【字符串数据结构后缀系列Part2】后缀自动机学习笔记
由SA到SAM无疑是一个难度极大的跨越.
听说SAM非常厉害可以线性构造SA再也不需要O(nlogn)的倍增构造SA(虽然由于常数速度和O(nlogn)并没有太大区别233)简直太神啦有木有>w<
————————————–线 割 分 是 我 >ω<——————————————–
学SAM需要更多的基础知识QAQ
之前在后缀数组里面已经学过了字符串的基本知识,这次就要学自动机的基本知识=。=
后缀自动机是一个确定有限状态自动机(DFA).
什么是有限状态自动机?
有限状态自动机,用于实现字符串的不同状态之间的转移.有限状态自动机就是说这个自动机可以转移的初始状态和目标状态数目是有限的.转移的双方都在这个自动机的有限的状态集合内.
有限状态自动机包括:
1.确定有限状态自动机(DFA)
2.非确定有限状态自动机(NFA)
3.带ϵ转移的非确定有限状态自动机(ϵ−NFA)
不同的有限状态自动机有不同的转移函数δ
一个确定有限状态自动机包含如下部分:
1.一个非空的状态集合Q
2.一个输入字母表∑(非空且有限)
3.一个转移函数δ
4.一个开始状态q0,q0∈Q
5.一个非空接受状态集合F,F⊆Q
接受状态集合即指所有由初始状态q0能转移到的那些状态.
通常使用一个五元组表示一个DFA—–(Q,∑,δ,q0,F)
DFA上的字符串识别
读入在∑上的字符串后,对字符串中字符逐个进行识别,然后对每一位字符逐个转移到可接受状态,若最终状态属于接受状态集合,则称该串是可接受的,或自动机接受了该串.所有能被自动机A接受的串称为该自动机的”语言”,记作L(A).
看一个图: 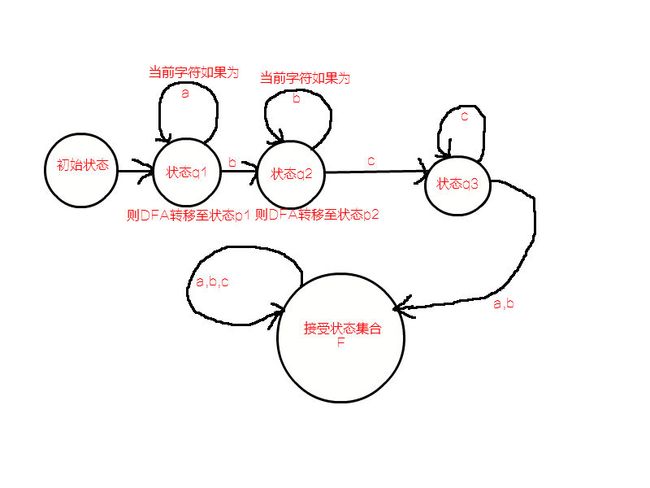
画的不太好看QAQ
这个图代表的自动机能识别的串为”ca…”“cb…”
因为从图中可以看出来只有出现”ca”“cb”串,自动机才有可能转移到接受状态集合,且此后将一直在接收状态集合中转移不会出来.
这样看来,识别时候的复杂度应当是O(len(s))的,但是这是在转移函数实现的效率是O(1)的条件下.综合考虑常数和其他方面,实际上时间大概会大于这个数.
对NFA的识别,我并不想学╮(╯▽╰)╭反正SAM又不是非确定的和主题没关系
后缀自动机SAM
终于到正文了!
字符串S的后缀自动机是一个能识别S的所有后缀的自动机.即当str是S的后缀,SAM(str)=true.后缀自动机的总状态数(节点个数)和转移数(边数)都是O(|S|)的如:
有字符串”suffix”,其后缀自动机是这个样子↓: 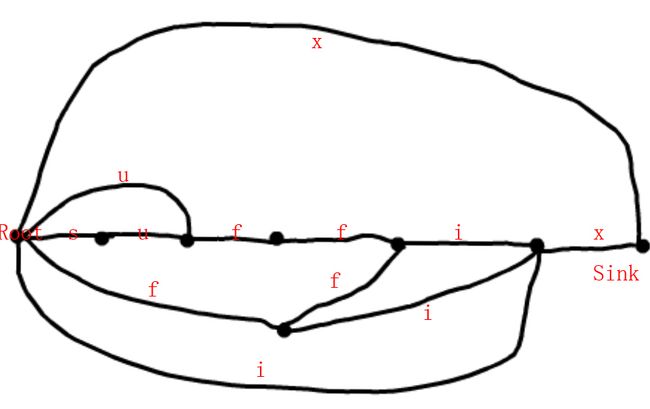
多出来的那些基本算常数拉>_<
不过仔细思考一下发现它并不仅仅能识别后缀,对S的所有子串都是可以识别的.
