Kubernetes(K8S)学习笔记(2):Kubernetes架构
注:该笔记整理自Kubernetes官方文档中的内容,笔记中使用的观点与资源均来源于官方文档以及我个人的理解,如果涵盖其它来源的观点,会额外标明引用。
1、相关概念
Kubernetes集群由一个控制平面与一组用于运行容器化应用的工作机器组成,我们把这些工作机器称之为节点(Node)。工作节点托管着组成工作负载的Pod,控制平面负责管理工作节点以及Pod,以下为Kubernetes集群组件的逻辑关系图:
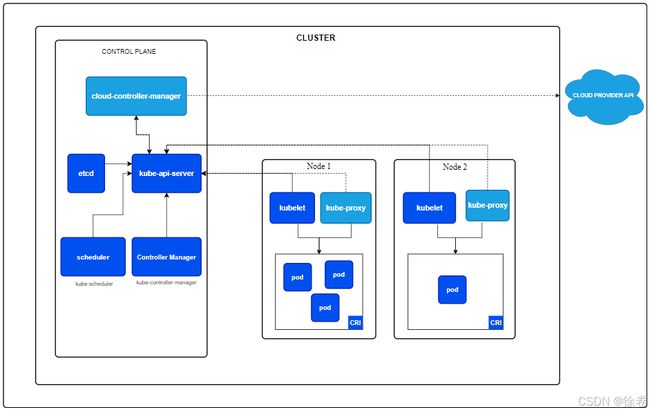
控制平面为集群提供全局层面的决策,例如资源调度。以及检测集群层面的事件,例如Pod副本不足时,需要启动新的Pod。
控制平面的组件可以在任意的节点上运行,但是通常而言,为了方便,我们通常将这些组件单独放置在一个节点上,该节点不会托管用户容器。
以下描述了控制平面中的各个组件:
-
kube-api-server:API服务器是Kubernetes控制平面的前端,该组件公开了Kubernetes API,并负责接收请求的工作。
-
etcd:一种键值数据库,用作所有集群数据的后台数据库,如果使用etcd作为后台数据库,建议进行备份。
-
kube-scheduler:负责监视新创建的、未指定节点的Pod,并为它们分配合适的Node
-
kube-controller-manager:负责运行控制器进程,虽然在逻辑上看每个控制器都属于一个进程,但是为了降低复杂性,通常把这些控制器进程编译到一个文件中执行。一些控制器的例子:Node控制器(负责节点出现故障时进行通知响应)、Job控制器(监视代表一次性任务的Job对象,创建Pod来运行这些任务直至完成)等。
-
cloud-controller-manager:这是一个特定于云平台的控制管理器,注意,我们部署的本地集群如果不连接云提供商的云端集群,则不需要该组件,其中嵌入了特定于云平台的控制逻辑。
以下描述了节点组件:
-
kubelet:在每个节点上运行,它保证容器都运行在Pod之中,此外,它接收一个通过各种机制传递给它的一个PodSpec,它需要监控这些PodSpec中的容器处于运行状态且健康(仅限于由kubernetes创建的)。
-
kube-proxy:每个节点上运行的网络代理,实现Kubernetes服务概念的一部分,它维护网络规则,并允许集群内部或外部的一些网络会话与Pod进行通信。
-
容器运行时:负责容器的执行与生命周期。
除了组件,插件也十分重要,插件使用Kubernetes资源实现某些功能,由于插件提供的集群级别的功能,因此插件中命名空间范围的资源属于 kube-system 名字空间。
-
DNS:即使某些插件可能不是必须的,但几乎所有的Kubernetes集群都需要有集群DNS,因为很多示例都需要DNS服务。集群DNS本质上也是一个DNS服务器,它与环境中的其他DNS服务器一起工作。
-
Web界面:Dashboard是Kubernetes集群的通用的,基于Web的用户界面
-
容器资源监控:将关于容器的一些常见的时序度量值放置在一个数据库中,并提供浏览这些数据的界面。
2、节点
Kubernetes通过将容器放置在节点上运行的Pod来处理工作负载,节点可以是一个虚拟机也可以是一个物理主机。节点上的组件主要包括kubelet、kube-proxy、容器运行时。
向API Server中添加节点的方式主要有两种:
-
节点上的kubelet向控制平面执行自注册
-
某人手动创建了一个Node
当以上两种方式发生时,控制平面会检测新创建的Node是否是合法的。以下是一个Node的创建示例:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}Node的名称必须为合法的DNS子域名,Kubernetes会创建一个Node对象作为节点的表示,如果节点是健康的(所有必要的服务都在运行中)则该节点可以被用来运行Pod,否则,Kubernetes持续检查该非法节点,直至其变为健康。在此之前,集群会忽略该节点。你必须人为删除或者某个控制器删除该节点,才会终止Kubernetes对于该非法节点的持续检测。
节点的名称用于唯一标识Node对象,没有两个Node的名称是一样的。Kubernetes任务相同名称的资源是相同的,如何理解这句话呢?例如,一个工作机器有一个Node对象,也有一个Lease对象,他们两个的名字相同,则认为他们都指代该工作机器。
当kubelet标志 --register-node 为True(默认)时,节点会尝试向API服务注册它自己。
3、控制器
控制器会监控集群的状态,并致力于将当前状态转化为期望状态。举一个例子,我们使用空调遥控器调节温度,它上面显示的温度就是期望状态,但屋子里的实际温度并不是遥控器上显示的温度,因此空调会致力于将屋子里的温度转化为那个温度。
3.1、控制器模式
一个控制器至少追踪一种类型的Kubernetes资源,这些资源对象存在一个spec(规约)字段,控制器负责让它的当前状态逼近期望状态。
以Job控制器为例,Job是Kubernetes资源的一种,完成它需要运行一个或多个Pod,Job服务器本身不会执行任何容器或Pod,它通知API-server来控制Pod的创建与删除操作。创建Job以后,期望状态就是完成这个Pod,因此Job控制器会要求API-server创建完成该Job所需的pod,进而使Job不断逼近完成状态。一旦Job完成了,Job控制器会更新该Job的状态为Finished。
控制器是Kubernetes设计原则之一,Kubernetes中存在相当多的控制器,一个控制器通常负责管理集群的一个方面,最常见的是,一个控制器期望实现一种类型的资源的状态(例如Job控制器希望完成Job),并操控另一种资源来逼近这个状态(Job控制器控制Pod的运行来完成Job)。
3.2 运行控制器的方式
kubernetes内置的一组控制器在kube-controller-manager中运行,这点我们在前面已经进行了简单的介绍。Kubernetes允许你运行一个稳定的控制平面,当一些控制器失败的时候,其他控制平面的部分会接替他们的工作。你自定义的控制器可以放置在Pod中,也可以放置在Kubernetes集群之外。
4、租约
租约(Lease)提供了一个锁定共享资源的机制,同时协调集群成员之间的活动。在Kubernetes中,租约使用 coordination.k8s.io 组中的Lease对象表示。
节点心跳:每个节点都存在节点心跳,它周期性的向其他节点发送心跳信号,以表明自己的存在与健康。具体表现为,在kube-node-lease名字空间中,对于每一个节点都存在一个Lease对象,该Lease对象与Node对象的名称一致,kubelet心跳本质上是对Lease对象的update请求,即更新该Lease对象的 spec.renewTime 字段,kubelet周期性将心跳信号发送给API Server,API Server会更新ETCD中Lease对象。
领导者选取:在高可用环境下,我们通常要提升集群的容灾能力,一个集群如果只包含一个组件,那如果这个组件崩溃,则会影响到集群整体的性能,因此,我们通常选择将一个组件创建成多个实例,但其中只需要一个Leader进行,其他作为备用,当Leader崩溃或无法使用时,Lease对象会根据一定策略从该组件的备用实例中选取一个接管其职责。与集群节点的心跳类似,组件同样会更新Lease的spec.renewTime 字段,并根据这个字段确定其是否可用。
API服务器身份:每个apiserver通过一个租约对象公开自身信息,这可以允许客户端查询当前活跃的API-Server有多少个。