JDK中多线程之JUC集合的JDK源码解读配合大神的一起看,秒懂。
一、 “JUC集合”01之框架
1) 概要
之前,在"Java 集合系列目录(Category)"中,讲解了Java集合包中的各个类。接下来,将展开对JUC包中的集合进行学习。在学习之前,先温习一下"Java集合包"。本章内容包括:
Java集合包
JUC中的集合类
2) Java集合包
在“Java 集合系列01之 总体框架”中,介绍java集合的架构。主体内容包括Collection集合和Map类;而Collection集合又可以划分为List(队列)和Set(集合)。
1. List的实现类主要有: LinkedList, ArrayList, Vector, Stack。
(01) LinkedList是双向链表实现的双端队列;它不是线程安全的,只适用于单线程。
(02) ArrayList是数组实现的队列,它是一个动态数组;它也不是线程安全的,只适用于单线程。
(03) Vector是数组实现的矢量队列,它也一个动态数组;不过和ArrayList不同的是,Vector是线程安全的,它支持并发。
(04) Stack是Vector实现的栈;和Vector一样,它也是线程安全的。
2. Set的实现类主要有: HastSet和TreeSet。
(01) HashSet是一个没有重复元素的集合,它通过HashMap实现的;HashSet不是线程安全的,只适用于单线程。
(02) TreeSet也是一个没有重复元素的集合,不过和HashSet不同的是,TreeSet中的元素是有序的;它是通过TreeMap实现的;TreeSet也不是线程安全的,只适用于单线程。
3.Map的实现类主要有: HashMap,WeakHashMap,Hashtable和TreeMap。
(01) HashMap是存储“键-值对”的哈希表;它不是线程安全的,只适用于单线程。
(02) WeakHashMap是也是哈希表;和HashMap不同的是,HashMap的“键”是强引用类型,而WeakHashMap的“键”是弱引用类型,也就是说当WeakHashMap 中的某个键不再正常使用时,会被从WeakHashMap中被自动移除。WeakHashMap也不是线程安全的,只适用于单线程。
(03) Hashtable也是哈希表;和HashMap不同的是,Hashtable是线程安全的,支持并发。
(04) TreeMap也是哈希表,不过TreeMap中的“键-值对”是有序的,它是通过R-B Tree(红黑树)实现的;TreeMap不是线程安全的,只适用于单线程。
更多关于这些集合类的介绍,可以参考“Java 集合系列目录(Category)”。
为了方便,我们将前面介绍集合类统称为”java集合包“。java集合包大多是“非线程安全的”,虽然可以通过Collections工具类中的方法获取java集合包对应的同步类,但是这些同步类的并发效率并不是很高。为了更好的支持高并发任务,并发大师Doug Lea在JUC(java.util.concurrent)包中添加了java集合包中单线程类的对应的支持高并发的类。例如,ArrayList对应的高并发类是CopyOnWriteArrayList,HashMap对应的高并发类是ConcurrentHashMap,等等。
JUC包在添加”java集合包“对应的高并发类时,为了保持API接口的一致性,使用了”Java集合包“中的框架。例如,CopyOnWriteArrayList实现了“Java集合包”中的List接口,HashMap继承了“java集合包”中的AbstractMap类,等等。得益于“JUC包使用了Java集合包中的类”,如果我们了解了Java集合包中的类的思想之后,理解JUC包中的类也相对容易;理解时,最大的难点是,对JUC包是如何添加对“高并发”的支持的!
3) JUC中的集合类
下面,我们先了解JUC包中集合类的框架;为了方便讲诉,我将JUC包中的集合类划分为3部分来进行说明。在简单的了解JUC包中集合类的框架之后,后面的章节再逐步对各个类进行介绍。
1. List和Set
JUC集合包中的List和Set实现类包括: CopyOnWriteArrayList, CopyOnWriteArraySet和ConcurrentSkipListSet。ConcurrentSkipListSet稍后在说明Map时再说明,CopyOnWriteArrayList 和 CopyOnWriteArraySet的框架如下图所示:

(01)CopyOnWriteArrayList相当于线程安全的ArrayList,它实现了List接口。CopyOnWriteArrayList是支持高并发的。
(02)CopyOnWriteArraySet相当于线程安全的HashSet,它继承于AbstractSet类。CopyOnWriteArraySet内部包含一个CopyOnWriteArrayList对象,它是通过CopyOnWriteArrayList实现的。
2. Map
JUC集合包中Map的实现类包括:ConcurrentHashMap和ConcurrentSkipListMap。它们的框架如下图所示:

(01) ConcurrentHashMap是线程安全的哈希表(相当于线程安全的HashMap);它继承于AbstractMap类,并且实现ConcurrentMap接口。ConcurrentHashMap是通过“锁分段”来实现的,它支持并发。
(02)ConcurrentSkipListMap是线程安全的有序的哈希表(相当于线程安全的TreeMap); 它继承于AbstractMap类,并且实现ConcurrentNavigableMap接口。ConcurrentSkipListMap是通过“跳表”来实现的,它支持并发。
(03)ConcurrentSkipListSet是线程安全的有序的集合(相当于线程安全的TreeSet);它继承于AbstractSet,并实现了NavigableSet接口。ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,它也支持并发。
3. Queue
JUC集合包中Queue的实现类包括:ArrayBlockingQueue, LinkedBlockingQueue, LinkedBlockingDeque, ConcurrentLinkedQueue和ConcurrentLinkedDeque。它们的框架如下图所示:
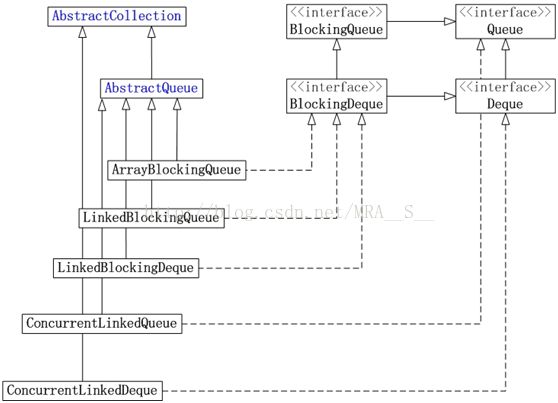
(01)ArrayBlockingQueue是数组实现的线程安全的有界的阻塞队列。
(02)LinkedBlockingQueue是单向链表实现的(指定大小)阻塞队列,该队列按 FIFO(先进先出)排序元素。
(03)LinkedBlockingDeque是双向链表实现的(指定大小)双向并发阻塞队列,该阻塞队列同时支持FIFO和FILO两种操作方式。
(04)ConcurrentLinkedQueue是单向链表实现的无界队列,该队列按 FIFO(先进先出)排序元素。
(05)ConcurrentLinkedDeque是双向链表实现的无界队列,该队列同时支持FIFO和FILO两种操作方式。
接下来,将逐个对JUC包中的集合类进行学习。
二、 “JUC集合”02之 CopyOnWriteArrayList
1) 概要
本章是"JUC系列"的CopyOnWriteArrayList篇。接下来,会先对CopyOnWriteArrayList进行基本介绍,然后再说明它的原理,接着通过代码去分析,最后通过示例更进一步的了解CopyOnWriteArrayList。内容包括:
CopyOnWriteArrayList介绍
CopyOnWriteArrayList原理和数据结构
CopyOnWriteArrayList函数列表
CopyOnWriteArrayList源码分析(JDK1.7.0_40版本)
CopyOnWriteArrayList示例
2) CopyOnWriteArrayList介绍
它相当于线程安全的ArrayList。和ArrayList一样,它是个可变数组;但是和ArrayList不同的时,它具有以下特性:
1. 它最适合于具有以下特征的应用程序:List 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等操作。
5. 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
建议:在学习CopyOnWriteArraySet之前,先通过"Java 集合系列03之ArrayList详细介绍(源码解析)和使用示例"对ArrayList进行了解!
3) CopyOnWriteArrayList原理和数据结构
CopyOnWriteArrayList的数据结构,如下图所示:
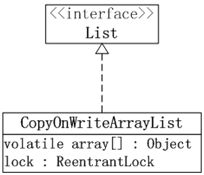
说明:
1. CopyOnWriteArrayList实现了List接口,因此它是一个队列。
2.CopyOnWriteArrayList包含了成员lock。每一个CopyOnWriteArrayList都和一个互斥锁lock绑定,通过lock,实现了对CopyOnWriteArrayList的互斥访问。
3.CopyOnWriteArrayList包含了成员array数组,这说明CopyOnWriteArrayList本质上通过数组实现的。
下面从“动态数组”和“线程安全”两个方面进一步对CopyOnWriteArrayList的原理进行说明。
1.CopyOnWriteArrayList的“动态数组”机制 -- 它内部有个“volatile数组”(array)来保持数据。在“添加/修改/删除”数据时,都会新建一个数组,并将更新后的数据拷贝到新建的数组中,最后再将该数组赋值给“volatile数组”。这就是它叫做CopyOnWriteArrayList的原因!CopyOnWriteArrayList就是通过这种方式实现的动态数组;不过正由于它在“添加/修改/删除”数据时,都会新建数组,所以涉及到修改数据的操作,CopyOnWriteArrayList效率很
低;但是单单只是进行遍历查找的话,效率比较高。
2.CopyOnWriteArrayList的“线程安全”机制 -- 是通过volatile和互斥锁来实现的。(01) CopyOnWriteArrayList是通过“volatile数组”来保存数据的。一个线程读取volatile数组时,总能看到其它线程对该volatile变量最后的写入;就这样,通过volatile提供了“读取到的数据总是最新的”这个机制的
保证。(02) CopyOnWriteArrayList通过互斥锁来保护数据。在“添加/修改/删除”数据时,会先“获取互斥锁”,再修改完毕之后,先将数据更新到“volatile数组”中,然后再“释放互斥锁”;这样,就达到了保护数据的目的。
4) CopyOnWriteArrayList函数列表
// 创建一个空列表。
CopyOnWriteArrayList()
// 创建一个按 collection 的迭代器返回元素的顺序包含指定 collection 元素的列表。
CopyOnWriteArrayList(Collection c)
//CopyOnWriteArrayList(E[] toCopyIn)
创建一个保存给定数组的副本的列表。
// 将指定元素添加到此列表的尾部。
boolean add(E e)
// 在此列表的指定位置上插入指定元素。
void add(intindex, E element)
// 按照指定 collection 的迭代器返回元素的顺序,将指定 collection 中的所有元素添加此列表的尾部。
booleanaddAll(Collection c)
// 从指定位置开始,将指定 collection 的所有元素插入此列表。
boolean addAll(intindex, Collection c)
// 按照指定 collection 的迭代器返回元素的顺序,将指定 collection 中尚未包含在此列表中的所有元素添加列表的尾部。
intaddAllAbsent(Collection c)
// 添加元素(如果不存在)。
booleanaddIfAbsent(E e)
// 从此列表移除所有元素。
void clear()
// 返回此列表的浅表副本。
Object clone()
// 如果此列表包含指定的元素,则返回 true。
booleancontains(Object o)
// 如果此列表包含指定 collection 的所有元素,则返回 true。
booleancontainsAll(Collection c)
// 比较指定对象与此列表的相等性。
booleanequals(Object o)
// 返回列表中指定位置的元素。
E get(int index)
// 返回此列表的哈希码值。
int hashCode()
// 返回第一次出现的指定元素在此列表中的索引,从 index 开始向前搜索,如果没有找到该元素,则返回 -1。
int indexOf(E e,int index)
// 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。
int indexOf(Objecto)
// 如果此列表不包含任何元素,则返回 true。
boolean isEmpty()
// 返回以恰当顺序在此列表元素上进行迭代的迭代器。
Iterator
// 返回最后一次出现的指定元素在此列表中的索引,从 index 开始向后搜索,如果没有找到该元素,则返回 -1。
int lastIndexOf(Ee, int index)
// 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。
intlastIndexOf(Object o)
// 返回此列表元素的列表迭代器(按适当顺序)。
ListIterator
// 返回列表中元素的列表迭代器(按适当顺序),从列表的指定位置开始。
ListIterator
// 移除此列表指定位置上的元素。
E remove(intindex)
// 从此列表移除第一次出现的指定元素(如果存在)。
booleanremove(Object o)
// 从此列表移除所有包含在指定 collection 中的元素。
booleanremoveAll(Collection c)
// 只保留此列表中包含在指定 collection 中的元素。
booleanretainAll(Collection c)
// 用指定的元素替代此列表指定位置上的元素。
E set(int index, Eelement)
// 返回此列表中的元素数。
int size()
// 返回此列表中 fromIndex(包括)和toIndex(不包括)之间部分的视图。
List
// 返回一个按恰当顺序(从第一个元素到最后一个元素)包含此列表中所有元素的数组。
Object[] toArray()
// 返回以恰当顺序(从第一个元素到最后一个元素)包含列表所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。
// 返回此列表的字符串表示形式。
String toString()
5) CopyOnWriteArrayList源码分析(JDK1.7.0_40版本)
下面我们从“创建,添加,删除,获取,遍历”这5个方面去分析CopyOnWriteArrayList的原理。
1. 创建
CopyOnWriteArrayList共3个构造函数。它们的源码如下:
publicCopyOnWriteArrayList() {
setArray(new Object[0]);
}
publicCopyOnWriteArrayList(Collection c) {
Object[] elements = c.toArray();
if (elements.getClass() != Object[].class)
elements = Arrays.copyOf(elements,elements.length, Object[].class);
