第十二章 软件壳(五)(代码混淆壳)
文章目录
- 代码混淆壳
- LLVM 基础
- 编写 Pass
- Obfuscator-LLVM
- 指令替换
- 控制流平坦化
- 伪造控制流
- 代码混淆壳的脱壳
- 指令替换混淆的还原
- 控制流平坦化混淆的还原
- 伪造控制流混淆的还原
代码混淆壳
- 分为
- Java 级别的代码混淆
- 加密保护型的第一代壳
- 原生程序的代码混淆
- 代码混淆的第三代壳
- Java 级别的代码混淆
- 源于 LLVM 编译套件的编译器特性,通过编写 LLVM Pass 对编译原生程序时生成的 LLVM IR 进行操作,可实现类似 Windows 平台 VMProtect 等虚拟机软件壳的加密保护效果
- 目前 Android 平台最高级别的软件加密技术
LLVM 基础
-
LLVM 不是单一的编译器,是一个可重用的、与编译器相关的组件集合,包含:
- LLVM source code
- LLVM 源码,包含 LLVM 所有核心功能库
- Clang source code
- Clang 前端源码
- Compiler-rt source code
- 编译器运行时
- libc++ source code
- 开源的 C++ 标准库的实现
- libc++abi source code
- 开源的 C++ 标准库 ABI 的实现
- libunwind source code
- 异常展开库
- LLD source code
- 链接器
- LLDB source code
- 调试器
- OpenMP source code
- OpenMP 并行库的实现
- Polly source code
- Polly 库
- Clang-tools-extra
- Clang 前端的额外工具
- LLVM test suite
- LLVM 测试套件
- LLVM source code
-
传统的编译器采用三步设计法(Three Phase Design)设计,按照程序的生成步骤为编译器设计了前端(Frontend)、优化器(Optimizer)、后端(Backend)共三个功能模块
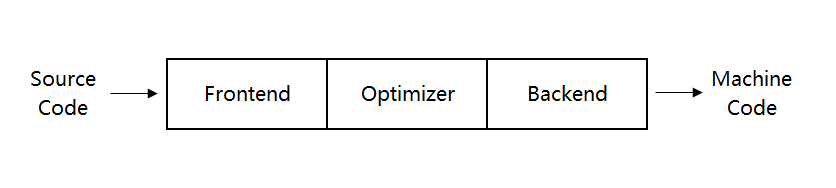
- 前端
- 负责解析代码,检查代码中的错误,生成与语言相关的抽象语法树(AST)
- 由前端生成的 AST 可选择性的生成供优化器处理的中间表示形式
- 优化器
- 负责对前端生成的中间结果优化处理
- 后端
- 将优化器的处理结果生成与处理器相关的平台指令集
- 前端
-
LLVM 沿用三步设计法
-
基于 LLVM 的编译器,由前端生成的 AST 首先会转换成 LLVM 的中间表示(LLVM IR),然后由 LLVM 提供的优化器优化处理,优化器会加载当前 LLVM IR 使用的 LLVM Pass,对 LLVM IR 层层优化,最后交给后端生成与平台相关的机器指令
-
LLVM 优化器的框架
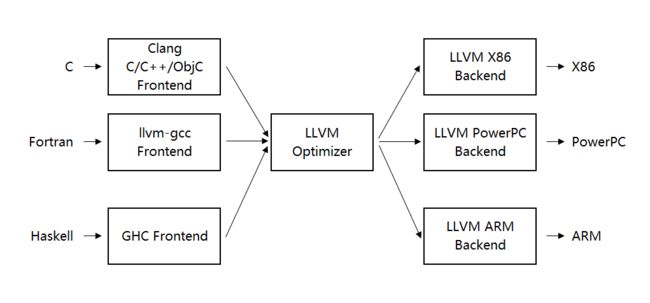
-
以 LLVM 编译套件中的 Clang 编译器为例,其编译器前端实现是一个 clangFrontend 动态库模块,在代码中被抽象成 ASTFrontendAction 类,LLVM 的优化器是一个命令行程序 opt,它将传入的 LLVM Pass 用于 LLVM IR,LLVM Pass 可理解为“流程”,既可嵌入编译系统,也可以动态库形式单独存在(供 opt 命令行调用)
-
安装最新版本的 LLVM 套件(下载地址)


-
安装 graphviz
apt-get install graphviz -
app6.c
#includeint nums[5] = {1, 2, 3, 4, 5}; int for1(int n) { int i = 0; int s = 0; for (i = 0; i < n; i++) { s += i * 2; } return s; } int for2(int n) { int i = 0; int s = 0; for (i = 0; i < n; i++) { s += i * i + nums[n - 1]; } return s; } int dowhile(int n) { int i = 1; int s = 0; do { s += i; } while (i++ < n); return s; } int whiledo(int n) { int i = 1; int s = 0; while (i <= n) { s += i++; } return s; } void if1(int n) { if (n < 10) { printf("the number less than 10\n"); } else { printf("the number greater than or equal to 10\n"); } } void if2(int n) { if (n < 16) { printf("he is a boy\n"); } else if (n < 30) { printf("he is a young man\n"); } else if (n < 45) { printf("he is a strong man\n"); } else { printf("he is an old man\n"); } } int switch1(int a, int b, int i) { switch (i) { case 1: return a + b; break; case 2: return a - b; break; case 3: return a * b; break; case 4: return a / b; break; default: return a + b; break; } } int main(int argc, char const *argv[]) { printf("for1: %d\n", for1(5)); printf("for2: %d\n", for2(5)); printf("dowhile: %d\n", dowhile(100)); printf("while: %d\n", whiledo(100)); if1(5); if2(35); printf("switch1: %d\n", switch1(3, 5, 3)); return 0; }
-
执行如下命令,即可使用 Clang 编译生成 app6 的 LLVM IR

-
执行上述命令会生成 app6.ll,即 LLVM IR 的可视化表示
-
将
-Xclang -ast-dump参数传入编译器,打印程序的 AST 信息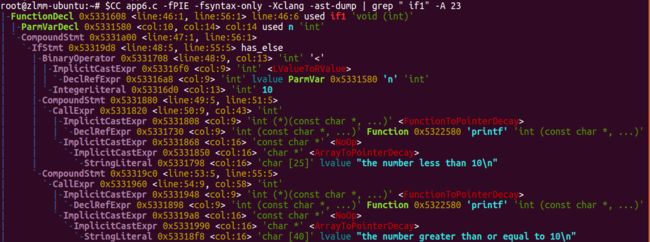
-
可看到,LLVM IR 被抽象成了 C++ 类的对象。一个源文件经过编译器的编译,生成的中间结果表示一个模块 Module,在源码中其对应
llvm::Module类。Module 由代码和数据组成,它们都被抽象成llvm::Value类,全局变量llvm::GlobalVariable与函数llvm::Function都继承自它 -
可将
-print-module参数传入 opt 命令,打印 LLVM IR 的 Module 信息opt -print-module app6.ll -
对代码混淆而言,主要关注函数对象
llvm::Function -
llvm::Function由一个或多个基本块llvm::BasicBlock组成,每个基本块由多条指令llvm::Instruction组成 -
可将
-print-function和-print-bb参数传入 opt 命令,分别打印它们的函数和基本块信息opt -print-function app6.ll opt -print-bb app6.ll
-
基本块表示一组顺序执行且没有分支跳转的指令集合,基本块和基本块间的连接形成流程控制图(Control Flow Graph,CFG)
-
可将
-dot-cfg参数传入 opt 命令,生成 Module 中所有函数的 CFG(隐藏文件)
-
可用 dot 命令将生成的 dot 文件转换为 png 格式的图片,以 if1() 为例,执行如下命令即可生成 cfgif1.png

-
cfgif1.png 内容
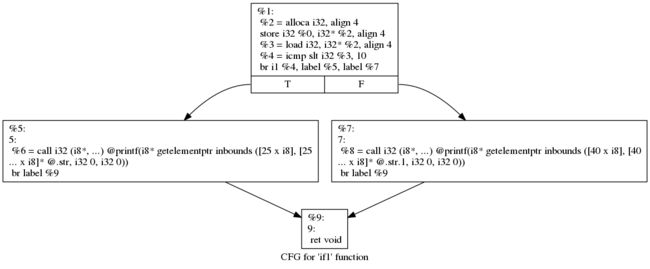
-
上图中有四个基本块,每个之间用箭头连接,每个中都有一条或多条 LLVM IR 指令。LLVM IR 指令和平台相关的汇编指令一样,有自己的含义和规范
-
app6 的 if1() 的 LLVM IR 指令
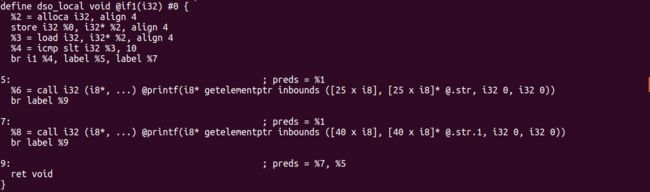
-
LLVM 语言参考手册:可查看所有指令含义和格式规范
-
第一条指令的格式
= alloca [inalloca] [, ] [, align ] [, addrspace( )] -
作用
-
在栈中为当前执行的函数分配内存空间,该空间会在函数返回后自动释放
-
%3 = alloca i32, align 4:分配一个按 4 字节对齐的 32 位内存空间,将结果保存在标号%3中
-
-
-
store i32 %0, i32* %4, align 4:将标号%0中的参数的值存储到标号%4指向
的内存区域
-
函数和函数间也存在一种类似 CFG 的图 —— CG(Call Graph,调用关系图),它们间是调用和被调用的关系
-
将
-dot-callgraph参数传入 opt 命令,生成 Module 的 CG,执行如下命令,可生成 callgraph.png
-
生成的 png 中,每个函数都变成一个”基本块“,它们间用箭头连接,构成一幅完整的调用关系图
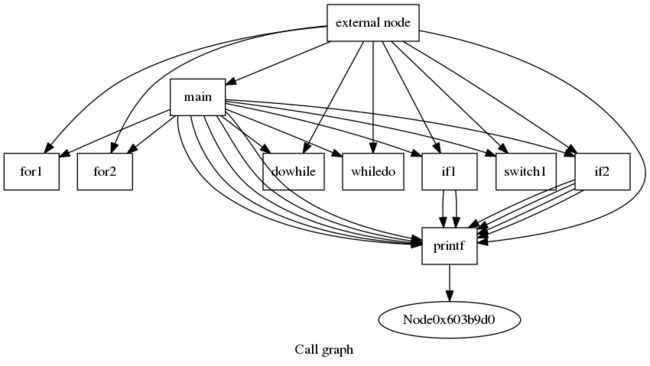
编写 Pass
-
LLVM 的 Pass 在代码中表示为
llvm::Pass类,安装 LLVM 套件后,在其/include/llvm/Pass.h中声明了常用的 Pass 类 ModulePass、FunctionPass、BasicBlockPass,分别作用于模块、函数、基本块 -
如何通过编写 FunctionPass 类实现 LLVM IR 的代码混淆?
-
FunctionPass 类的声明(备注:explicit 关键字的作用为防止类构造函数的隐式自动转换)
class FunctionPass : public Pass { public: explicit FunctionPass(char &pid) : Pass(PT_Function, pid) {} /// createPrinterPass - Get a function printer pass. Pass *createPrinterPass(raw_ostream &OS, const std::string &Banner) const override; /// runOnFunction - Virtual method overriden by subclasses to do the /// per-function processing of the pass. virtual bool runOnFunction(Function &F) = 0; void assignPassManager(PMStack &PMS, PassManagerType T) override; /// Return what kind of Pass Manager can manage this pass. PassManagerType getPotentialPassManagerType() const override; protected: /// Optional passes call this function to check whether the pass should be /// skipped. This is the case when Attribute::OptimizeNone is set or when /// optimization bisect is over the limit. bool skipFunction(const Function &F) const; };
-
编写 Pass 时,主要添加对 runOnFunction() 虚函数的处理,该函数会在 Module 中的每个函数做优化时执行,LLVM Pass 操作的是函数中的指令,因此要对其指令的遍历访问方法有所了解
-
如何通过 C++ 11 Range-based for 循环遍历 app4.c 程序的 LLVM IR 指令:
namespace { struct AddObfPass: public FunctionPass { static char ID; // Pass identification, replacement for typeid AddObfPass(): FunctionPass(ID) { llvm::errs() << "AddObfPass init.\n"; } bool runOnFunction(Function &F) override { for (BasicBlock &B: F) { for (Instruction &I: B) { llvm::errs() << I << "\n"; } } return false; } } }
-
除了通过 Range-based for 循环遍历,还可用 STL 模板的迭代器 Iterator 遍历:
bool runOnFunction(Function &F) override { Function* tmp = &F; for (Function::iterator bb = tmp->begin(); bb != tmp->end(); ++bb) { for (BasicBlock::iterator inst = bb->begin(); inst != bb->end(); ++inst) { llvm::errs() << *inst << "\n"; } } return false; }
-
手动实现一个基于 LLVM Pass 的加法指令混淆器
-
LLVM Pass 的名字为 AddObfPass,作用:对 LLVM IR 中的所有加法操作执行代码混淆
-
编写 AddObfPass 前要为 Pass 编写注册代码,以便 Pass 能正确加载
-
Pass 的注册分:命令行参数注册、自动化注册
-
以自动化注册为例
static void registerAddObfPass(const PassManagerBuilder &, legacy::PassManagerBase &PM) { PM.add(new AddObfPass()); } static RegisterStandardPasses RegisterMyPass(PassManagerBuilder::EP_EarlyAsPossible, registerAddObfPass);
-
编写 Pass 后,要完成编译工作,可将 Pass 的代码放到 LLVM 的源码中编译,也可编写 CMake 脚本从外部编译
cmake_minimum_required(VERSION 3.5) find_package(LLVM REQUIRED CONFIG) add_definitions(${LLVM_DEFINITIONS}) include_directories(${LLVM_INCLUDE_DIRS}) link_directories(${LLVM_LIBRARY_DIRS}) add_library(AddObf MODULE # List your source files here. AddObf.cpp ) set(LIBRARY_OUTPUT_PATH ${PROJECT_BINARY_DIR}/lib) # Use C++11 to compile our pass (i.e., supply -std=c++11). target_compile_features(AddObf PRIVATE cxx_range_for cxx_auto_type) # LLVM is (typically) built with no C++ RTTI. We need to match that; # otherwise, we'll get linker errors about missing RTTI data. set_target_properties(AddObf PROPERTIES COMPILE_FLAGS "-fno-rtti" ) find_program(LLVM_CONFIG_EXECUTABLE llvm-config) if(NOT LLVM_CONFIG_EXECUTABLE) message(FATAL_ERROR "Unable to find program 'llvm-config'") endif(NOT LLVM_CONFIG_EXECUTABLE) message(STATUS "Using llvm-config: ${LLVM_CONFIG_EXECUTABLE}") #LLVMCONFIG_COMPILE_FLAGS="llvm-config --cppflags" #LLVMCONFIG_LINK_FLAGS="llvm-config --ldflags --libs --system-libs" execute_process(COMMAND ${LLVM_CONFIG_EXECUTABLE} --cppflags OUTPUT_VARIABLELLVMCONFIG_CXX_FLAGS OUTPUT_STRIP_TRAILING_WHITESPACE) execute_process(COMMAND ${LLVM_CONFIG_EXECUTABLE} --ldflags OUTPUT_VARIABLELLVMCONFIG_LD_FLAGS OUTPUT_STRIP_TRAILING_WHITESPACE) execute_process(COMMAND ${LLVM_CONFIG_EXECUTABLE} --libs OUTPUT_VARIABLELLVMCONFIG_LIBS OUTPUT_STRIP_TRAILING_WHITESPACE) execute_process(COMMAND ${LLVM_CONFIG_EXECUTABLE} --system-libs OUTPUT_VARIABLELLVMCONFIG_SYSLIBS OUTPUT_STRIP_TRAILING_WHITESPACE) # LLVM is (typically) built with no C++ RTTI. We need to match that; # otherwise, we'll get linker errors about missing RTTI data. set_target_properties(AddObf PROPERTIES COMPILE_FLAGS "-fno-rtti -O0 -g -std=c++11 ${LLVMCONFIG_CXX_FLAGS}" ) set_target_properties(AddObf PROPERTIES LINK_FLAGS "${LLVMCONFIG_LD_FLAGS} ${LLVMCONFIG_LIBS} ${LLVMCONFIG_SYSLIBS}" ) # Get proper shared-library behavior (where symbols are not necessarily # resolved when the shared library is linked) on OS X. if(APPLE) set_target_properties(AddObf PROPERTIES LINK_FLAGS "-undefined dynamic_lookup" ) endif(APPLE) #add_dependencies(AddObf intrinsics_gen) # $ clang -Xclang -load -Xclang cmake-build-debug/lib/libAddObf.so cmake-build-debug/app.c -o cmake-build-debug/bin/app
-
编译
-
编译完成后 lib 目录下会生成一个 libAddObf.so,执行如下命令,为 app4 加载它
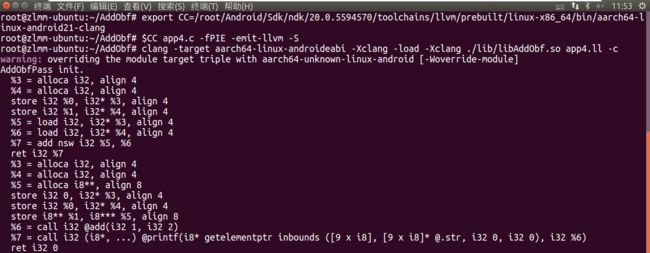
-
接下来对指令处理。以加法指令 add 为例,代码混淆应用了代数中的恒等式交换法则,可实现对加法的指令混淆。以
x+y为例,可被分解为x+y==(x|y)+(x&y),用于实现它的指令混淆代码如下bool runOnFunction(Function &F) override { Function *tmp = &F; for (Function::iterator bb = tmp->begin(); bb != tmp->end(); ++bb) { for (BasicBlock::iterator inst = bb->begin(); inst != bb->end(); ++inst) { if (inst->isBinaryOp()) { if (inst->getOpcode() == Instruction::Add) { return modAddInst1(cast<BinaryOperator>(inst)); } } } } return false; } // x+y == (x|y) + (x&y) bool modAddInst1(BinaryOperator* bo) { BinaryOperator* op = NULL; BinaryOperator* op2 = NULL; if (bo->getOpcode() == Instruction::Add) { // x|y op = BinaryOperator::Create(Instruction::Or, bo->getOperand(0), bo->getOperand(1), "", bo); // x&y op2 = BinaryOperator::Create(Instruction::And, bo->getOperand(0), bo->getOperand(1), "",bo); op = BinaryOperator::Create(Instruction::Add, op, op2, "", bo); op->setHasNoSignedWrap(bo->hasNoSignedWrap()); op->setHasNoUnsignedWrap(bo->hasNoUnsignedWrap()); bo->replaceAllUsesWith(op); } return true; }
-
Instruction 类的 getOpcode() 用于返回当前指令的操作码。对加法指令而言,其操作码为
Instruction::Add。加法指令属于二进制操作 BinaryOperator,包含两个操作数,可用 BinaryOperator 的 getOperand(0) 和 getOperand(1) 分别获取 -
先看看 app4.ll 中 add() 在执行 AddObfPass 操作前的指令

-
输出中只有一条 add 指令
-
应用 AddObfPass 后,add 指令会被 or、and 等多条指令替换
Obfuscator-LLVM
- 这是一款基于 LLVM Pass 实现的开源代码混淆壳,其更新到 3.6.1 后转向商业化,不再提供免费版本
- Obfuscator-LLVM 分为指令替换(Instructions Substitution,IS)、控制流平坦化(Control Flow Flattening,CFF)、伪造控制流(Bogus Control Flow,BCF)
- 环境搭建:《LLVM第二弹—— OLLVM环境搭建、源码分析及使用》(本人用 git clong 的源码编译失败,也不太容易下载,最后在 GitHub 下载 zip 编译成功;虚拟机内存 4 G 的情况下仍内存不足,需要添加临时的交换分区)
指令替换
-
即前述 AddObfPass 使用的技术,原理是基于代数恒等式的替换
-
编译参数:
-mllvm -sub -
实例:xortest.c

-
正常编译生成的代码:
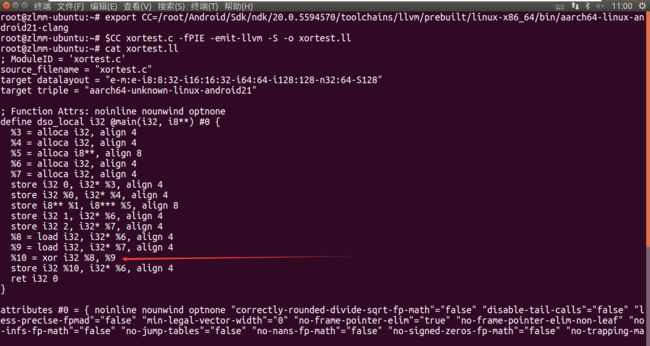
-
使用指令替换编译生成的代码:

-
不加
-emit-llvm -S参数编译生成 xortestsub,使用 IDA 查看: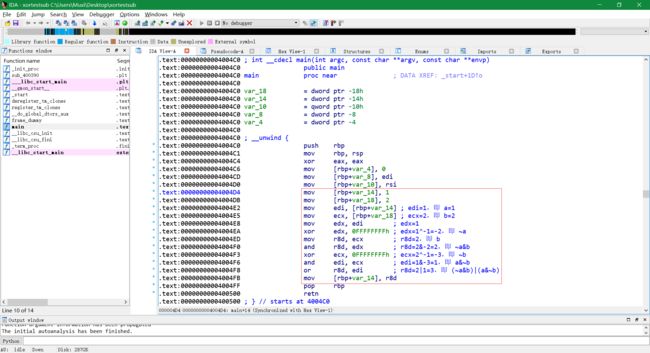
控制流平坦化
-
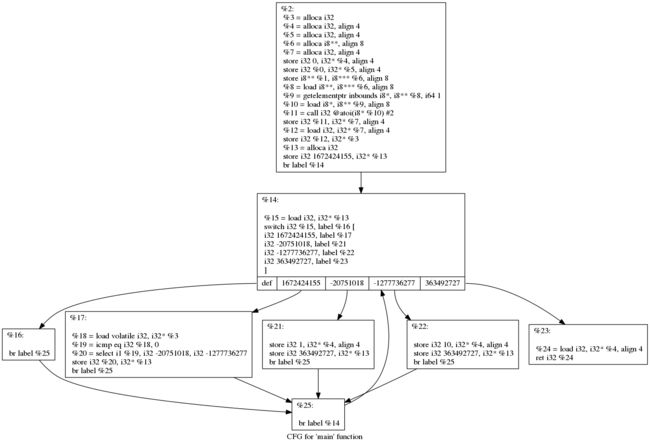
原理是在原始指令中添加分支及垃圾指令,让原来的 CFG 变成由循环分支接管的变形 CFG
-
经过控制流平坦化混淆的 LLVM IR 的 CFG,看似一个头尾较小的陀螺
-
编译参数:
-mllvm -fla -
正常 C 程序的 CFG
-
经过控制流平坦化混淆处理的 CFG
伪造控制流
- 原理:修改 LLVM IR 的函数的基本块,在当前的基本块之前添加一个基本块,添加的基本块包含一个不透明谓词(Opaque Predicate,OP);构造一个条件跳转,以便执行原来的基本块
- 编译参数:
-mllvm -bcf - 对比分析直接编译生成的 LLVM IR 和经过伪造控制流处理的 LLVM IR,可发现:伪造控制流主要通过处理原始 LLVM IR 的 br 等跳转指令,先将真实的指令添加到新增的基本块中,再跳转回原始的基本块执行
代码混淆壳的脱壳
- 代码混淆壳在编译时改写了代码生成的指令,分析和破解此类二进制程序时,与其说脱壳,更像是对原始指令的还原,或对代码混淆的还原
- 针对 Obfuscator-LLVM 的三种混淆方式的分析方法
指令替换混淆的还原
-
实际场景中使用最多的指令替换技术是代数恒等式替换和花指令
-
花指令
- 指在原指令序列中插入一系列无用的垃圾指令,干扰对代码的分析,类似前述不透明谓词
- Obfuscator-LLVM 没使用会干扰分析的花指令,若遇到,最好的分析方法是指令模式匹配和垃圾代码消除
-
指令模式匹配可对付指令替换混淆
-
以加法指令 add 为例
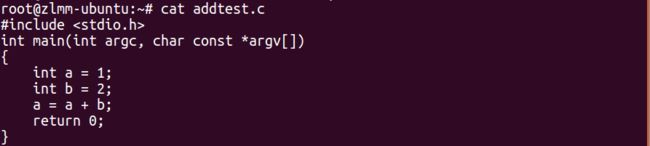
-
正常生成的代码:
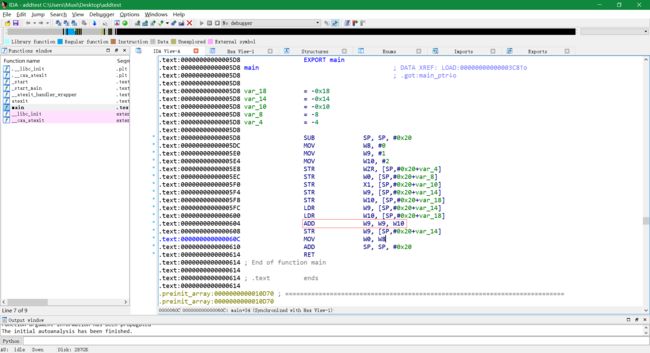
-
启用指令替换后的代码:
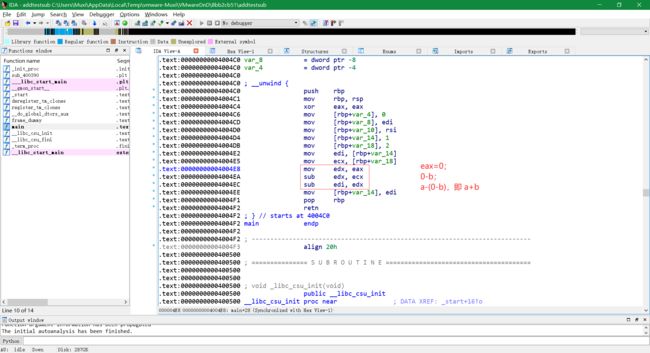
-
指令模式匹配的关键在于识别如下三行:
mov edx, eax sub edx, ecx sub edi, edx
-
在进行模式匹配时可先判断指令序列是否为
mov sub sub,然后判断mov和第一条sub指令操作的结果寄存器是否相同,最后判断第二条sub指令的目标寄存器是否为前一条指令的结果寄存器,若所有判断符合,可将这三条指令nop掉,再用add指令替换 -
基于上述思路,即可对其他指令模式匹配如法炮制
-
指令模式匹配的缺点
- 针对不同平台,要编写不同的匹配策略,工作量相对较大
-
若能在 LLVM IR 级别进行匹配,准确率和匹配效率将大大提高
-
如何根据二进制的机器指令反推出 LLVM IR?dagger 是这一领域的突破
-
对垃圾代码的消除,要结合动态执行的方式进行。这方面有概念性的工具 nao,其原理是执行代码中的指令,通过递归的方式判断执行的指令对寄存器的影响。若指令的运行对上一次执行后的寄存器没有影响,则该指令被视为垃圾指令,将对该指令用
nop填充 -
nao 只实现了基于 x86 指令的模拟,不支持其他平台的指令
控制流平坦化混淆的还原
-
其还原思路和指令替换混淆不同
-
控制流平坦化不改变 LLVM IR 中的指令,而是在原有指令基础上添加循环分析指令,以干扰分析,因此只要正确识别并去除干扰指令,即可达到较好的还原效果
-
用 IDA 对控制流平坦化前后的汇编代码的 CFG 对比
-
进行控制流平坦化之前:
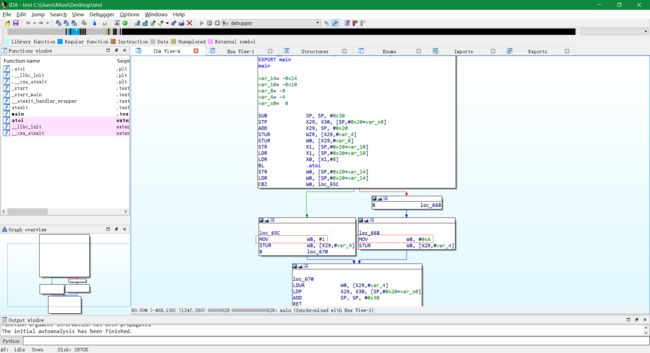
-
进行控制流平坦化之后:
-
用 IDA 查看:
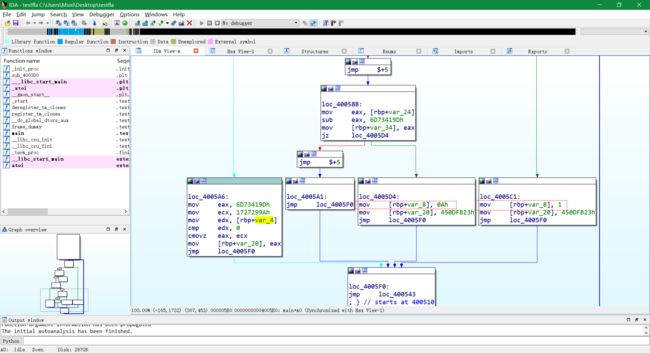
-
进行控制流平坦化后,所有原指令都被安插在循环体中,因此如何正确识别进行控制流平坦化后所有的循环体和循环体间的关系才是还原的关键
-
关于 Obfuscator-LLVM 逆向还原的文章 《Deobfuscation: recovering an OLLVM-protected program》有针对性地分析了经过控制流平坦化地代码地特征,及如何用 miasm 通过动态符号执行技术还原经过控制流平坦化地代码
-
miasm 提供了一个符号执行引擎,其内部从汇编指令级别抽象了 IR、CFG、基本块等与 LLVM 相同的数据结构,并在概念上保持高度一致
-
使用 miasm 还原经过控制流平坦化的代码的思路:
- 生成目标分析函数的 CFG
- 找出 CFG 中的重要基本块
- 序言(prologue)
- 函数的第一个基本块
- 主分发器(main dispatcher)
- 在序言之后第一个执行的基本块
- 负责分发和执行不同的相关块(基本块),是循环体的开始部分
- 预分发器(pre-dispatcher)
- 相关块执行后跳转的目的地址
- 通过该分发器后,只剩一条跳转指令,跳转的目的地址是主分发器
- 返回块(return block)
- 函数的出口
- 该基本块执行后,函数会返回调用处
- 相关块(relevant block)
- 包含真实指令的循环体
- 无用块
- 以上重要基本块之外的基本块
- 序言(prologue)
- 通过执行动态符号来确定相关块间的联系
- 使用跳转指令修正相关块间的联系,nop 掉主分发器与预分发器的代码及所有无用块
- 将内存中修改过的数据写入新的文件,完成反混淆
-
整个流程中最困难的是确定相关块间的联系。在这里,要动态执行函数中所有的分支,覆盖所有执行的可能性,以确定相关块间的调用和被调用关系,因此要修改基本块中出现的分析跳转,并 Hook 所有的外部函数调用
-
相关技术细节可参考《利用符号执行去除控制流平坦化》
伪造控制流混淆的还原
-
和控制流平坦化一样,不会修改原始 CFG 中的指令,因此重点仍是还原 CFG
-
为完整理解伪造控制流对 CFG 的修改,分别编译生成
test.c的正常 LLVM IR 文件test.ll和经过伪造控制流处理的test_bcf.ll,通过对比它们的差异部分找出test_bcf.ll的特点 -
test.c#includeint main(int argc, char const *argv[]) { int a = atoi(argv[1]); if (a == 0) return 1; else return 10; return 0; }
-
编译生成正常的
test.ll:
-
编译生成经过伪造控制流处理的
testbcf.ll:root@zlmm-ubuntu:~# $CCO test.c -emit-llvm -S -mllvm -bcf -o testbcf.ll root@zlmm-ubuntu:~# cat testbcf.ll ; ModuleID = 'test.c' source_filename = "test.c" target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128" target triple = "x86_64-unknown-linux-gnu" @x = common global i32 0 @y = common global i32 0 ; Function Attrs: noinline nounwind uwtable define i32 @main(i32, i8**) #0 { %3 = alloca i32, align 4 %4 = alloca i32, align 4 %5 = alloca i8**, align 8 %6 = alloca i32, align 4 store i32 0, i32* %3, align 4 store i32 %0, i32* %4, align 4 store i8** %1, i8*** %5, align 8 %7 = load i8**, i8*** %5, align 8 %8 = getelementptr inbounds i8*, i8** %7, i64 1 %9 = load i8*, i8** %8, align 8 %10 = call i32 @atoi(i8* %9) #2 store i32 %10, i32* %6, align 4 %11 = load i32, i32* %6, align 4 %12 = icmp eq i32 %11, 0 br i1 %12, label %13, label %14 ; <label>:13: ; preds = %2 store i32 1, i32* %3, align 4 br label %15 ; <label>:14: ; preds = %2 store i32 10, i32* %3, align 4 br label %15 ; <label>:15: ; preds = %14, %13 %16 = load i32, i32* @x %17 = load i32, i32* @y %18 = sub i32 %16, 1 %19 = mul i32 %16, %18 %20 = urem i32 %19, 2 %21 = icmp eq i32 %20, 0 %22 = icmp slt i32 %17, 10 %23 = or i1 %21, %22 br i1 %23, label %24, label %35 ; <label>:24: ; preds = %15, %35 %25 = load i32, i32* %3, align 4 %26 = load i32, i32* @x %27 = load i32, i32* @y %28 = sub i32 %26, 1 %29 = mul i32 %26, %28 %30 = urem i32 %29, 2 %31 = icmp eq i32 %30, 0 %32 = icmp slt i32 %27, 10 %33 = or i1 %31, %32 br i1 %33, label %34, label %35 ; <label>:34: ; preds = %24 ret i32 %25 ; <label>:35: ; preds = %24, %15 %36 = load i32, i32* %3, align 4 br label %24 } ; Function Attrs: nounwind readonly declare i32 @atoi(i8*) #1 attributes #0 = { noinline nounwind uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } attributes #1 = { nounwind readonly "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } attributes #2 = { nounwind readonly } !llvm.ident = !{!0} !0 = !{!"Obfuscator-LLVM clang version 4.0.1 (based on Obfuscator-LLVM 4.0.1)"}
-
经过伪造控制流处理的代码的特点:
testbcf.ll包含test.ll中所有原始指令,只是由于引用的标号个数不同,使用的名称发生了变化- 在插入的基本块中,添加的每一条
br i1 %x, lable %xx, label %yy指令,其标号 xx、yy 代表的是;开头的基本块,且该指令永远只执行前一个 label
-
因此,只要将如下图所示的两处
jnz指令nop,再nop最后一个jump,即可完成对伪造控制流混淆的 CFG 还原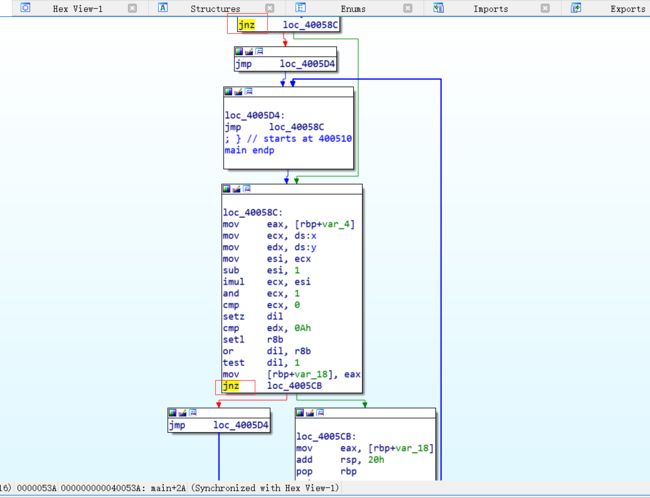
-
按 F5 查看伪代码:
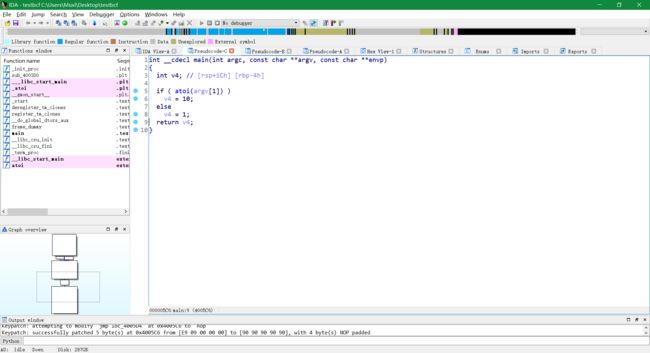
-
未经伪造控制流处理的伪代码:
