Django的前后端分离以及Rest风格接口开发大全
1.什么是前后端分离开发:
就是前后端工程师约定好数据交互接口,并行的进行开发和测试,后端只提供数据,不负责将数据渲染到页面上,前端通过HTTP请求获取数据并负责将数据渲染到页面上,这个工作是交给浏览器中的JavaScript代码来完成。
2.前后端开发的好处:
- 1.提升开发效率
- 2.增强代码的可维护性。
- 3支持多终端和服务化架
3.数据接口:
FBV - 基于函数的视图
CBV - 基于类的视图
FBV 前后端分离源码
- 需要判断请求方式
- 序列化,反序列化难度大
CBV django的前后端分离
- 不需要判断请求方式
- 序列化,反序列化难度大
DRF djangorestframework
- 解决序列化,反序列化问题
FBV+DRF
- 需要判断请求方式
- 序列化,反序列化问题解决
CBV+DRF
- 不需要判断请求方式
- 序列化,反序列化问题解决
FBV源码实现:
前后端分离的开发模式下,后端需要为前端提供数据接口,这些接口通常返回JSON格式的数据。在Django项目中,我们可以先将对象处理成字典,然后就可以利用Django封装的JsonResponse向浏览器返回JSON格式的数据,例如以下例子:
def show_subjects(request):
queryset = Subject.objects.all() #获取所有学科对象
subjects = [] #定义一个空列表
for subject in queryset: #遍历查询学科的到的对象,并把数据处理一个字典保存在subjects列表容器中
subjects.append({
'no': subject.no,
'name': subject.name,
'intro': subject.intro,
'isHot': subject.is_hot
})
return JsonResponse(subjects, safe=False) #利用JsonResponse完成对列表的序列化,返回json格式的数据。由于序列化的是一个列表而不是字典,所以需要指定safe参数的值为False
此时返回的就是Json格式的数据。前端可以通过Ajax来获取。
前端部分代码如下:

概念:基于函数的视图函数。(function base view)
使用结构:
if request.method == 'GET':
pass
if request.method == 'POST':
pass
if request.method == 'DELETE':
pass
if request.method == 'PUT':
pass
if request.method == 'PATCH':
pass
注意:请求方式必须大写
总结:- 需要判断请求方式
- 序列化,反序列化难度大
CBV实现前后端分离:
(1)view
概念:基于类的视图函数。(class base view)
使用步骤:
①继承自系统的类视图
class HelloCBV(View)
②书写请求方式对应的函数, 函数名就是请求方式名字的小写
注意只能小写
方法中的参数必须书写request
③:注册路由 views.类视图.as_view()
url(r'^index/',views.类名.as_view(),name='index')
url(r'^hello/',views.HelloCBV.as_view(),name='hello')
注意:as_view默认情况下没有() 需要手动添加
总结:- 不需要判断请求方式
- 序列化,反序列化难度大
(2)TemplateView
作用:执行类视图然后跳转到指定模板。
TemplateView
继承TemplateView
不需要写get方法 因为TemplateView里重写了get方法
实现方法1
在as_view中书写tempate_name属性
eg:
url(r'^template/', views.HelloTemplateView.as_view(template_name='hello.html'), name='template')
实现方法2
在类视图中指定 template_name='hello.html'
eg:
url(r'^template/', views.HelloTemplateView.as_view(), name='template')
实现原理:
TemplateView继承了TemplateResponseMixin, ContextMixin, View
TemplateView类中定义了get方法,该方法调用了TemplateResponseMixin的render_to_response方法
应用场景:单纯的跳转页面 eg:跳转到登陆页面
(3)ListView
作用:执行类视图然后跳转到指定模板并且传递数据
ListView
属性
template_name
model=模型
queryset=模型.object.all()
必须要写model或者queryset写一个
渲染在模板上
模型_list
object_list
实现原理:
负责跳转页面
ListView继承了MultipleObjectTemplateResponseMixin,
MultipleObjectTemplateResponseMixin继承了TemplateResponseMixin,
在TemplateResponseMixin中有render_to_response方法
负责传递参数
ListView继承了BaseListView,
BaseListView继承了MultipleObjectMixin,
MultipleObjectMixin中有model和queryset的属性和get_queryset方法
应用场景:查询 eg:list 分页
(4)DetailView
作用:执行类视图跳转到指定模板,传递一个数据
DetailView
渲染在模板上
template_name
数据
model
model=Animal
queryset
queryset = Animal.objects.all()
单一实例
pk
url(r'^single/(?P\d+)/', views.HeDetailView.as_view(), name='single')
实现原理:
负责跳转页面
DetailView继承了SingleObjectTemplateResponseMixin,
SingleObjectTemplateResponseMixin继承了TemplateResponseMixin,
TemplateResponseMixin有一个render_to_response方法
负责传递参数
DetailView继承了BaseDetailView,
