线程和IO模型的极简知识
缘起
相信绝大部分开发者都知道“设计模式”(英文为Design Patterns)。设计模式很好,让我们在设计和开发软件模块的时候为实现“高内聚,低耦合”等目标提供了强有力的指导。
不过,在我的体会中,设计模式还是更“静态”——它比较关注设计好类、接口、类之间的关系。值得指出的是,设计模式是需要有一定开发经历和经验的人才需要看的。
以我自己为例,我是工作三年后才知道有设计模式得。看完GoF设计模式一书后,理论水平就上升了,以后再看到代码里的Adapter、Factory、Proxy、Observer等词汇就大概知道是什么意思了。
但在我之前和后来的软件开发实践中,我发现还有一类也和程序设计有关的知识比设计模式更加基础和重要。并且,这个知识实际上从每个人第一天coding开始就存在。比如下面这个场景:
- 最开始写个hello world程序,在main函数中直通通得写完,程序运行完就退出。
- 接着,我们要改造这个main,让它能等待并处理用户的输入事件。
- 再过一段时间后,我们在程序里创建多个线程,让耗时的工作能在别的线程去处理,从而不耽误主线程继续接收用户新的输入事件。
从上述的1到2再到3,我们可以明显发现程序的结构在演进。这种演进是追随一种思路或者更直白得讲是有一定套路的,这个套路就是我刚才说除了设计模式之外的另外一种模式方面的知识了——它更倾向于关注程序工作时的“动态”。
有了这方面的知识,不需要设计模式(或者在不太方便使用设计模式的领域,比如用汇编,脚本写个程序),你也能更好得设计出一个运行良好的程序。这个套路中最核心和基础的知识就是本文要介绍的线程和I/O模型。当然,有一套叫《Patterns Of System Architecture》书你可以看,它有5本之多。
接下来我会介绍线程和I/O模型方面的知识。它们看起来非常简单。但我要提醒各位的是,最重要的并不是你记住了这些知识,而要理解模型演化的推动力——其实是靠问题驱动的。没有问题,就无需演化。并且,每种模型都有适用场景,并不是最后的模型就是最合适的模型。
所以,通过这篇文章,你最终要明白 模型演化的历史以及促使它演化的问题和解决办法。
现在网上有很多文章介绍多线程方面的知识,比如Android上的AsyncTask之类的,它们都很好,但如果能了解到整个线程模型的演化历史,我相信你的整体认识会上升一个台阶。
而且,负责任得讲,虽然IT发展飞快,但这些套路几乎没有太多的变化——这也是为何设计模式到今天还很流行的原因。历史是没有答案的未来,未来的知识很可能就在你对历史的回顾中就已经掌握了。
线程和I/O模型极简知识视频
先来看一个视频,这是我用PPT做的,然后保存为mp4。视频只有不到3分钟,但是包含8个部分(视频地址在https://mp.weixin.qq.com/s/qodCngOPXGSaaBy2ULAgqg)。
上面视频里介绍了8个部分,分别是:
- 线程模型:Thread Loop的演化
- 线程模型:生产者/消费者模型
- 线程模型:线程池
- 线程模型:如何让线程池里的线程“动”起来
- I/O模型:发现问题
- I/O模型:解决忙等的问题
- I/O模型:解决一个人忙不过来的问题
- I/O模型:异步I/O
每个部分都很短。各位先看,接下来我会逐个介绍。等大家整体了解了,再回头看这个视频,跟着动画过一遍演化历史及相关问题就行了。
接着来文字+图片来继续讲述我们的故事。
线程——Thread Loop的演化
下面是Thread Loop的演化。请按照图中的数字序号的顺序来看。

