Oracle 分析函数详解(Analytic Functions)--概念部分
一、概念介绍:
Analytic functions compute an aggregate value based on a group of rows. They differ from aggregate functions in that they return multiple rows for each group. The group of rows is called a window and is defined by the analytic_clause. For each row, a sliding window of rows is defined. The window determines the range of rows used to perform the calculations for the current row. Window sizes can be based on either a physical number of rows or a logical interval such as time.
分析函数基于一组行记录来计算聚合值。不同于聚合函数,分析函数为每一组返回多行记录。这里所谓的组就是分析条件语句(analytic_clause)定义的窗口(window)。窗口决定了用于计算的行范围。窗口大小可以用多个物理行大小或者逻辑区间进行度量例如时间。
Analytic functions are the last set of operations performed in a query except for the final ORDER BY clause. All joins and all WHERE, GROUP BY, and HAVING clauses are completed before the analytic functions are processed. Therefore, analytic functions can appear only in the select list or ORDER BY clause.
分析函数式查询中除需要再最终处理的order by子句之外最后执行的操作。所有连接和where, group by和having子句都在分析函数之前完成。因此,分析函数只能用于选择列或order by子句中。
Analytic functions are commonly used to compute cumulative, moving, centered, and reporting aggregates.
分析函数通常用于计算累积值,数据移动值,中间值和报告聚合值。
二 语法介绍:
![]()

analytic_function
Analytic functions take 0 to 3 arguments. The arguments can be any numeric datatype or any nonnumeric datatype that can be implicitly converted to a numeric datatype. Oracle determines the argument with the highest numeric precedence and implicitly converts the remaining arguments to that datatype. The return type is also that datatype, unless otherwise noted for an individual function.
分析函数可取0-3个参数。参数可以是任何数字类型或是可以隐式转换为数字类型的数据类型。Oracle根据最高数字优先级别确定函数参数,并且隐式地将需要处理的参数转换为数字类型。函数的返回类型也为数字类型,除非此函数另有说明。
analytic_clause
Use OVER analytic_clause to indicate that the function operates on a query result set. That is, it is computed after the FROM, WHERE, GROUP BY, and HAVING clauses. You can specify analytic functions with this clause in the select list or ORDER BY clause. To filter the results of a query based on an analytic function, nest these functions within the parent query, and then filter the results of the nested subquery.
Over Analytic_clause用以指明函数操作的是一个查询结果集。也就是说分析函数是在from,where,group by,和having子句之后才开始进行计算的。因此在选择列或order by子句中可以使用分析函数。为了过滤分析函数计算的查询结果,可以将它作为子查询嵌套在外部查询中,然后在外部查询中过滤其查询结果。
Notes on the analytic_clause: The following notes apply to the analytic_clause:
-
You cannot specify any analytic function in any part of the
analytic_clause. That is, you cannot nest analytic functions. However, you can specify an analytic function in a subquery and compute another analytic function over it. -
You can specify
OVERanalytic_clausewith user-defined analytic functions as well as built-in analytic functions
用户自定义分析函数和内置函数分析函数都可以使用over analytic_clause。参见create function。
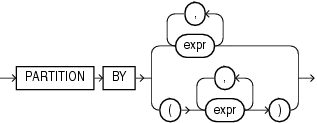
query_partition_clause
Use the PARTITION BY clause to partition the query result set into groups based on one or more value_expr. If you omit this clause, then the function treats all rows of the query result set as a single group.
To use the query_partition_clause in an analytic function, use the upper branch of the syntax (without parentheses). To use this clause in a model query (in the model_column_clauses) or a partitioned outer join (in the outer_join_clause), use the lower branch of the syntax (with parentheses).
You can specify multiple analytic functions in the same query, each with the same or different PARTITION BY keys.
If the objects being queried have the parallel attribute, and if you specify an analytic function with the query_partition_clause, then the function computations are parallelized as well.