BaseDetailView继承了SingleObjectMixin,
SingleObjectMixin中有model,queryset,get_queryset方法
应用场景:修改 点击修改的时候 然后传递id参数 获取到对象 在表单中遍历
总结
View适用于前后端分离,方法返回的是json数据 eg:changexxx
TemplateView,ListView, DetailView适用全栈开发,
TemplateView:跳转页面 eg:toLogin
ListView:跳转页面,传递数据 eg:xxxList
DetailView:跳转页面,传递单个数据 eg:loadxxx
4.Rest架构:
REST架构简单介绍参考阮一峰http://www.ruanyifeng.com/blog/2018/10/restful-api-best-practices.html
REpresentational State Transfer —> 表述性状态转移
REST架构两大特点: 无状态和幂等性
HTTP协议请求行 GET / POST / DELETE / PUT / PATCH
新建 —> POST-不需要幂等性
查看 —> GET
更新 —> PUT/PATCH
删除 —> DELETE
1. 实现步骤
(1) 安装restframework
pip install djangorestframework
(2) 修改配置文件setting.py
INSTALLED_APPS = [
'rest_framework',
]
一些 DRF的配置
REST_FRAMEWORK = {
# 配置默认⻚⾯⼤⼩
'PAGE_SIZE': 10,
# 配置默认的分⻚类
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
# 配置异常处理器
# 'EXCEPTION_HANDLER': 'api.exceptions.exception_handler',
# 配置默认解析器
# 'DEFAULT_PARSER_CLASSES': (
# 'rest_framework.parsers.JSONParser',
# 'rest_framework.parsers.FormParser',
# 'rest_framework.parsers.MultiPartParser',
# ),
# 配置默认限流类
# 'DEFAULT_THROTTLE_CLASSES': (),
# 配置默认授权类
# 'DEFAULT_PERMISSION_CLASSES': (
# 'rest_framework.permissions.IsAuthenticated',
# ),
# 配置默认认证类
# 'DEFAULT_AUTHENTICATION_CLASSES': (
# 'rest_framework_jwt.authentication.JSONWebTokenAuthentication',
# ),
}
(3) 新建一个serializers.py编写序列化器
from rest_framework import serializers
from polls.models import Subject, Teacher
class SubjectSimpleSerializer(serializers.ModelSerializer):
class Meta:
model = Subject
# 指定只序列化的属性字段
fields = ('no', 'name')
# -------------------------------------------------------------------------
class SubjectSerializer(serializers.ModelSerializer):
class Meta:
model = Subject
# 指定哪些不序列化的字段
exclude = ('create_data',)
# -------------------------------------------------------------------------
class TeacherSerializer(serializers.ModelSerializer):
sex = serializers.SerializerMethodField()
# 需要单独处理的属性
@staticmethod
def get_sex(teacher):
return '男' if teacher.sex else '女'
class Meta:
model = Teacher
exclude = ('subject',)
(4) 在view.py文件中定义接口并调用自己的序列化器
# 利用rest_framwork序列化模型
# 使用FBV
@api_view(('GET',))
def show_subjects(request):
queryset = Subject.objects.all()
serializer = SubjectSerializer(queryset, many=True) # 多个对象需要定义many = Ture
return Response(serializer.data)
# ============================华丽的分割线==============================
# 使用CBV
class SubjectsViewSet(ModelViewSet):
#定义查询集
queryset = Subject.objects.all()
#序列化查询集
serializer_class = SubjectSerializer
注意:序列化器默认序列化一个对象 会报错 解决方案:在序列化器实例化的时候添加参数many=True
如果报错safe问题 那么需要在JsonResponse中添加参数safe=False
乱码问题:JsonResponse中添加参数json_dumps_params={'ensure_ascii':False}
(5) 在urls.py文件里映射
from common.views import show_subjects,SubjectsViewSet
# FBV
urlpatterns = [
path('subjects/', show_subjects),
]
# CBV注册路由
router = DefaultRouter()
router.register('subjects', SubjectsViewSet)
urlpatterns += router.urls
此时,一个完整的Rest风格的接口就定制成功了。
