python进阶—OpenCV之图像处理(三)
文章目录
- 图像直方图(Histograms)
- 直方图查找,绘制,分析
- 直方图均衡化
- 二维直方图
- 直方图反向投影
- OpenCV里的反映射
- 图像模板匹配(Template Matching)
- 单目标模板匹配
- 多目标模板匹配
- 霍夫直线检测(Hough Line Transform)
- 霍夫圆检测(Hough Circle Transform)
- 分水岭算法的图像分割(Image Segmentation with Watershed Algorithm)
- 基于GrabCut算法的交互式前景提取(Interactive Foreground Extraction using GrabCut Algorithm)
python opencv 图像处理第三篇。
图像直方图(Histograms)
图像的直方图是用来表现图像中亮度分布的直方图,给出的是图像中某个亮度或者某个范围亮度下共有几个像素;X轴表示灰度的范围,一般是0-255,Y轴表示相同灰度之下像素的个数。
直方图的BIN:bins一般翻译为箱子,在图像直方图中,可以把一个灰度值设置为一个bins,0~255强度的灰度值一共就需要256个bins,也可以把一个灰度范围内的值设置为一个bins。
直方图查找,绘制,分析
cv.calcHist此函数由三种实现,下面仅介绍第一种
- 函数原型:hist = cv.calcHist( images, channels, mask, histSize, ranges[, hist[, accumulate]] )
- images: 输入的图像或数组,它们的深度必须为CV_8U, CV_16U或CV_32F中的一类,尺寸必须相同。
- nimages: 输入数组个数,也就是第一个参数中存放了几张图像,有几个原数组。
- channels: 需要统计的通道dim,第一个数组通道从0到image[0].channels()-1,第二个数组从image[0].channels()到images[0].channels()+images[1].channels()-1,以后的数组以此类推
- mask: 可选的操作掩码。如果此掩码不为空,那么它必须为8位并且尺寸要和输入图像images一致。非零掩码用于标记出统计直方图的数组元素数据。
- hist: 输出的目标直方图,一个二维数组
- dims: 需要计算直方图的维度,必须是正数且并不大于CV_MAX_DIMS(在opencv中等于32)
- histSize: 每个维度的直方图尺寸的数组
- ranges: 每个维度中bin的取值范围
- uniform: 直方图是否均匀的标识符,有默认值true
- accumulate: 累积标识符,有默认值false,若为true,直方图再分配阶段不会清零。此功能主要是允许从多个阵列中计算单个直方图或者用于再特定的时间更新直方图.
此函数查找并计算直方图,但是并没有绘制直方图。
以下方式可以直接计算并绘制直方图
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('home.jpg',0)
plt.hist(img.ravel(),256,[0,256]); plt.show()

import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('home.jpg')
color = ('b','g','r')
for i,col in enumerate(color):
histr = cv.calcHist([img],[i],None,[256],[0,256])
plt.plot(histr,color = col)
plt.xlim([0,256])
plt.show()

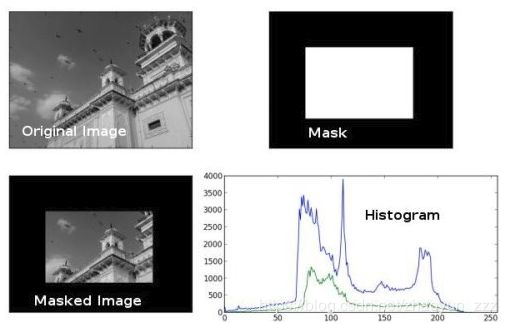
- 绘制ROI内的直方图
img = cv.imread('home.jpg',0)
# create a mask
mask = np.zeros(img.shape[:2], np.uint8)
mask[100:300, 100:400] = 255
masked_img = cv.bitwise_and(img,img,mask = mask)
# Calculate histogram with mask and without mask
# Check third argument for mask
hist_full = cv.calcHist([img],[0],None,[256],[0,256])
