PostgreSQL的高级特性>窗口函数
这篇文章纯属搬运,特此贴出链接https://www.cnblogs.com/funnyzpc/p/9311281.html#undefined,感谢这位大神。这是pg官网关于***窗口函数***的官方文档链接http://www.postgres.cn/docs/9.3/functions-window.html
DROP TABLE IF EXISTS "public"."products";
CREATE TABLE "public"."products" (
"id" varchar(10) COLLATE "default",
"name" text COLLATE "default",
"price" numeric,
"uid" varchar(14) COLLATE "default",
"type" varchar(100) COLLATE "default"
)
WITH (OIDS=FALSE);
BEGIN;
INSERT INTO "public"."products" VALUES ('0006', 'iPhone X', '9600', null, '电器');
INSERT INTO "public"."products" VALUES ('0012', '电视', '3299', '4', '电器');
INSERT INTO "public"."products" VALUES ('0004', '辣条', '5.6', '4', '零食');
INSERT INTO "public"."products" VALUES ('0007', '薯条', '7.5', '1', '零食');
INSERT INTO "public"."products" VALUES ('0009', '方便面', '3.5', '1', '零食');
INSERT INTO "public"."products" VALUES ('0005', '铅笔', '7', '4', '文具');
INSERT INTO "public"."products" VALUES ('0014', '作业本', '1', null, '文具');
INSERT INTO "public"."products" VALUES ('0001', '鞋子', '27', '2', '衣物');
INSERT INTO "public"."products" VALUES ('0002', '外套', '110.9', '3', '衣物');
INSERT INTO "public"."products" VALUES ('0013', '围巾', '93', '5', '衣物');
INSERT INTO "public"."products" VALUES ('0008', '香皂', '17.5', '2', '日用品');
INSERT INTO "public"."products" VALUES ('0010', '水杯', '27', '3', '日用品');
INSERT INTO "public"."products" VALUES ('0015', '洗发露', '36', '1', '日用品');
INSERT INTO "public"."products" VALUES ('0011', '毛巾', '15', '1', '日用品');
INSERT INTO "public"."products" VALUES ('0003', '手表', '1237.55', '5', '电器');
INSERT INTO "public"."products" VALUES ('0016', '绘图笔', '15', null, '文具');
INSERT INTO "public"."products" VALUES ('0017', '汽水', '3.5', null, '零食');
COMMIT;
这我先用第一个函数row_number() ,一句即可实现>
select type,name,price,row_number() over(order by price asc) as idx from products ;
查询结果>

用窗口函数的好处不仅仅可实现序号列,还可以在over()内按指定的列排序,上图是按照price列升序。
这里,对于以上提到的一个问题,根据上面的数据 我再做个扩充>如果需要在类别(type)内按照价格(price) 升序排列(就是在类别内做排序),该怎么做呢?
当然也很简单,只需要在窗口(over())中声明分隔方式 Partition .