查询的时候在输入select_related/prefetch_related 1对多/多对多 的方法来解决查询数据库1+N的问题
补充
补充1. 使用三方库进行删选(过滤器filter)
如果需要过滤数据(对数据接⼝设置筛选条件、排序条件等),可以使⽤ django-filter 三⽅库来实
现。
pip install django-filter
(1) 在view.py中定义的试图
class HouseInfoView(ListCreateAPIView, RetrieveUpdateDestroyAPIView):
'''房源展示图集'''
queryset = HouseInfo.objects.all().select_related('type', 'estate')
#导入自定义的序列化器
serializer_class = HouseInfoSerializer
# =========================筛选部分================================
# 继承父类支持筛选(DjangoFilterBackend),排序(OrderingFilter)
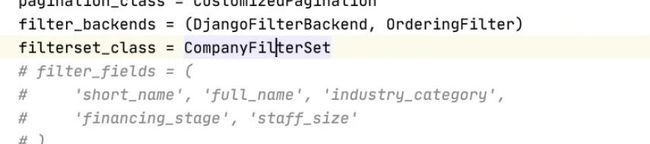
filter_backends = (DjangoFilterBackend, OrderingFilter)
# 自定义方法查询
filter_class = HouseInfoFilterSet # 过滤的字段 ('short_name','full_name','industry_category')
# 按'area', 'price'排序
ordering_fields = ('area', 'price')
(2)在serializers.py中自定义序列化器
class HouseInfoSerializer(serializers.ModelSerializer):
'''房源序列化器'''
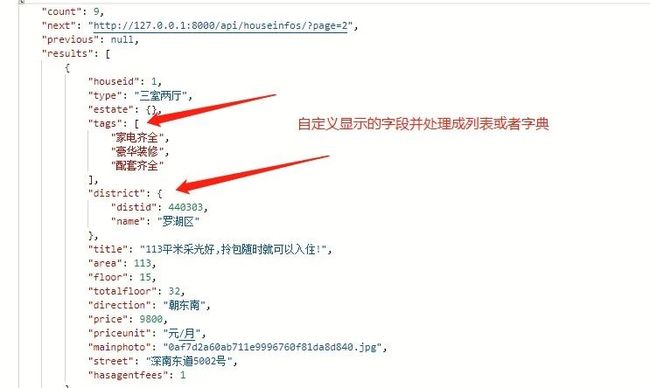
# 都是关联键,需要二次处理的字段,自定义序列化的方法(SerializerMethodField
type = serializers.SerializerMethodField()
estate = serializers.SerializerMethodField()
tags = serializers.SerializerMethodField()
district = serializers.SerializerMethodField()
@staticmethod
def get_type(obj): #obj是上述序列化对象
# return obj.type.name #显示type中的name名称,是一个字段
return obj.type.name
@staticmethod
def get_estate(obj):
# return obj.estate.name #显示estate中的name名称,得到是一个字段,例如“楼盘名称”
'''重写一个序列器,将字段("楼盘")可拓展查询为字典,字典中的字段由新定义的序列器(EstateSimpleSerializer)决定'''
return EstateSimpleSerializer(obj.estate).data
@staticmethod
def get_tags(obj):
'''tag是多对多的关系,因此返回是一个集合,可以用生成器的方式将对象一个个取出来'''
return [tag.content for tag in obj.tags.all()]
@staticmethod
def get_district(obj):
'''distid3无上下关联所以重定义一个district字段根据需要的筛选条件(distid=obj.distid3)查询出来的数据扔进自定义的序列器中(DistrictSimpleSerializer)进行序列化'''
district = District.objects.filter(distid=obj.distid3).only('name').first()
return DistrictSimpleSerializer(district).data
class Meta:
model = HouseInfo
exclude = ('detail','distid3','pubdate','hassubway','isshared','userid','distid2','agent')
=============================自定义查询方法============================
# 引入搜索引擎 Whoosh +jieba(小型) -----> 倒排索引
# 中科院研发的搜索引擎对中文适配度很高ElasticSearch / Solr + 中文分词插件ik-analysis/smartcn/pinyin支持数据量大,并发高的查询支持
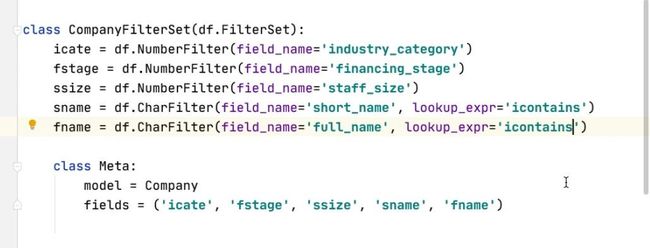
class HouseInfoFilterSet(django_filters.FilterSet):
"""自定义房源信息模糊查询"""
# title字段模糊查询,contacts/startwith/endswith性能很差,建议搞个搜索引擎
title = django_filters.CharFilter(lookup_expr='contains')
minprice = django_filters.NumberFilter(field_name='price')
maxprice = django_filters.NumberFilter(field_name='price')
#自定义关键字查询方法
keyword = django_filters.CharFilter(method='filter_by_keyword')
# 自定义查询方法
@staticmethod #若不是静态方法,第一个参数是self
def filter_by_keyword(queryset, key, value):
queryset = queryset.filter(Q(title__contains=value) |
Q(detail__startswith=value))
return queryset
自定义过滤类,自定义设置模糊查询,字段查询的操作
补充2. 身份认证 —> JWT - Json Web Token 生成用户令牌
用户跟踪
- URL重写(在url中通过查询参数向服务器传递相关数据)
2.隐藏表单域(隐藏域、埋点)
3.浏览器本地存储
~cookie
~localStorage / sessionStorage