我们写了一个程序,其中主线程有一段逻辑,叫Thread Loop①。它的演化是这样的:
- 最开始是所谓的忙等(Busy Wait)②:不断得去检查是不是该做什么事情了。当然,为了减少CPU占用,会使用sleep让自己歇一会。不要瞧不起这个模型,内核里的spin lock就是这样的处理。所以,正如我上面提到的,每种模型都有适用场景。不过,对用户空间的应用来说,这个模型有点low了。
- 接着,Thread Loop进化到等待用户输入③。等待用户输入的时候,CPU就让出来了。而且,只有确实有用户输入的情况才会被唤醒。这个简直不能再棒了。
- 模型③进一步演化。首先演化成等待消息的模型④。显然,所有UI程序都是这么个模型。Android、iOS、Windows上的带界面的应用都这样。
- 好吧,那些没有UI的服务端程序怎么办?这就演化出了模型⑤。在Thread Loop里等待I/O事件。
以上就是线程Thread Loop的演化过程。直到今天,程序架构也脱离不了这些个架构。并且,模型③④⑤在本质上差不多,都是要等待一个事情的发生(无论这个事情是I/O事件,还是消息,还是什么别的玩意)。
线程——生产者和消费者模型
接着来仔细看看上面的模型④,线程需要搭配一个消息队列(Message Queue)。怎么让这个搭配消息队列的线程工作呢?来看下图:
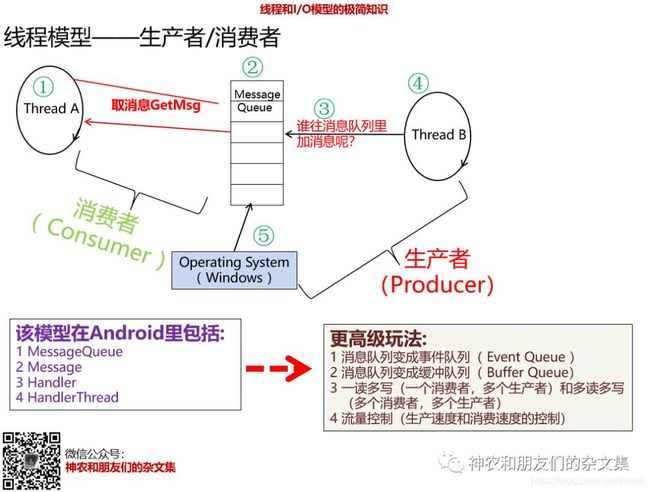
这个图中:
- 线程A从消息队列(Message Queue)里取消息并处理消息(①和②)。
- 那么,谁往消息队列里添加消息呢③?
- 答案有两个:一个是另外一个线程B④(当然,线程A也可以)
- 另外一个是操作系统⑤。比如,Windows上的应用,UI消息是Windows内核发送给应用的。
站在消息队列的角度看,线程A是消息的消费者,而线程B或OS是消息的生产者。这个模型是不是非常简单?
但各位Android同学想想,这么简单的东西,反映在Android里,不就是MessageQueue、Message、Handler和HandlerThread吗(HandlerThread就是线程A+消息队列)。如果知道这个模型,还会在面试的时候被人问倒么.....
上面这个线程模型还能进化出更高级的玩法,比如:
- 消息队列改成事件队列(Event Queue),比如Android里的InputSystem,将触屏事件派发给应用。
- 消息队列变成缓存队列,用于操作I/O。
- 给消息队列加上一些读写控制或流量控制。一读多写,多读多写....
不论哪种高级玩法,最终都是在上面这个模型上附加的操作。
线程池——入门
上面都是单个线程自己玩,现在来看看线程池。
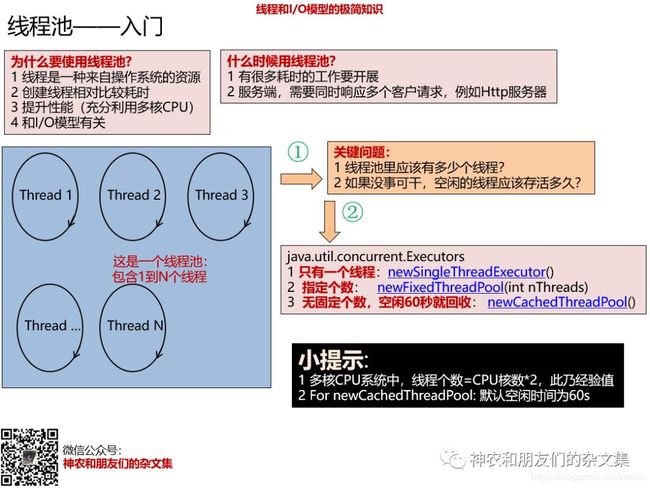
图片里首先解释了为什么要使用线程池“”以及“什么时候使用线程池”。假设你已经确定要用线程池了,那么有两个关键问题需要事先确定好①:
- 线程池里有多少个线程?
- 如果没事可干,空闲线程应该存活多久?
上面两个问题在Java Concurrent库也是替你做好了分类处理:
- newSingleThreadExecutor:创建只有一个线程的线程池。
- newFixedThreadPool:创建有固定个数的线程池。
- newCachedThreadPool:创建无固定个数的线程池,空闲线程60s没事干就回收。
这两个问题很关键,但第一个问题其实很多年前就有了一点参考性得答案。根据大量测试,人们得到了一个经验值——线程个数约等于CPU核数的2倍。这个经验值我不确定在应用开发中是不是也适合,反正是有这么一个说法。
线程池——让线程“动”起来
现在我们有了线程池,事情还没完,还要演化。现在面临的问题是,我有这么多线程,我怎么让它们工作呢?来看下图:
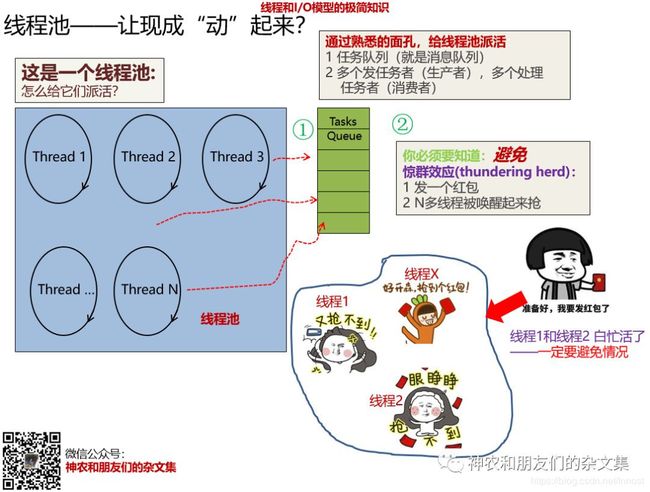
这里再次借助了生产者和消费者模型:
- 针对线程池,我们往往会设置一个Task Queue①(任务队列,其实和上面说的消息队列没什么区别,这些个名词不过是“在什么山头唱什么歌”的忠实拥趸)。根据前面的生产者/消费者模型,如何让线程池里的线程动起来就不用再解释了吧?
- 不过,现在出现了一个新问题。就是僧多粥少的问题②。就是发一个任务,线程池里所有线程都跑来抢,最终肯定只有一个线程能抢到任务,而其它线程白白忙活。这个问题有一个专有名词,叫惊群效应(Thundering herd)。以后可以叫红包抢不到效应——是不是让人很烦恼?
惊群效应是使用线程池一个要重点注意的问题——你值得知道有。
I/O模型——发现问题
到此,和消息队列有关的线程模型演化史告一段落。现在我们看看I/O模型的演化史。

