第四章 常见 Android 文件格式(二)(classes.dex)
文章目录
- classes.dex
- DEX 文件结构
- DEX 文件的验证与优化过程
- DEX 文件的修改
- MultiDex
classes.dex
- 其中包含 APK 的可执行代码,是分析 Android 软件时最常见的目标
DEX 文件结构
- 在 Android 源码文件 dalvik/libdex/DexFile.h 中,有 DEX 文件可能用到的所有数据结构和常量定义
- 先了解 DEX 文件使用的数据类型:
| 自定义类型 | 原类型 | 含义 |
|---|---|---|
| s1 | int8_t | 8 位有符号整型 |
| u1 | uint8_t | 8 位无符号整型 |
| s2 | int16_t | 16 位有符号整型,小端字节序 |
| u2 | uint16_t | 16 位无符号整型,小端字节序 |
| s4 | int32_t | 32 位有符号整型,小端字节序 |
| u4 | uint32_t | 32 位无符号整型,小端字节序 |
| s8 | int64_t | 64 位有符号整型,小端字节序 |
| u8 | uint64_t | 64 位无符号整型,小端字节序 |
| sleb128 | 无 | 有符号 LEB128,可变长度 |
| uleb128 | 无 | 无符号 LEB128,可变长度 |
| uleb128p1 | 无 | 无符号 LEB128 加 1,可变长度 |
- u1 ~ u8 好理解,表示 1 ~ 8 字节的无符号数;s1 ~ s8 表示 1 ~ 8 字节的有符号数;sleb128、uleb128、uleb128p1 则是 DEX 文件中特有的 LEB128 数据类型
- 每个 LEB128 由 1 ~ 5 字节组成,所有的字节组合在一起表示一个 32 位的数据,如下图。每个字节只有 7 位为有效位,若第一个字节的最高位为 1,表示 LEB128 要使用第二个字节;若第二个字节的最高位为 1,表示 LEB128 要使用第三个字节;依此类推,直到最后一个字节的最高位为 0。当然,LEB128 最多使用 5 字节,若读取 5 字节后下一个字节的最高位仍为 1,则表示该 DEX 文件无效,Dalvik 虚拟机在验证 DEX 文件时会失败并返回

- 在 Android 系统源码 dalvik/libdex/Leb128.h 中可找到 LEB128 的实现。读取无符号 LEB128(uleb128)数据的代码:
DEX_INLINE int readUnsignedLeb128(const u1** pStream) {
const u1* ptr = *pStream;
int result = *(ptr++);
// 大于 0x7f,表示第一个字节最高位为 1
if (result > 0x7f) {
// 第二个字节
int cur = *(ptr++);
// 前两个字节的组合
result = (result & 0x7f) | ((cur & 0x7f) << 7);
// 大于 0x7f,表示第二个字节最高位仍为 1
if (cur > 0x7f) {
// 第三个字节
cur = *(ptr++);
// 前三个字节的组合
result |= (cur & 0x7f) << 14;
if (cur > 0x7f) {
// 第四个字节
cur = *(ptr++);
// 前四个字节的组合
result |= (cur & 0x7f) << 21;
if (cur > 0x7f) {
// 第五个字节
cur = *(ptr++);
// 前五个字节的组合
result |= cur << 28;
}
}
}
}
*pStream = ptr;
return result;
}
- 有符号的 LEB128(sleb128)与无符号的 LEB128 的计算方法大致相同,区别是无符号的 LEB128 的最后一个字节的最高有效位进行了符号扩展。读取有符号的 LEB128 数据的代码:
DEX_INLINE int readSignedLeb128(const u1** pStream) {
const u1* = *pStream;
int result = *(ptr++);
// 小于 0x7f,表示第一个字节的最高位不为 1
if (result <= 0x7f) {
// 对第一个字节的最高有效位进行符号扩展
result = (result << 25) >> 25;
}
else {
// 第二个字节
int cur = *(ptr++);
// 前两个字节的组合
result = (result & 0x7f) | ((cur & 0x7f) << 7);
if (cur <= 0x7f) {
// 对结果进行符号位扩展
result = (result << 18) >> 18;
}
else {
// 第三个字节
cur = *(ptr++);
// 前三个字节的组合
result |= (cur & 0x7f) << 14;
if (cur <= 0x7f) {
// 对结果进行符号位扩展
result = (result << 11) >> 11;
}
else {
// 第四个字节
cur = *(ptr++);
// 前四个字节的组合
result |= (cur & 0x7f) << 21;
if (cur <= 0x7f) {
// 对结果进行符号位扩展
result = (result << 4) >> 4;
}
else {
// 第五个字节
cur = *(ptr++);
// 前五个字节的组合
result |= cur << 28;
}
}
}
}
*pStream = ptr;
return result;
}
- uleb128p1 类型很简单,其值为 uleb128 的值加 1
- 计算字符序列“c0 83 92 25”的 uleb128 值:
- 第一个字节 0xc0 大于 0x7f,表示要使用第二个字节,即 result1 = 0xc0 & 0x7f
- 第二个字节 0x83 大于 0x7f,要使用第三个字节,即 result2 = result1 + (0x83 & 0x7f) << 7
- 第三个字节 0x92 大于 0x7f,要使用第四个字节,即 result3 = result2 + (0x92 & 0x7f) << 14
- 第四个字节 0x25 小于 0x7f,表示到了结尾,即 result4 = result3 + (0x25 & 0x7f) << 21
- 结果为:0x40 + 0x180 + 0x1200000 + 0x4a00000000 = 0x4a012001c0
- 计算字符序列“d1 c2 b3 40”的 sleb128 值:
- 第一个字节 0xd1 大于 0x7f,要使用第二个字节,即 result1 = 0xd1 & 0x7f
- 第二个字节 0xc2 大于 0x7f,要使用第三个字节,即 result2 = result1 + (0xc2 & 0x7f) << 7
- 第三个字节 0xb3 大于 0x7f,要使用第四个字节,即 result3 = result2 + (0xb3 & 0x7f) << 14
- 第四个字节 0x40 小于 0x7f,表示到了结尾,即 result4 = ((result3 + (0x40 & 7f) << 21) << 4) >> 4
- 结果为:((0x51 + 0x2100 + 0x3300000 + 0x8000000000) << 4) >> 4 = 0x8003302151
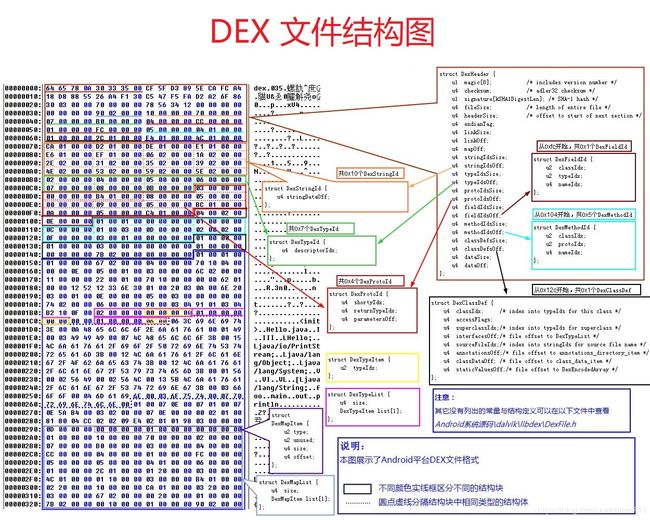
- DEX 文件由多个结构体组合而成。如下图,一个 DEX 文件由七部分组成:dex header 为 DEX 文件头,指定了 DEX 文件的一些属性并记录了其他数据结构在 DEX 文件中的物理偏移;string_ids 到class_def 部分可理解为“索引结构区”;真实的数据存放在 data 数据区;link_data 为静态链接数据区
| dex header |
|---|
| string_ids |
| type_ids |
| proto_ids |
| field_ids |
| method_ids |
| class_def |
| data |
| link_data |
- DEX 文件由 DexFile 结构体表示,定义如下:
struct DexFile {
// directly-mapped "opt" header
const DexOptHeader* pOptHeader;
// pointers to directly-mapped structs and arrays in base DEX
const DexHeader* pHeader;
const DexStringId* pStringIds;
const DexTypeId* pTypeIds;
const DexFileId* pFileIds;
const DexMethodId* pMethodIds;
const DexProtoId* pProtoIds;
const DexClassDef* pClassDefs;
const DexLink* pLinkData;
// These are mapped out of the "auxillary" section,
// and may not be included in the file
const DexClassLookup* pClassLookup;
const void* pRegisterMapPool; // RegisterMapClassPool
// points to start of DEX file data
const u1* baseAddr;
// track memory overhead for auxillary structures
int overhead;
// additional app-specific data structures associated with the DEX
//void* auxData;
};
- DexOptHeader 是 ODEX 的头。DexHeader 是 DEX 文件的头部信息,定义:
struct DexHeader {
u1 magic[8]; // DEX 版本标识
u4 checksum; // adler32 检验
u1 signature[kSHA1DigestLen]; // SHA-1 散列值
u4 fileSize; // 整个文件的大小
u4 headerSize; // DexHeader 结构的大小
u4 endianTag; // 字节序标记
u4 linkSize; // 链接段的大小
u4 linkOff; // 链接段的偏移量
u4 mapOff; // DexMapList 的文件偏移
u4 stringIdsSzie; // DexStringId 的个数
u4 stringIdsOff; // DexStringId 的文件偏移
u4 typeIdsSize; // DexTypeId 的个数
u4 typeIdsOff; // DexTypeId 的文件偏移
u4 protoIdsSize; // DexProtoId 的个数
u4 protoIdsOff; // DexProtoId 的文件偏移
u4 fieldIdsSize; // DexFieldId 的个数
u4 fieldIdsOff; // DexFieldId 的文件偏移
u4 methodIdsSize; // DexMethodId 的个数
u4 methodIdsOff; // DexMethodId 的文件偏移
u4 classDefsSize; // DexClassDef 的个数
u4 classDefsOff; // DexClassDef 的文件偏移
u4 dataSize; // 数据段的大小
u4 dataOff; // 数据段的文件偏移
};
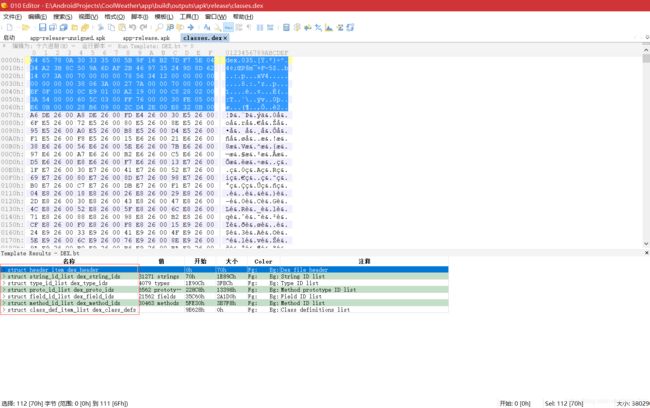
- magic 字段:表示这是一个有效的 DEX 文件,目前它的值固定为“64 65 78 0A 30 33 35 00”,转换为字符串格式为“dex.035.”
