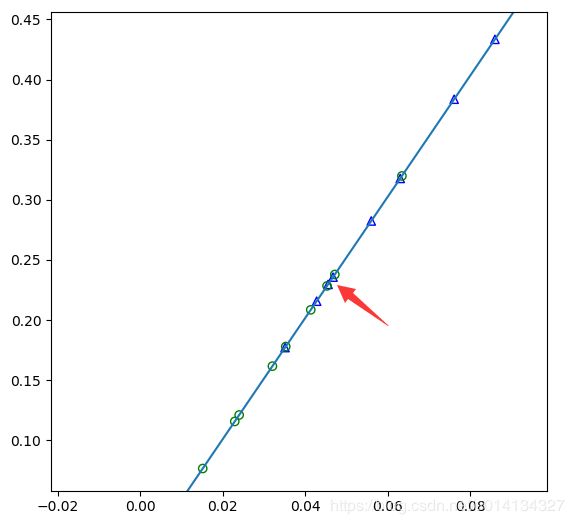
降维后的分类超平面为上图红色箭头所指点(一维空间下通过学习得到该点,大于该点值的为一类,小于该点值的为另一类),与题目3.3的运行结果对应,蓝色点有3个分类错误,绿色点有2个分类错误。从这道题的实践可见,高维线性不可分,降维后依旧线性不可分。
题目3.6
线性判别分析仅在线性可分数据上能获得理想结果,试设计一个改进方法,使其能较好地用于非线性可分数据。
在当前维度下数据线性不可分,降维后依旧线性不可分,那么升维呢?即将当前数据 x \bm{x} x映射到更高维度上 ϕ ( x ) \phi(\bm{x}) ϕ(x)。跟着题目3.5的思路,这回从一维变到二维,看看效果如何。
考虑 x 1 = ( 0.1 ) \bm{x}_1 = (0.1) x1=(0.1), x 2 = ( − 0.35 ) \bm{x}_2 = (-0.35) x2=(−0.35), x 3 = ( 3 ) \bm{x}_3 = (3) x3=(3), x 4 = ( − 4.1 ) \bm{x}_4 = (-4.1) x4=(−4.1), x 5 = ( 2.7 ) \bm{x}_5= (2.7) x5=(2.7),对应标签为 y 1 = 0 y_1 = 0 y1=0, y 2 = 0 y_2 = 0 y2=0, y 3 = 1 y_3 = 1 y3=1, y 4 = 1 y_4 = 1 y4=1, y 5 = 1 y_5 = 1 y5=1,此时数据在一维空间下明显线性不可分。若设计 ( x 1 ′ , x 2 ′ ) = ϕ ( x ) = ( x 1 , x 1 2 ) (x'_1, x'_2) = \phi(\bm{x}) = (x_1, x_1^2) (x1′,x2′)=ϕ(x)=(x1,x12),可以得到下图:
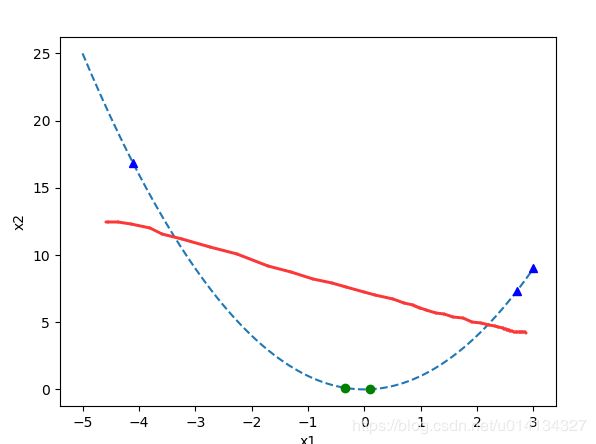
此时数据在二维空间下是线性可分的(红色线即为分类超平面)。
若能够找到合适的映射函数 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅),则可解决低维空间数据线性不可分问题,然而在实战中,找到这样一个合适的映射函数并非易事,预习到第6章SVM可以看到核函数 κ \kappa κ的作用,这里不再扩展。
Acknowledge
题目3.2参考自:
https://blog.csdn.net/icefire_tyh/article/details/52069025
感谢@四去六进一
题目3.3参考自:
https://blog.csdn.net/qq_25366173/article/details/80223523
感谢@Liubinxiao
https://blog.csdn.net/da_kao_la/article/details/81908154
感谢@da_kao_la
TensorFlow入门参考自:
https://mp.weixin.qq.com/s/JVSxFFIyW4yCuV1LoIKM3g
感谢@Jacob Buckman、@机器之心
https://mp.weixin.qq.com/s/P8oJV1UUr0cHQ9iulcPAmw
感谢@Jacob Buckman、@机器之心
题目3.5参考自:
https://blog.csdn.net/macunshi/article/details/80756016
感谢@言寺之风雅颂
https://blog.51cto.com/13959448/2327130
感谢@myhaspl
https://www.cnblogs.com/Jerry-Dong/p/8177094.html
感谢@从菜鸟开始