hist_mask = cv.calcHist([img],[0],mask,[256],[0,256])
plt.subplot(221), plt.imshow(img, 'gray')
plt.subplot(222), plt.imshow(mask,'gray')
plt.subplot(223), plt.imshow(masked_img, 'gray')
plt.subplot(224), plt.plot(hist_full), plt.plot(hist_mask)
plt.xlim([0,256])
plt.show()
直方图均衡化
直方图均衡化处理的“中心思想”是把原始图像的灰度直方图从比较集中的某个灰度区间变成在全部灰度范围内的均匀分布;这样就增加了象素灰度值的动态范围从而可达到增强图像整体对比度的效果。
直方图均衡化就是对图像进行非线性拉伸,重新分配图像像素值,使一定灰度范围内的像素数量大致相同。
直方图均衡化就是把给定图像的直方图分布改变成“均匀”分布直方图分布。
1)变换后图像的灰度级减少,某些细节消失;
2)某些图像,如直方图有高峰,经处理后对比度不自然的过分增强。
当图像有用数据的对比度相当接近的时候;通过这种方法,亮度可以更好地在直方图上分布;这样就可以用于增强局部的对比度而不影响整体的对比度
这种方法对于背景和前景都太亮或者太暗的图像非常有用,这种方法尤其是可以带来X光图像中更好的骨骼结构显示以及曝光过度或者曝光不足照片中更好的细节。这种方法的一个主要优势是它是一个相当直观的技术并且是可逆操作,如果已知均衡化函数,那么就可以恢复原始的直方图,并且计算量也不大。这种方法的一个缺点是它对处理的数据不加选择,它可能会增加背景杂讯的对比度并且降低有用信号的对比度。
- 函数原型:dst = cv.equalizeHist( src[, dst] )
- src: Source 8-bit single channel image.
- dst: Destination image of the same size and type as src .
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('wiki.jpg',0)
hist,bins = np.histogram(img.flatten(),256,[0,256])
cdf = hist.cumsum()
cdf_normalized = cdf * float(hist.max()) / cdf.max()
plt.plot(cdf_normalized, color = 'b')
plt.hist(img.flatten(),256,[0,256], color = 'r')
plt.xlim([0,256])
plt.legend(('cdf','histogram'), loc = 'upper left')
plt.show()

局部区域自适应直方图均衡
- 函数原型:retval = cv.createCLAHE( [, clipLimit[, tileGridSize]] )
- src: Source 8-bit single channel image.
- dst: Destination image of the same size and type as src .
import numpy as np
import cv2 as cv
img = cv.imread('tsukuba_l.png',0)
# create a CLAHE object (Arguments are optional).
clahe = cv.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
cl1 = clahe.apply(img)
cv.imwrite('clahe_2.jpg',cl1)
二维直方图
二维直方图中,考虑两个特征,通常来说它是用来获取彩色直方图,而它的两个特征是每个像素点的色调和饱和度。
二维直方图计算,用的是同一个方法,cv.calcHist()。对于彩色直方图,我们需要把图像从 BGR 转成 HSV。(记住对于一维直方图,我们是把 BGR 转成灰度图像)。对于二维直方图,它的参数被修改成如下:
- channels = [0,1] 因为我们需要同时处理H和S平面(译者注:分别表示H色调和S饱和度)。
- bins = [180,256] H平面最多180个抽屉,S平面最多256个抽屉。
- range = [0,180,0,256] 色调值落在 0 到 180 & 饱和度落在 0 到 256。
import numpy as np
import cv2 as cv