- checksum 字段:DEX 文件的校验和,可通过它判断 DEX 文件是否已损坏或被篡改
- signature 字段:用于识别未经 dexopt 优化的 DEX 文件
- fileSize 字段:记录包括 DexHeader 在内的整个 DEX 文件的大小
- headerSize 字段:记录 DexHeader 结构本身占用的字节数
- endianTag 字段:指定 DEX 运行环境的 CPU 字节序,预设值 ENDIAN_CONSTANT 等于 0x12345678,表示默认采用小端字节序
- linkSize、linkOff 字段:分别指定链接段的大小和文件偏移,大多数情况下它们的值为 0
- mapOff 字段:指定 DexMapList 结构的文件偏移
- 剩余字段:分别表示 DexStringId、DexTypeId、DexProtoId、DexFieldId、DexMethodId、DexClassDef 及数据段的大小与文件偏移
- DexHeader 结构下面的数据是索引结构区和数据区。索引结构区中各数据结构的偏移地址都由 DexHeader 结构的 stringIdsOff ~ classDefsOff 字段的值指定。它们并非真正的类数据,而是指向 DEX 文件的 data 数据区(DexData 字段,实际是 ubyte 字节数组,其中包含程序使用的所有数据)的偏移量或数据结构索引
- 下面以第三章的 Hello.dex 为例演示 DEX 文件中的各个结构
- Dalvik 虚拟机解析 DEX 文件的内容,最终将其映射成 DexMapList 数据结构。DexHeader 结构的 mapOff 字段指明了 DexMapList 结构在 DEX 文件中的偏移量,其声明如下:
struct DexMapList {
u4 size; // DexMapItem 结构的个数
DexMapItem list[1]; // DexMapItem 结构
};
- size 字段:表示接下来有多少个 DexMapItem 结构
- DexMapItem 结构的声明:
struct DexMapItem {
u2 type; // kDexType 开头的类型
u2 unused; // 未使用,用于字节对齐
u4 size; // 指定类型的个数
u4 offset; // 指定类型数据的文件偏移
};
- type 字段是一个枚举常量,如下,通过类型名称很容易就能判断它的具体类型:
enum {
kDexTypeHeaderItem = 0x0000,
kDexTypeStringIdItem = 0x0001,
kDexTypeTypeIdItem = 0x0002,
kDexTypeProtoIdItem = 0x0003,
kDexTypeFieldIdItem = 0x0004,
kDexTypeMethodIdItem = 0x0005,
kDexTypeClassDefItem = 0x0006,
kDexTypeMapList = 0x1000,
kDexTypeTypeList = 0x1001,
kDexTypeAnnotationSetRefList = 0x1002,
kDexTypeAnnotationSetItem = 0x1003,
kDexTypeClassDataItem = 0x2000,
kDexTypeCodeItem = 0x2001,
kDexTypeStringDataItem = 0x2002,
kDexTypeDebugInfoItem = 0x2003,
kDexTypeAnnotationItem = 0x2004,
kDexTypeEncodeedArrayItem = 0x2005,
kDexTypeAnnotationsDirectoryItem = 0x2006,
};
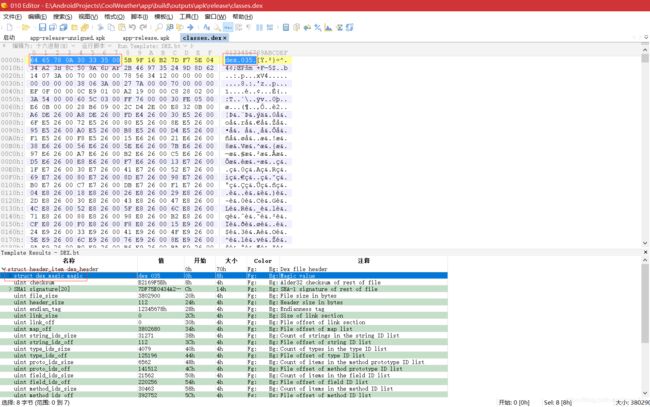
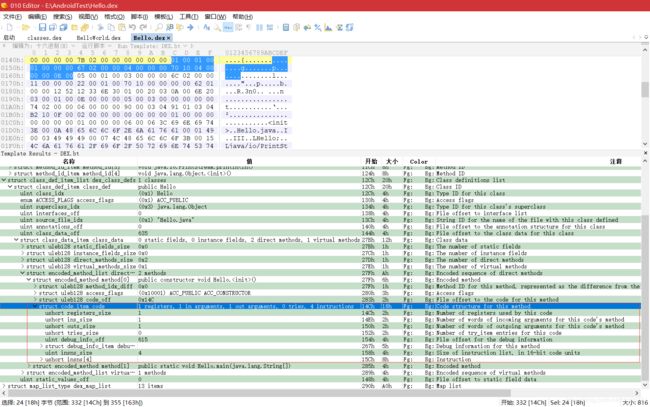
- DexMapItem 中的 size 字段指定特定类型的个数,它们以特定类型在 DEX 文件中连续存放,offset 为该类型的起始文件偏移地址。用 010 Editor 打开 Hello.dex,可看到 DexHeader 结构的 mapOff 字段的值为 656(十六进制为 0x290)。读取 0x290 处的一个双字,值为 0x0d,表示接下来会有 13 个 DexMapItem 结构:

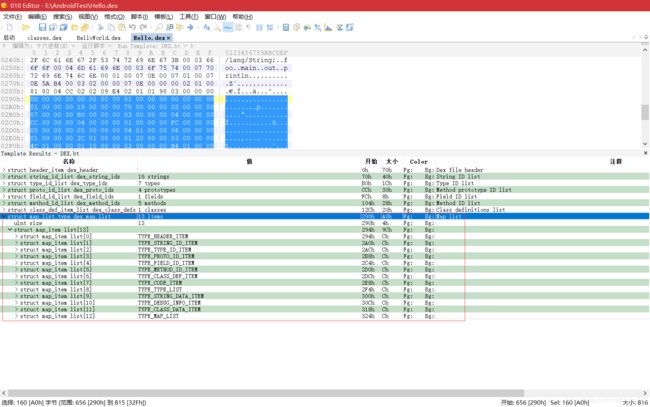
- 根据上面的结构描述整理出的 13 个 DexMapItem 结构,如下:
| 类型 | 个数 | 偏移量 |
|---|---|---|
| kDexTypeHeaderItem | 0x1 | 0x0 |
| kDexTypeStringIdItem | 0x10 | 0x70 |
| kDexTypeTypeIdItem | 0x7 | 0xb0 |
| kDexTypeProtoIdItem | 0x4 | 0xcc |
| kDexTypeFieldIdItem | 0x1 | 0xfc |
| kDexTypeMethodIdItem | 0x5 | 0x104 |
| kDexTypeClassDefItem | 0x1 | 0x12c |
| kDexTypeCodeItem | 0x3 | 0x14c |
| kDexTypeTypeList | 0x3 | 0x1b4 |
| kDexTypeStringDataItem | 0x10 | 0x1ca |
| kDexTypeDebugInfoItem | 0x3 | 0x267 |
| kDexTypeClassDataItem | 0x1 | 0x27b |
| kDexTypeMapList | 0x1 | 0x290 |
-
对比文件头 DexHeader 部分,如下图,kDexTypeHeaderItem 描述了整个 DexHeader 结构,占用了文件的前 0x70 字节空间,而接下来的 kDexTypeStringIdItem ~ kDexTypeClassDefItem 与 DexHeader 中对应的类型及类型个数字段的值相同
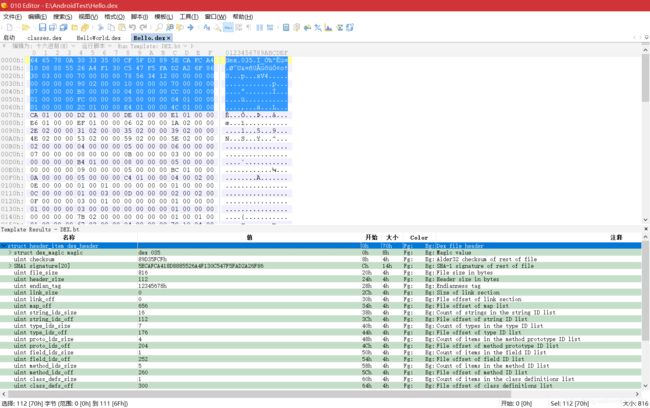
-
如,kDexTypeStringIdItem 对应 DexHeader 的 stringIdsSize 和 stringIdsOff 字段,表示 0x70 偏移处有连续 0x10 个 DexStringId 对象。DexStringId 结构的声明:
struct DexStringId {
u4 stringDataOff; // 字符串数据偏移
};
- DexStringId 结构中只有一个 stringDataOff 字段,它直接指向字符串数据。从 0x70 处开始,整理 16 个字符串,如下:
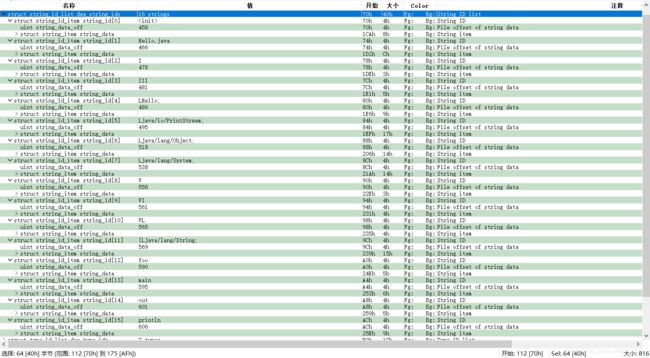
- stringDataOff 字段指向的字符串并非 ASCII 字符串,而是由 MUTF-8 编码表示的字符串。MUTF-8 是 Modified UTF-8 的缩写,即“经过修改的 UTF-8 编码”。MUTF-8 与 UTF-8 相似,但有几点区别:
- MUTF-8 使用 1 ~ 3 字节编码长度
- 对大于 16 位的 Unicode 编码 U+0x10000 ~ U+0x10ffff,使用 3 字节来编码