传统的用户跟踪是把数据放在服务器上称为session的队象中
session对象的ID被保存在cookie中,下一次请求带上cookie,
服务器从cookie中获取sessionid,找到对应的session对象
现在的做法:用户登录成功,服务器签发身份令牌,浏览器保存身份令牌
每次请求带上身份,服务器根据身份令牌识别用户
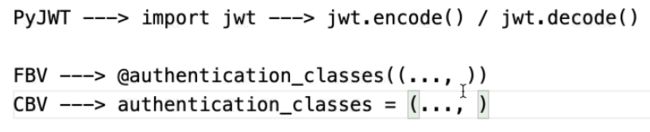
JWT ----> Web 应用中为用户生成(签发)身份令牌的一种方式
-----> 一种可以防伪造防篡改的令牌生成方式
JWT 的原理是,服务器认证以后,生成一个 JSON 对象,发回给用户。以后,用户与服务端通信的时候,都要发回这个 JSON 对象。服务器完全只靠这个对象认定用户身份
对于什么是JWT?可以先行参考http://www.ruanyifeng.com/blog/2018/07/json_web_token-tutorial.html
优点: JWT无法伪造、也无法篡改令牌中包含的用户信息
保存在用户浏览器端,服务器没有任何储存开销,便于水平扩展

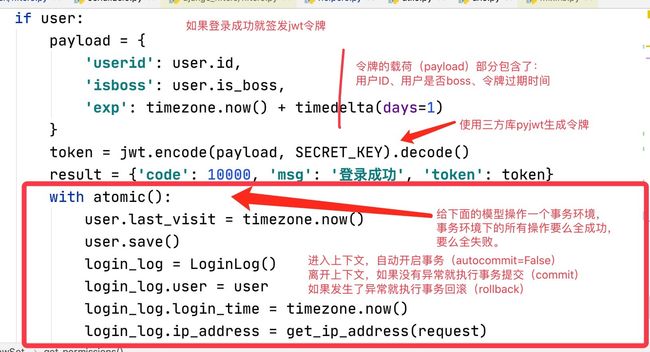
(1)在view.py中登录的逻辑代码中若存在用户则生成token
@api_view(('GET', 'POST'))
# @atomic() # 开启ORM的事务,太局限,显得很粗暴
def login(request):
username = request.data.get('username')
password = request.data.get('password')
if username and password:
password = make_sha256_digest(password)
user = User.objects.filter(username=username, password=password, is_locked=False).only('is_boss').first()
if user:
#------------------#---------------------#--------------------
payload = {
'userid': user.id,
'is_boss': user.is_boss,
# 过期时间
# 当前时间加上seconds=20秒days=1
'exp': timezone.now() + timedelta(days=1)
} # 定义要传递的数据
token = pyjwt.encode(payload, SECRET_KEY).decode()
result = {'code', 10000, 'msg', '登录成功', 'token', token}
#----------------#---------------------#---------------------#
with atomic(): # 生成登录日志,事务操作
user.last_visit = timezone.now()
login_log = LoginLog()
login_log.user = user
login_log.login_time = timezone.now()
login_log.ip_address = get_ip_address(request)
login_log.save()
else:
result = {'code', 10001, 'msg', '请输入有效的用户名和密码'}
else:
result = {'code', 10002, 'msg', '请输入有效的用户名和密码'}
return Response(result)
(2)在需要认证才能调用的接口上定义
class CompanyViewSet(ModelViewSet):
queryset = Company.objects.all() \
.select_related('industry_category') \
.defer('full_name', 'start_work_time', 'end_work_time',
'overtime_work', 'day_off', 'welfares', 'editor') \
.order_by('id')
serializer_class = CompanySimpleSerializer
# 认证类(登录才能调用)自定义类LoginRequiredAuthentication
authentication_classes = (LoginRequiredAuthentication,)
(3) 自定义需要认证的类
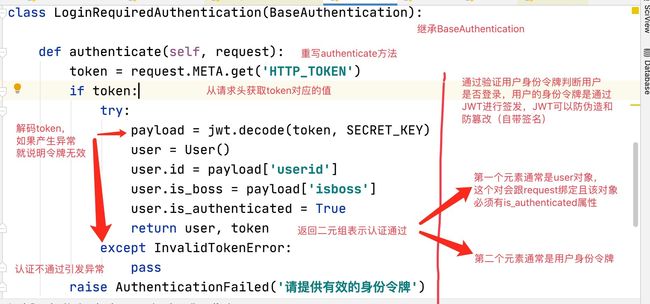
~~~ 通过验证用户身份令牌判断是否登录,用户的身份令牌是通过JWT进行签发,JWT可以防伪造和防篡改(自带签名)
from jwt import InvalidTokenError
from rest_framework.authentication import BaseAuthentication
from rest_framework.exceptions import AuthenticationFailed
class LoginRequiredAuthentication(BaseAuthentication):
'''登录请求认证'''
def authenticate(self, request): # 重写authenticate方法
'''重写认证方法'''
# 获取请求头的数据,后面均要 HTTP_需要获取的字段(全大写)
token = request.META.get('HTTP_TOKEN')
if token:
try:
payload = jwt.decode(token, SECRET_KEY)
user = User()
user.id = payload['userid']
user.is_boss = payload['is_boss']
# django2以上版本必须定义is_authenticated属性
user.is_authenticated = True
# 返回任意二元组,建议返回以下二元组,方便调用user使用里面的user.id
return user, token
except InvalidTokenError:
pass
raise AuthenticationFailed('请提供有效身份令牌')
这样一来CompanyViewSet这个数据接口只有有效用户带着指定的token才可以访问。
- 那么假如有些接口只有指定的人可以访问/修改/删除,或者某一字段为Ture的用户才可以经行操作,那么如何实现?