img = cv.imread('home.jpg')
hsv = cv.cvtColor(img,cv.COLOR_BGR2HSV)
hist = cv.calcHist([hsv], [0, 1], None, [180, 256], [0, 180, 0, 256])
Numpy里的2D直方图
Numpy也为此提供了一个特定的函数:np.histogram2d()。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('home.jpg')
hsv = cv.cvtColor(img,cv.COLOR_BGR2HSV)
hist, xbins, ybins = np.histogram2d(h.ravel(),s.ravel(),[180,256],[[0,180],[0,256]])
绘制二维直方图
方法 - 1:使用 cv.imshow()
我们拿到的结果是一个二维数组,大小 180x256。所以我们可以像往常一样显示它们,使用cv.imshow()函数。它将是一个灰度图像,它不会直观的显示出那具体是什么颜色,除非你知道不同颜色的色调值。
方法 - 2:使用 Matplotlib
我们可以使用 matplotlib.pyplot.imshow() 函数,通过不同的颜色映射关系来绘制2D直方图。它让我们对不同的像素密度有了更好的了解。但这也不能在第一时间告诉我们那颜色是什么,除非你知道不同颜色的色调值。但我还是推荐这种方法。它很简单,而且更好。
当使用这个函数时,记住,插补标记interpolation应该是最近的,以便获得更好的结果。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('home.jpg')
hsv = cv.cvtColor(img,cv.COLOR_BGR2HSV)
hist = cv.calcHist( [hsv], [0, 1], None, [180, 256], [0, 180, 0, 256] )
plt.imshow(hist,interpolation = 'nearest')
plt.show()

直方图反向投影
它用于图像分割或寻找图像中感兴趣的对象。简单的说,它创造了一个和我们输入图像相同大小(但只有一个单通道)的新图像,其中每一个像素点对应了该像素属于我们的(感兴趣的)对象的概率。直方图反映射常常与连续自适应均值漂移算法(CamShift算法的全称是"Continuously Adaptive Mean-SHIFT",附链接)等一起使用。
我们怎么做? 我们创建一个包含了我们感兴趣对象的图像的直方图(在我们接下来的示例中,感兴趣对象设为地面,不去管球员和其他东西)。感兴趣对象应该尽可能的填充这个图像,这样能得到更好的结果。并且推荐使用彩色直方图而不是灰度直方图,因为物体的颜色比起物体的灰度强度更好的定义了这个物体。然后我们在需要找出感兴趣对象的测试图像上开始“反映射”这个直方图,换句话说,我们计算每个像素点属于地面(我们感兴趣对象)的概率,并且显示这些像素点。在给定合理阈值的情况下,结果输出就会只给我们地面。
import numpy as np
import cv2 as cvfrom matplotlib import pyplot as plt
#roi is the object or region of object we need to find
roi = cv.imread('rose_red.png')
hsv = cv.cvtColor(roi,cv.COLOR_BGR2HSV)
#target is the image we search in
target = cv.imread('rose.png')
hsvt = cv.cvtColor(target,cv.COLOR_BGR2HSV)
# Find the histograms using calcHist. Can be done with np.histogram2d also
M = cv.calcHist([hsv],[0, 1], None, [180, 256], [0, 180, 0, 256] )
I = cv.calcHist([hsvt],[0, 1], None, [180, 256], [0, 180, 0, 256] )
OpenCV里的反映射
OpenCV 提供了一个内置函数 cv.calcBackProject()。它的参数几乎和 cv.calcHist() 函数一样。其中一个参数是直方图,也就是物体的直方图我们必须找到它。并且,这个物体的直方图参数应该在传入这个反映射函数之前被标准化。它返回的是(那张表示了每个像素点属于我们感兴趣物体的)概率的图像。然后我们用圆盘内核做卷积,应用阈值。以下是我的代码和运行结果:
import numpy as np
import cv2 as cv
roi = cv.imread('rose_red.png')
hsv = cv.cvtColor(roi,cv.COLOR_BGR2HSV)
target = cv.imread('rose.png')
hsvt = cv.cvtColor(target,cv.COLOR_BGR2HSV)
# calculating object histogram
roihist = cv.calcHist([hsv],[0, 1], None, [180, 256], [0, 180, 0, 256] )
# normalize histogram and apply backprojection
cv.normalize(roihist,roihist,0,255,cv.NORM_MINMAX)
dst = cv.calcBackProject([hsvt],[0,1],roihist,[0,180,0,256],1)
# Now convolute with circular disc
disc = cv.getStructuringElement(cv.MORPH_ELLIPSE,(5,5))
cv.filter2D(dst,-1,disc,dst)
# threshold and binary AND
ret,thresh = cv.threshold(dst,50,255,0)
thresh = cv.merge((thresh,thresh,thresh))
res = cv.bitwise_and(target,thresh)
res = np.vstack((target,thresh,res))
cv.imwrite('res.jpg',res)

图像模板匹配(Template Matching)
模板匹配是在图像中寻找目标的方法
模板匹配的工作方式跟直方图的反向投影基本一样,大致过程是这样的:通过在输入图像上滑动图像块对实际的图像块和输入图像进行匹配。
假设我们有一张100x100的输入图像,有一张10x10的模板图像,查找的过程如下:
(1)从输入图像的左上角(0,0)开始,切割一块(0,0)至(10,10)的临时图像;
(2)用临时图像和模板图像进行对比,对比结果记为c;
(3)对比结果c,就是结果图像(0,0)处的像素值;
(4)切割输入图像从(0,1)至(10,11)的临时图像,对比,并记录到结果图像;
(5)重复(1)~(4)步直到输入图像的右下角。
单目标模板匹配
模板匹配的函数: cv.matchTemplate,说明如下:
- 函数原型:result = cv.matchTemplate( image, templ, method[, result[, mask]] )
- image:待匹配的图像,必须是 8-bit 或者 32-bit 浮点数
- templ: 模板图像,必须小于搜索图像,数据类型与image一致
- result: 模板匹配函数cvMatchTemplate依次计算模板与待测图片的重叠区域的相似度,并将结果存入映射图像result当中,也就是说result图像中的每一个点的值代表了一次相似度比较结果。结果是单通道 32-bit 浮点数。如果image图像大小是W×H,模板图像大小是w×h,则result图像大小是(W−w+1)×(H−h+1)
- method:模板匹配方法。
- CV_TM_SQDIFF 平方差匹配法:该方法采用平方差来进行匹配;最好的匹配值为0;匹配越差,匹配值越大。
- CV_TM_CCORR 相关匹配法:该方法采用乘法操作;数值越大表明匹配程度越好。
- CV_TM_CCOEFF 相关系数匹配法:1表示完美的匹配;-1表示最差的匹配。
- CV_TM_SQDIFF_NORMED 归一化平方差匹配法
- CV_TM_CCORR_NORMED 归一化相关匹配法
- CV_TM_CCOEFF_NORMED 归一化相关系数匹配法
- mask:模板掩模图像,数据类型、尺寸大小必须与templ一致;当前只有TM_SQDIFF 与TM_CCORR_NORMED方法支持
函数cv.minMaxLoc说明 - 函数原型:minVal, maxVal, minLoc, maxLoc = cv.minMaxLoc( src[, mask] )
- src: 输入单通道图像
- minVal:比对结果中的最小值
- maxVal:比对结果中的最大值
- minLoc:比对结果中的最小值位置坐标
- maxLoc:比对结果中的最大值位置坐标
- mask: 可选的mask,用于选择sub-array.