- 对 U+0x0000,采用 2 字节来编码
- 采用类似 C 语言中的空字符 null 作为字符串的结尾
- MUTF-8 可表示的有效字符串包括:大小写字母、数字、“$”、“-”、“_”、U+0x00A1 ~ U+0x1FFF、U+0x2010 ~ U+0x2027、U+0x2030 ~ U+0xD7FF、U+0xE000 ~ U+0xFFEF、U+0x10000 ~ U+0x10FFFF。其实现代码:
DEX_INLINE const char* dexGetStringData(const DexFile* pDexFile,
const DexStringId* pStringId) {
// 指向 MUTF-8 字符串的指针
const u1* ptr = pDexFile->baseAddr + pStringId->stringDataOff;
// Skip the uleb128 length
while (*(ptr++) > 0x7f) /* empty */ ;
return (const char*)ptr;
}
-
在 MUTF-8 字符串的头部存放的是由 uleb128 编码的字符的个数。如,字符序列“02 e4 bd a0 e5 a5 bd 00”头部的“02”表示字符串中有两个字符,“e4 bd a0”是 UTF-8 编码字符“你”,“e5 a5 bd”是 UTF-8 编码字符“好”,最后的空字符“00”是字符串的结尾(计算字符个数时好像不包含它)
-
接下来是 kDexTypeTypeIdItem,它对应 DexHeader 中的 typeIdsSize 和 typeIdsOff 字段,指向的结构体位 DexTypeId,声明:
struct DexTypeId {
u4 descriptorIdx; // 指向 DexStringId 列表的索引
};
-
descriptorIdx 为指向 DexStringId 列表的索引,其所对应的字符串代表具体类的类型。从 0xb0 处开始,有 7 个 DexTypeId 结构,即有 7 个字符串的索引:
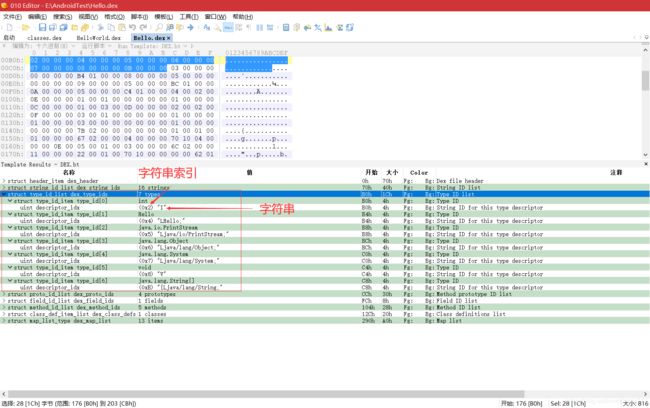
-
然后是 kDexTypeProtoIdItem,其对应 DexHeader 中的 protoIdsSize 和 protoIdsOff 字段,指向的结构体为 DexProtoId,声明:
struct DexProtoId {
u4 shortyIdx; // 指向 DexStringId 列表的索引
u4 returnTypeIdx; // 指向 DexTypeId 列表的索引
u4 parametersOff; // 指向 DexTypeList 的偏移量
};
- DexProtoId 是一个方法声明结构体,shortyIdx 为方法声明字符串,returnTypeIdx 为方法返回类型字符串,parametersOff 指向一个 DexTypeList 结构体,其中存放了方法的参数列表
- DexTypeList 结构体声明:
struct DexTypeList {
u4 size; // 接下来 DexTypeItem 结构的个数
DexTypeItem list[1]; // DexTypeItem 结构
};
- DexTypeItem 结构体声明:
struct DexTypeItem {
u2 typeIdx; // 指向 DexTypeId 列表的索引
};
-
DexTypeItem 中的 typeIdx 最终也指向一个字符串。从 0xcc 开始,有 4 个 DexProtoId 结构:
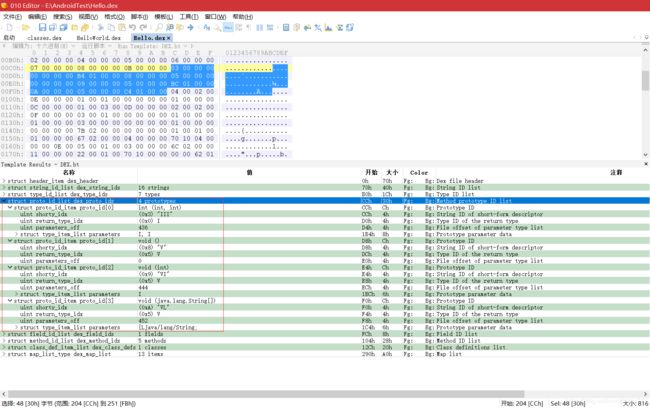
-
由上图可发现,方法声明由返回类型与参数列表组成,且返回类型在参数列表前面。如:第一个 DexProtoId 结构,方法声明为“III”,返回类型为“I”,参数列表为“I, I”
-
接下来是 kDexTypeFieldIdItem,对应 DexHeader 中的 fieldIdsSize 和fieldIdsOff 字段,指向的结构体为 DexFieldId,声明:
struct DexFieldId {
u2 classIdx; // 类的类型,指向 DexTypeId 列表的索引
u2 typeIdx; // 字段类型,指向 DexTypeId 列表的索引
u4 nameIdx; // 字段名,指向 DexStringId 列表的索引
};
-
DexFieldId 结构中的数据全是索引值,指明了字段所在的类、字段类型、字段名。从 0xfc 开始,有 1 个 DexFieldId 结构:
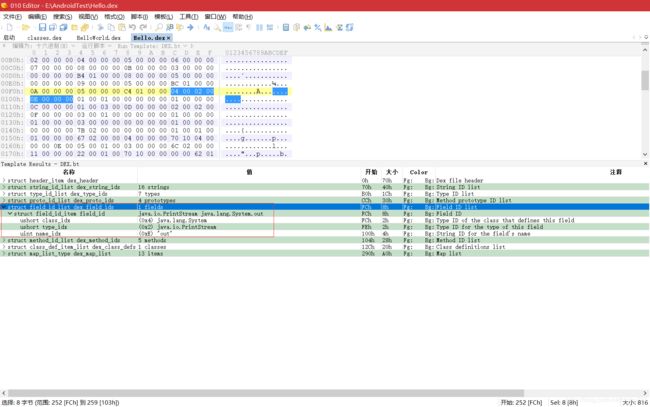
-
接下来是 kDexTypeMethodIdItem,对应 DexHeader 中的 methodIdsSize 和 methodIdsOff 字段,指向的结构体是 DexMethodId,声明:
struct DexMethodId {
u2 classIdx; // 类的类型,指向 DexTypeId 列表的索引
u2 protoIdx; // 声明类型,指向 DexProtoId 列表的索引
u4 nameIdx; // 方法名,指向 DexStringId 列表的索引
};
-
DexMethodId 结构中的数据也都是索引值,指明了方法所在的类、方法的声明、方法名。从 0x104 处开始,有 5 个 DexMethodId 结构:
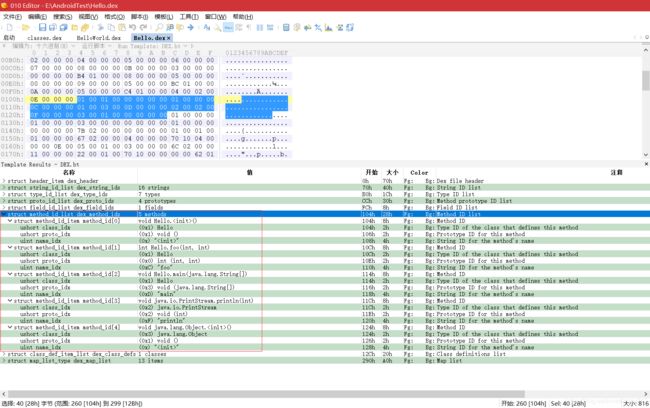
-
接下来是 kDexTypeClassDefItem,对应 DexHeader 中的 classDefsSize 和 classDefsOff 字段,指向的结构体是 DexClassDef,声明:
struct DexClassDef {
u4 classIdx; // 类的类型,指向 DexTypeId 列表的索引
u4 accessFlags; // 访问标志
u4 superclassIdx; // 父类的类型,指向 DexTypeId 列表的索引
u4 interfacesOff; // 接口,指向 DexTypeList 的偏移量
u4 sourceFileIdx; // 源文件名,指向 DexStringId 列表的索引
u4 annotationsOff; // 注解,指向 DexAnnotationsDirectoryItem 结构
u4 classDataOff; // 指向 DexClassData 结构的偏移量
u4 staticValuesOff; // 指向 DexEncodeedArray 结构的偏移量
};
- classIdx 字段:一个索引值,表示类的类型
- accessFlags 字段:类的访问标志,一个以 ACC_ 开头的枚举值
- superclassIdx 字段:父类类型索引值
- interfacesOff 字段:如果类中含有接口声明或实现,该字段会指向一个 DexTypeList 结构,否则值为 0
- sourceFileIdx 字段:字符串索引值,表示类所在源文件的名称
- annotationsOff 字段:指向注解目录结构,根据类型不同,会有注解类、注解方法、注解字段及注解参数,若类中无注解,则值为 0
- classDataOff 字段:指向 DexClassData 结构,它是类的数据部分
