python迷你项目:8个知识点实现今日A股涨跌幅排行榜前10名股票信息
我在博文4行代码获取今日股票数据中使用tushare库进行爬取了今日股市的信息,以下的代码编写了如何通过pandas中对DF数据类型的操作找到今日股市涨幅榜和跌幅榜的前10支股票。
这里需要用到的知识点有:
1.用.sort_values()方法对DF数据进行排序。
2.使用[‘column’]方法取DF中的某一列
3.用list对Series数据转换成列表
4.使用生成表达式用range方法来产生等差数列列表。([ i for i in range(1,total_count+1)])
5.使用切片方法来去部分数据
6.使用len()方法来获得列表的长度
7.用字典和列表来生成DataFrame
8.函数的编写方法。
import pandas as pd
stock_data = pd.read_csv('stock_data.csv')
def get_top_10_perfomers():
top_performers = stock_data.sort_values(by = 'changepercent',ascending = False)
tp_names = list(top_performers['name'])
tp_chpct = list(top_performers['changepercent'])
tp_stkid = list(top_performers['code'])
total_count = len(top_performers)
top_list = pd.DataFrame({'股票代码':tp_stkid,'股票名':tp_names,'涨幅/%':tp_chpct},index = [ i for i in range(1,total_count+1)])
top_10_performers = top_list[:10]
return top_10_performers
def get_top_10_droppers():
top_performers = stock_data.sort_values(by = 'changepercent')
tp_names = list(top_performers['name'])
tp_chpct = list(top_performers['changepercent'])
tp_stkid = list(top_performers['code'])
total_count = len(top_performers)
top_list = pd.DataFrame({'股票代码':tp_stkid,'股票名':tp_names,'涨幅/%':tp_chpct},index = [ i for i in range(1,total_count+1)])
top_10_performers = top_list[:10]
return top_10_performers
print("**********涨幅榜前10************")
print(get_top_10_perfomers())
print("**********跌幅榜前10************")
print(get_top_10_droppers())
运行后得到结果如下:
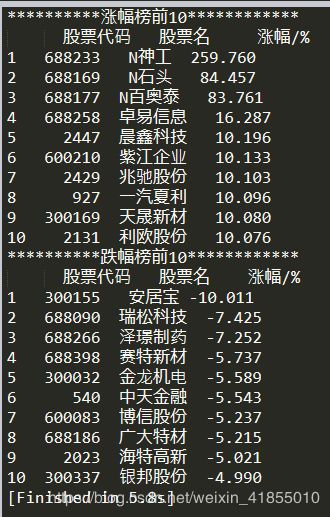
可以看出,之用5.8秒时间,就完成了这个任务,非常高效。