原理:在token中带上指定字段,自定义授权类进行验证,在接口函数中定义permission_classes = (xxxxx,)
例如只有is_boss = Ture 才能执行PUT/Delete/操作:
(1) token设置如上,然后在接口中定义
class CompanyViewSet(ModelViewSet):
queryset = Company.objects.all() \
.select_related('industry_category') \
.defer('full_name', 'start_work_time', 'end_work_time',
'overtime_work', 'day_off', 'welfares', 'editor') \
.order_by('id')
serializer_class = CompanySimpleSerializer
# 认证类(登录才能调用)自定义类LoginRequiredAuthentication
authentication_classes = (LoginRequiredAuthentication,)
def get_permissions(self):
if self.request.method == 'GET':
return ()
return (BossPermission,)
授予权限
权限检查总是在视图的最开始处运⾏,在任何其他代码被允许进⾏之前。最简单的权限是允许通过身份
验证的⽤户访问,并拒绝未经身份验证的⽤户访问,这对应于dfr中的 IsAuthenticated 类,可以⽤它
来取代默认的 AllowAny 类。权限策略可以在Django的DRF配置中⽤ DEFAULT_PERMISSION_CLASSES 全局设置。
REST_FRAMEWORK = {
'DEFAULT_PERMISSION_CLASSES': (
'rest_framework.permissions.IsAuthenticated',
)
}
(2) 自定义授权类,可以在基于 APIView 类的视图上设置身份验证策略
⾃定义权限需要继承 BasePermission 并实现以下⽅法中的⼀个或两个,下⾯是BasePermission的代
码。
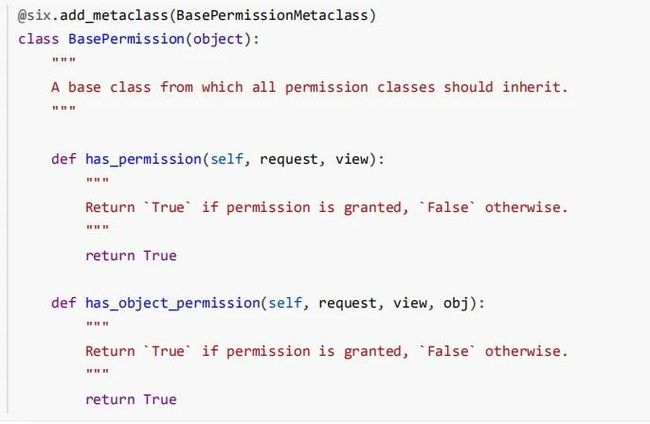
from rest_framework.permissions import BasePermission
from django.contrib.auth.models import AnonymousUser
class BossPermission(BasePermission):# 权限类都要继承的基类
'''授权类'''
# 是否有权限
@staticmethod
def has_permission(request, view): # 重写has_permission方法,返回Ture表示有权限
if isinstance(request.user,AnonymousUser): # 如果认证没过,没有得到返回的二元组,request.user就是Django框架自带的AnonymousUser,匿名用户
return False
return request.user.is_boss
或者在基于 @api_view 装饰器的视图函数上设置
from rest_framework.decorators import api_view, permission_classes
from rest_framework.permissions import IsAuthenticated
@api_view(['GET'])
@permission_classes((IsAuthenticated, ))
def example_view(request, format=None):
# 此处省略其他代码
1234567
此时,只有is_boss = Ture 才能对对应得数据接口进行操作
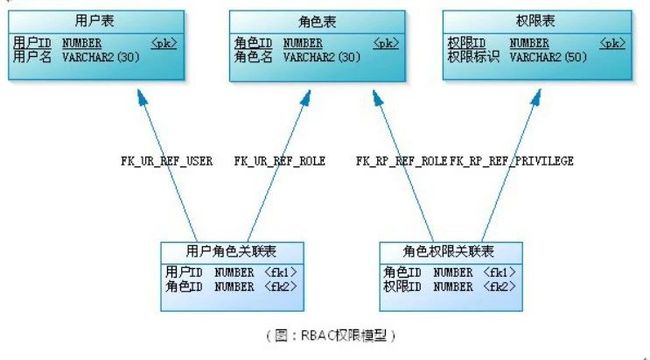
如果要实现更为完整的权限验证,可以考虑RBAC或ACL
- RBAC - 基于⻆⾊的访问控制,如下图所示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xXO2wwgD-1591964777119)(C:\Users\ANemo\AppData\Roaming\Typora\typora-user-images\image-20200611123054797.png)]
- ACL - 访问控制列表(每个⽤户绑定⾃⼰的访问⽩名单或⿊名单)。
补充3. 中间件定制IP黑名单
(1)在应用下创建middlewares.py,自定义中间件(本质上是装饰器)
from django.http import HttpResponse
from django_redis import get_redis_connection
from common.utils import get_ip_address
# 设置黑名单,禁止黑名单里的IP访问
def black_list_middleware(get_resp):
def middleware(request,*args,**kwargs):
ip = get_ip_address(request) # 获取访问的IP,代码见下方
# 在IP集合里的名单则无法访问
redis_cli = get_redis_connection() # 连接redis
if redis_cli.sismember('bosszhipin:common:middlewares:black_list',ip):
resp = HttpResponse(status=403)
else:
resp = get_resp(request,*args,**kwargs)
return resp
return middleware
也可以使用以下方式创建中间件

(2)在setting.py 里注册中间件
MIDDLEWARE = [
'common.middlewares.black_list_middleware', # 自定义的中间间件
'debug_toolbar.middleware.DebugToolbarMiddleware',