为什么?
考虑自动机的工作方式,结合上面那个图.假设有随意的子串str,我们可以通过在str后添加一个字符串a的方式构成S的一个后缀.既然后缀自动机是用来识别后缀的,它发现这种”类似后缀”的东西的时候肯定会继续转移下去.而如果不是S的子串,SAM识别到一个字符时就会发现这货绝壁是假的←_←所以就不会继续转移,也就没有办法识别str了.
从上面来看,一个SAM的状态数目貌似是O(|S|2)的了.但是显然不可能是这样…如果是这样的话还要SAM干什么=- =
实际上,SAM的状态数是O(|S|)的.
为什么呢0-0
定义rightstr为子串str在S中每次出现的右端点位置构成的集合
注意到,不同子串在后缀自动机中的状态是有重复的.这种重复出现当且仅当有子串str和子串s1+str,而rightstr=rights1+str.显然,这种情况下我们对这两个串后添加子串所构成的后缀是相同的,故他们在后缀自动机中的状态是相同的.
对这样的字符串,可以在SAM中合并一下状态,从而达到减少时间空间复杂度的目的.
对于两个串a,b如果有righta∩rightb≠∅,显然其中一个串是另一个的后缀.对于一个字符串S的后缀s,显然有rights⊂rightS.对一个字符串而言,它要么是另一个字符串的后缀,要么不是,因此两个字符串的right只可能是不相交或包含的关系.
对自动机中的每个状态a,都找到一个其字典序最小的父状态f[a],满足a是f[a]的一个后缀,则有righta⊂rightf[a].这样SAM中每个状态都有自己的父状态,他们构成一个树形结构,称为Parent树.
后缀自动机的复杂度证明
根据之前的一些定义和基础知识,我们显然可以看出对于初始状态,其right为1-|S|的所有整数,而叶节点的right只有一个元素.从他们的关系我们可以看出,叶节点最多也不过|S|个.也就是说,后缀自动机的状态数是O(|S|)的.
由于SAM的本体形态主要是一个Parent树,因此树上的边最多也就是|S|-1条,看做是O(|S|)的.可是SAM上同样存在一些非树边(因为有重复字符等因素的存在).
这会不会影响SAM的转移数大小呢?并不会0-0
假设一条非树边连接状态u,v.从初始状态到u可以走树边抵达,从u到v走非树边,继续向下行走,可以看出必定会到达一个后缀,然后进入树边.所以非树边的数量必定小于树边,故转移数也是O(|S|)的.
后缀自动机的构造
舍弃SA的倍增,我们转而使用增量法构造SAM.
这时候不得不提一个SAM的巨大优点:SAM支持在线插入字符!
假设之前已有由|S|−1个字符构成的一个字符串,现在要新插入一个字符C使之变成长度为|S|的字符串.
在每次插入一个新字符时,构建新的状态np(new point的意思),设在它之前插入的状态是last,则我们添加一条由last连向np的有向边,即加入一个对应转移.之后添加last的父亲状态的转移,一直扫到一个节点,它已经存在一个字符C的转移.我们假设这个节点的状态为p,经C转移后状态为q.显然,这时集合rightq增加了一个新的元素.多出的元素是一个字符串,右端为字符C,最大长度为len(p)+1.但是问题来了:
1.lenq=lenp+1.显然这时候q所以表示的串的right都相同,直接令fanp=q.
(在下面我一直不太懂,求神犇给个详细点的说明>_<)
2.lenq>lenp+1.这时,q表示的串里长度不超过lenp+1的right都会增加一个元素,其他串则不会,这就导致q状态对应的所有串的right集合不同,因此新建状态nq(注意与np区分开),令nq表示q代表的串中长度不超过lenp+1的串,则显然lennq=lenp+1.对于nq,其fa状态和转移和q一样,因此显然有faq=fanq=nq.因此我们从p开始,不断扫fa.每遇到一个经c转移得到q的节点,就把转移的终点改到nq上,直到遇到一个转移后不是q的节点.
由于采用这种方法,SAM能够支持在线插入字符.
我终于学完SAM了!人生成就get(虽然构造那里还有没看懂的…)!