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg',0)
img2 = img.copy()
template = cv.imread('template.jpg',0)
w, h = template.shape[::-1]
# All the 6 methods for comparison in a list
methods = ['cv.TM_CCOEFF', 'cv.TM_CCOEFF_NORMED', 'cv.TM_CCORR',
'cv.TM_CCORR_NORMED', 'cv.TM_SQDIFF', 'cv.TM_SQDIFF_NORMED']
for meth in methods:
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv.matchTemplate(img,template,method)
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv.TM_SQDIFF, cv.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv.rectangle(img,top_left, bottom_right, 255, 2)
plt.subplot(121),plt.imshow(res,cmap = 'gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img,cmap = 'gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()


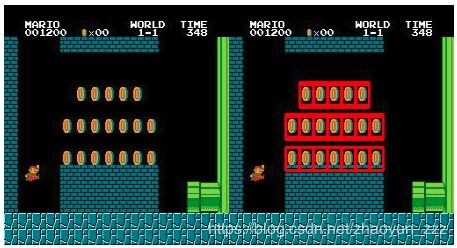
多目标模板匹配
可以使用阈值在图像中搜索多目标图像
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img_rgb = cv.imread('mario.png')
img_gray = cv.cvtColor(img_rgb, cv.COLOR_BGR2GRAY)
template = cv.imread('mario_coin.png',0)
w, h = template.shape[::-1]
res = cv.matchTemplate(img_gray,template,cv.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):
cv.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)
cv.imwrite('res.png',img_rgb)
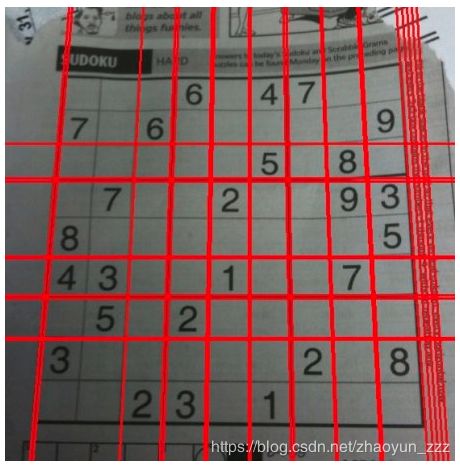
霍夫直线检测(Hough Line Transform)
霍夫直线检测数学原理性的东西,我讲不来,网上有很多,待到我确实理解其数学原理后(惭愧,十几年不用数学,全忘了)再来添加介绍;这里只说明用法。
- 函数原型: lines = cv.HoughLines( image, rho, theta, threshold[, lines[, srn[, stn[, min_theta[, max_theta]]]]] )
- image:输入图像,要求是单通道的二值图像,输入图像可能被此函数修改
- lines:输出直线向量,两个元素的向量(ρ,θ)代表一条直线,ρ是从原点(图像的左上角)的距离,θ是直线的角度(单位是弧度),0表示垂直线,π/2表示水平线
- rho:像素相关单位的距离加器
- theta:角度分辨率
- threshold:阈值参数,如果相应的累计值大于 threshold, 则函数返回这条线段
- srn:多尺度霍夫直线变换rto参数的除数,它导致累加精度为:rho/srn 。
- stn: 多尺度霍夫直线变换 theta参数的除数
- 如果srn和stn同时为0,就表示使用经典的霍夫变换;否则这两个参数应该都为正数。
- min_theta:检测直线的最小角度θ,取值范围是:0 and max_theta.
- max_theta:检测直线的最大角度θ,取值范围是: min_theta and CV_PI.
import cv2 as cv
import numpy as np
img = cv.imread('../data/sudoku.png')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
edges = cv.Canny(gray,50,150,apertureSize = 3)
lines = cv.HoughLines(edges,1,np.pi/180,200)
for line in lines:
rho,theta = line[0]
a = np.cos(theta)
b = np.sin(theta)
x0 = a*rho
y0 = b*rho
x1 = int(x0 + 1000*(-b))
y1 = int(y0 + 1000*(a))
x2 = int(x0 - 1000*(-b))
y2 = int(y0 - 1000*(a))
cv.line(img,(x1,y1),(x2,y2),(0,0,255),2)
cv.imwrite('houghlines3.jpg',img)
- 函数原型: lines = cv.HoughLinesP( image, rho, theta, threshold[, lines[, minLineLength[, maxLineGap]]] )
- image: 必须是二值图像,推荐使用canny边缘检测的结果图像;
- rho: 线段以像素为单位的距离精度,double类型的,推荐用1.0
- theta: 线段以弧度为单位的角度精度,推荐用numpy.pi/180