Valid values of value_expr are constants, columns, nonanalytic functions, function expressions, or expressions involving any of these.
在分析函数中使用query_partition_clause,应该使用语法图中上分支中的语法(不带圆括号).在model查询(位于model_column_clauses中)或被分隔的外部连接(位于outer_join_clause中)中使用该子句,应该使用语法图中下分支中的语法(带有圆括号)。
在同一查询中可以使用多个分析函数,他们可以有相同或不同的partition key键值。
若查询的对象具有并行特性,并且分析函数中包含query_partition_clause,那么函数的计算也是并行的。
value_expr的有效值包含常量,表列,非分析函数,函数表达式,或者前面这些元素的任意组合表达式。
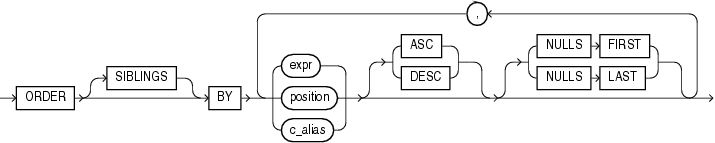
order_by_clause
Use the order_by_clause to specify how data is ordered within a partition. For all analytic functions except PERCENTILE_CONT and PERCENTILE_DISC (which take only a single key), you can order the values in a partition on multiple keys, each defined by a value_expr and each qualified by an ordering sequence.
Within each function, you can specify multiple ordering expressions. Doing so is especially useful when using functions that rank values, because the second expression can resolve ties between identical values for the first expression.
Whenever the order_by_clause results in identical values for multiple rows, the function returns the same result for each of those rows. Please refer to the analytic example for SUM for an illustration of this behavior.
每个键值在value_expr中定义,并且被排序序列限定。
每个函数内可以指定多个排序表达式。当使用函数给值排名时,尤其显得意义非凡,因为第二个表达式能够解决按照第一个表达式排序后仍然存在相同排名的问题。
只要使用order_by_clause后,仍存在值相同的行,则每一行都会返回相同的结果。相关行为的例子请参阅sum分析函数例子。
Restrictions on the ORDER BY Clause The following restrictions apply to the ORDER BY clause:
-
When used in an analytic function, the
order_by_clausemust take an expression (expr). TheSIBLINGSkeyword is not valid (it is relevant only in hierarchical queries). Position (position) and column aliases (c_alias) are also invalid. Otherwise thisorder_by_clauseis the same as that used to order the overall query or subquery. -
An analytic function that uses the
RANGEkeyword can use multiple sort keys in itsORDERBYclause if it specifies either of these two windows:-
RANGEBETWEENUNBOUNDEDPRECEDINGANDCURRENTROW. The short form of this isRANGEUNBOUNDEDPRECEDING. -
RANGEBETWEENCURRENTROWANDUNBOUNDEDFOLLOWING. The short form of this isRANGEUNBOUNDEDFOLLOWING.
Window boundaries other than these two can have only one sort key in the
ORDERBYclause of the analytic function. This restriction does not apply to window boundaries specified by theROWkeyword. -
若窗口范围由range关键字指定的分析函数中指定的不是这2个窗口范围,那么order by子句中仅能使用一个排序键值。若分析函数的窗口由row关键字指定,order by子句中排序键值没有这个限制。
ASC | DESC Specify the ordering sequence (ascending or descending). ASC is the default.
NULLS FIRST | NULLS LAST Specify whether returned rows containing nulls should appear first or last in the ordering sequence.
NULLS LAST is the default for ascending order, and NULLS FIRST is the default for descending order.
Analytic functions always operate on rows in the order specified in the order_by_clause of the function. However, the order_by_clause of the function does not guarantee the order of the result. Use the order_by_clause of the query to guarantee the final result ordering.
nulls first | nulls last 指定若返回行包含空值,该值应该出现在排序序列的开始还是末尾。
升序排序的默认值是nulls last,降序排序的默认值是nulls first。
分析函数总是按order_by_clause对行排序。然而,分析函数中的order_by_clause只对各个分组进行排序,而不能保证查询结果有序。要保证最后的查询结果有序,可以使用查询的order_by_clause。
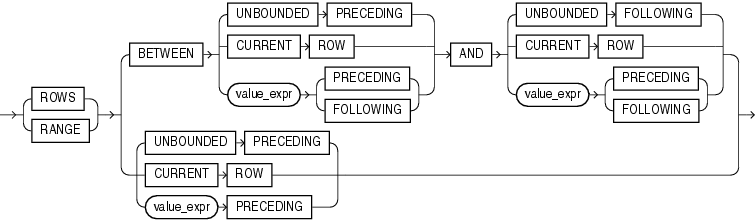
windowing_clause
Some analytic functions allow the windowing_clause. In the listing of analytic functions at the end of this section, the functions that allow the windowing_clauseare followed by an asterisk (*).
ROWS | RANGE These keywords define for each row a window (a physical or logical set of rows) used for calculating the function result. The function is then applied to all the rows in the window. The window moves through the query result set or partition from top to bottom.
-
ROWSspecifies the window in physical units (rows). rows 指定窗口以物理单位(行)构成。 -
RANGEspecifies the window as a logical offset. range 指定窗口以逻辑偏移量构成。
row | range 这些关键字为每一行定义一个窗口,该窗口用于计算函数结果(物理或逻辑的行的集合).然后对窗口中的每一行应用分析函数。窗口在查询结果集或分组中从上至下移动。
You cannot specify this clause unless you have specified the order_by_clause. Some window boundaries defined by the RANGE clause let you specify only one expression in the order_by_clause. Please refer to "Restrictions on the ORDER BY Clause".
The value returned by an analytic function with a logical offset is always deterministic. However, the value returned by an analytic function with a physical offset may produce nondeterministic results unless the ordering expression results in a unique ordering. You may have to specify multiple columns in theorder_by_clause to achieve this unique ordering.
一个带逻辑偏移量的分析函数的返回值总是确定的。然而,除非排序表达式能产生唯一的排序,否则带有物理偏移量的分析函数的返回值可能会产生不确定的结果。为了解决此问题,你可能不得不在order_by_clause中指定多个列以获得唯一的排序。
BETWEEN ... AND Use the BETWEEN ... AND clause to specify a start point and end point for the window. The first expression (before AND) defines the start point and the second expression (after AND) defines the end point.
If you omit BETWEEN and specify only one end point, then Oracle considers it the start point, and the end point defaults to the current row.
UNBOUNDED PRECEDING Specify UNBOUNDED PRECEDING to indicate that the window starts at the first row of the partition. This is the start point specification and cannot be used as an end point specification.
UNBOUNDED FOLLOWING Specify UNBOUNDED FOLLOWING to indicate that the window ends at the last row of the partition. This is the end point specification and cannot be used as a start point specification.
CURRENT ROW As a start point, CURRENT ROW specifies that the window begins at the current row or value (depending on whether you have specified ROW orRANGE, respectively). In this case the end point cannot be value_expr PRECEDING.
As an end point, CURRENT ROW specifies that the window ends at the current row or value (depending on whether you have specified ROW or RANGE, respectively). In this case the start point cannot be value_expr FOLLOWING.
若不使用between而仅指定一个终点,那末oracle认为它是起点,终点默认为当前行。
unbounded preceding 指定unbounded preceding 指明窗口开始于分组的第一行。
它只用于指定起点而不能用于指定终点。
unbounded following 指定unbounded following 指明窗口结束于分组的最后一行。它只用于指定终点而不能用于指定起点。
current row 用作起点,current row 指定窗口开始于当前行或当前值(依赖于是否分别指定row 或range)。在这种情况下终点不能为value_expr preceding。
用作终点,current row 指定窗口结束于当前行或当前值(依赖于是否分别指定row 或range)。这种情况下起点不能为value_expr following。
----------------------
Dylan presents