分类排序序号,row_number() 实现>
select type,name,price,row_number() over(PARTITION by type order by price asc) as idx from products ;
查询结果>

上面的问题这里需求完美实现,额,这里其实还可以做个扩充,你可以注意到零食类别内的 方便面和汽水价格是一样的,如何将零食和汽水并列第一呢?答案是:用窗口函数>rank()
分类排序序号并列, rank() 实现>
SELECT type,name,price,rank() over(partition by type order by price asc) from products;
查询结果>
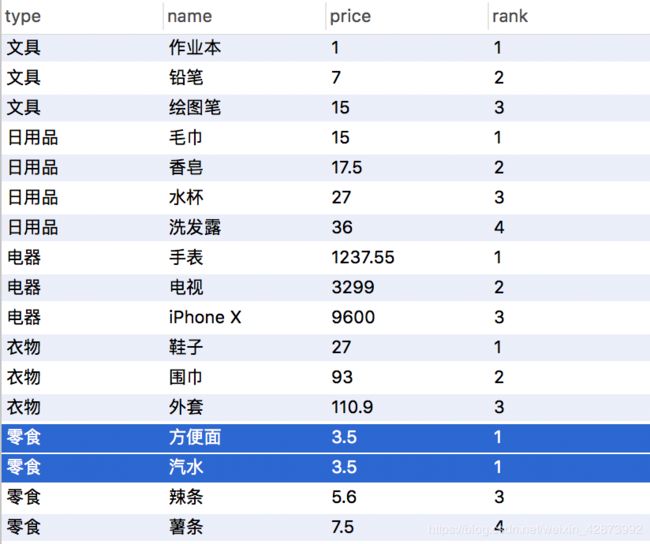
需求又完美的实现了,但,注意到没,零食类别中的第三个 辣条 排到第三了,如果这里需要在类别里面能保持序号不重不少(将辣条排名至第二),如何实现呢?答案>使用窗口函数 dense_rank()
分类排序序号并列顺序,dense_rank() 实现>
SELECT type,name,price,dense_rank() over(partition by type order by price asc) from products;
SQL输出>

OK,以上的几个窗口函数已经能实现大多数业务需求了,如果有兴趣可以看看一些特殊业务可能用到的功能,比如说如何限制序号在0到1之间排序呢?
限制序号在0~1之间(0作为第一个序),窗口函数 percernt_rank() >
SELECT type,name,price,percent_rank() over(partition by type order by price asc) from products;
SQL语句输出>
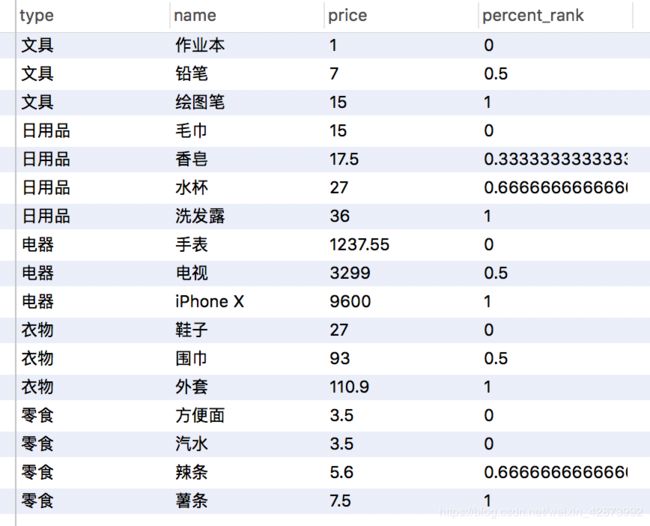
注意:上面的percernt_rank()函数默认是从0开始排序的,如果需要使用相对0~1之间的排名,需要这样:
限制序号在0~1之间相对排名,窗口函数 cume_dist() 实现>
SELECT type,name,price,cume_dist() over(partition by type order by price asc) from products;
SQL语句输出>
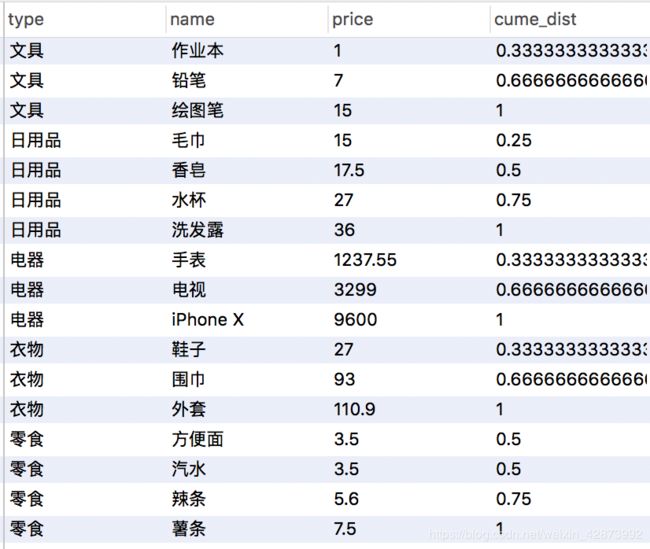
注意:上面的序号是相对于0开始排序的。
对于排序序号还可以限制最大序号,这样做:
限制最大序号为指定数字序号 ntile(val1) 实现 >
SELECT type,name,price,ntile(2) over(partition by type order by price asc) from products;