- threshod: 累加平面的阈值参数,int类型,超过设定阈值才被检测出线段,值越大,基本上意味着检出的线段越长,检出的线段个数越少。根据情况推荐先用100试试
- lines:这个参数的意义未知,发现不同的lines对结果没影响,但是不要忽略了它的存在
- minLineLength:线段以像素为单位的最小长度,小于此值线段不会放入到lines集合
- maxLineGap:同一方向上两条线段判定为一条线段的最大允许间隔,超过了设定值,则为两条线段,值越大,允许线段上的断裂越大。
import cv2 as cv
import numpy as np
img = cv.imread('../data/sudoku.png')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
edges = cv.Canny(gray,50,150,apertureSize = 3)
lines = cv.HoughLinesP(edges,1,np.pi/180,100,minLineLength=100,maxLineGap=10)
for line in lines:
x1,y1,x2,y2 = line[0]
cv.line(img,(x1,y1),(x2,y2),(0,255,0),2)
cv.imwrite('houghlines5.jpg',img)

霍夫圆检测(Hough Circle Transform)
- 函数原型:circles = cv.HoughCircles( image, method, dp, minDist[, circles[, param1[, param2[, minRadius[, maxRadius]]]]] )
- image:8-bit, 单通道灰度图像
- circles:输出圆向量,每个向量包括三个浮点型的元素——圆心横坐标,圆心纵坐标和圆半径
- method:霍夫变换圆检测的算法,见cv::HoughModes,当前仅支持 HOUGH_GRADIENT算法
- dp:霍夫空间的分辨率,dp=1时表示霍夫空间与输入图像空间的大小一致,dp=2时霍夫空间是输入图像空间的一半,以此类推,dp的值不能比1小
- minDist:圆心之间的最小距离,如果检测到的两个圆心之间距离小于该值,则认为它们是同一个圆心,取值过小会造成邻近圆检测为一个圆,取值过大回造成一些圆检测丢失。
- param1:Canny的边缘阀值上限,下限被置为上限的一半
- param2:第二项参数method的明细参数, 算法为CV_HOUGH_GRADIENT , 它为圆心检测累加器的阈值,取值越小,会造成越多的错误圆检测,累加器值越大的圆,先返回
- minRadius:圆最小直径
- maxRadius:圆最大直径
import numpy as np
import cv2 as cv
img = cv.imread('opencv-logo-white.png',0)
img = cv.medianBlur(img,5)
cimg = cv.cvtColor(img,cv.COLOR_GRAY2BGR)
circles = cv.HoughCircles(img,cv.HOUGH_GRADIENT,1,20,
param1=50,param2=30,minRadius=0,maxRadius=0)
circles = np.uint16(np.around(circles))
for i in circles[0,:]:
# draw the outer circle
cv.circle(cimg,(i[0],i[1]),i[2],(0,255,0),2)
# draw the center of the circle
cv.circle(cimg,(i[0],i[1]),2,(0,0,255),3)
cv.imshow('detected circles',cimg)
cv.waitKey(0)
cv.destroyAllWindows()

分水岭算法的图像分割(Image Segmentation with Watershed Algorithm)
分水岭分割方法,它是一种基于拓扑理论的数学形态学的分割方法,其基本思想是把图像看作是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆,而集水盆的边界则形成分水岭。分水岭的概念和形成可以通过模拟浸入过程来说明。在每一个局部极小值表面,刺穿一个小孔,然后把整个模型慢慢浸入水中,随着浸入的加深,每一个局部极小值的影响域慢慢向外扩展,在两个集水盆汇合处构筑大坝,即形成分水岭。
一般的分水岭算法会对微弱边缘,图像中的噪声,物体表面细微的灰度变化造成过度的分割。opencv中的分水岭算法对此进行了改进,它使用预定义的一组标记来引导对图像的分割。
在执行分水岭函数watershed之前,必须对第二个参数markers进行处理,它应该包含不同区域的轮廓,每个轮廓有一个自己唯一的编号,轮廓的定位可以通过Opencv中findContours方法实现,这个是执行分水岭之前的要求。
接下来执行分水岭会发生什么呢?算法会根据markers传入的轮廓作为种子(也就是所谓的注水点),对图像上其他的像素点根据分水岭算法规则进行判断,并对每个像素点的区域归属进行划定,直到处理完图像上所有像素点。而区域与区域之间的分界处的值被置为“-1”,以做区分。
简单概括一下就是说第二个入参markers必须包含了种子点信息。Opencv官方例程中使用鼠标划线标记,其实就是在定义种子,只不过需要手动操作,而使用findContours可以自动标记种子点。而分水岭方法完成之后并不会直接生成分割后的图像,还需要进一步的显示处理
- 函数原型:markers = cv.watershed( image, markers )
- image:Input 8-bit 3-channel image.
- markers:Input/output 32-bit single-channel image (map) of markers. It should have the same size as image .
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('coins.png')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(gray,0,255,cv.THRESH_BINARY_INV+cv.THRESH_OTSU)
# noise removal
kernel = np.ones((3,3),np.uint8)
opening = cv.morphologyEx(thresh,cv.MORPH_OPEN,kernel, iterations = 2)
# sure background area
sure_bg = cv.dilate(opening,kernel,iterations=3)
# Finding sure foreground area
dist_transform = cv.distanceTransform(opening,cv.DIST_L2,5)
ret, sure_fg = cv.threshold(dist_transform,0.7*dist_transform.max(),255,0)
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv.subtract(sure_bg,sure_fg)
# Marker labelling
ret, markers = cv.connectedComponents(sure_fg)
# Add one to all labels so that sure background is not 0, but 1
markers = markers+1
# Now, mark the region of unknown with zero
markers[unknown==255] = 0





基于GrabCut算法的交互式前景提取(Interactive Foreground Extraction using GrabCut Algorithm)
GrabCut算法我解释不来,我只能说明一下函数的用法。
- 函数原型:mask, bgdModel, fgdModel = cv.grabCut( img, mask, rect, bgdModel, fgdModel, iterCount[, mode] )
- img:待分割的源图像,必须是8位3通道(CV_8UC3)图像,在处理的过程中不会被修改
- mask:输入输出8bit单通道掩码图像,如果使用mode=GC_INIT_WITH_RECT,则掩码被函数进行初始化;在执行分割的时候,也可以将用户交互所设定的前景与背景保存到mask中,然后再传入grabCut函数;在处理结束之后,mask中会保存结果。mask只能取以下四种值:
GCD_BGD(=0),背景;
GCD_FGD(=1),前景;
GCD_PR_BGD(=2),可能的背景;
GCD_PR_FGD(=3),可能的前景。
如果没有手工标记GCD_BGD或者GCD_FGD,那么结果只会有GCD_PR_BGD或GCD_PR_FGD - rect:用于限定需要进行分割的图像范围,只有该矩形窗口内的图像部分才被处理,此参数仅在mode==GC_INIT_WITH_RECT有效
- bgdModel:前景模型,如果为null,函数内部会自动创建一个fgdModel;fgdModel必须是单通道浮点型(CV_32FC1)图像,且行数只能为1,列数只能为13x5
- fgdModel:前景模型,如果为null,函数内部会自动创建一个fgdModel;fgdModel必须是单通道浮点型(CV_32FC1)图像,且行数只能为1,列数只能为13x5
- iterCount:迭代次数,必须大于0;返回结果前结果可能会被优化,如果 mode == GC_INIT_WITH_MASK or mode==GC_EVAL .
- mode:用于指示grabCut函数进行什么操作,可选的值有:
GC_INIT_WITH_RECT(=0),用矩形窗初始化GrabCut;
GC_INIT_WITH_MASK(=1),用掩码图像初始化GrabCut;
GC_EVAL(=2),执行分割
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg')
mask = np.zeros(img.shape[:2],np.uint8)
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
rect = (50,50,450,290)
cv.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv.GC_INIT_WITH_RECT)
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask2[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show()



觉得写的越来越差,很多原理性的东西我都不能解释,只能模糊的学习了,内容也多半是看一看别人的总结,再加上自己的一点理解,拼凑而成,就想着以后自己查找的是方便。
如果有哪位博主觉得我总结的内容,冒犯了您,请通知我。
看来想要进入计算机视觉的门不容易啊,不过我会坚持的。