setArray(elements);
}
publicCopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn,toCopyIn.length, Object[].class));
}
说明:这3个构造函数都调用了setArray(),setArray()的源码如下:
private volatiletransient Object[] array;
final Object[]getArray() {
return array;
}
final voidsetArray(Object[] a) {
array = a;
}
说明:setArray()的作用是给array赋值;其中,array是volatiletransient Object[]类型,即array是“volatile数组”。
关于volatile关键字,我们知道“volatile能让变量变得可见”,即对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。正在由于这种特性,每次更新了“volatile数组”之后,其它线程都能看到对它所做的更新。
关于transient关键字,它是在序列化中才起作用,transient变量不会被自动序列化。transient不是本文关注的重点,了解即可。
关于transient的更多内容,请参考:http://www.cnblogs.com/skywang12345/p/io_06.html
2. 添加
以add(E e)为例,来对“CopyOnWriteArrayList的添加操作”进行说明。下面是add(E e)的代码:
public booleanadd(E e) {
final ReentrantLock lock = this.lock;
// 获取“锁”
lock.lock();
try {
// 获取原始”volatile数组“中的数据和数据长度。
Object[] elements = getArray();
int len = elements.length;
// 新建一个数组newElements,并将原始数据拷贝到newElements中;
// newElements数组的长度=“原始数组的长度”+1
Object[] newElements =Arrays.copyOf(elements, len + 1);
// 将“新增加的元素”保存到newElements中。
newElements[len] = e;
// 将newElements赋值给”volatile数组“。
setArray(newElements);
return true;
} finally {
// 释放“锁”
lock.unlock();
}
}
说明:add(E e)的作用就是将数据e添加到”volatile数组“中。它的实现方式是,新建一个数组,接着将原始的”volatile数组“的数据拷贝到新数组中,然后将新增数据也添加到新数组中;最后,将新数组赋值给”volatile数组“。
在add(E e)中有两点需要关注。
第一,在”添加操作“开始前,获取独占锁(lock),若此时有需要线程要获取锁,则必须等待;在操作完毕后,释放独占锁(lock),此时其它线程才能获取锁。通过独占锁,来防止多线程同时修改数据!lock的定义如下:
transient finalReentrantLock lock = new ReentrantLock();
关于ReentrantLock的更多内容,可以参考:Java多线程系列--“JUC锁”02之 互斥锁ReentrantLock
第二,操作完毕时,会通过setArray()来更新”volatile数组“。而且,前面我们提过”即对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入“;这样,每次添加元素之后,其它线程都能看到新添加的元素。
3. 获取
以get(int index)为例,来对“CopyOnWriteArrayList的获取操作”进行说明。下面是get(intindex)的代码:
public E get(intindex) {
return get(getArray(), index);
}
private Eget(Object[] a, int index) {
return (E) a[index];
}
说明:get(int index)的实现很简单,就是返回”volatile数组“中的第index个元素。
4. 删除
以remove(int index)为例,来对“CopyOnWriteArrayList的删除操作”进行说明。下面是remove(intindex)的代码:
public Eremove(int index) {
final ReentrantLock lock = this.lock;
// 获取“锁”
lock.lock();
try {
// 获取原始”volatile数组“中的数据和数据长度。
Object[] elements = getArray();
int len = elements.length;
// 获取elements数组中的第index个数据。
E oldValue = get(elements, index);
int numMoved = len - index - 1;
// 如果被删除的是最后一个元素,则直接通过Arrays.copyOf()进行处理,而不需要新建数组。
// 否则,新建数组,然后将”volatile数组中被删除元素之外的其它元素“拷贝到新数组中;最后,将新数组赋值给”volatile数组“。
if (numMoved == 0)
setArray(Arrays.copyOf(elements,len - 1));
else {
Object[] newElements = newObject[len - 1];
System.arraycopy(elements, 0,newElements, 0, index);
System.arraycopy(elements, index +1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
// 释放“锁”
lock.unlock();
}
}
说明:remove(int index)的作用就是将”volatile数组“中第index个元素删除。它的实现方式是,如果被删除的是最后一个元素,则直接通过Arrays.copyOf()进行处理,而不需要新建数组。否则,新建数组,然后将”volatile数组中被删除元素之外的其它元素“拷贝到新数组中;最后,将新数组赋值给”volatile数组“。
和add(E e)一样,remove(int index)也是”在操作之前,获取独占锁;操作完成之后,释放独占是“;并且”在操作完成时,会通过将数据更新到volatile数组中“。
5. 遍历
以iterator()为例,来对“CopyOnWriteArrayList的遍历操作”进行说明。下面是iterator()的代码:
publicIterator
return new COWIterator
}
说明:iterator()会返回COWIterator对象。
COWIterator实现额ListIterator接口,它的源码如下:
private staticclass COWIterator
private final Object[] snapshot;
private int cursor;
private COWIterator(Object[] elements, intinitialCursor) {
cursor = initialCursor;
snapshot = elements;
}
public boolean hasNext() {
return cursor < snapshot.length;
}
public boolean hasPrevious() {
return cursor > 0;
}
// 获取下一个元素
@SuppressWarnings("unchecked")
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
// 获取上一个元素
@SuppressWarnings("unchecked")
public E previous() {
if (! hasPrevious())
throw new NoSuchElementException();
return (E) snapshot[--cursor];
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor-1;
}
public void remove() {
throw newUnsupportedOperationException();
}
public void set(E e) {
throw newUnsupportedOperationException();
}
public void add(E e) {
throw newUnsupportedOperationException();
}
}
说明:COWIterator不支持修改元素的操作。例如,对于remove(),set(),add()等操作,COWIterator都会抛出异常!
另外,需要提到的一点是,CopyOnWriteArrayList返回迭代器不会抛出ConcurrentModificationException异常,即它不是fail-fast机制的!
关于fail-fast机制,可以参考“Java 集合系列04之fail-fast总结(通过ArrayList来说明fail-fast的原理、解决办法)”。
6) CopyOnWriteArrayList示例
下面,我们通过一个例子去对比ArrayList和CopyOnWriteArrayList。
importjava.util.*;
importjava.util.concurrent.*;
/*
* CopyOnWriteArrayList是“线程安全”的动态数组,而ArrayList是非线程安全的。
*
* 下面是“多个线程同时操作并且遍历list”的示例
* (01)当list是CopyOnWriteArrayList对象时,程序能正常运行。
* (02)当list是ArrayList对象时,程序会产生ConcurrentModificationException异常。
*
* @author skywang
*/
public classCopyOnWriteArrayListTest1 {
// TODO: list是ArrayList对象时,程序会出错。
//private static List
private static List
public static void main(String[] args) {
// 同时启动两个线程对list进行操作!
new MyThread("ta").start();
new MyThread("tb").start();
}
private static void printAll() {
String value = null;
Iterator iter = list.iterator();
while(iter.hasNext()) {
value = (String)iter.next();
System.out.print(value+",");
}
System.out.println();
}
private static class MyThread extendsThread {
MyThread(String name) {
super(name);
}
@Override
public void run() {
int i = 0;
while (i++ < 6) {
// “线程名” + "-" + "序号"
String val =Thread.currentThread().getName()+"-"+i;
list.add(val);
// 通过“Iterator”遍历List。
printAll();
}
}
}
}
(某一次)运行结果:
ta-1, tb-1, ta-1,
tb-1,
ta-1, ta-1, tb-1,tb-1, tb-2,
tb-2, ta-1, ta-2,
tb-1, ta-1, tb-2,tb-1, ta-2, tb-2, tb-3,
ta-2, ta-1, tb-3,tb-1, ta-3,
tb-2, ta-1, ta-2,tb-1, tb-3, tb-2, ta-3, ta-2, tb-4,
tb-3, ta-1, ta-3,tb-1, tb-4, tb-2, ta-4,
ta-2, ta-1, tb-3,tb-1, ta-3, tb-2, tb-4, ta-2, ta-4, tb-3, tb-5,
ta-3, ta-1, tb-4,tb-1, ta-4, tb-2, tb-5, ta-2, ta-5,
tb-3, ta-1, ta-3,tb-1, tb-4, tb-2, ta-4, ta-2, tb-5, tb-3, ta-5, ta-3, tb-6,
tb-4, ta-4, tb-5,ta-5, tb-6, ta-6,
结果说明:如果将源码中的list改成ArrayList对象时,程序会产生ConcurrentModificationException异常。
三、 “JUC集合”03之 CopyOnWriteArraySet
1) 概要
本章是JUC系列中的CopyOnWriteArraySet篇。接下来,会先对CopyOnWriteArraySet进行基本介绍,然后再说明它的原理,接着通过代码去分析,最后通过示例更进一步的了解CopyOnWriteArraySet。内容包括:
CopyOnWriteArraySet介绍
CopyOnWriteArraySet原理和数据结构
CopyOnWriteArraySet函数列表
CopyOnWriteArraySet源码(JDK1.7.0_40版本)
CopyOnWriteArraySet示例
2) CopyOnWriteArraySet介绍
它是线程安全的无序的集合,可以将它理解成线程安全的HashSet。有意思的是,CopyOnWriteArraySet和HashSet虽然都继承于共同的父类AbstractSet;但是,HashSet是通过“散列表(HashMap)”实现的,而CopyOnWriteArraySet则是通过“动态数组(CopyOnWriteArrayList)”实现的,并不是散列表。
和CopyOnWriteArrayList类似,CopyOnWriteArraySet具有以下特性:
1. 它最适合于具有以下特征的应用程序:Set 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等 操作。
5. 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
建议:在学习CopyOnWriteArraySet之前,先通过"Java 集合系列16之HashSet详细介绍(源码解析)和使用示例"对HashSet进行了解。
3) CopyOnWriteArraySet原理和数据结构
CopyOnWriteArraySet的数据结构,如下图所示:
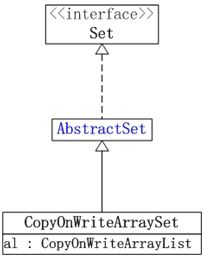
说明:
1. CopyOnWriteArraySet继承于AbstractSet,这就意味着它是一个集合。
2. CopyOnWriteArraySet包含CopyOnWriteArrayList对象,它是通过CopyOnWriteArrayList实现的。而CopyOnWriteArrayList本质是个动态数组队列,
所以CopyOnWriteArraySet相当于通过动态数组实现的“集合”! CopyOnWriteArrayList中允许有重复的元素;但是,CopyOnWriteArraySet是一个集合,所以它不能有重复集合。因此,CopyOnWriteArrayList额外提供了addIfAbsent()和addAllAbsent()这两个添加元素的API,通过这些API来添加元素时,只有当元素不存在时才执行添加操作!