- staticValuesOff 字段:指向 DexEncodedArray 结构,其中记录了类中的静态数据
- DexClassData 结构声明:
struct DexClassData {
DexClassDataHeader header; // 指定字段与方法的个数
DexField* staticFields; // 静态字段,DexField 结构
DexField* instanceFields; // 实例字段,DexField 结构
DexMethod* directMethods; // 直接方法,DexMethod 结构
DexMethod* virtualMethods; // 虚方法,DexMethod 结构
};
- DexClassDataHeader 结构记录了当前类中字段和方法的数目,声明:
struct DexClassDataHeader {
u4 staticFieldsSize; // 静态字段的个数
u4 instanceFieldsSize; // 实例字段的个数
u4 directMethodsSize; // 直接方法的个数
u4 virtualMethodsSize; // 虚方法的个数
};
- DexClassDataHeader 的结构与 DexClassData 一样,都在 DexClass.h 文件中声明。这两个结构都是 DexFile 文件结构的一部分,却不在 DexFile.h 文件中声明的原因:DexClass.h 文件中所有结构的 u4 类型的字段其实都是 uleb128 类型,uleb128 使用 1 ~ 5 字节来表示一个 32 位的值,大多数情况下,字段中的这些数据可以用小于 2 字节的空间表示,因此采用 uleb128 会节省更多存储空间
- DexField 结构描述了字段的类型与访问标志,声明:
struct DexField {
u4 fieldIdx; // 指向 DexFieldId 的索引
u4 accessFlags; // 访问标志
};
- fieldIdx 字段:指向 DexFieldId 的索引
- accessFlags 字段:与 DexClassDef 结构中相应字段的类型相同
- DexMethod 结构描述了方法的原型、名称、访问标志、代码数据块,声明:
struct DexMethod {
u4 methodIdx; // 指向 DexMethodId 的索引
u4 accessFlags; // 访问标志
u4 codeOff; // 指向 DexCode 结构的偏移量
};
- methodIdx 字段:指向 DexMethodId 的索引
- accessFlags 字段:访问标志
- codeOff 字段:指向一个 DexCode 结构体
- DexCode 结构体描述了方法的详细信息和方法中指令的内容,声明:
struct DexCode {
u2 registersSize; // 使用的寄存器个数
u2 insSize; // 参数个数
u2 outsSize; // 调用其他方法时使用的寄存器个数
u2 triesSize; // try/catch 语句个数
u4 debugInfoOff; // 指向调试信息的偏移量
u4 insnsSize; // 指令集个数,以 2 字节为单位
u2 insns[1]; // 指令集
// 2 字节空间用于结构对齐
// try_item[triesSize],DexTry 结构
// try/catch 语句中 handler 个数
// catch_handler_item[handlersSize],DexCatchHandler 结构
};
- registersSize 字段:指定方法中使用的寄存器个数,即第三章 smali 语法中的 .registers 指令的值
- insSize 字段:指定方法的参数个数,对应 smali 语法中的 .parameter 指令
- outsSize 字段:指定方法在调用外部方法时使用的寄存器个数
- triesSize 字段:指定方法中 try/catch 语句个数,若 DEX 文件中保留了调试信息,debugInfoOff 字段会指向它。调试信息的解码函数为 dexDecodeDebugInfo(),可在 DexDebugInfo.cpp 文件中查看
- insnsSize 字段:指定接下来的指令个数
- insns 字段:真正的代码部分
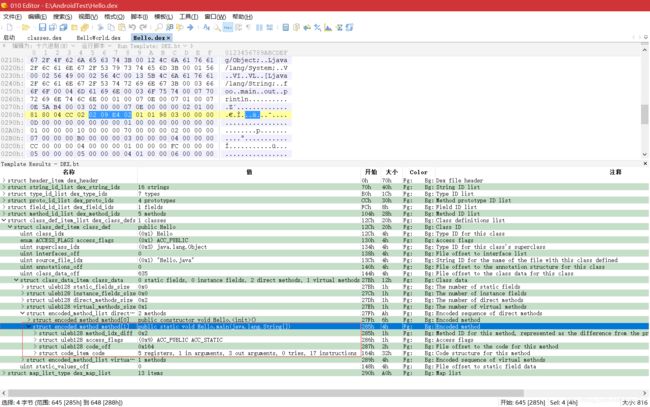
- 从 0x12c 开始,有一个 DexClassDef 结构,如下:
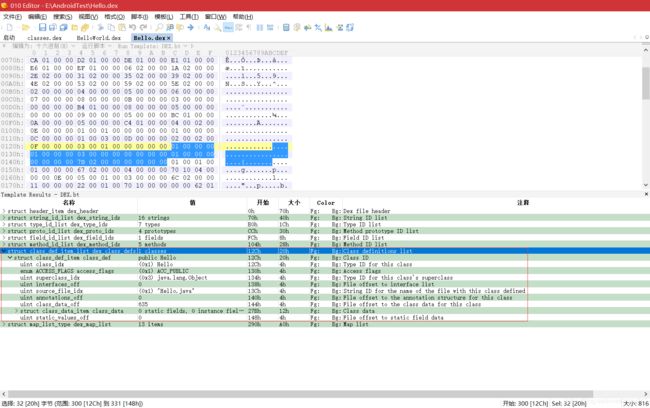
- 第一个字段为索引值 1,指定的字符串是“LHello;”,表明类名为“Hello”。第二个字段为 1,访问标志为 ACC_PUBLIC。第三个字段为 3,指向的字符串是“Ljava/lang/Object;”,即 Hello 的父类名。第四个字段为 0,表示没有接口。第五个字段为 1,指向的字符串是“Hello.java”,即类的源文件名。第六个字段为 0,表示没有注解。第七个字段为 0x27B,指向 DexClassData 结构。第八个字段为 0,表示没有静态值
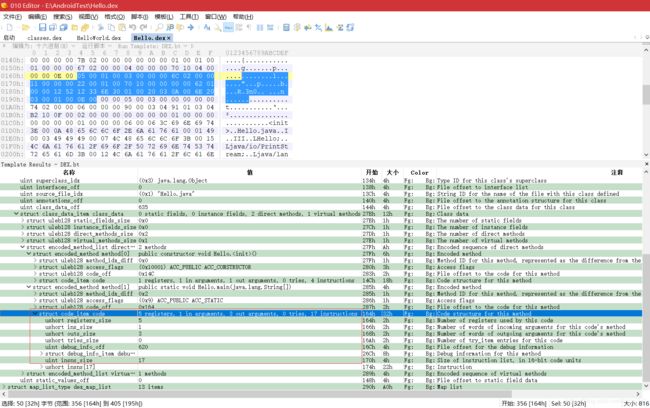
- 从 0x27b 开始,读取 DexClassDataHeader 结构,发现其为 4 个 uleb128 值,分别为 0、0、2、1,表示该类不含字段,有两个直接方法和一个虚方法。由于不含字段,DexClassData 中的两个 DexField 结构就没用了
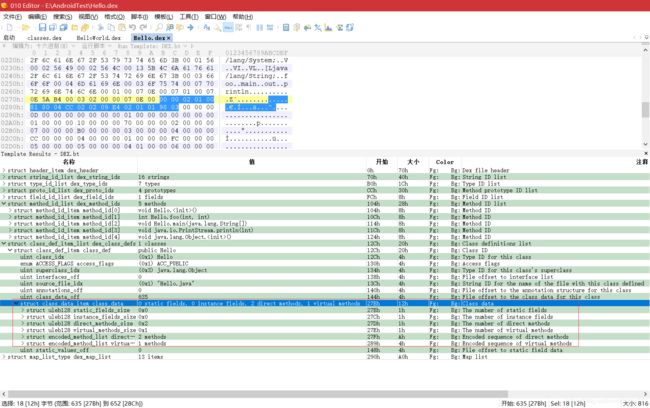
- 从 0x27f 开始解析 DexMethod。第一个字段为 0,指向的 DexMethodId 为第一条,即
ACC_PUBLIC | ACC_CONSTRUCTOR。第三个字段“cc 02”为 0x14c,指向 DexCode 结构
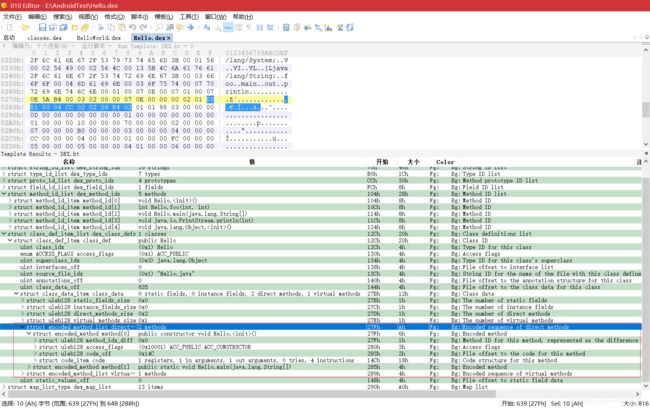
- 从 0x14c 开始解析 DexCode,发现寄存器个数、参数个数、调用其他方法使用的寄存器个数都为 1,方法中有四条指令,具体为“7010 0400 0000 0e00”。打开 DEX,查看指令文档格式(可在这个网站查看:https://source.android.com/devices/tech/dalvik/dalvik-bytecode ),“70”的 Opcode 为
invoke-direct,格式为 0x35c。0x35c 的指令格式(可在这个网站查看:https://source.android.com/devices/tech/dalvik/instruction-formats )为“A|G|op BBBB F|E|D|C”,有八种表示方式,如下图三:


- 在指令“7010”(小端字节序为“1070”)中,A 为 1,G 为 0,表示采用
[A=1] op {vC}, kind@BBBB的方式,其中“vC”为 v0 寄存器,指令后面的“BBBB”和“F|E|D|C”都是 16 位的,“7010”后的两个 16 位都为 0,因此 BBBB=4 且 F=E=D=C=0,BBBB 为 kind@ 类型(指向 DexMethodId 列表的索引值),通过查找得到方法名

- 解码指令,可得如下代码段:
7010 0400 0000 invoke-direct {v0}, Ljava/lang/Object;.:()V