上图中我们以socket I/O为例,因为它是比较典型的I/O操作场景。线程A在自己的Thread Loop里做accept客户连接以及read客户发过来的数据①。这个模型有什么问题呢?有两个非常明显的问题②:
- accept和read默认都是阻塞的(Blocked I/O),即如果没有客户连接,或者客户连接上了没有发送数据,那么调用accept或read的时候就会阻塞。
- 一旦在其中一个函数里阻塞,那么就无法处理其它函数。比如,accept阻塞了,那么就无法read前一个已经连接的客户的数据读取请求。而一旦阻塞在一个客户的read中,那么后面新客户的accept就无法处理。
怎么办?模型演化的推动力就是解决碰到的问题,不要把这个事情想得太难,我们经常是头疼医头脚疼医脚。比如上面两个问题的解法。最开始想到的解决办法是把阻塞改成非阻塞。
上图中,我们把accept和read改成了非阻塞(③),结果又引入了新的问题(④):
- 如果没有新客户的连接,或者没有客户发送数据,那么thread loop就成了忙等。
- 假设有数据要读取,但是速度特别慢,所以read依然会比较耗时。在read读取的时候,我们就没法accept其它客户的连接请求——我称之为一个人忙不过来的问题。
这算是一个馒头引发的血案吗?没有关系,新问题正是模型演化的推动力,我们看看I/O模型演化是如何解决上面两个问题的。
I/O模型——解决忙等
针对阻塞I/O、非阻塞I/O引发的忙等问题,我们发现问题的本质原因其实是在于不知道发生什么事情了。参考前面的Message Queue,如果我们知道发生什么事情了,然后针对这些事情做对应的处理,不就完美了吗?来看下图(序号接上图):

I/O模型演化到此就得到一个里程碑式的模型——I/O多路复用(Multiplexing I/O):
- I/O多路复用和核心本质在于使用了类似Thread+MessageQueue的模型。即等待特定事件发生后才去处理,而不是忙等。
- 然后可以在一个地方等待多个I/O。
和I/O多路复用相关的有select、poll和epoll。这是Linux平台上最为高效的I/O模型了。而且,select、poll、epoll都是一个东西,只不过具体实现上epoll更高效一点而已(可以大胆猜测,select一定是要出现的,然后因为效率问题才演化出了epoll。由于epoll非常完美,所以几十年过去了,epoll还没有出现新的替代者)。
I/O模型——解决一个人忙不过来的问题
忙等问题通过I/O多路复用模型解决了,但是read耗时——也就是一个人忙不过来的问题却解决不了。其实,这个问题其实用刚才说的线程/线程池就能轻松解决。来看下图:

解决一个人忙不过来的问题很简单:
- 最开始为每个连接上的新客户创建一个线程②,在那个线程里去read。原线程可以继续accept。但这种方法很傻很天真,很容易把服务端线程资源耗干。所以,引出了第二个解决办法。
- 第二个解决办法③就是搞个线程池加任务队列来处理客户的read请求。
到此,Linux上I/O模型的演化就告一段落。但演化的推动力还在继续。
I/O模型——异步I/O
上面反复说了,演化的推动力是新问题的出现。I/O多路复用在Linux平台上效率极其优秀,但在Windows平台上,这个模型的效率还是有很大的问题。问题不是出在I/O模型本身上,而是Windows在网络栈里埋了很多Hook,各种Hook,严重影响了I/O效率。
所以,Windows平台上演化了I/O模型的最高级形势——异步I/O,Windows行叫I/O Completion Port(简写为IOCP,中文叫I/O完成端口)。可惜的是,Windows上的IOCP的效率依然不如Linux上的I/O多路复用。
来看看异步I/O模型是什么。

异步I/O模型比较复杂,要用好非常麻烦,但理解并不困难:
- 首先,要有一个内核线程池(以Windows为例),这个线程池里的线程是真正完成I/O操作的①。
- 应用里的线程不再真正去做I/O操作,而是把要做的I/O动作通过xx队列,让内核的I/O线程“动”起来。这涉及到②③。由于应用不再做具体的I/O操作,所以应用就轻松了。
- 站在应用的角度看,I/O操作都交给别人去做了,那么自己唯一要干的事情就是等待I/O完成的消息。这就是图中的④⑤。
以上就是异步I/O模型的核心。我记得很多年前Linux系统是不支持socket使用异步I/O的,现在再看manual socket,发现好像也有对异步I/O支持的蛛丝马迹。不管怎样,异步I/O模型大概就是这个样子。
最后说几点,异步I/O模型比较难理解,代码不好写....。没想清楚这一点的人是幸运的,如果不是强制要用的话就不讨论了。
线程和协程
Kotlin引入了协程的概念。我个人觉得除非像JavaScript、go、dart这种从一开始就没有线程概念的语言可以搞“协程”,Kotlin在明知道Java里是有线程概念的情况下还搞个协程是有点意思了(是好是坏我感觉自己还评价不了....)。
我们来回顾下历史。早期,存在所谓的User Thread——即用户态的线程和所谓的Kernel Thread——kernel线程,真正被kernel用来调度的线程,也就是Java中的Thread、Posix中的Thread。另外,历史上甚至还有一个Light Weight Process(LWP)的概念。

User Thread和Kernel Thread的关系有两种:
- 1-on-1:一个User Thread对应一个Kernel Thread。
- M-on-N:M个User Thread对应N个Kernel Thread。中间有一个Thread管理库来真正维护User Thread和Kernel Thread的关系。这就很像协程的样子了。
早期,不同的线程库(比如Posix线程库)使用了不同的对应关系,有使用1-on-1的,也有使用M-on-N的。大名鼎鼎的POSIX线程库在发展过程中也是从M-on-N到1-on-1。下面是官方霸气回应什么最终会选择1-on-1:

所以,仅从并发、异步操作这个角度来看,协程(包括kotlin、dart、go)其实是又回归到了M-on-N的情况。当然,在现在的软硬件环境下,协程可能会比给开发人员直接暴露OS线程操作API要方便许多。毕竟,线程是一种重要资源,并发逻辑要写好还是有一定难度的。
不过我现在依然觉得既然java早就完美支持线程了,而且还有线程池,还有强大的并发库。Kotlin搞个协程是有点奇怪了。有同学说Kotlin协程能减少线程上下文切换的损耗——讲真:
- 什么时候一个Android应用会把线程上下文切换看做是性能瓶颈了?即使Java后台服务,貌似也不会。
- 非得Kotlin自己搞个线程调度管理模块才能解决这个问题吗?我感觉还不如使用线程池这种模型来得更方便和清爽呢。
最后的最后
- 我期望的结果不是朋友们从我的书、文章、博客后学会了什么知识,干成了什么,而应该是说,神农,我可是踩在你的肩膀上得喔。
- 关于学习方面的问题,我已经讨论完了。后面这个公众号将对一些基础的技术,新技术做一些学习和分享。也欢迎你的投稿。不过,正如我在公众号“联系方式”里说的那样——郑渊洁在童话大王《智齿》里有一句话令我印象深刻,大意是“我有权保持沉默,但你说的每一句话都可能成为我灵感的源泉”。所以,影响不是单向的,很可能我从你那学到的东西更多。
参考链接
- “POSIX Thread Libraries”:https://www.linuxjournal.com/article/3184
- “The Native POSIX Thread Library for Linux”:https://www.cs.utexas.edu/~witchel/372/lectures/POSIX_Linux_Threading.pdf
- “Native POSIX Thread Library 0.1 released":https://lwn.net/Articles/10465/

神农和朋友们的杂文集
长按识别二维码关注我们