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
补充; 获取IP地址的正确代码
def get_ip_address(request):
"""获得请求的IP地址"""
ip = request.META.get('HTTP_X_FORWARDED_FOR', None)
return ip or request.META['REMOTE_ADDR']
注意: 中间件有依赖关系,如下图

关于各种状态码的原因
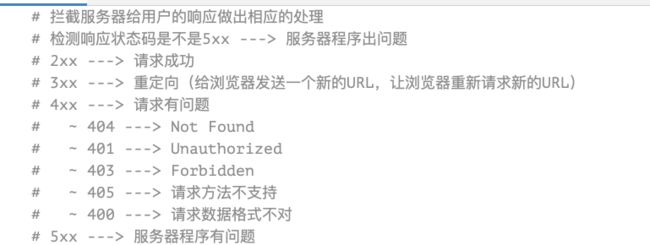
补充4. REST_FRAMEWORK实现接口限流
原理: 在缓存(Redis)内记录IP地址,并记录访问次数,当请求超过阈值则限制访问
(1)配置文件,打开settings.py
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.AnonRateThrottle',
'rest_framework.throttling.UserRateThrottle'
),
'DEFAULT_THROTTLE_RATES': {
'anon': '5/min', # 匿名用户限流频率
'user': '50/min' # 登录用户限流频率
}
}
若不想限流,可以在视图类里面加入以下代码:
throttle_classes = ()
补充5.DRF中的分页
1. PageNumberPagination ---> 按页码分页
2. LimitoffsetPagination ---> 跳过N条,查第N+1条
3. CursorPagination --->游标进行分页
(1)全局分页。在setting.py中配置一下内容(商业项目中不推荐使用,可能会暴露服务器规模)
# DRF配置文件
REST_FRAMEWORK = {
# 按页码分页
'DEFAULT_PAGINATION_CLASS':'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 5,
}
# 若单个视图类不想分页可以加以下代码:
pagination_class = None
(2)自定义分页(不能使用缓存,应无法准确获取上下文信息)
# 定义游标分页类
class EstatePagination(CursorPagination):
page_size_query_param = 'size' # 自定义单页显示记录数
max_page_size = 20 # 单页最多记录数
ordering = 'estateid' # 按楼盘id分页
# 在视图类里面调用
pagination_class = EstatePagination
补充6. 手机二维码扫码登录的问题
原理:服务器生成一个唯一标识码,手机扫码获取将唯一标识符和token发送给服务器进行验证

(1) 安装三方库
pip install qrcode
(2) 定义工具函数,生成二维码
from io import BytesIO
def gen_qrcode(data):
"""生成二维码"""
qrcode_image = qrcode.make(data)
buffer = io.BytesIO()
qrcode_image.save(buffer)
return buffer.getvalue()
(3) 在view.py中进行调用,这里生成一个uuid 生成二维码
from django_redis import get_redis_connection
import uuid
def show_qrcode(request):
'''展示二维码'''
uuid_string = uuid.uuid1().hex #
print(uuid_string)
redis_cli = get_redis_connection() # 调用redis连接保存
redis_cli.set('bosszhipin:qrcode:' + uuid_string, '', ex=30)
data = gen_qrcode(uuid_string)
return HttpResponse(data, content_type='image/png')
补充7. 实现上传文件(图片)的功能
(1) 上传到本地(内存中),基于前后端分离开发。
@api_view(('POST', ))
def upload(request):
file_obj = request.FILES.get('photo') # 获取上传的图片
file_name = make_md5_digest(file_obj.file) # 将文件生成一个唯一的哈希摘要,作为文件名避免重复上传,消耗服务器资源。生成摘要代码见下
file_ext = os.path.splitext(file_obj.name)[1] # 调用os.path中拆分路径的方法获取尾部作为后缀
full_name = f'{file_name}{file_ext}' # 将文件名和后缀组合成全名
filepath = os.path.join(BASE_DIR, f'static/images/{full_name}') #定义保存的位置
if not os.path.exists(filepath):
with open(filepath, 'wb') as file: # 写入文件(二进制)
file.write(file_obj.file.getvalue())
return Response({'code': 30000, 'msg': '上传成功', 'url': f'/static/images/{full_name}'})
为避免格式错误,定义了一个方法将写入的东西都转化为字节流返回。生成摘要的代码为:
def _force_bytes(data):
if type(data) != bytes:
if type(data) == str:
data = data.encode()
elif type(data) == io.BytesIO:
data = data.getvalue()
else:
data = bytes(data)
return data
def make_sha256_digest(data):
"""生成SHA256摘要"""
data = _force_bytes(data)
return hashlib.sha256(data).hexdigest()
前端可用form表单实现或者异步实现:
# 用form表单实现
<form action="/upload/" method="post" enctype="multipart/form-data">
<input type="file" name="photo">
<input type="submit" value="确定">
form>
# 异步实现
<div>
<input type="file" name="photo">
<button id="okBtn">确定button>
<img id="preview" src="" alt="" width="120">
div>
<script>
let okBtn = document.querySelector('#okBtn')
console.log(okBtn)
okBtn.addEventListener('click', (evt) => {
let fileInput = document.querySelector('input[name=photo]')
let formData = new FormData()
//formData.append('username', 'hellokitty')
formData.append('photo', fileInput.files[0])
fetch('/upload/',{
method: 'POST',
body: formData
}).then(resp => resp.json()).then(json => {
alert(json.msg)
fileInput.value = ''
# 将上传的图片进行预展示
document.querySelector('#preview').src = json.url
})
})
(2)很多时候,我们上传的图片很大很多,为了降低服务器的损耗和给用户更快的体验,我们一般选择第三方服务器,例如七牛云,阿里云的oss2,亚马逊的s3…
调用三方服务:
-
S3 - Simple Storage Service
-
OSS2 - Object Storage Service
- API调用 - HTTP请求 - 三方数据接口#
- SDK集成 - 安装三方库 - 调用函数方法
以下实现方式使用七牛云SDK集成进行试验
详细内容参考官方文档
-
安装七牛云三方库
pip install qiniu -
编写qiniu.py,定义上传函数逻辑
from concurrent.futures.thread import ThreadPoolExecutor import qiniu # 注册成功七牛云,会返回一个AK/Sk密钥 QINIU_ACCESS_KEY = 'gtAVvjfndlbZL72cnfX9fiS4p3IEB65dS' QINIU_SECRET_KEY = 'ORjPSniRANHKcLRrXA_GEz9743hn83nhQ' QINIU_BUCKET_NAME = 'yangjin' #自定义存储空间 AUTH = qiniu.Auth(QINIU_ACCESS_KEY, QINIU_SECRET_KEY) # 返回图片的唯一标识码和文件名称 def upload_file_to_qiniu(file_path, filename): """将本地(内存)文件上传到七牛云存储""" token = AUTH.upload_token(QINIU_BUCKET_NAME, filename) result, *_ = qiniu.put_file(token, filename, file_path) return result def upload_stream_to_qiniu(file_stream, filename, size): """将图片以数据流上传到七牛云存储""" token = AUTH.upload_token(QINIU_BUCKET_NAME, filename) result, *_ = qiniu.put_stream(token, filename, file_stream, None, size) return result # 生成都 POOL = ThreadPoolExecutor(max_workers=32) # upload_file_to_qiniu('./123.jpg', '123.jpg') -
在view.py中进行调用,这里假设指定2.5M以下的图片进行上传,根据实际进行更改
MAX_PHOTO_SIZE = 2.5 * 1024 * 1024 #2.5M大小 def upload1(request): file_obj = request.FILES.get('photo') if file_obj and len(file_obj) < MAX_PHOTO_SIZE: file_name = make_md5_digest(file_obj.file) file_ext = os.path.splitext(file_obj.name)[1] full_name = f'{file_name}{file_ext}' upload_stream_to_qiniu(file_obj.file,full_name,len(file_obj)) return Response({'code': 30000, 'msg': '文件已上传', 'url': f'http://qbp0btwfq.bkt.clouddn.com/{full_name}'}) else: return Response({'code': 30001, 'msg': '文件大小超过2.5M'}) -
为了解决高并发并且给用户更好的体验,我们一般将上传图片的任务交给线程来进行,所以将以上代码修改为:
@api_view(('POST', )) def upload2(request): file_obj = request.FILES.get('photo') if file_obj and len(file_obj) < MAX_PHOTO_SIZE: file_name = make_md5_digest(file_obj.file) file_ext = os.path.splitext(file_obj.name)[1] full_name = f'{file_name}{file_ext}' # 扔到线程池里(POOL在qiniu.py里定义) POOL.submit(upload_stream_to_qiniu, BytesIO(file_obj.file.getvalue()), full_name, len(file_obj)) return Response({'code': 30000, 'msg': '文件已上传', 'url': f'http://qboymizkv.bkt.clouddn.com/{full_name}'}) else: return Response({'code': 30001, 'msg': '文件大小超过2.5M'}
补充8:利用DRF配置缓存
添加缓存也有两种方式(继承父类CacheResponseMixin,加类装饰器)
准备:
-
依赖项drf-extensions==0.5.0 为DRF提供缓存扩展
-
1)修改配置文件setting.py
# 缓存混入类 REST_FRAMEWORK_EXTENSIONS = { 'DEFAULT_CACHE_RESPONSE_TIMEOUT': 120, 'DEFAULT_USE_CACHE': 'default', 'DEFAULT_OBJECT_CACHE_KEY_FUNC': 'rest_framework_extensions.utils.default_object_cache_key_func', 'DEFAULT_LIST_CACHE_KEY_FUNC': 'rest_framework_extensions.utils.default_list_cache_key_func', }2)django里的装饰器@method_decorator可以将装饰函数的装饰器变成可以装饰类方法的装饰器
# 让视图类继承混入类: class EstatesView(CacheResponseMixin): # 带Mixin的类是混入类,混入类必须写在前面 class EstateView(CacheResponseMixin, ListCreateAPIView, RetrieveUpdateDestroyAPIView): queryset = Estate.objects.all().defer('agents') filter_backends = (DjangoFilterBackend, OrderingFilter) filter_class = EstateFilterSet @method_decorator(decorator=cache_page(500), name='list') @method_decorator(decorator=cache_page(120), name='retrieve') class HouseTypeViewSet(ModelViewSet): queryset = HouseType.objects.all() serializer_class = HouseTypeSerializer # 拒绝分页 pagination_class = None
补充9:如何解决跨域请求数据问题
CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。
它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
(1)安装第三方库
pip install django-cors-headers
(2) 在seeting.py中添加应用
INSTALLED_APPS = [
'django_filters',
]
(3)添加中间件
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware',
]
(3) 配置
# 设置允许所有网站跨域请求
CORS_ORGIN_ALLOW_ALL=True
# 配置跨域白名单
# CORS_ORIGIN_WHITELIST = ('www.abc.com','www.baidu.com')
# CORS_ORIGIN_REGEX_WHITELIST = ('.....')
# CORS_ALLOW_CREDENTIALS = True
# CORS_ALLOW-METHODS = ('GET','POST','PUT','DELETE')
详细了解跨域请求内容请参考阮老师文章http://www.ruanyifeng.com/blog/2016/04/cors.html
补充10:线上的一些命令
-
- 克隆项目
- git clone --depth=1 [email protected]:jackfrued/carsys3.git carsys
- cd carsys
-
- 创建虚拟环境
- 方法一:python3 -m venv venv
-
方法二:
whereis python3
pip3 install virtualenv
virtualenv --python=/usr/bin/python3 venv
-
- 激活虚拟环境安装依赖项
- source venv/bin/activate
- pip install -U pip
- pip install -r requirements.txt
- 补充说明:如果安装依赖项报错,可能是因为确实了底层库文件,可以用yum补包
- 查找:yum search
- 安装:yum install
- 卸载:yum erase / yum remove
- 更新:yum update
- 信息:yum info
- 列出已经安装:yum list installed | grep
-
- 运行FastAPI项目
-
查看本机IP地址:
- ifconfig eth0
- ip addr
- uvicorn --host 0.0.0.0 api.main:app
请求数据的几个小工具
git bash 中的curl 和httpie 加数据接口地址
这篇文章主要是用来给自己查阅笔记之用,有不对之处欢迎投稿指正。