至于CopyOnWriteArraySet的“线程安全”机制,和CopyOnWriteArrayList一样,是通过volatile和互斥锁来实现的。这个在前一章节介绍CopyOnWriteArrayList时数据结构时,已经进行了说明,这里就不再重复叙述了。
4) CopyOnWriteArraySet函数列表
// 创建一个空 set。
CopyOnWriteArraySet()
// 创建一个包含指定 collection 所有元素的 set。
CopyOnWriteArraySet(Collection c)
// 如果指定元素并不存在于此 set 中,则添加它。
boolean add(Ee)
// 如果此 set 中没有指定 collection 中的所有元素,则将它们都添加到此 set 中。
booleanaddAll(Collection c)
// 移除此 set 中的所有元素。
void clear()
// 如果此 set 包含指定元素,则返回 true。
booleancontains(Object o)
// 如果此 set 包含指定 collection 的所有元素,则返回 true。
booleancontainsAll(Collection c)
// 比较指定对象与此 set 的相等性。
booleanequals(Object o)
// 如果此 set 不包含任何元素,则返回 true。
booleanisEmpty()
// 返回按照元素添加顺序在此 set 中包含的元素上进行迭代的迭代器。
Iterator
// 如果指定元素存在于此 set 中,则将其移除。
booleanremove(Object o)
// 移除此 set 中包含在指定 collection 中的所有元素。
booleanremoveAll(Collection c)
// 仅保留此 set 中那些包含在指定 collection 中的元素。
booleanretainAll(Collection c)
// 返回此 set 中的元素数目。
int size()
// 返回一个包含此 set 所有元素的数组。
Object[]toArray()
// 返回一个包含此 set 所有元素的数组;返回数组的运行时类型是指定数组的类型。
5) CopyOnWriteArraySet源码(JDK1.7.0_40版本)
CopyOnWriteArraySet是通过CopyOnWriteArrayList实现的,它的API基本上都是通过调用CopyOnWriteArrayList的API来实现的。相信对CopyOnWriteArrayList了解的话,对CopyOnWriteArraySet的了解是水到渠成的事;所以,这里就不再对CopyOnWriteArraySet的代码进行详细的解析了。若对CopyOnWriteArrayList不了解,请参考“Java多线程系列--“JUC集合”02之 CopyOnWriteArrayList”。
6) CopyOnWriteArraySet示例
下面,我们通过一个例子去对比HashSet和CopyOnWriteArraySet。
importjava.util.*;
importjava.util.concurrent.*;
/*
* CopyOnWriteArraySet是“线程安全”的集合,而HashSet是非线程安全的。
*
* 下面是“多个线程同时操作并且遍历集合set”的示例
* (01)当set是CopyOnWriteArraySet对象时,程序能正常运行。
* (02)当set是HashSet对象时,程序会产生ConcurrentModificationException异常。
*
* @author skywang
*/
public classCopyOnWriteArraySetTest1 {
// TODO: set是HashSet对象时,程序会出错。
//private static Set
private static Set
public static void main(String[] args) {
// 同时启动两个线程对set进行操作!
new MyThread("ta").start();
new MyThread("tb").start();
}
private static void printAll() {
String value = null;
Iterator iter = set.iterator();
while(iter.hasNext()) {
value = (String)iter.next();
System.out.print(value+",");
}
System.out.println();
}
private static class MyThread extendsThread {
MyThread(String name) {
super(name);
}
@Override
public void run() {
int i = 0;
while (i++ < 10) {
// “线程名” + "-" + "序号"
String val =Thread.currentThread().getName() + "-" + (i%6);
set.add(val);
// 通过“Iterator”遍历set。
printAll();
}
}
}
}
(某一次)运行结果:
ta-1, tb-1,ta-1,
tb-1, ta-1,
tb-1, ta-1,ta-2,
tb-1, ta-1,ta-2, tb-1, tb-2,
ta-2, ta-1,tb-2, tb-1, ta-3,
ta-2, ta-1,tb-2, tb-1, ta-3, ta-2, tb-3,
tb-2, ta-1,ta-3, tb-1, tb-3, ta-2, ta-4,
tb-2, ta-1,ta-3, tb-1, tb-3, ta-2, ta-4, tb-2, tb-4,
ta-3, ta-1,tb-3, tb-1, ta-4, ta-2, tb-4, tb-2, ta-5,
ta-3, ta-1,tb-3, tb-1, ta-4, ta-2, tb-4, tb-2, ta-5, ta-3, tb-5,
tb-3, ta-1,ta-4, tb-1, tb-4, ta-2, ta-5, tb-2, tb-5, ta-3, ta-0,
tb-3, ta-1,ta-4, tb-1, tb-4, ta-2, ta-5, tb-2, tb-5, ta-3, ta-0, tb-3, tb-0,
ta-4, ta-1,tb-4, tb-1, ta-5, ta-2, tb-5, tb-2, ta-0, ta-3, tb-0,
tb-3, ta-1,ta-4, tb-1, tb-4, ta-2, ta-5, tb-5, ta-0, tb-0,
ta-1, tb-2,tb-1, ta-3, ta-2, tb-3, tb-2, ta-4, ta-3, tb-4, tb-3, ta-5, ta-4, tb-5, tb-4,ta-0, ta-5, tb-0,
tb-5, ta-1,ta-0, tb-1, tb-0,
ta-2, ta-1,tb-2, tb-1, ta-3, ta-2, tb-3, tb-2, ta-4, ta-3, tb-4, tb-3, ta-5, tb-5, ta-0,tb-0,
ta-4, ta-1,tb-4, tb-1, ta-5, ta-2, tb-5, tb-2, ta-0, ta-3, tb-0,
tb-3, ta-1,ta-4, tb-1, tb-4, ta-2, ta-5, tb-2, tb-5, ta-3, ta-0, tb-3, tb-0,
ta-4, tb-4,ta-5, tb-5, ta-0, tb-0,
结果说明:
由于set是集合对象,因此它不会包含重复的元素。
如果将源码中的set改成HashSet对象时,程序会产生ConcurrentModificationException异常。
四、 “JUC集合”04之 ConcurrentHashMap
1) 概要
本章是JUC系列的ConcurrentHashMap篇。内容包括:
ConcurrentHashMap介绍
ConcurrentHashMap原理和数据结构
ConcurrentHashMap函数列表
ConcurrentHashMap源码分析(JDK1.7.0_40版本)
ConcurrentHashMap示例
2) ConcurrentHashMap介绍
ConcurrentHashMap是线程安全的哈希表。HashMap, Hashtable, ConcurrentHashMap之间的关联如下:
HashMap是非线程安全的哈希表,常用于单线程程序中。
Hashtable是线程安全的哈希表,它是通过synchronized来保证线程安全的;即,多线程通过同一个“对象的同步锁”来实现并发控制。Hashtable在线程竞争激烈时,效率比较低(此时建议使用ConcurrentHashMap)!因为当一个线程访问Hashtable的同步方法时,其它线程就访问Hashtable的同步方法时,可能会进入阻塞状态。
ConcurrentHashMap是线程安全的哈希表,它是通过“锁分段”来保证线程安全的。ConcurrentHashMap将哈希表分成许多片段(Segment),每一个片段除了保存哈希表之外,本质上也是一个“可重入的互斥锁”(ReentrantLock)。多线程对同一个片段的访问,是互斥的;但是,对于不同片段的访问,却是可以同步进行的。
关于HashMap,Hashtable以及ReentrantLock的更多内容,可以参考:
1. Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
2. Java 集合系列11之 Hashtable详细介绍(源码解析)和使用示例
3. Java多线程系列--“JUC锁”02之 互斥锁ReentrantLock
3) ConcurrentHashMap原理和数据结构
要想搞清ConcurrentHashMap,必须先弄清楚它的数据结构:
(01) ConcurrentHashMap继承于AbstractMap抽象类。
(02) Segment是ConcurrentHashMap中的内部类,它就是ConcurrentHashMap中的“锁分段”对应的存储结构。ConcurrentHashMap与Segment是组合关系,1个ConcurrentHashMap对象包含若干个Segment对象。在代码中,这表现为ConcurrentHashMap类中存在“Segment数组”成员。
(03) Segment类继承于ReentrantLock类,所以Segment本质上是一个可重入的互斥锁。
(04) HashEntry也是ConcurrentHashMap的内部类,是单向链表节点,存储着key-value键值对。Segment与HashEntry是组合关系,Segment类中存在“HashEntry数组”成员,“HashEntry数组”中的每个HashEntry就是一个单向链表。
对于多线程访问对一个“哈希表对象”竞争资源,Hashtable是通过一把锁来控制并发;而ConcurrentHashMap则是将哈希表分成许多片段,对于每一个片段分别通过一个互斥锁来控制并发。ConcurrentHashMap对并发的控制更加细腻,它也更加适应于高并发场景!
