Python基础爬虫课设
文章目录
- MovieSpider
- 80sMovieSpider
去年上的Python课,现在想把做的课设发出来。
制作过程其实还蛮坎坷的,因为第一次做,需要下载很多爬虫用的库,同时还需要用到HTML之类的知识。
实际上就是一个简单的网络爬虫,爬取电影资源链接并保存在指定路径中,这里选用的是电影天堂和80s电影两个网站,所以我写了两个py文件。
MovieSpider
moviespider用的是电影天堂,网站好像过了一年换掉了,不过代码中只需要更改网站url。
想利用网站内的搜索功能,于是加入了chromedriver来模拟鼠标点击等操作。
运行过程:
1.首先输入想要搜索的资源,将字符串赋值给kw
2.查看路径存不存在,若不存在创建路径new_path
3.调用Search(),传递kw,模拟浏览器执行搜索工作,并把网页url传递给下一函数GetLink()
4.调用GetLink(),读取该网页的html,运用xpath匹配搜索到的记录链接保存在列表Nodes里,传递每一个搜索到的超链接 fullurl 和截取的文件名 filename
5.调用GetSourse(),打开所有搜索到的链接并读取html,运用正则表达式匹配到 ftp:// 开头的下载链接保存到列表fulllink里,遍历fulllink将下载链接写入txt文件里
注意事项:
1.先试试import selenium,如果出现错误,需要下载selenium包
2.16行的webdriver.Chrome()如果出现错误,需要下载对应的chromedriver
简单来说就是要根据自己的谷歌浏览器版本找到对应的chromedriver版本下载,下载完成后解压并将其放入谷歌浏览器的安装路径的application文件夹中,还需要在环境变量path中添加一个新的环境变量
3.27行和52行的useragent根据自己的电脑自行更改
4.71行new_path可以自行更改,并确保路径结尾有“/”字符
代码如果有错误或者需要改进的地方请指出
给出源代码:
import urllib
import os
import re
from selenium import webdriver #需要下载安装selenium
from lxml import etree
#模拟浏览器搜索指定电影
def Search(url,key,path):
global browser
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options) #需要下载chromedriver,放在指定路径,并指定环境变量path,详情见https://www.cnblogs.com/cnhkzyy/p/7294119.html
browser.get(url)
browser.find_element_by_name('keyboard').clear()
browser.find_element_by_name('keyboard').send_keys(key)
browser.find_element_by_name('Submit').click()
new_url = browser.current_url
GetLink(new_url,path)
#获取搜索到的各个网页链接,传递要创建写入的文件名
def GetLink(url,path):
#此headers中的useragent需要根据自己的电脑更改
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
request = urllib.request.Request(url,headers=headers)
page = urllib.request.urlopen(request).read().decode('gbk')
tree = etree.HTML(page)
Nodes = tree.xpath('//*[@class="ulink"]') #利用xpath匹配网页链接
print("查找到记录",len(Nodes),"条")
for node in Nodes:
url=node.xpath("@href")[0]
if re.match(r'/', url):
filename=node.xpath("@title")[0].replace("/"," ")\
.replace("\\"," ")\
.replace(":"," ")\
.replace("*"," ")\
.replace("?"," ")\
.replace("\""," ")\
.replace("<", " ")\
.replace(">", " ")\
.replace("|", " ")
fullurl = "https://www.xiaopian.com/" + url
GetSourse(fullurl,filename,path)
#获取ftp下载链接并写入txt文件
def GetSourse(url,filename,path):
#此headers中的useragent需要根据自己的电脑更改
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
request = urllib.request.Request(url, headers = headers)
page = urllib.request.urlopen(request).read().decode('gbk')
pattern = re.compile('(ftp://[\s\S]*?)') #正则表达式匹配ftp链接
fulllink = re.findall(pattern, str(page))
#写入txt文件
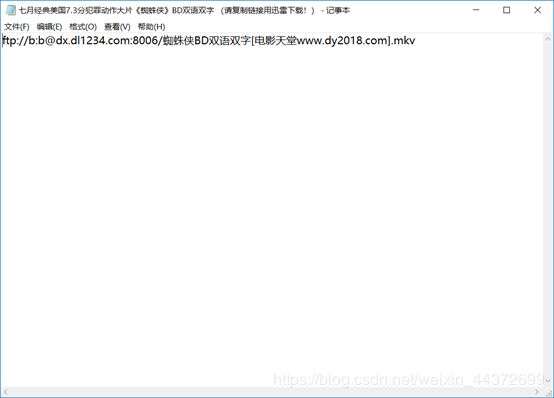
fullfilename = filename + " (请复制链接用迅雷下载!)"