SQL语句输出 >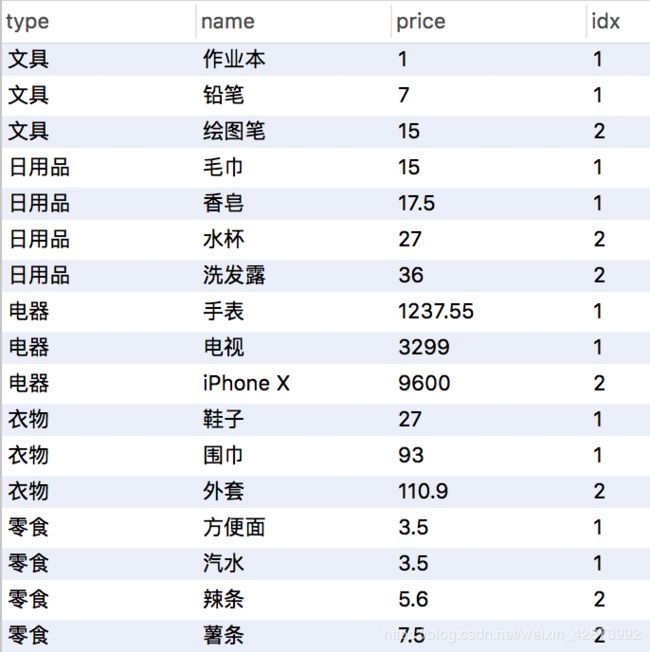
窗口函数还可以实现在子分类排序的情况下取偏移值,这样实现>
获取到排序数据的每一项的偏移值(向下偏移) , lag(val1,val2,val3) 函数实现>
SELECT id,type,name,price,lag(id,1,'') over(partition by type order by price asc) as topid from products;
SQL语句输出 >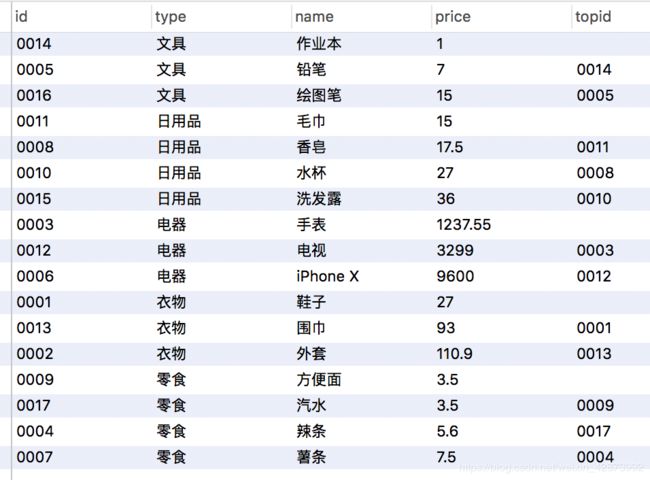
注意:函数lag(val1,val2,val3) 中的三个参数分别为->(输出的上一条记录的字段,偏移值,无偏移值的默认值);以上这里的偏移值为1,偏移字段为id,无偏移默认值为空(’’)
若获取数据项偏移值(向上偏移) , lead(val1,val2,val3)>
SELECT id,type,name,price,lead(id,1,'') over(partition by type order by price asc) as downid from products;
SQL 语句输出 >
当然,窗口函数还可以实现每个子类排序中的第一项的某个字段的值,可以这样实现:
获取分类子项排序中的第一条记录的某个字段的值, first_value(val1) 实现>
SELECT id,type,name,price,first_value(name) over(partition by type order by price asc) from products;
SQL语句输出>
注意:以上函数取的是排序子类记录中的第一条记录的name字段。
当然也可以向下取分类排序中的最后一条记录的某个字段, last_value(val1)实现>
SELECT id,type,name,price,last_value(name) over(partition by type order by price range between unbounded preceding and unbounded following) from products; -- order by type asc ;-- ,price asc;
SQL 语句输出 >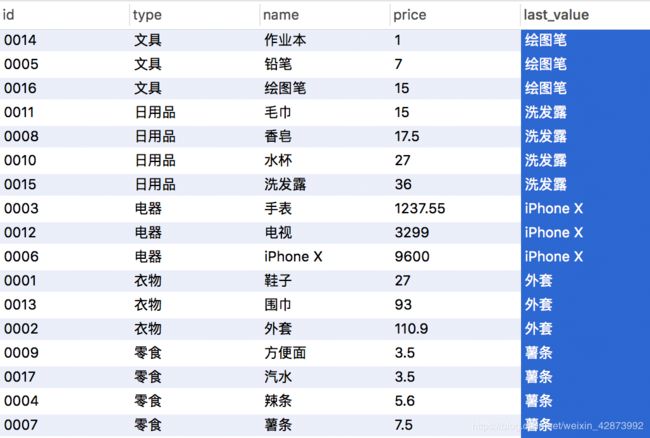
这里需要说明的是,当取分类在最后一条记录的时候 自然排序下不可以在over() 使用排序字段,不然取得的值为相对于当前记录的值,故这里按价格(price) 升序的时候指定 排序字段 -> range between unbounded preceding and unbounded following