0e00 return-void
- 解析第二个直接方法
- 从 0x285 开始解析 DexMethod。第一个字段为 2,指向 DexMethodId 的第三条,即
main方法。第二个字段“09”为 0x9,访问标志为ACC_PUBLIC | ACC_STATIC。第三个字段“e4 02”为 0x164,指向 DexCode 结构
- 从 0x164 开始解析 DexCode。寄存器个数为 5,参数个数为 1,调用其他方法使用的寄存器个数为 3。方法中有 17 条指令,具体为“2200 0100 7010 0000 0000 6201 0000 1252 1233 6e30 0100 2003 0a00 6e20 0300 0100 0e00”。查看指令文档格式,“22”的 Opcode 为
new-instance vAA, type@BBBB,格式为 0x21c。0x21c 的指令格式为AA|op BBBB,有五种表示方式(见下图三):

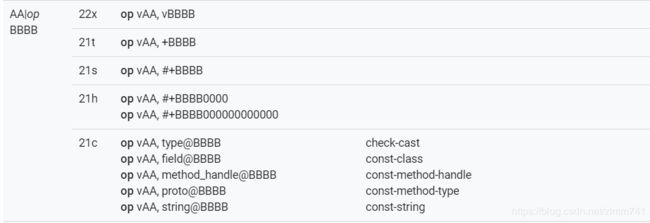
- 在指令“2200”(小端字节序为“0022”)中,AA 为 0,表示采用
op vAA, type@BBBB的方式,其中的“vAA”为 v0 寄存器,BBBB=1,BBBB 为 type@ 类型(指向 DexTypeId 列表的索引值),通过查找得到类类型“LHello;”。至此,第一条指令分析完毕:
2200 0100 new-instance v0, LHello;
- 接着分析。“7010”前面分析过。接下来的“0000 0000”表示 BBBB=0 且 F=E=D=C=0,查表可知方法名为
0710 0000 0000 invoke-direct {v0},LHello;.<init>:()V
- 接着分析。“62”的 Opcode 为
sget-object,格式为 0x21c。0x21c 上面也分析过。“01”表示 AA=0,即采用op vAA, field@BBBB的方式;寄存器为 v1。BBBB=0,表示查 DexFieldId 列表索引值为 0 的那一项。至此,第三条指令分析完毕:

6201 0000 sget-object v1, Ljava/lang/system;.out:Ljava/io/PrintStream;
- 继续分析。“12”的 Opcode 为
const/4 vA, #+B,格式为 0x11n。0x11n 的指令格式为B|A|op,因为指令为“1252”,所以 B=5 且 A=2,即使用 v2 寄存器,常量为 int 类型的 5。至此,第四条指令分析完毕:


1252 const/4 v2, 5
- 继续分析。“1233”基本同上,如下:
1233 const/4 v3, 3
- 继续分析。“6e”的 Opcode 为
invoke-virtual,格式为 0x35c。又是分析过的,可知此处要分析“6e30 0100 2003”。A=3,G=0,表示采用[A=3] op {vC, vD, vE}, kind@BBBB。“2003”的小端字节序为“0320”,即F=0,E=3,D=2,C=0,表示使用 v0、v2、v3 寄存器。
BBBB=1,表示查 DexMethodId 的第二项,可知方法名为foo。至此,第六条指令分析完毕:

6e20 0100 2003 invoke-virtual {v0, v2, v3}, LHello;.foo:(II)I
- 接着分析。“0a”的 Opcode 为
move-result vAA,格式为 0x11x,指令格式为AA|op,可知此处要分析“0a00”,AA=0,使用 v0 寄存器。至此,第七条指令分析完毕:


0a00 move-result v0
- 接着分析。“6e”又是分析过的,可知此处要分析“6e20 0300 0100”。A=2,G=0,表示采用
[A=2] op {vC, vD}, kind@BBBB。“0100”的小端字节序为“0001”,即F=0,E=0,D=0,C=1,表示使用 v1、v0 寄存器。
BBBB=3,表示查 DexMethodId 的第四项,可知方法名为println。至此,第八条指令分析完毕:
6e20 0300 0100 invoke-virtual {v1, v0}, Ljava/io/PrintStream;.println:(I)V
- 最后一条指令之前分析过。至此,全部分析完毕,如下:
2200 0100 new-instance v0, LHello;
0710 0000 0000 invoke-direct {v0},LHello;.:()V
6201 0000 sget-object v1, Ljava/lang/system;.out:Ljava/io/PrintStream;
1252 const/4 v2, 5
1233 const/4 v3, 3
6e20 0100 2003 invoke-virtual {v0, v2, v3}, LHello;.foo:(II)I
0a00 move-result v0
6e20 0300 0100 invoke-virtual {v1, v0}, Ljava/io/PrintStream;.println:(I)V
0e00 return-void
- 剩下的一个虚方法
- 从 0x289 开始解析 DexMethod。第一个字段为 1,指向 DexMethodId 的第一项,即 foo 方法。第二个字段“01”为 0x1,访问标志为 ACC_PUBLIC。第三个字段“9803”为 0x198,指向 DexCode 结构
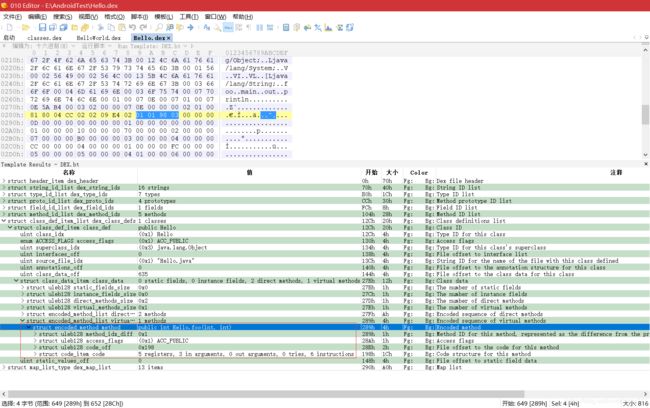
- 从 0x198 开始解析 DexCode。寄存器个数为 5,参数个数为 3,调用其他方法使用的寄存器为 0,方法有 6 条指令,具体为“9000 0304 9101 0304 b210 0f00”。“90”的 Opcode 为
add-int,格式为 0x23x,指令格式为AA|op CC|BB,可知此条指令要分析“9000 0304”。AA=0,CC=4,BB=3,即使用的寄存器为 v0、v3、v4。至此,第一条指令分析完毕:


9000 0304 add-int v0, v3, v4
- 接着分析。“91”的 Opcode 为
sub-int,格式仍为 0x23x,同上面的分析。寄存器为 v1、v3、v4。至此,第二条指令分析完毕:

9101 0304 sub-int v1, v3, v4
- 继续分析。“b2”的 Opcode 为
mul-int/2addr,格式为 0x12x,指令格式为B|A|op,可知此处要分析“b210”。B=1,A=0,使用的寄存器为 v0、v1。至此,第三条指令分析完毕:
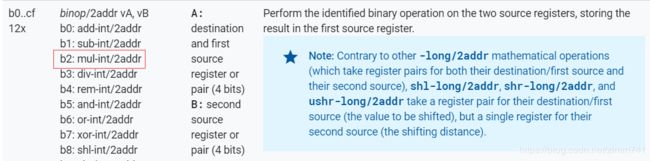

b210 mul-int/2addr v0, v1
- 继续分析。“0f”的 Opcode 为
return vAA,格式为 0x11x,指令格式为AA|op,可知此处要分析“0f00”。AA=0,使用的寄存器为 v0。至此,第四条指令分析完毕:


0f00 return v0
- 所以这个虚方法的代码段如下:
9000 0304 add-int v0, v3, v4
9101 0304 sub-int v1, v3, v4
b210 mul-int/2addr v0, v1
0f00 return v0
-
至此,全部分析完毕
