SparkSQL相关语句总结
1.in 不支持子查询
eg. select * from src where key in(select key from test);
支持查询个数 eg. select * from src where key in(1,2,3,4,5);
in 40000个 耗时25.766秒
in 80000个 耗时78.827秒
2.union all/union
不支持顶层的union all eg. select key from src UNION ALL select key from test;
支持select * from (select key from src union all select key from test)aa;
不支持 union
支持select distinct key from (select key from src union all select key from test)aa;
3.intersect 不支持
4.minus 不支持
5.except 不支持
6.inner join/join/left outer join/right outer join/full outer join/left semi join 都支持
left outer join/right outer join/full outer join 中间必须有outer
join是最简单的关联操作,两边关联只取交集;
left outer join是以左表驱动,右表不存在的key均赋值为null;
full outer join全表关联,将两表完整的进行笛卡尔积操作,左右表均可赋值为null;
Hive不支持where子句中的子查询,SQL常用的exist in子句在Hive中是不支持的
可用以下两种方式替换:
select * from src aa left outer join test bb on aa.key=bb.key where bb.key <> null;
select * from src aa left semi join test bb on aa.key=bb.key;
大多数情况下 JOIN ON 和 left semi on 是对等的
A,B两表连接,如果B表存在重复数据
当使用JOIN ON的时候,A,B表会关联出两条记录,应为ON上的条件符合;
而是用LEFT SEMI JOIN 当A表中的记录,在B表上产生符合条件之后就返回,不会再继续查找B表记录了, 所以如果B表有重复,也不会产生重复的多条记录。
left outer join 支持子查询 eg. select aa.* from src aa left outer join (select * from test111)bb on aa.key=bb.a;
7. hive四中数据导入方式
1)从本地文件系统中导入数据到Hive表
create table wyp(id int,name string) ROW FORMAT delimited fields terminated by '\t' STORED AS TEXTFILE;
load data local inpath 'wyp.txt' into table wyp;2)从HDFS上导入数据到Hive表
$>bin/hadoop fs -cat /home/wyp/add.txt
hive> load data inpath '/home/wyp/add.txt' into table wyp;3)从别的表中查询出相应的数据并导入到Hive表中
hive> create table test(
> id int, name string
> ,tel string)
> partitioned by
> (age int)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> STORED AS TEXTFILE;注:test表里面用age作为了分区字段,分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。
比如wyp表有dt和city两个分区,则对应dt=20131218city=BJ对应表的目录为/user/hive/warehouse/dt=20131218/city=BJ,
所有属于这个分区的数据都存放在这个目录中。
hive> insert into table test
> partition (age='25')
> select id, name, tel
> from wyp;也可以在select语句里面通过使用分区值来动态指明分区:
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> insert into table test
> partition (age)
> select id, name,
> tel, age
> from wyp;Hive也支持insert overwrite方式来插入数据
hive> insert overwrite table test
> PARTITION (age)
> select id, name, tel, age
> from wyp;Hive还支持多表插入
hive> from wyp
> insert into table test
> partition(age)
> select id, name, tel, age
> insert into table test3
> select id, name
> where age>25;4)在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中
hive> create table test4 as select id, name, tel from wyp;
8.查看建表语句
hive> show create table test3;9.表重命名
hive> ALTER TABLE events RENAME TO 3koobecaf; 10.表增加列
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT); 11.添加一列并增加列字段注释
hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment'); 12.删除表
hive> DROP TABLE pokes; 13.top n
hive> select * from test order by key limit 10;14.修改列的名称和类型
Create Database baseball;
alter table yangsy CHANGE product_no phone_no stringThriftServer 开启FAIR模式
SparkSQL Thrift Server 开启FAIR调度方式:
1. 修改SPARKHOME/conf/spark−defaults.conf,新增2.spark.scheduler.modeFAIR3.spark.scheduler.allocation.file/Users/tianyi/github/community/apache−spark/conf/fair−scheduler.xml4.修改SPARK_HOME/conf/fair-scheduler.xml(或新增该文件), 编辑如下格式内容
<allocations>
<pool name="production">
<schedulingMode>FAIRschedulingMode>
<weight>1weight>
<minShare>2minShare>
pool>
<pool name="test">
<schedulingMode>FIFOschedulingMode>
<weight>2weight>
<minShare>3minShare>
pool>
allocations>- 重启Thrift Server
- 执行SQL前,执行
- set spark.sql.thriftserver.scheduler.pool=指定的队列名
等操作完了 create table yangsy555 like CI_CUSER_YYMMDDHHMISSTTTTTT 然后insert into yangsy555 select * from yangsy555
创建一个自增序列表,使用row_number() over()为表增加序列号 以供分页查询
create table yagnsytest2 as SELECT ROW_NUMBER() OVER() as id,* from yangsytest;
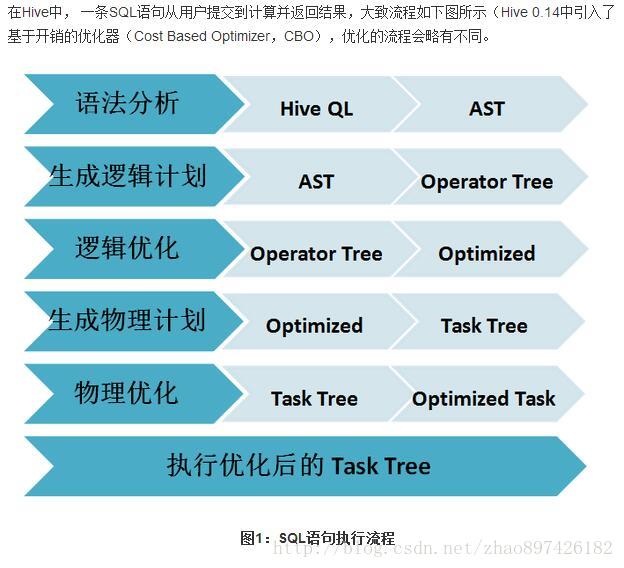
Sparksql的解析与Hiveql的解析的执行流程: