python3爬取巨潮资讯网的年报数据
python3爬取巨潮资讯网的年报数据
- 前期准备:
- 需要用到的库:
- 完整代码:
前期准备:
巨潮资讯网有反爬虫机制,所以先打开巨潮资讯网的年报板块,看看有什么解决办法。
巨潮咨询年报板块
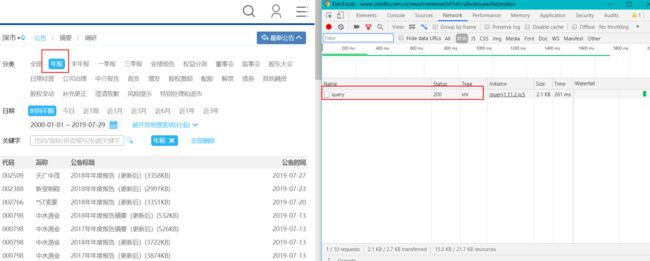
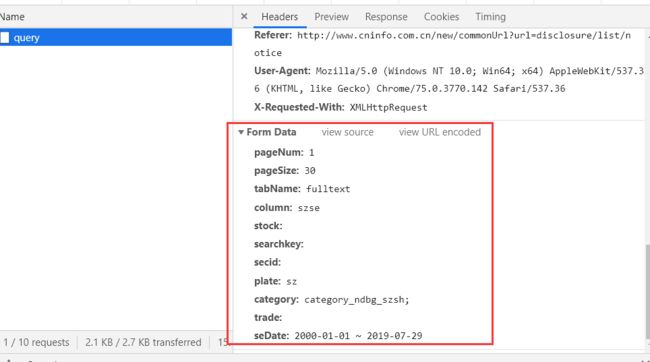
可以通过这样的方式获取单页年报的数据,数据格式为json。其中包括年报名称,地址等数据。
所以思路就是,先通过单页的数据,然后在对每页中的年报数据进行下载。
需要用到的库:
import requests
import random #随机生成爬虫休眠时间
import time
完整代码:
import requests
import random
import time
download_path= 'http://static.cninfo.com.cn/'
saving_path= 'E://2018年报sz'
User_Agent= [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0"
] #User_Agent的集合
headers= {'Accept': 'application/json, text/javascript, */*; q=0.01',
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-HK;q=0.6,zh-TW;q=0.5",
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Referer': 'http://www.cninfo.com.cn/new/commonUrl?url=disclosure/list/notice',
'X-Requested-With': 'XMLHttpRequest'
}
def single_page(page):
query_path= 'http://www.cninfo.com.cn/new/hisAnnouncement/query'
headers['User-Agent']= random.choice(User_Agent) #定义User_Agent
query= {'pageNum': page, #页码
'pageSize': 30,
'tabName': 'fulltext',
'column': 'szse', #深交所
'stock': '',
'searchkey': '',
'secid': '',
'plate': 'sz',
'category': 'category_ndbg_szsh;', #年度报告
'trade': '',
'seDate': '2000-01-01+~+2019-04-26' #时间区间
}
namelist= requests.post(query_path,headers = headers,data = query)
print(page, '*********')
return namelist.json()['announcements'] #json中的年度报告信息
def saving(single_page): #下载年报
headers= {'Accept': 'application/json, text/javascript, */*; q=0.01',
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-HK;q=0.6,zh-TW;q=0.5",
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn'
}
for i in single_page:
if i['announcementTitle']== '2018年年度报告(更新后)' or i['announcementTitle']== '2018年年度报告':
download= download_path+ i["adjunctUrl"]
name= i["secCode"]+ '_' + i['secName']+ '_' + i['announcementTitle']+ '.pdf'
if '*' in name:
name= name.replace('*','')
file_path= saving_path+ '//' + name
time.sleep(random.random()* 2)
headers['User-Agent']= random.choice(User_Agent)
r= requests.get(download,headers = headers)
f= open(file_path, "wb")
f.write(r.content)
f.close()
print(name)
else:
continue
def spy_save(page):
try:
page_data = single_page(page)
except:
print(page,'page error, retrying')
try:
page_data= single_page(page)
except:
print(page,'page error')
saving(page_data )
后续还可以通过使用代理,使用多进程来 提高爬取效率以及减少被反爬虫封禁的可能。