-
再回头看看之前列出的结构(如下表):kDexTypeCodeItem 与上面分析的 DexCode 结构对应;kDexTypeTypeList 与上面分析的 DexTypeList 结构对应;kDexTypeStringDataItem 指向 DexStringId 字符串列表的首地址;kDexTypeDebugInfoItem 指向调试信息偏移量,与 DexCode 的 debugInfoOff 字段指向的内容相同;kDexTypeClassDataItem 指向 DexClassData 结构;kDexTypeMapList 指向 DexMapItem 结构自身
| 类型 | 个数 | 偏移量 |
|---|---|---|
| kDexTypeHeaderItem | 0x1 | 0x0 |
| kDexTypeStringIdItem | 0x10 | 0x70 |
| kDexTypeTypeIdItem | 0x7 | 0xb0 |
| kDexTypeProtoIdItem | 0x4 | 0xcc |
| kDexTypeFieldIdItem | 0x1 | 0xfc |
| kDexTypeMethodIdItem | 0x5 | 0x104 |
| kDexTypeClassDefItem | 0x1 | 0x12c |
| kDexTypeCodeItem | 0x3 | 0x14c |
| kDexTypeTypeList | 0x3 | 0x1b4 |
| kDexTypeStringDataItem | 0x10 | 0x1ca |
| kDexTypeDebugInfoItem | 0x3 | 0x267 |
| kDexTypeClassDataItem | 0x1 | 0x27b |
| kDexTypeMapList | 0x1 | 0x290 |
- 至此,DEX 文件结构分析完毕。下面是一张整理好的 DEX 文件结构图:
DEX 文件的验证与优化过程
- 了解 DEX 文件的验证和优化过程,才能知道 DEX 文件头结构 DexHeader 中 checksum 与 signature 字段的计算过程,才能在修改 DEX 文件后对这两个字段进行修正
- 为使 Android 程序在 Dalvik 虚拟机中快速顺畅运行,有必要对 DEX 文件进行验证和优化。通常,验证与优化 DEX 最简单最安全的方法是直接在虚拟机中加载 DEX,这样一旦程序加载失败,即说明 DEX 文件未优化或验证失败(此时中止程序的运行即可)。不幸的是,这会导致部分资源(如加载的 Native 动态库)难以从内存释放。因此,让验证优化工作与要执行的代码在同一虚拟机运行不是很好的解决方案
- 为解决此问题,Android 提供了一个专门验证和优化 DEX 的工具 dexopt,其源码位于 Android 系统源码的 dalvik/dexopt 目录下,Dalvik 虚拟机在加载一个 DEX 时,通过指定的验证和优化选项来调用 dexopt 进行相应的验证和优化操作
- dexopt 的主程序代码为 OptMain.cpp,其中,处理 apk/jar/zip 中的 classes.dex 文件的函数为 extractAndProcessZip()。extractAndProcessZip() 先通过 dexZipFindEntry() 检查目标文件中是否有 classes.dex。若没有,程序失败并返回。若有,则调用 dexZipGetEntryInfo() 读取 classes.dex 的时间戳与 CRC 校验值。若这一步没问题,接着调用 dexZipExtractEntryToFile() 释放 classes.dex 为缓存文件,然后解析传递过来的验证和优化选项。验证选项用“v=”指出,优化选项用“o=”指出。做完所有准备工作后,调用 dvmPrepForDexOpt(),启动一个虚拟机进程。在这个函数中,优化选项 dexOptMode 和验证选项 verifyMode 被传递到全局 DvmGlobals 结构 gDvm 的 dexOptMode 与 classVerifyMode 字段中。这时,所有的初始化工作完成,dexopt 调用 dvmContinueOptimization(),开始进行真正的验证和优化工作
- dvmContinueOptimization() 的调用链较长。把注意力从 OptMain.cpp 转到 dalvik/vm/analysis/DexPrepare.cpp 上,这里有 dvmContinueOptimization() 的实现。该函数首先对 DEX 进行简单的检查,确保传递进来的目标文件属于 DEX 或 ODEX,接着调用 mmap() 将整个文件映射到内存,然后根据 gDvm 的 dexOptMode 与 classVerifyMode 字段来设置 doVerify 与 doOpt 两个布尔值,调用 rewriteDex() 重写 DEX(重写内容包括字节序调整、结构重新对齐、类验证信息及辅助数据)。rewriteDex() 调用 dexSwapAndVerify() 调整字节序,调用 dvmDexFileOpenPartial() 创建 DexFile 结构。dvmDexFileOpenPartial() 的实现在 Android 系统源码文件 dalvik/vm/DvmDex.cpp 中,该函数调用 dexFileParse() 解析 DEX。dexFileParse() 读取 DEX 文件头,并根据需要调用 dexComputeChecksum() 验证 DEX 文件头的 checksum 字段,或调用 dexComputeoOptChecksum() 验证 ODEX 文件头的 checksum 字段。代码片段如下:
if (flags & kDexParseVerifyChecksum) {
u4 adler = dexComputeChecksum(pHeader);
if (adler != pHeader->checksum) {
ALOGE("ERROR: bad checksum (%08x vs %08x)",
adler, pHeader->checksum);
if (!(flags & kDexParseContinueOnError)) {
goto bail;
}
}
else {
ALOGV("+++ adler32 checksum (%08x) verified", adler);
}
const DexOptHeader* oOptHeader = pDexFile->oOptHeader;
if (pOptHeader != NULL) {
adler = dexComputeOptChecksum(pOptHeader);
if (adler != pOptHeader->checksum) {
ALOGE("ERROR: bad opt checksum (%08x vs %08x)",
adler, pOptHeader->checksum);
if (!(flags & kDexParseContinueOnError)) {
goto bail;
}
}
else {
ALOGV("+++ adler32 opt checksum (%08x) verified", adler);
}
}
}
- dexComputeChecksum() 的代码:
u4 dexComputeChecksum(const DexHeader* pHeader) {
const u1* start = (const u1*)pHeader;
uLong adler = adler32(0L, Z_NULL, 0);
const int nonSum = sizeof(pHeader->magic) + sizeof(pHeader->checksum);
return (u4)adler32(adler, start + nonSum, pHeader->fileSize - nonSum);
}
-
checksum 实际是调用 adler32() 完成计算的,整个步骤:跳过 DexHeader 的 magic 和 checksum 字段,将第三个字段到文件结尾作为计算的总数据长度,调用 Adler32 标准算法计算数据的 adler 值
-
dexComputeOptChecksum() 的代码:
u4 dexComputeOptChecksum(const DexOptHeader* pOptHeader) {
cosnt u1* start = (const u1*)pOptHeader + pOptHeader->depsOffset;
const u1* end = (cosnt u1*)pOptHeader + pOptHeader->optOffset +
pOptHeader->optLength;
uLong adler = adler32(0L, Z_NULL, 0);
return (u4)adler32(adler, start, end - start);
}
-
ODEX 的 checksum 计算方法与 DEX 的一样,只是其取值范围是从 ODEX 文件头到最后的依赖库与辅助数据两个数据块
-
下一步是验证 signature,代码:
if (kVerifySignature) {
unsigned char sha1Digest[kSHA1Digest];
const int nonSum = sizeof(pHeader->magic) + sizeof(pHeader->checksum) + kSHA1DigestLen;
dexComputeSHA1Digest(data + nonSum, length - nonSum, sha1Digest);
if (memcmp(sha1Digest, pHeader->signature, kSHA1DigestLen) != 0) {
char tmpBuf1[kSHA1DigestOutputLen];
char tmpBuf2[kSHA1DigestOutputLen];
ALOGE("ERROR: bad SHA1 digest (%s vs %s)",
dexSHA1DigestToStr(sha1Digest, tmpBuf1),
dexSHA1DigestToStr(pHeader-signature, tmpBuf2));
if (!(flags & kDexParseContinueOnError)) {
goto bail;
}
}
else {
ALOGV("+++ sha1 digest verified");
}
}
-
验证算法是:跳过 magic、checksum、signature 字段,调用 dexComputeSHA1Digest() 对 DEX 头部后面的数据进行 SHA-1 计算,然后将计算结果与 signature 字段中保存的值比较,若相等就通过,不相等则验证失败
-
dexComputeSHA1Digest() 的代码:
static void dexComputeSHA1Digest(const unsigned char* data,
size_t length, unsigned char digest[]) {
SHA1_CTX context;
SHA1Init(&context);
SHA1Update(&context, data, length);
SHA1Final(digest, &context);
}
-
这是 OpenSSL 库中计算 SHA-1 散列值的接口
-
回到分析流程。验证成功后,dvmDexFileOpenPartial() 调用 allocateAuxStructures(),设置与 DexFile 结构辅助数据相关的字段,执行后返回 rewriteDex()。接着,rewriteDex() 调用loadAllClasses(),加载 DEX 中所有的类(若这一步失败,程序等不到后面的优化与验证就推出了;若执行这一步没发生错误,程序会调用 verifyAndOptimizeClasses() 完成真正的验证工作)。loadAllClasses() 会调用 verifyAndOptimizeClass() 优化和验证具体的类,而且 verifyAndOptimizeClasses() 会细分这些工作,先调用 dvmVerifyClass() 进行验证,再调用 dvmOptimizeClass() 进行优化
-
dvmVerifyClass() 的实现代码位于 Android 系统源码文件 dalvik/vm/analysis/DexVerify.cpp 中。这个函数调用 verifyMethod() 对类的所有直接方法和虚方法进行验证。verifyMethod() 的具体工作:先调用 verifyInstructions() 验证方法中的指令及其数目的正确性,再调用 dvmVerifyCodeFlow() 验证代码流的正确性
-
dvmOptimizeClass() 的实现代码位于 Android 系统源码文件 dalvik/vm/analysis/Optimize.cpp 中。这个函数调用 optimizeMethod() 对类的所有直接方法和虚方法进行优化,优化的主要工作是进行指令替换,替换的优先级:volatile 替换最高,正确性替换其次,高性能替换最低。如,iget-wide 指令会根据优先级被替换成 volatile 形式的 iget-wide-volatile,而不是高性能的 iget-wide-quick
-
rewriteDex() 返回后,会再次调用 dvmDexFileOpenPartial() 验证 ODEX,并接着调用 dvmGenerateRegisterMaps() 填充辅助数据区的结构。完成对结构的填充后,会调用 updateChecksum() 重写 DEX 的 shecksum 值。接下来,调用 writeDependencies() 和 writeOptData()
-
dexopt 的整个验证和优化过程就是这样
DEX 文件的修改
- 在第二章的破解中,修改完 smali 代码后,使用 ApkTool 重新编译 APK 会花费大量时间。接下来是一种快速测试 APK 的方法
- Android 程序的代码都存储在 DEX 中,通过修改代码中的执行路径就能破解程序。但先要定位程序的破解点,可使用 IDA Pro,用它可方便地找到程序破解点对应的文件偏移
- 用 unzip 解压缩命令取出 crackme0201.apk 中的 classes.dex,将其拖入 IDA Pro,进入程序反汇编界面,等待 IDA 分析完成
- 按照第二章的破解思路,搜索字符串“unsuccessed”。在 IDA 中按 Alt+T,在 Text search 搜索框中输入“unsuccessed”字符串的 ID 0x7f0c0028,单击“OK”
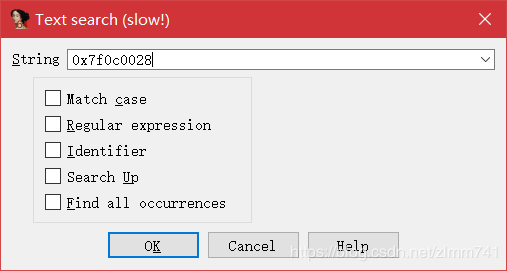
- 搜索结果如下,按空格进入
