DataX3.0离线同步工具介绍
DataX3.0离线同步工具介绍
一. DataX3.0概览
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
(这是一个单机多任务的ETL工具)
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
设计理念
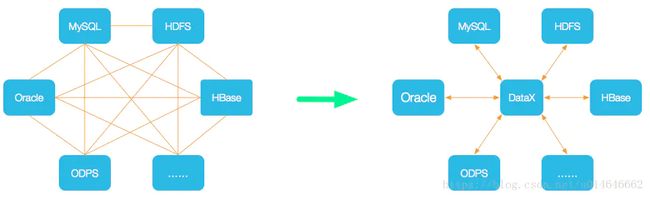
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
此前已经开源DataX1.0版本,此次介绍为阿里云开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。Github主页地址:https://github.com/alibaba/DataX
二、DataX3.0框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
三. DataX3.0插件体系
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南
字段名 |
类型 |
备注 |
name |
varchar |
|
age |
int |
|
age_true |
int |
并向其中插入40条数据,如表2-2所示。
表2-2 测试表数据
| name | age | age_true |
|---|---|---|
| tom | 23 | |
| tom | 23 | |
| tom | 23 | |
| tom | 23 | |
| tom | 23 | |
| tom | 23 | |
| tom | 23 | |
| tom | 23 | |
| ... | ... |
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": ["name","age"],
"where": "age<100",
"connection": [
{
"table": [
"person"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "root",
"password": "123456",
"column": ["name","age_true"],
"connection": [
{
"table": [
"person"
],
"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8"
}
]
}
}
}
],
"setting": {
"speed": {
"channel": 1,
"byte": 104857600
},
"errorLimit": {
"record": 10,
"percentage": 0.05
}
}
}
它由三部分组成,分别是读,写和通用配置。
Reader部分,也就是读,常用以下几种参数,如表2-3所示。
表2-3 读参数表
参数名 |
解释 |
备注 |
name |
与要读取的数据库一致 |
字符串 |
jdbcUrl |
数据库链接 |
数组 会自动选择一个合法的链接 可以填写连接附件控制信息 |
username |
用户名 |
字符串,数据库的用户名 |
password |
密码 |
字符串,数据库的密码 |
table |
要同步的表名 |
数组,需保证表结构一致 |
column |
要同步的列名 |
数组 |
where |
选取的条件 |
字符串 |
querySql |
自定义查询语句 |
会自动忽略上述的同步条件 |
Writer部分,也就是写,常用以下几种参数,如表2-4所示。
表2-4 写参数表
参数名 |
解释 |
备注 |
name |
与要读取的数据库一致 |
字符串 |
jdbcUrl |
数据库链接 |
字符串 不和writer一样 可以填写连接附件控制信息 |
username |
用户名 |
字符串,数据库的用户名 |
password |
密码 |
字符串,数据库的密码 |
table |
要同步的表名 |
数组,需保证表结构一致 |
column |
要同步的列名 |
列名可以不对应,但是类型和总的个数要一致 |
preSql |
写入前执行的语句 |
数组,比如清空表等 |
postSql |
写入后执行的语句 |
数组 |
writeMode |
写入方式,默认为insert |
insert/replace/update |