窗口函数还能在分类排序下取得指定序号记录的某个字段,这样:
取得排序字段项目中指定序号记录的某个字段值, nth_value(val1,val2)>
SELECT id,type,name,price,nth_value(name,2) OVER(partition by type order by price range between unbounded preceding and unbounded following ) from products;
SQL语句输出 >
窗口函数在单独使用的时候能省略很多不必要的查询 ,比如子查询、聚合查询,当然窗口函数能做得更多(配合聚合函数使用的时候) ,额,这里我给出一个示例 >
SQL查询语句 ,窗口函数+聚合函数 实现 >
sum(price) over (partition by type) 类别金额合计,
(sum(price) over (order by type))/sum(price) over() 类别总额占所有品类商品百分比,
round(price/(sum(price) over (partition by type rows between unbounded preceding and unbounded following)),3) 子除类别百分比,
rank() over (partition by type order by price desc) 排名,
sum(price) over() 金额总计
from products ORDER BY type,price asc;
SQL 语句输出>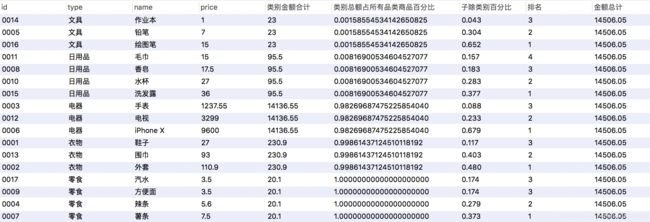
上面的语句看起来会有点儿晕,查询语句子项就像是在输出参数项里面直接写子查询的感觉,事实上为使语句有更好的可读性,窗口条件可以放在from后面 ,这样子>
select
id,type,name,price,
sum(price) over w1 类别金额合计,
(sum(price) over (order by type))/sum(price) over() 类别总额占所有品类商品百分比,
round(price/(sum(price) over w2),3) 子除类别百分比,
rank() over w3 排名,
sum(price) over() 金额总计
from
products
WINDOW
w1 as (partition by type),
w2 as (partition by type rows between unbounded preceding and unbounded following),
w3 as (partition by type order by price desc)
ORDER BY
type,price asc;