new_path = path + fullfilename + ".txt"
f = open(new_path, 'w')
for link in fulllink:
f.write(link+"\n")
f.close()
print("下载完成!请在'"+path+"'路径下查看链接文件~")
if __name__=='__main__':
kw = input("请输入您想搜索的电影名:")
#创建路径,请按照自己的路径更改
new_path = "C:/Users/15261/Desktop/电影资源/"
if not os.path.isdir(new_path):
os.mkdir(new_path) #如果没有,创建新路径
print("创建目录成功!------"+new_path)
url = "https://www.xiaopian.com/html/gndy/dyzz"
Search(url,kw,new_path)
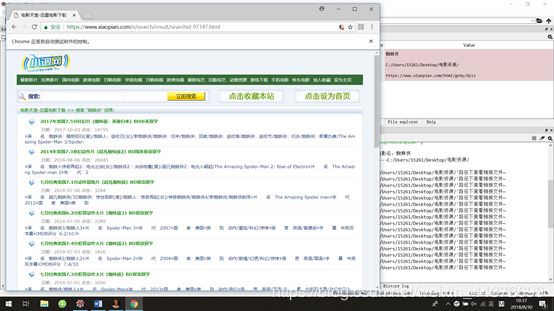
界面显示:


80sMovieSpider
此版本的功能是将电影分类后下载指定页码的全部电影下载链接,使用的网站url:https://www.80s.tw/movie/list/
过程:
1.首先需要按照提示一步一步选择自己想要的电影分类,“最新”和“全部”选项直接按回车,其他选项输入后面的序号即可
2.输入页码赋值给num
3.如果没有指定路径new_path,将自动创建路径
4.所有输入的电影分类信息将会正确匹配到确切的网址,算法是77行
5.调用Spider(),将指定页码的网址最终确定为fullurl,并传递给LoadPage()
6.调用LoadPage(),读取网页的html,运用正则表达式匹配到当前网页的所有电影超链接,保存到列表link_list中,遍历link_list确定最终url为fulllink并逐个传递
7.调用GetSourse(),读取各个网页的html,运用正则表达式匹配截取“thunder://”开头的下载链接和文件名filename,遍历fulllink将所有下载链接写入txt文件
注意事项:
1.请确保分类信息输入正确
2.25行和41行的useragent需根据自己的电脑自行更改
3.71行的new_path可自行更改
代码如果有错误或者需要改进的地方请指出:
import urllib
import os
import re
#页面提取
def Spider(url,num,path):
if num == '1':
fullurl = url + '-p/'
print(fullurl)
else:
fullurl = url + '-p/' + num
print(fullurl)
LoadPage(fullurl,path)
print("数据抓取完成!")
#加载电影网页链接
def LoadPage(url,path):
#此headers中的useragent需要根据自己的电脑更改
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"}
request = urllib.request.Request(url,headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
pattern = re.compile('') #匹配此页中所有电影网页链接
#将电影网页超链接查找到并传递给下一函数
link_list = re.findall(pattern, str(html))
for link in link_list:
fulllink = "https://www.80s.tw" + link
print("链接:",fulllink)
GetSourse(fulllink,path)
#在网页中获取链接地址并写入txt文件
def GetSourse(url,path):
#此headers中的useragent需要根据自己的电脑更改
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"}
request = urllib.request.Request(url, headers = headers)
try:
html = urllib.request.urlopen(request).read().decode('utf-8')
pattern1 = re.compile('') #匹配下载链接
pattern2 = re.compile('') #匹配要创建的电影文件名
fulllink = re.findall(pattern1, str(html))
#找到要创建的电影文件名,并创建txt文件写入下载链接
filename = re.findall(pattern2, str(html))
fullfilename = str(filename)+" (请复制链接用迅雷下载!)"