4) ConcurrentHashMap函数列表
// 创建一个带有默认初始容量(16)、加载因子 (0.75) 和concurrencyLevel (16) 的新的空映射。
ConcurrentHashMap()
// 创建一个带有指定初始容量、默认加载因子 (0.75) 和 concurrencyLevel (16) 的新的空映射。
ConcurrentHashMap(int initialCapacity)
// 创建一个带有指定初始容量、加载因子和默认 concurrencyLevel (16) 的新的空映射。
ConcurrentHashMap(int initialCapacity, floatloadFactor)
// 创建一个带有指定初始容量、加载因子和并发级别的新的空映射。
ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel)
// 构造一个与给定映射具有相同映射关系的新映射。
ConcurrentHashMap(Map m)
// 从该映射中移除所有映射关系
void clear()
// 一种遗留方法,测试此表中是否有一些与指定值存在映射关系的键。
boolean contains(Object value)
// 测试指定对象是否为此表中的键。
boolean containsKey(Object key)
// 如果此映射将一个或多个键映射到指定值,则返回 true。
boolean containsValue(Object value)
// 返回此表中值的枚举。
Enumeration
// 返回此映射所包含的映射关系的Set 视图。
Set
// 返回指定键所映射到的值,如果此映射不包含该键的映射关系,则返回 null。
V get(Object key)
// 如果此映射不包含键-值映射关系,则返回 true。
boolean isEmpty()
// 返回此表中键的枚举。
Enumeration
// 返回此映射中包含的键的 Set 视图。
Set
// 将指定键映射到此表中的指定值。
V put(K key, V value)
// 将指定映射中所有映射关系复制到此映射中。
void putAll(Map m)
// 如果指定键已经不再与某个值相关联,则将它与给定值关联。
V putIfAbsent(K key, V value)
// 从此映射中移除键(及其相应的值)。
V remove(Object key)
// 只有目前将键的条目映射到给定值时,才移除该键的条目。
boolean remove(Object key, Object value)
// 只有目前将键的条目映射到某一值时,才替换该键的条目。
V replace(K key, V value)
// 只有目前将键的条目映射到给定值时,才替换该键的条目。
boolean replace(K key, V oldValue, VnewValue)
// 返回此映射中的键-值映射关系数。
int size()
// 返回此映射中包含的值的Collection 视图。
Collection
5) ConcurrentHashMap源码分析(JDK1.7.0_40版本)
下面从ConcurrentHashMap的创建,获取,添加,删除这4个方面对ConcurrentHashMap进行分析。
1 创建
下面以ConcurrentHashMap(intinitialCapacity,float loadFactor, int concurrencyLevel)来进行说明。
@SuppressWarnings("unchecked")
public ConcurrentHashMap(intinitialCapacity,
float loadFactor, intconcurrencyLevel) {
// 参数有效性判断
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel<= 0)
throw new IllegalArgumentException();
// concurrencyLevel是“用来计算segments的容量”
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
int ssize = 1;
// ssize=“大于或等于concurrencyLevel的最小的2的N次方值”
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 初始化segmentShift和segmentMask
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
// 哈希表的初始容量
// 哈希表的实际容量=“segments的容量” x “segments中数组的长度”
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// “哈希表的初始容量” / “segments的容量”
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
// cap就是“segments中的HashEntry数组的长度”
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// segments
Segment
new Segment
(HashEntry
Segment
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
说明:
(01) 前面我们说过,ConcurrentHashMap采用了“锁分段”技术;在代码中,它通过“segments数组”对象来保存各个分段。segments的定义如下:
final Segment
concurrencyLevel的作用就是用来计算segments数组的容量大小。先计算出“大于或等于concurrencyLevel的最小的2的N次方值”,然后将其保存为“segments的容量大小(ssize)”。
(02) initialCapacity是哈希表的初始容量。需要注意的是,哈希表的实际容量=“segments的容量” x “segments中数组的长度”。
(03) loadFactor是加载因子。它是哈希表在其容量自动增加之前可以达到多满的一种尺度。
ConcurrentHashMap的构造函数中涉及到的非常重要的一个结构体,它就是Segment。下面看看Segment的声明:
static final class Segment
...
transient volatile HashEntry
// threshold阈,是哈希表在其容量自动增加之前可以达到多满的一种尺度。
transient int threshold;
// loadFactor是加载因子
final float loadFactor;
Segment(float lf, int threshold, HashEntry
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
...
}
说明:Segment包含HashEntry数组,HashEntry保存了哈希表中的键值对。
此外,还需要说明的Segment继承于ReentrantLock。这意味着,Segment本质上就是可重入的互斥锁。
HashEntry的源码如下:
static final class HashEntry
final int hash; // 哈希值
final K key; // 键
volatile V value; // 值
volatile HashEntry
HashEntry(int hash, K key, V value, HashEntry
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
}
说明:和HashMap的节点一样,HashEntry也是链表。这就说明,ConcurrentHashMap是链式哈希表,它是通过“拉链法”来解决哈希冲突的。
2 获取
下面以get(Object key)为例,对ConcurrentHashMap的获取方法进行说明。
public V get(Object key) {
Segment
HashEntry
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) < // 获取key对应的Segment片段。 // 如果Segment片段不为null,则在“Segment片段的HashEntry数组中”中找到key所对应的HashEntry列表; // 接着遍历该HashEntry链表,找到于key-value键值对对应的HashEntry节点。 if ((s = (Segment (tab = s.table) != null) { for (HashEntry (tab, ((long)(((tab.length -1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null; } 说明:get(Object key)的作用是返回key在ConcurrentHashMap哈希表中对应的值。 它首先根据key计算出来的哈希值,获取key所对应的Segment片段。 如果Segment片段不为null,则在“Segment片段的HashEntry数组中”中找到key所对应的HashEntry列表。Segment包含“HashEntry数组”对象,而每一个HashEntry本质上是一个单向链表。 接着遍历该HashEntry链表,找到于key-value键值对对应的HashEntry节点。 下面是hash()的源码 private int hash(Object k) { int h = hashSeed; if ((0 != h) && (k instanceof String)) { return sun.misc.Hashing.stringHash32((String) k); } h^= k.hashCode(); // Spread bits to regularize both segment and index locations, // using variant of single-word Wang/Jenkins hash. h+= (h << 15) ^ 0xffffcd7d; h^= (h >>> 10); h+= (h << 3); h^= (h >>> 6); h+= (h << 2) + (h << 14); returnh ^ (h >>> 16); } 3 增加 下面以put(K key, V value)来对ConcurrentHashMap中增加键值对来进行说明。 public V put(K key, V value) { Segment if (value == null) throw new NullPointerException(); // 获取key对应的哈希值 int hash = hash(key); int j = (hash >>> segmentShift) & segmentMask; // 如果找不到该Segment,则新建一个。 if ((s = (Segment (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); return s.put(key, hash, value, false); } 说明: (01) put()根据key获取对应的哈希值,再根据哈希值找到对应的Segment片段。如果Segment片段不存在,则新增一个Segment。 (02) 将key-value键值对添加到Segment片段中。 final V put(K key, int hash, V value,boolean onlyIfAbsent) { // tryLock()获取锁,成功返回true,失败返回false。 // 获取锁失败的话,则通过scanAndLockForPut()获取锁,并返回”要插入的key-value“对应的”HashEntry链表“。 HashEntry scanAndLockForPut(key, hash, value); VoldValue; try { // tab代表”当前Segment中的HashEntry数组“ HashEntry // 根据”hash值“获取”HashEntry数组中对应的HashEntry链表“ int index = (tab.length - 1) & hash; HashEntry for (HashEntry // 如果”HashEntry链表中的当前HashEntry节点“不为null, if (e != null) { K k; // 当”要插入的key-value键值对“已经存在于”HashEntry链表中“时,先保存原有的值。 // 若”onlyIfAbsent“为true,即”要插入的key不存在时才插入”,则直接退出; // 否则,用新的value值覆盖原有的原有的值。 if ((k = e.key) == key || (e.hash == hash &&key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { // 如果node非空,则将first设置为“node的下一个节点”。 // 否则,新建HashEntry链表 if (node != null) node.setNext(first); else node = newHashEntry int c = count + 1; // 如果添加key-value键值对之后,Segment中的元素超过阈值(并且,HashEntry数组的长度没超过限制),则rehash; // 否则,直接添加key-value键值对。 if (c > threshold &&tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index,node); ++modCount; count = c; oldValue = null; break; } } }finally { // 释放锁 unlock(); } return oldValue; } 说明: put()的作用是将key-value键值对插入到“当前Segment对应的HashEntry中”,在插入前它会获取Segment对应的互斥锁,插入后会释放锁。具体的插入过程如下: (01) 首先根据“hash值”获取“当前Segment的HashEntry数组对象”中的“HashEntry节点”,每个HashEntry节点都是一个单向链表。 (02) 接着,遍历HashEntry链表。 若在遍历HashEntry链表时,找到与“要key-value键值对”对应的节点,即“要插入的key-value键值对”的key已经存在于HashEntry链表中。则根据onlyIfAbsent进行判断,若onlyIfAbsent为true,即“当要插入的key不存在时才插入”,则不进行插入,直接返回;否则,用新的value值覆盖原始的value值,然后再返回。 若在遍历HashEntry链表时,没有找到与“要key-value键值对”对应的节点。当node!=null时,即在scanAndLockForPut()获取锁时,已经新建了key-value对应的HashEntry节点,则”将HashEntry添加到Segment中“;否则,新建key-value对应的HashEntry节点,然后再“将HashEntry添加到Segment中”。 在”将HashEntry添加到Segment中“前,会判断是否需要rehash。如果在添加key-value键值之后,容量会超过阈值,并且HashEntry数组的长度没有超过限制,则进行rehash;否则,直接通过setEntryAt()将key-value键值对添加到Segment中。 在介绍rehash()和setEntryAt()之前,我们先看看自旋函数scanAndLockForPut()。下面是它的源码: private HashEntry // 第一个HashEntry节点 HashEntry // 当前的HashEntry节点 HashEntry HashEntry // 重复计数(自旋计数器) int retries = -1; // negative while locating node // 查找”key-value键值对“在”HashEntry链表上对应的节点“; // 若找到的话,则不断的自旋;在自旋期间,若通过tryLock()获取锁成功则返回;否则自旋MAX_SCAN_RETRIES次数之后,强制获取”锁“并退出。 // 若没有找到的话,则新建一个HashEntry链表。然后不断的自旋。 // 此外,若在自旋期间,HashEntry链表的表头发生变化;则重新进行查找和自旋工作! while (!tryLock()) { HashEntry // 1. retries<0的处理情况 if (retries < 0) { // 1.1 如果当前的HashEntry节点为空(意味着,在该HashEntry链表上上没有找到”要插入的键值对“对应的节点),而且node=null;则新建HashEntry链表。 if (e == null) { if (node == null) // speculativelycreate node node = newHashEntry retries = 0; } // 1.2 如果当前的HashEntry节点是”要插入的键值对在该HashEntry上对应的节点“,则设置retries=0 else if (key.equals(e.key)) retries = 0; // 1.3 设置为下一个HashEntry。 else e = e.next; } // 2. 如果自旋次数超过限制,则获取“锁”并退出 else if (++retries > MAX_SCAN_RETRIES) { lock(); break; } // 3. 当“尝试了偶数次”时,就获取“当前Segment的第一个HashEntry”,即f。 // 然后,通过f!=first来判断“当前Segment的第一个HashEntry是否发生了改变”。 // 若是的话,则重置e,first和retries的值,并重新遍历。 else if ((retries & 1) == 0 && (f = entryForHash(this, hash))!= first) { e = first = f; // re-traverse if entry changed retries = -1; } } return node; } 说明: scanAndLockForPut()的目标是获取锁。流程如下: 它首先会调用entryForHash(),根据hash值获取”当前Segment中对应的HashEntry节点(first),即找到对应的HashEntry链表“。 紧接着进入while循环。在while循环中,它会遍历”HashEntry链表(e)“,查找”要插入的key-value键值对“在”该HashEntry链表上对应的节点“。 若找到的话,则不断的自旋,即不断的执行while循环。在自旋期间,若通过tryLock()获取锁成功则返回;否则,在自旋MAX_SCAN_RETRIES次数之后,强制获取锁并退出。 若没有找到的话,则新建一个HashEntry链表,然后不断的自旋。在自旋期间,若通过tryLock()获取锁成功则返回;否则,在自旋MAX_SCAN_RETRIES次数之后,强制获取锁并退出。 此外,若在自旋期间,HashEntry链表的表头发生变化;则重新进行查找和自旋工作! 理解scanAndLockForPut()时,务必要联系”哈希表“的数据结构。一个Segment本身就是一个哈希表,Segment中包含了”HashEntry数组“对象,而每一个HashEntry对象本身是一个”单向链表“。 下面看看rehash()的实现代码。 private void rehash(HashEntry HashEntry // ”Segment中原始的HashEntry数组的长度“ int oldCapacity = oldTable.length; // ”Segment中新HashEntry数组的长度“ int newCapacity = oldCapacity << 1; // 新的阈值 threshold = (int)(newCapacity * loadFactor); // 新的HashEntry数组 HashEntry (HashEntry int sizeMask = newCapacity - 1; // 遍历”原始的HashEntry数组“, // 将”原始的HashEntry数组“中的每个”HashEntry链表“的值,都复制到”新的HashEntry数组的HashEntry元素“中。 for (int i = 0; i < oldCapacity ; i++) { // 获取”原始的HashEntry数组“中的”第i个HashEntry链表“ HashEntry if (e != null) { HashEntry int idx = e.hash & sizeMask; if (next == null) // Single node on list newTable[idx] = e; else { // Reuse consecutive sequence at same slot HashEntry int lastIdx = idx; for (HashEntry last != null; last = last.next) { int k = last.hash &sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } newTable[lastIdx] = lastRun; // 将”原始的HashEntry数组“中的”HashEntry链表(e)“的值,都复制到”新的HashEntry数组的HashEntry“中。 for (HashEntry V v = p.value; int h = p.hash; int k = h & sizeMask; HashEntry newTable[k] = newHashEntry } } } } // 将新的node节点添加到“Segment的新HashEntry数组(newTable)“中。 int nodeIndex = node.hash & sizeMask; // add the new node node.setNext(newTable[nodeIndex]); newTable[nodeIndex] = node; table = newTable; } 说明:rehash()的作用是将”Segment的容量“变为”原始的Segment容量的2倍“。 在将原始的数据拷贝到“新的Segment”中后,会将新增加的key-value键值对添加到“新的Segment”中。 setEntryAt()的源码如下: static final HashEntry UNSAFE.putOrderedObject(tab, ((long)i << TSHIFT) + TBASE, e); } UNSAFE是Segment类中定义的“静态sun.misc.Unsafe”对象。源码如下: static final sun.misc.Unsafe UNSAFE; Unsafe.java在openjdk6中的路径是:openjdk6/jdk/src/share/classes/sun/misc/Unsafe.java。其中,putOrderedObject()的源码下: public native void putOrderedObject(Objecto, long offset, Object x); 说明:putOrderedObject()是一个本地方法。 它会设置obj对象中offset偏移地址对应的object型field的值为指定值。它是一个有序或者有延迟的putObjectVolatile()方法,并且不保证值的改变被其他线程立即看到。只有在field被volatile修饰并且期望被意外修改的时候,使用putOrderedObject()才有用。 总之,setEntryAt()的目的是设置tab中第i位置元素的值为e,且该设置会有延迟。 4 删除 下面以remove(Object key)来对ConcurrentHashMap中的删除操作来进行说明。 public V remove(Object key) { int hash = hash(key); // 根据hash值,找到key对应的Segment片段。 Segment return s == null ? null : s.remove(key, hash, null); } 说明:remove()首先根据“key的计算出来的哈希值”找到对应的Segment片段,然后再从该Segment片段中删除对应的“key-value键值对”。 remove()的方法如下: final V remove(Object key, int hash, Objectvalue) { // 尝试获取Segment对应的锁。 // 尝试失败的话,则通过scanAndLock()来获取锁。 if (!tryLock()) scanAndLock(key, hash); VoldValue = null; try { // 根据“hash值”找到“Segment的HashEntry数组”中对应的“HashEntry节点(e)”,该HashEntry节点是一HashEntry个链表。 HashEntry int index = (tab.length - 1) & hash; HashEntry HashEntry // 遍历“HashEntry链表”,删除key-value键值对 while (e != null) { K k; HashEntry if ((k = e.key) == key || (e.hash == hash &&key.equals(k))) { V v = e.value; if (value == null || value == v|| value.equals(v)) { if (pred == null) setEntryAt(tab, index,next); else pred.setNext(next); ++modCount; --count; oldValue = v; } break; } pred = e; e = next; } }finally { // 释放锁 unlock(); } return oldValue; } 说明:remove()的目的就是删除key-value键值对。在删除之前,它会获取到Segment的互斥锁,在删除之后,再释放锁。 它的删除过程也比较简单,它会先根据hash值,找到“Segment的HashEntry数组”中对应的“HashEntry”节点。根据Segment的数据结构,我们知道Segment中包含一个HashEntry数组对象,而每一个HashEntry本质上是一个单向链表。 在找到“HashEntry”节点之后,就遍历该“HashEntry”节点对应的链表,找到key-value键值对对应的节点,然后删除。 下面对scanAndLock()进行说明。它的源码如下: private void scanAndLock(Object key, inthash) { // 第一个HashEntry节点 HashEntry HashEntry int retries = -1; // 查找”key-value键值对“在”HashEntry链表上对应的节点“; // 无论找没找到,最后都会不断的自旋;在自旋期间,若通过tryLock()获取锁成功则返回;否则自旋MAX_SCAN_RETRIES次数之后,强制获取”锁“并退出。 // 若在自旋期间,HashEntry链表的表头发生变化;则重新进行查找和自旋! while (!tryLock()) { HashEntry if (retries < 0) { // 如果“遍历完该HashEntry链表,仍然没找到”要删除的键值对“对应的节点” // 或者“在该HashEntry链表上找到”要删除的键值对“对应的节点”,则设置retries=0 // 否则,设置e为下一个HashEntry节点。 if (e == null || key.equals(e.key)) retries = 0; else e = e.next; } // 自旋超过限制次数之后,获取锁并退出。 else if (++retries > MAX_SCAN_RETRIES) { lock(); break; } // 当“尝试了偶数次”时,就获取“当前Segment的第一个HashEntry”,即f。 // 然后,通过f!=first来判断“当前Segment的第一个HashEntry是否发生了改变”。 // 若是的话,则重置e,first和retries的值,并重新遍历。 else if ((retries & 1) == 0 && (f = entryForHash(this, hash))!= first) { e = first = f; retries = -1; } } } 说明:scanAndLock()的目标是获取锁。它的实现与scanAndLockForPut()类似,这里就不再过多说明。 总结:ConcurrentHashMap是线程安全的哈希表,它是通过“锁分段”来实现的。ConcurrentHashMap中包括了“Segment(锁分段)数组”,每个Segment就是一个哈希表,而且也是可重入的互斥锁。第一,Segment是哈希表表现在,Segment包含了“HashEntry数组”,而“HashEntry数组”中的每一个HashEntry元素是一个单向链表。即Segment是通过链式哈希表。第二,Segment是可重入的互斥锁表现在,Segment继承于ReentrantLock,而ReentrantLock就是可重入的互斥锁。 对于ConcurrentHashMap的添加,删除操作,在操作开始前,线程都会获取Segment的互斥锁;操作完毕之后,才会释放。而对于读取操作,它是通过volatile去实现的,HashEntry数组是volatile类型的,而volatile能保证“即对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入”,即我们总能读到其它线程写入HashEntry之后的值。以上这些方式,就是ConcurrentHashMap线程安全的实现原理。 下面,我们通过一个例子去对比HashMap和ConcurrentHashMap。 import java.util.*; import java.util.concurrent.*; /* * ConcurrentHashMap是“线程安全”的哈希表,而HashMap是非线程安全的。 * * 下面是“多个线程同时操作并且遍历map”的示例 * (01)当map是ConcurrentHashMap对象时,程序能正常运行。 * (02)当map是HashMap对象时,程序会产生ConcurrentModificationException异常。 * *@author skywang */ public class ConcurrentHashMapDemo1 { // TODO: map是HashMap对象时,程序会出错。 //private static Map private static Map public static void main(String[] args) { // 同时启动两个线程对map进行操作! new MyThread("ta").start(); new MyThread("tb").start(); } private static void printAll() { String key, value; Iterator iter = map.entrySet().iterator(); while(iter.hasNext()) { Map.Entry entry = (Map.Entry)iter.next(); key = (String)entry.getKey(); value = (String)entry.getValue(); System.out.print(key+" - "+value+", "); } System.out.println(); } private static class MyThread extends Thread { MyThread(String name) { super(name); } @Override public void run() { int i = 0; while (i++ < 6) { // “线程名” + "-" + "序号" String val =Thread.currentThread().getName()+i; map.put(String.valueOf(i),val); // 通过“Iterator”遍历map。 printAll(); } } } } (某一次)运行结果: 1 - tb1, 1 - tb1, 1 - tb1, 1 - tb1, 2 - tb2, 2 - tb2, 1 - tb1, 3 - ta3, 1 - tb1, 2 - tb2, 3 - tb3, 1 - tb1, 2 - tb2, 3 - tb3, 1 - tb1, 4 - tb4, 3 - tb3, 2 -tb2, 4 - tb4, 1 - tb1, 2 - tb2, 5 - ta5, 1 - tb1, 3 - tb3, 5 - tb5, 4 -tb4, 3 - tb3, 2 - tb2, 4 - tb4, 1 - tb1, 2 - tb2, 5 - tb5, 1 - tb1, 6 - tb6, 5 - tb5, 3 -tb3, 6 - tb6, 4 - tb4, 3 - tb3, 2 - tb2, 4 - tb4, 2 - tb2, 结果说明:如果将源码中的map改成HashMap对象时,程序会产生ConcurrentModificationException异常。 本章对Java.util.concurrent包中的ConcurrentSkipListMap类进行详细的介绍。内容包括: ConcurrentSkipListMap介绍 ConcurrentSkipListMap原理和数据结构 ConcurrentSkipListMap函数列表 ConcurrentSkipListMap源码分析(JDK1.7.0_40版本) ConcurrentSkipListMap示例 ConcurrentSkipListMap是线程安全的有序的哈希表,适用于高并发的场景。 ConcurrentSkipListMap和TreeMap,它们虽然都是有序的哈希表。但是,第一,它们的线程安全机制不同,TreeMap是非线程安全的,而ConcurrentSkipListMap是线程安全的。第二,ConcurrentSkipListMap是通过跳表实现的,而TreeMap是通过红黑树实现的。 关于跳表(Skip List),它是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。 ConcurrentSkipListMap的数据结构,如下图所示: 说明: 先以数据“7,14,21,32,37,71,85”序列为例,来对跳表进行简单说明。 跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。 跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在“需要找出值为32的节点”为例,来对比说明跳表和普遍的链表。 情况1:链表中查找“32”节点 路径如下图1-02所示: 需要4步(红色部分表示路径)。 情况2:跳表中查找“32”节点 路径如下图1-03所示: 忽略索引垂直线路上路径的情况下,只需要2步(红色部分表示路径)。 下面说说Java中ConcurrentSkipListMap的数据结构。 (01) ConcurrentSkipListMap继承于AbstractMap类,也就意味着它是一个哈希表。 (02) Index是ConcurrentSkipListMap的内部类,它与“跳表中的索引相对应”。HeadIndex继承于Index,ConcurrentSkipListMap中含有一个HeadIndex的对象head,head是“跳表的表头”。 (03) Index是跳表中的索引,它包含“右索引的指针(right)”,“下索引的指针(down)”和“哈希表节点node”。node是Node的对象,Node也是ConcurrentSkipListMap中的内部类。 // 构造一个新的空映射,该映射按照键的自然顺序进行排序。 ConcurrentSkipListMap() // 构造一个新的空映射,该映射按照指定的比较器进行排序。 ConcurrentSkipListMap(Comparator comparator) // 构造一个新映射,该映射所包含的映射关系与给定映射包含的映射关系相同,并按照键的自然顺序进行排序。 ConcurrentSkipListMap(Map m) // 构造一个新映射,该映射所包含的映射关系与指定的有序映射包含的映射关系相同,使用的顺序也相同。 ConcurrentSkipListMap(SortedMap // 返回与大于等于给定键的最小键关联的键-值映射关系;如果不存在这样的条目,则返回 null。 Map.Entry // 返回大于等于给定键的最小键;如果不存在这样的键,则返回 null。 K ceilingKey(K key) // 从此映射中移除所有映射关系。 void clear() // 返回此ConcurrentSkipListMap 实例的浅表副本。 ConcurrentSkipListMap // 返回对此映射中的键进行排序的比较器;如果此映射使用键的自然顺序,则返回 null。 Comparator comparator() // 如果此映射包含指定键的映射关系,则返回 true。 boolean containsKey(Object key) // 如果此映射为指定值映射一个或多个键,则返回 true。 boolean containsValue(Object value) // 返回此映射中所包含键的逆序NavigableSet 视图。 NavigableSet // 返回此映射中所包含映射关系的逆序视图。 ConcurrentNavigableMap // 返回此映射中所包含的映射关系的Set 视图。 Set // 比较指定对象与此映射的相等性。 boolean equals(Object o) // 返回与此映射中的最小键关联的键-值映射关系;如果该映射为空,则返回 null。 Map.Entry // 返回此映射中当前第一个(最低)键。 K firstKey() // 返回与小于等于给定键的最大键关联的键-值映射关系;如果不存在这样的键,则返回 null。 Map.Entry // 返回小于等于给定键的最大键;如果不存在这样的键,则返回 null。 K floorKey(K key) // 返回指定键所映射到的值;如果此映射不包含该键的映射关系,则返回 null。 V get(Object key) // 返回此映射的部分视图,其键值严格小于 toKey。 ConcurrentNavigableMap // 返回此映射的部分视图,其键小于(或等于,如果 inclusive 为 true)toKey。 ConcurrentNavigableMap // 返回与严格大于给定键的最小键关联的键-值映射关系;如果不存在这样的键,则返回 null。 Map.Entry // 返回严格大于给定键的最小键;如果不存在这样的键,则返回 null。 K higherKey(K key) // 如果此映射未包含键-值映射关系,则返回 true。 boolean isEmpty() // 返回此映射中所包含键的NavigableSet 视图。 NavigableSet // 返回与此映射中的最大键关联的键-值映射关系;如果该映射为空,则返回 null。 Map.Entry // 返回映射中当前最后一个(最高)键。 K lastKey() // 返回与严格小于给定键的最大键关联的键-值映射关系;如果不存在这样的键,则返回 null。 Map.Entry // 返回严格小于给定键的最大键;如果不存在这样的键,则返回 null。 K lowerKey(K key) // 返回此映射中所包含键的 NavigableSet视图。 NavigableSet // 移除并返回与此映射中的最小键关联的键-值映射关系;如果该映射为空,则返回 null。 Map.Entry // 移除并返回与此映射中的最大键关联的键-值映射关系;如果该映射为空,则返回 null。 Map.Entry // 将指定值与此映射中的指定键关联。 V put(K key, V value) // 如果指定键已经不再与某个值相关联,则将它与给定值关联。 V putIfAbsent(K key, V value) // 从此映射中移除指定键的映射关系(如果存在)。 V remove(Object key) // 只有目前将键的条目映射到给定值时,才移除该键的条目。 boolean remove(Object key, Object value) // 只有目前将键的条目映射到某一值时,才替换该键的条目。 V replace(K key, V value) // 只有目前将键的条目映射到给定值时,才替换该键的条目。 boolean replace(K key, V oldValue, VnewValue) // 返回此映射中的键-值映射关系数。 int size() // 返回此映射的部分视图,其键的范围从 fromKey 到 toKey。 ConcurrentNavigableMap // 返回此映射的部分视图,其键值的范围从 fromKey(包括)到 toKey(不包括)。 ConcurrentNavigableMap // 返回此映射的部分视图,其键大于等于 fromKey。 ConcurrentNavigableMap // 返回此映射的部分视图,其键大于(或等于,如果 inclusive 为 true)fromKey。 ConcurrentNavigableMap // 返回此映射中所包含值的Collection 视图。 Collection 下面从ConcurrentSkipListMap的添加,删除,获取这3个方面对它进行分析。 1. 添加 下面以put(K key, V value)为例,对ConcurrentSkipListMap的添加方法进行说明。 public V put(K key, V value) { if (value == null) throw new NullPointerException(); return doPut(key, value, false); } 实际上,put()是通过doPut()将key-value键值对添加到ConcurrentSkipListMap中的。 doPut()的源码如下: private V doPut(K kkey, V value, booleanonlyIfAbsent) { Comparable key = comparable(kkey); for (;;) { // 找到key的前继节点 Node // 设置n为“key的前继节点的后继节点”,即n应该是“插入节点”的“后继节点” Node for (;;) { if (n != null) { Node // 如果两次获得的b.next不是相同的Node,就跳转到”外层for循环“,重新获得b和n后再遍历。 if (n != b.next) break; // v是“n的值” Object v = n.value; // 当n的值为null(意味着其它线程删除了n);此时删除b的下一个节点,然后跳转到”外层for循环“,重新获得b和n后再遍历。 if (v == null) { // n is deleted n.helpDelete(b, f); break; } // 如果其它线程删除了b;则跳转到”外层for循环“,重新获得b和n后再遍历。 if (v == n || b.value == null)// b is deleted break; // 比较key和n.key int c = key.compareTo(n.key); if (c > 0) { b = n; n = f; continue; } if (c == 0) { if (onlyIfAbsent ||n.casValue(v, value)) return (V)v; else break; // restart iflost race to replace value } // else c < 0; fall through } // 新建节点(对应是“要插入的键值对”) Node // 设置“b的后继节点”为z if (!b.casNext(n, z)) break; // 多线程情况下,break才可能发生(其它线程对b进行了操作) // 随机获取一个level // 然后在“第1层”到“第level层”的链表中都插入新建节点 int level = randomLevel(); if (level > 0) insertIndex(z, level); return null; } } } 说明:doPut() 的作用就是将键值对添加到“跳表”中。 要想搞清doPut(),首先要弄清楚它的主干部分 —— 我们先单纯的只考虑“单线程的情况下,将key-value添加到跳表中”,即忽略“多线程相关的内容”。它的流程如下: 第1步:找到“插入位置”。 即,找到“key的前继节点(b)”和“key的后继节点(n)”;key是要插入节点的键。 第2步:新建并插入节点。 即,新建节点z(key对应的节点),并将新节点z插入到“跳表”中(设置“b的后继节点为z”,“z的后继节点为n”)。 第3步:更新跳表。 即,随机获取一个level,然后在“跳表”的第1层~第level层之间,每一层都插入节点z;在第level层之上就不再插入节点了。若level数值大于“跳表的层次”,则新建一层。 主干部分“对应的精简后的doPut()的代码”如下(仅供参考): private V doPut(K kkey, V value, booleanonlyIfAbsent) { Comparable key = comparable(kkey); for (;;) { // 找到key的前继节点 Node // 设置n为key的后继节点 Node for (;;) { // 新建节点(对应是“要被插入的键值对”) Node // 设置“b的后继节点”为z b.casNext(n, z); // 随机获取一个level // 然后在“第1层”到“第level层”的链表中都插入新建节点 int level = randomLevel(); if (level > 0) insertIndex(z, level); return null; } } } 理清主干之后,剩余的工作就相对简单了。主要是上面几步的对应算法的具体实现,以及多线程相关情况的处理! 2. 删除 下面以remove(Object key)为例,对ConcurrentSkipListMap的删除方法进行说明。 public V remove(Object key) { return doRemove(key, null); } 实际上,remove()是通过doRemove()将ConcurrentSkipListMap中的key对应的键值对删除的。 doRemove()的源码如下: final V doRemove(Object okey, Object value){ Comparable key = comparable(okey); for (;;) { // 找到“key的前继节点” Node // 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点) Node for (;;) { if (n == null) return null; // f是“当前节点n的后继节点” Node // 如果两次读取到的“b的后继节点”不同(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。 if (n != b.next) // inconsistent read break; // 如果“当前节点n的值”变为null(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。 Object v = n.value; if (v == null) { // n is deleted n.helpDelete(b, f); break; } // 如果“前继节点b”被删除(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。 if (v == n || b.value == null) // b is deleted break; int c = key.compareTo(n.key); if (c < 0) return null; if (c > 0) { b = n; n = f; continue; } // 以下是c=0的情况 if (value != null && !value.equals(v)) return null; // 设置“当前节点n”的值为null if (!n.casValue(v, null)) break; // 设置“b的后继节点”为f if (!n.appendMarker(f) || !b.casNext(n, f)) findNode(key); // Retry via findNode else { // 清除“跳表”中每一层的key节点 findPredecessor(key); // Clean index // 如果“表头的右索引为空”,则将“跳表的层次”-1。 