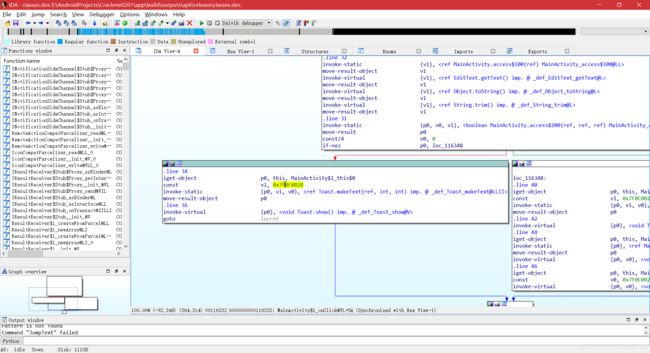
- 根据第二章的分析经验,可判断下图中标记处是破解的关键点
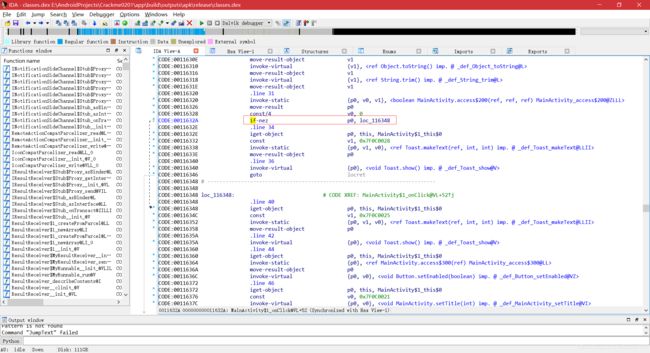
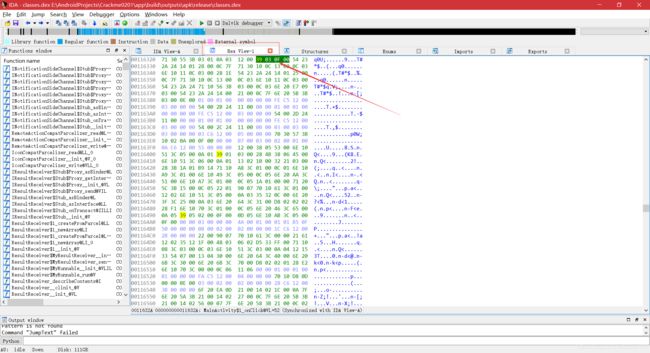
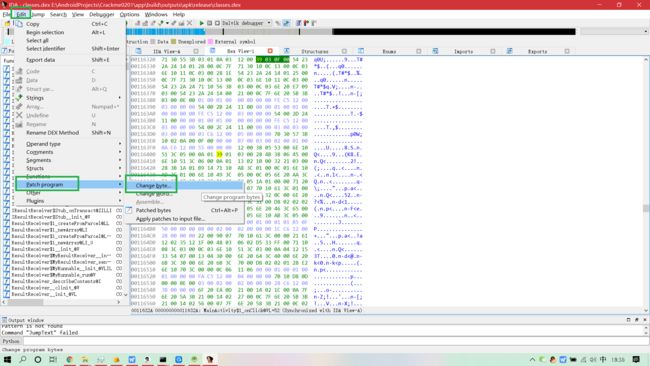
- 单击 IDA 主界面上的“Hex View-1”选项卡,发现这行代码的指令为“39 03 0f 00”,第一个字节“39”为指令
if-nez的 Opcode,只要将其改成if-eqz指令的 Opcode 即可,查看 Dalvik 指令集列表(如下),可知if-eqz指令的 Opcode 为“38”

- 接下来利用 IDA 的给原文件打补丁功能,把“39”修改为“38”,如下:
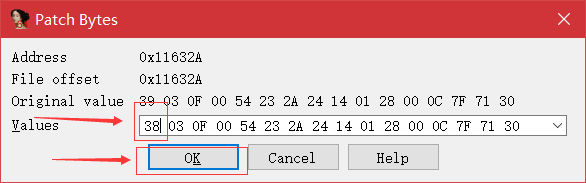
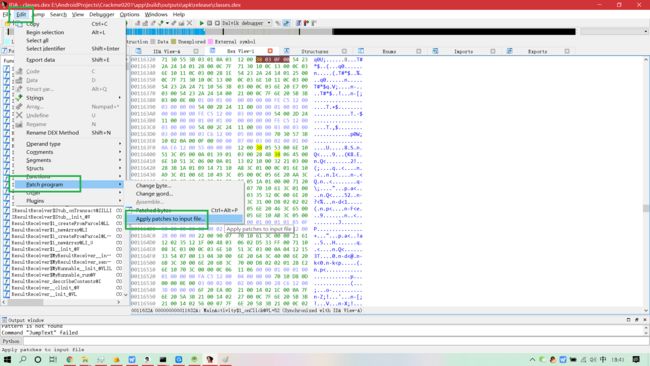
- 修改完成后,执行如下操作保存:
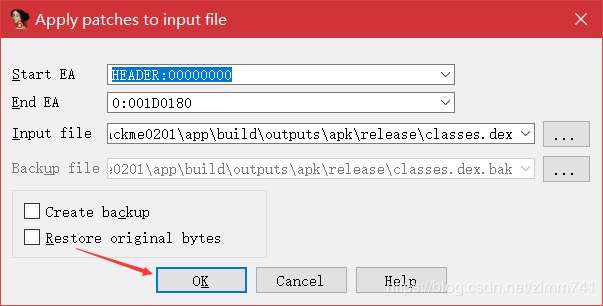
- 修改后的 DEX,其 DexHeader 头部的 checksum 和 signature 字段是错的,要修正。结合上一节分析的 DEX 的合法性验证流程,可用 010 Editor 编写脚本,完成对 DEX 的修改。脚本如下:
int endian = ReadInt(0x28); // endian_flag
if (endian == 0x12345678) {
LittleEndian();
}
else {
BigEndian();
}
uchar sha1[20];
ReadBytes(sha1, 0xc, 20);
Printf("src sha1: ");
uint i = 0;
for (i = 0; i < 20; i++) {
Printf("%02x", sha1[i]);
}
Printf("\n");
uchar checksum[20];
ChecksumAlgBytes(CHECKSUM_SHA1, checksum, 0x20);
Printf("calced sha1: ");
for (i = 0; i < 20; i++) {
Printf("%02x", checksum[i]);
}
Printf("\n");
int adler32 = ReadInt(0x8);
if (Memcmp(checksum, sha1, 20) != 0) {
WriteBytes(checksum, 0xc, 20);
}
else {
Printf("same sha1\n");
}
int adler32_ = Checksum(CHECKSUM_ADLER32, 0xc);
Printf("src adler32: %x\n", adler32);
Printf("calced adler32:%x\n", adler32_);
if (adler32_ != adler32) {
WriteInt(0x8, adler32_);
}
else {
Printf("same adler32\n");
}
Printf("Done.\n");
- 用 010 Editor 打开要刚刚的 classes.dex,执行上述脚本,即可完成修改
- 推荐用 dex2jar(下载地址:https://github.com/DexPatcher/dex2jar/releases/ )提供的工具 d2j-dex-recompute-checksum。执行如下命令:
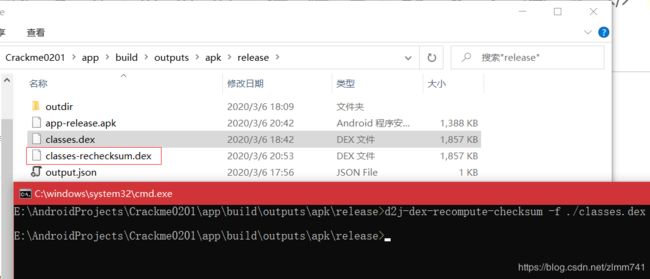
- 执行完后,会在 classes.dex 当前目录下生成如上图中所标记的文件。将其改名为“classes.dex”,重新打包进 APK 并签名,然后安装程序进行测试,如下:
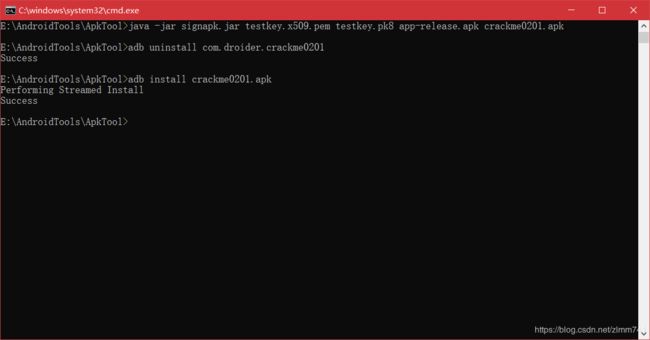
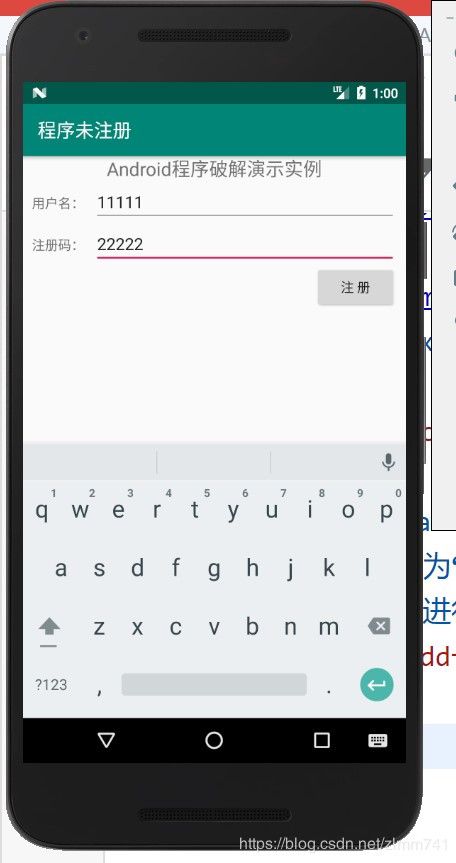
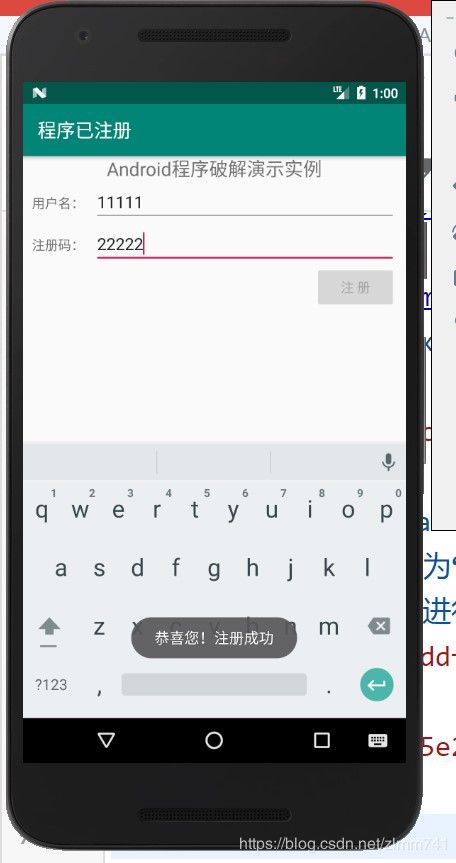
- 至此,破解成功
MultiDex
- MultiDex 称为“Dex 分包技术”。早期的文件格式设计中,DEX 中包含的方法数量被限制为 64KB 个。随着 APK 软件的升级和更新,DEX 中包含 64KB 个方法已不再稀奇。在这种情况下,DEX 的编译会失败,但修改 DEX 文件格式又不太现实,就出现了 DEX 分包技术
- MultiDex 的实现位于 Android 源码的 frameworks/multidex 目录下
- 要在 AS 中开启 MultiDex,可在模块的 build.gradle 文件中添加如下代码:
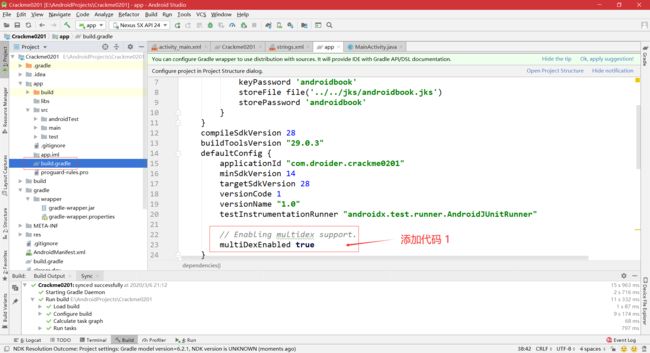
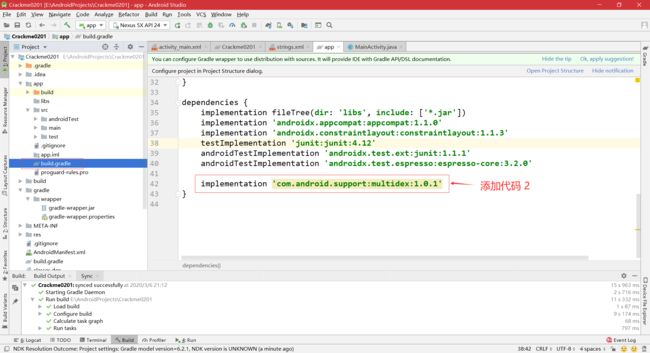
- buildToolsVersion 必须运行在 AS 21.1.0 及以上版本中,且必须在 defaultConfig 中将 multiDexEnabled 设置为 true。当 minSdkVersion 的值小于 21 时,必须在 dependencies 中配置 Multidex 支持,大于 21 则不需要
- 配置 build.gradle 后,还要对 MultiDex 进行初始化。若没有在 AndroidManifest.xml 中配置 Application 标签,就要为程序指定一个 Application,具体方法是编辑 AndroidManifest.xml 添加如下内容:
...
- 在程序没有 Application 类的情况下,要为 MultiDex 指定 APK 的 Application 的 name 为“android.support.multidex.MultiDexApplication”
- 若程序中已经设置 Application 类,则要在 Application 初始化时插入 MultiDex 的初始化代码,具体方法:修改自己的 Application 类,让它继承自 MultiDexApplication,然后在 attachBaseContext() 中添加如下代码:
public class MyApplication extends SomeOtherApplication {
@Override
protected void attachBaseContext(Context base) {
super.attachBaseContext(context);
Multidex.install(this);
}
}
- 配置完成后,AS 在生成 DEX 文件时就会自动生成 classes1.dex、classes2.dex、classes3.dex,依此类推
- 这种 APK 的破解方法:
- 新版本的 ApkTool 支持对启用了 MultiDex 的 APK 进行反编译,且不用对反编译后的命令进行任何修改:
apktoll d app-release.apk -o outdir
- ApkTool 会对不同的 DEX 分别进行反编译,并将反编译结果放到独立的目录中。只要找到关键的 smali 代码,之后的过程就和第二章介绍的一样
- 不进行反编译而直接修改 DEX 也是可行的,就如前一节介绍的那样就行