file_path = path + fullfilename + ".txt"
f = open(file_path, 'w')
for link in fulllink:
f.write(link+"\n")
f.close()
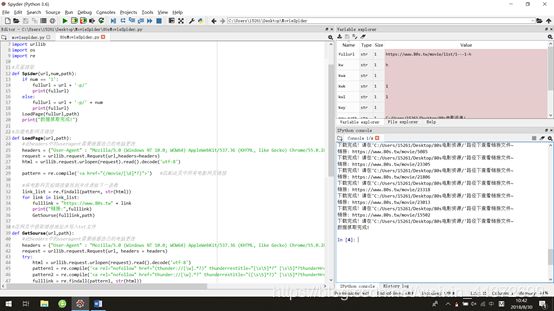
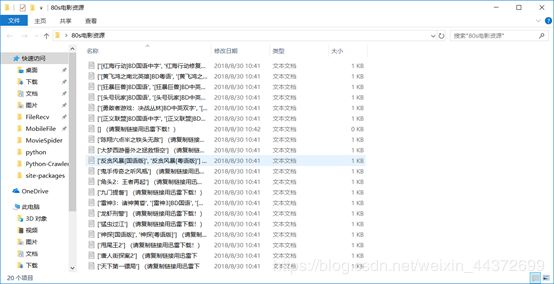
print("下载完成!请在'"+path+"'路径下查看链接文件~")
except:
print("下载失败!")
if __name__=='__main__':
print("========输入序号即可,“最新”和“全部”选项直接按回车========")
kw = input("请选择(最新 ,热门 h,好评 g):")
kwl = input("请选择语言(全部 ,国语 1,英语 2):")
kwk = input("请选择类型(全部 ,动作 1,喜剧 2,爱情 3,科幻 4,灾难 5,恐怖 6,悬疑 7,战争 9,犯罪 10,惊悚 11,动画 12):")
kwy = input("请选择年份(全部 ,2018,2017,2016,2015,2014,2013,2012,2011,2010,2009,2008,2007):")
kwa = input("请选择地区(全部 ,大陆 1,香港 2,台湾 3,美国 4,法国 5,英国 6,日本 7,韩国 8):")
num = input("请输入您想搜索的页码(最大450页,每页20部电影):")
#创建路径,请按照自己的电脑更改路径
new_path = "C:/Users/15261/Desktop/80s电影资源/"
if not os.path.isdir(new_path):
os.mkdir(new_path) #如果没有,创建新路径
print("创建目录成功!------"+new_path)
url = "https://www.80s.tw/movie/list/"
fullurl = url + kwk + '-' + kwy + '-' + kwa + '-' + kwl + '-' + kw
Spider(fullurl,num,new_path)
界面显示:
相关问题:
问题1.
moviespider中因为我们要做的是电影资源下载,但是在下载过程中我们发现会有一些不是电影的资源,例如游戏资源
这是因为要抓取的网站本身就是的多元网站。对于如何鉴别电影下载链接和其他下载链接这个问题还需要攻克
问题2.
在80smoviespider中其实分类并不能完全达到改原网站的分类程度,并且只能通过输入序号分类,不够直观
如果要通过输入文字来分类,目前的算法太过复杂,又臭又长,因为分类真的太多,网站上光是电影类型的分类就有二十多个
如果能重写一个分类算法,完美表示网站分类就好了
问题3.
在运行80smoviespider时发现一个小问题,在最后保存的txt链接文件中发现有一个txt是空的,文件名也是空的。
可能是在写入的时候出了问题,或者更大的可能性是在用正则表达式提取文件名时发生了问题,提取一个空的名字
虽然不影响其他资源下载,但是这是个小bug
延申
1.在写程序的时候发现利用正则表达式匹配的时候太难,花的时间很长,而且以我目前的水平利用正则表达式匹配的质量很低
在moviespider中我利用了xpath方法,发现利用时间很短,因为可以在网页中直接复制xpath
2.一开始写搜索算法时候我只利用了低效率的循环算法,一页一页去匹配输入的关键字,如果我要搜索的关键字在网页的尾页(第300页),那就需要遍历7500遍,因为一页有25部电影链接
咨询过老师后,我利用了模拟浏览器的方法,利用网站本身的搜索引擎,就能快速搜索到记录
3.因为时间有限,不能将两个功能写在一起,同时分类和搜索