if (head.right == null) tryReduceLevel(); } return (V)v; } } } 说明:doRemove()的作用是删除跳表中的节点。 和doPut()一样,我们重点看doRemove()的主干部分,了解主干部分之后,其余部分就非常容易理解了。下面是“单线程的情况下,删除跳表中键值对的步骤”: 第1步:找到“被删除节点的位置”。 即,找到“key的前继节点(b)”,“key所对应的节点(n)”,“n的后继节点f”;key是要删除节点的键。 第2步:删除节点。 即,将“key所对应的节点n”从跳表中移除 -- 将“b的后继节点”设为“f”! 第3步:更新跳表。 即,遍历跳表,删除每一层的“key节点”(如果存在的话)。如果删除“key节点”之后,跳表的层次需要-1;则执行相应的操作! 主干部分“对应的精简后的doRemove()的代码”如下(仅供参考): final V doRemove(Object okey, Object value){ Comparable key = comparable(okey); for (;;) { // 找到“key的前继节点” Node // 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点) Node for (;;) { // f是“当前节点n的后继节点” Node // 设置“当前节点n”的值为null n.casValue(v, null); // 设置“b的后继节点”为f b.casNext(n, f); // 清除“跳表”中每一层的key节点 findPredecessor(key); // 如果“表头的右索引为空”,则将“跳表的层次”-1。 if (head.right == null) tryReduceLevel(); return (V)v; } } } 3. 获取 下面以get(Object key)为例,对ConcurrentSkipListMap的获取方法进行说明。 public V get(Object key) { return doGet(key); } doGet的源码如下: private V doGet(Object okey) { Comparable key = comparable(okey); for (;;) { // 找到“key对应的节点” Node if (n == null) return null; Object v = n.value; if (v != null) return (V)v; } } 说明:doGet()是通过findNode()找到并返回节点的。 private Node for (;;) { // 找到key的前继节点 Node // 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点) Node for (;;) { // 如果“n为null”,则跳转中不存在key对应的节点,直接返回null。 if (n == null) return null; Node // 如果两次读取到的“b的后继节点”不同(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。 if (n != b.next) //inconsistent read break; Object v = n.value; // 如果“当前节点n的值”变为null(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。 if (v == null) { //n is deleted n.helpDelete(b, f); break; } if (v == n || b.value == null) //b is deleted break; // 若n是当前节点,则返回n。 int c = key.compareTo(n.key); if (c == 0) return n; // 若“节点n的key”小于“key”,则说明跳表中不存在key对应的节点,返回null if (c < 0) return null; // 若“节点n的key”大于“key”,则更新b和n,继续查找。 b = n; n = f; } } } 说明:findNode(key)的作用是在返回跳表中key对应的节点;存在则返回节点,不存在则返回null。 先弄清函数的主干部分,即抛开“多线程相关内容”,单纯的考虑单线程情况下,从跳表获取节点的算法。 第1步:找到“被删除节点的位置”。 根据findPredecessor()定位key所在的层次以及找到key的前继节点(b),然后找到b的后继节点n。 第2步:根据“key的前继节点(b)”和“key的前继节点的后继节点(n)”来定位“key对应的节点”。 具体是通过比较“n的键值”和“key”的大小。如果相等,则n就是所要查找的键。 import java.util.*; import java.util.concurrent.*; /* * ConcurrentSkipListMap是“线程安全”的哈希表,而TreeMap是非线程安全的。 * * 下面是“多个线程同时操作并且遍历map”的示例 * (01)当map是ConcurrentSkipListMap对象时,程序能正常运行。 * (02)当map是TreeMap对象时,程序会产生ConcurrentModificationException异常。 * *@author skywang */ public class ConcurrentSkipListMapDemo1 { // TODO: map是TreeMap对象时,程序会出错。 //private static Map private static Map public static void main(String[] args) { // 同时启动两个线程对map进行操作! new MyThread("a").start(); new MyThread("b").start(); } private static void printAll() { String key, value; Iterator iter = map.entrySet().iterator(); while(iter.hasNext()) { Map.Entry entry = (Map.Entry)iter.next(); key = (String)entry.getKey(); value = (String)entry.getValue(); System.out.print("("+key+", "+value+"),"); } System.out.println(); } private static class MyThread extends Thread { MyThread(String name) { super(name); } @Override public void run() { int i = 0; while (i++ < 6) { // “线程名” + "序号" String val =Thread.currentThread().getName()+i; map.put(val, "0"); // 通过“Iterator”遍历map。 printAll(); } } } } (某一次)运行结果: (a1, 0), (a1, 0), (b1, 0), (b1, 0), (a1, 0), (b1, 0), (b2, 0), (a1, 0), (a1, 0), (a2, 0), (a2, 0), (b1,0), (b1, 0), (b2, 0), (b2, 0), (b3, 0), (b3, 0), (a1, 0), (a2, 0), (a3, 0), (a1, 0), (b1, 0), (a2,0), (b2, 0), (a3, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (a1, 0), (b3, 0), (a2, 0), (b4,0), (a3, 0), (a1, 0), (a4, 0), (a2, 0), (b1,0), (a3, 0), (b2, 0), (a4, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (b5, 0), (b3, 0), (a1, 0), (b4, 0), (a2, 0), (b5,0), (a3, 0), (a1, 0), (a4, 0), (a2, 0), (a5,0), (a3, 0), (b1, 0), (a4, 0), (b2, 0), (a5, 0), (b3, 0), (b1, 0), (b4, 0),(b2, 0), (b5, 0), (b3, 0), (b6, 0), (b4, 0), (a1, 0), (b5, 0), (a2, 0), (b6,0), (a3, 0), (a4, 0), (a5, 0), (a6, 0), (b1,0), (b2, 0), (b3, 0), (b4, 0), (b5, 0), (b6, 0), 结果说明: 示例程序中,启动两个线程(线程a和线程b)分别对ConcurrentSkipListMap进行操作。以线程a而言,它会先获取“线程名”+“序号”,然后将该字符串作为key,将“0”作为value,插入到ConcurrentSkipListMap中;接着,遍历并输出ConcurrentSkipListMap中的全部元素。线程b的操作和线程a一样,只不过线程b的名字和线程a的名字不同。 当map是ConcurrentSkipListMap对象时,程序能正常运行。如果将map改为TreeMap时,程序会产生ConcurrentModificationException异常。 本章对Java.util.concurrent包中的ConcurrentSkipListSet类进行详细的介绍。内容包括: ConcurrentSkipListSet介绍 ConcurrentSkipListSet原理和数据结构 ConcurrentSkipListSet函数列表 ConcurrentSkipListSet源码(JDK1.7.0_40版本) ConcurrentSkipListSet示例 ConcurrentSkipListSet是线程安全的有序的集合,适用于高并发的场景。 ConcurrentSkipListSet和TreeSet,它们虽然都是有序的集合。但是,第一,它们的线程安全机制不同,TreeSet是非线程安全的,而ConcurrentSkipListSet是线程安全的。第二,ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,而TreeSet是通过TreeMap实现的。 ConcurrentSkipListSet的数据结构,如下图所示: 说明: (01) ConcurrentSkipListSet继承于AbstractSet。因此,它本质上是一个集合。 (02) ConcurrentSkipListSet实现了NavigableSet接口。因此,ConcurrentSkipListSet是一个有序的集合。 (03) ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的。它包含一个ConcurrentNavigableMap对象m,而m对象实际上是ConcurrentNavigableMap的实现类ConcurrentSkipListMap的实例。ConcurrentSkipListMap中的元素是key-value键值对;而ConcurrentSkipListSet是集合,它只用到了ConcurrentSkipListMap中的key! // 构造一个新的空 set,该 set 按照元素的自然顺序对其进行排序。 ConcurrentSkipListSet() // 构造一个包含指定collection 中元素的新 set,这个新 set 按照元素的自然顺序对其进行排序。 ConcurrentSkipListSet(Collection c) // 构造一个新的空 set,该 set 按照指定的比较器对其元素进行排序。 ConcurrentSkipListSet(Comparator comparator) // 构造一个新 set,该 set 所包含的元素与指定的有序 set 包含的元素相同,使用的顺序也相同。 ConcurrentSkipListSet(SortedSet // 如果此 set 中不包含指定元素,则添加指定元素。 boolean add(E e) // 返回此 set 中大于等于给定元素的最小元素;如果不存在这样的元素,则返回 null。 E ceiling(E e) // 从此 set 中移除所有元素。 void clear() // 返回此ConcurrentSkipListSet 实例的浅表副本。 ConcurrentSkipListSet // 返回对此 set 中的元素进行排序的比较器;如果此 set 使用其元素的自然顺序,则返回 null。 Comparator comparator() // 如果此 set 包含指定的元素,则返回 true。 boolean contains(Object o) // 返回在此 set 的元素上以降序进行迭代的迭代器。 Iterator // 返回此 set 中所包含元素的逆序视图。 NavigableSet // 比较指定对象与此 set 的相等性。 boolean equals(Object o) // 返回此 set 中当前第一个(最低)元素。 E first() // 返回此 set 中小于等于给定元素的最大元素;如果不存在这样的元素,则返回 null。 E floor(E e) // 返回此 set 的部分视图,其元素严格小于 toElement。 NavigableSet // 返回此 set 的部分视图,其元素小于(或等于,如果 inclusive 为 true)toElement。 NavigableSet // 返回此 set 中严格大于给定元素的最小元素;如果不存在这样的元素,则返回 null。 E higher(E e) // 如果此 set 不包含任何元素,则返回 true。 boolean isEmpty() // 返回在此 set 的元素上以升序进行迭代的迭代器。 Iterator // 返回此 set 中当前最后一个(最高)元素。 E last() // 返回此 set 中严格小于给定元素的最大元素;如果不存在这样的元素,则返回 null。 E lower(E e) // 获取并移除第一个(最低)元素;如果此 set 为空,则返回 null。 E pollFirst() // 获取并移除最后一个(最高)元素;如果此 set 为空,则返回 null。 E pollLast() // 如果此 set 中存在指定的元素,则将其移除。 boolean remove(Object o) // 从此 set 中移除包含在指定 collection 中的所有元素。 boolean removeAll(Collection c) // 返回此 set 中的元素数目。 int size() // 返回此 set 的部分视图,其元素范围从 fromElement 到 toElement。 NavigableSet // 返回此 set 的部分视图,其元素从 fromElement(包括)到 toElement(不包括)。 NavigableSet // 返回此 set 的部分视图,其元素大于等于 fromElement。 NavigableSet // 返回此 set 的部分视图,其元素大于(或等于,如果 inclusive 为 true)fromElement。 NavigableSet ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,它的接口基本上都是通过调用ConcurrentSkipListMap接口来实现的。这里就不再对它的源码进行分析了。 import java.util.*; import java.util.concurrent.*; /* * ConcurrentSkipListSet是“线程安全”的集合,而TreeSet是非线程安全的。 * * 下面是“多个线程同时操作并且遍历集合set”的示例 * (01)当set是ConcurrentSkipListSet对象时,程序能正常运行。 * (02)当set是TreeSet对象时,程序会产生ConcurrentModificationException异常。 * *@author skywang */ public class ConcurrentSkipListSetDemo1 { // TODO: set是TreeSet对象时,程序会出错。 //private static Set private static Set public static void main(String[] args) { // 同时启动两个线程对set进行操作! new MyThread("a").start(); new MyThread("b").start(); } private static void printAll() { String value = null; Iterator iter = set.iterator(); while(iter.hasNext()) { value = (String)iter.next(); System.out.print(value+", "); } System.out.println(); } private static class MyThread extends Thread { MyThread(String name) { super(name); } @Override public void run() { int i = 0; while (i++ < 10) { // “线程名” + "序号" String val =Thread.currentThread().getName() + (i%6); set.add(val); // 通过“Iterator”遍历set。 printAll(); } } } } (某一次)运行结果: a1, b1, a1, a1, a2, b1, b1, a1, a2, a3, b1, a1, a2, a3, a1, a4, b1, b2, a2, a1, a2, a3, a4, a5, b1, b2, a3, a0, a4, a5, a1, b1, a2, b2, a3, a0, a4, a1, a5, a2, b1, a3, b2, a4, b3, a5, a0, b1, a1, b2, a2, b3, a3, a0, a4, a1, a5, a2, b1, a3, b2, a4, b3,a5, b4, b1, a0, b2, a1, b3, a2, b4, a3, a0, a4, a1, a5, a2, b1, a3, b2, a4, b3,a5, b4, b1, b5, b2, a0, a1, a2, a3, a4, a5, b3, b1, b4, b2,b5, b3, a0, b4, a1, b5, a2, a0, a3, a1, a4, a2, a5, a3, b0, a4, b1,a5, b2, b0, b3, b1, b4, b2, b5, b3, b4, a0, b5, a1, a2, a3, a4, a5, b0, b1, b2, b3, b4, b5, a0, a1, a2, a3, a4, a5, b0, b1, b2, b3, b4,b5, a0, a1, a2, a3, a4, a5, b0, b1, b2, b3, b4,b5, a0, a1, a2, a3, a4, a5, b0, b1, b2, b3, b4,b5, 结果说明: 示例程序中,启动两个线程(线程a和线程b)分别对ConcurrentSkipListSet进行操作。以线程a而言,它会先获取“线程名”+“序号”,然后将该字符串添加到ConcurrentSkipListSet集合中;接着,遍历并输出集合中的全部元素。 线程b的操作和线程a一样,只不过线程b的名字和线程a的名字不同。 当set是ConcurrentSkipListSet对象时,程序能正常运行。如果将set改为TreeSet时,程序会产生ConcurrentModificationException异常。 本章对Java.util.concurrent包中的ArrayBlockingQueue类进行详细的介绍。内容包括: ArrayBlockingQueue介绍 ArrayBlockingQueue原理和数据结构 ArrayBlockingQueue函数列表 ArrayBlockingQueue源码分析(JDK1.7.0_40版本) ArrayBlockingQueue示例 ArrayBlockingQueue是数组实现的线程安全的有界的阻塞队列。 线程安全是指,ArrayBlockingQueue内部通过“互斥锁”保护竞争资源,实现了多线程对竞争资源的互斥访问。而有界,则是指ArrayBlockingQueue对应的数组是有界限的。 阻塞队列,是指多线程访问竞争资源时,当竞争资源已被某线程获取时,其它要获取该资源的线程需要阻塞等待;而且,ArrayBlockingQueue是按 FIFO(先进先出)原则对元素进行排序,元素都是从尾部插入到队列,从头部开始返回。 注意:ArrayBlockingQueue不同于ConcurrentLinkedQueue,ArrayBlockingQueue是数组实现的,并且是有界限的;而ConcurrentLinkedQueue是链表实现的,是无界限的。 ArrayBlockingQueue的数据结构,如下图所示: 说明: 1. ArrayBlockingQueue继承于AbstractQueue,并且它实现了BlockingQueue接口。 2. ArrayBlockingQueue内部是通过Object[]数组保存数据的,也就是说ArrayBlockingQueue本质上是通过数组实现的。ArrayBlockingQueue的大小,即数组的容量是创建ArrayBlockingQueue时指定的。 3. ArrayBlockingQueue与ReentrantLock是组合关系,ArrayBlockingQueue中包含一个ReentrantLock对象(lock)。ReentrantLock是可重入的互斥锁,ArrayBlockingQueue就是根据该互斥锁实现“多线程对竞争资源的互斥访问”。而且,ReentrantLock分为公平锁和非公平锁,关于具体使用公平锁还是非公平锁,在创建ArrayBlockingQueue时可以指定;而且,ArrayBlockingQueue默认会使用非公平锁。 4. ArrayBlockingQueue与Condition是组合关系,ArrayBlockingQueue中包含两个Condition对象(notEmpty和notFull)。而且,Condition又依赖于ArrayBlockingQueue而存在,通过Condition可以实现对ArrayBlockingQueue的更精确的访问 -- (01)若某线程(线程A)要取数据时,数组正好为空,则该线程会执行notEmpty.await()进行等待;当其它某个线程(线程B)向数组中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。此时,线程A会被唤醒从而得以继续运行。(02)若某线程(线程H)要插入数据时,数组已满,则该线程会它执行notFull.await()进行等待;当其它某个线程(线程I)取出数据之后,会调用notFull.signal()唤醒“notFull上的等待线程”。此时,线程H就会被唤醒从而得以继续运行。 关于ReentrantLock,公平锁,非公平锁,以及Condition等更多的内容,可以参考: (01) Java多线程系列--“JUC锁”02之 互斥锁ReentrantLock (02) Java多线程系列--“JUC锁”03之 公平锁(一) (03) Java多线程系列--“JUC锁”04之 公平锁(二) (04) Java多线程系列--“JUC锁”05之 非公平锁 (05) Java多线程系列--“JUC锁”06之 Condition条件 // 创建一个带有给定的(固定)容量和默认访问策略的 ArrayBlockingQueue。 ArrayBlockingQueue(int capacity) // 创建一个具有给定的(固定)容量和指定访问策略的 ArrayBlockingQueue。 ArrayBlockingQueue(int capacity, boolean fair) // 创建一个具有给定的(固定)容量和指定访问策略的 ArrayBlockingQueue,它最初包含给定 collection 的元素,并以 collection 迭代器的遍历顺序添加元素。 ArrayBlockingQueue(int capacity, booleanfair, Collection c) // 将指定的元素插入到此队列的尾部(如果立即可行且不会超过该队列的容量),在成功时返回 true,如果此队列已满,则抛出 IllegalStateException。 boolean add(E e) // 自动移除此队列中的所有元素。 void clear() // 如果此队列包含指定的元素,则返回true。 boolean contains(Object o) // 移除此队列中所有可用的元素,并将它们添加到给定 collection 中。 int drainTo(Collection c) // 最多从此队列中移除给定数量的可用元素,并将这些元素添加到给定 collection 中。 int drainTo(Collection c,int maxElements) // 返回在此队列中的元素上按适当顺序进行迭代的迭代器。 Iterator // 将指定的元素插入到此队列的尾部(如果立即可行且不会超过该队列的容量),在成功时返回 true,如果此队列已满,则返回 false。 boolean offer(E e) // 将指定的元素插入此队列的尾部,如果该队列已满,则在到达指定的等待时间之前等待可用的空间。 boolean offer(E e, long timeout, TimeUnitunit) // 获取但不移除此队列的头;如果此队列为空,则返回 null。 E peek() // 获取并移除此队列的头,如果此队列为空,则返回 null。 E poll() // 获取并移除此队列的头部,在指定的等待时间前等待可用的元素(如果有必要)。 E poll(long timeout, TimeUnit unit) // 将指定的元素插入此队列的尾部,如果该队列已满,则等待可用的空间。 void put(E e) // 返回在无阻塞的理想情况下(不存在内存或资源约束)此队列能接受的其他元素数量。 int remainingCapacity() // 从此队列中移除指定元素的单个实例(如果存在)。 boolean remove(Object o) // 返回此队列中元素的数量。 int size() // 获取并移除此队列的头部,在元素变得可用之前一直等待(如果有必要)。 E take() // 返回一个按适当顺序包含此队列中所有元素的数组。 Object[] toArray() // 返回一个按适当顺序包含此队列中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。 // 返回此 collection 的字符串表示形式。 String toString() 下面从ArrayBlockingQueue的创建,添加,取出,遍历这几个方面对ArrayBlockingQueue进行分析。 1. 创建 下面以ArrayBlockingQueue(int capacity, booleanfair)来进行说明。 public ArrayBlockingQueue(int capacity,boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); } 说明: (01) items是保存“阻塞队列”数据的数组。它的定义如下: final Object[] items; (02) fair是“可重入的独占锁(ReentrantLock)”的类型。fair为true,表示是公平锁;fair为false,表示是非公平锁。 notEmpty和notFull是锁的两个Condition条件。它们的定义如下: final ReentrantLock lock; private final Condition notEmpty; private final Condition notFull; 简单对Condition和Lock的用法进行说明,更多内容请参考“Java多线程系列--“JUC锁”06之 Condition条件”。 Lock的作用是提供独占锁机制,来保护竞争资源;而Condition是为了更加精细的对锁进行控制,它依赖于Lock,通过某个条件对多线程进行控制。 notEmpty表示“锁的非空条件”。当某线程想从队列中取数据时,而此时又没有数据,则该线程通过notEmpty.await()进行等待;当其它线程向队列中插入了元素之后,就调用notEmpty.signal()唤醒“之前通过notEmpty.await()进入等待状态的线程”。 同理,notFull表示“锁的满条件”。当某线程想向队列中插入元素,而此时队列已满时,该线程等待;当其它线程从队列中取出元素之后,就唤醒该等待的线程。 2. 添加 下面以offer(E e)为例,对ArrayBlockingQueue的添加方法进行说明。 public boolean offer(E e) { // 创建插入的元素是否为null,是的话抛出NullPointerException异常 checkNotNull(e); // 获取“该阻塞队列的独占锁” final ReentrantLock lock = this.lock; lock.lock(); try { // 如果队列已满,则返回false。 if (count == items.length) return false; else { // 如果队列未满,则插入e,并返回true。 insert(e); return true; } }finally { // 释放锁 lock.unlock(); } } 说明:offer(E e)的作用是将e插入阻塞队列的尾部。如果队列已满,则返回false,表示插入失败;否则,插入元素,并返回true。 (01) count表示”队列中的元素个数“。除此之外,队列中还有另外两个遍历takeIndex和putIndex。takeIndex表示下一个被取出元素的索引,putIndex表示下一个被添加元素的索引。它们的定义如下: // 队列中的元素个数 int count; // 下一个被取出元素的索引 int takeIndex; // 下一个被添加元素的索引 int putIndex; (02) insert()的源码如下: private void insert(E x) { // 将x添加到”队列“中 items[putIndex] = x; // 设置”下一个被取出元素的索引“ putIndex = inc(putIndex); // 将”队列中的元素个数”+1 ++count; // 唤醒notEmpty上的等待线程 notEmpty.signal(); } insert()在插入元素之后,会唤醒notEmpty上面的等待线程。 inc()的源码如下: final int inc(int i) { return (++i == items.length) ? 0 : i; } 若i+1的值等于“队列的长度”,即添加元素之后,队列满;则设置“下一个被添加元素的索引”为0。 3. 取出 下面以take()为例,对ArrayBlockingQueue的取出方法进行说明。 public E take() throws InterruptedException{ // 获取“队列的独占锁” final ReentrantLock lock = this.lock; // 获取“锁”,若当前线程是中断状态,则抛出InterruptedException异常 lock.lockInterruptibly(); try { // 若“队列为空”,则一直等待。 while (count == 0) notEmpty.await(); // 取出元素 return extract(); }finally { // 释放“锁” lock.unlock(); } } 说明:take()的作用是取出并返回队列的头。若队列为空,则一直等待。 extract()的源码如下: private E extract() { final Object[] items = this.items; // 强制将元素转换为“泛型E” Ex = this. // 将第takeIndex元素设为null,即删除。同时,帮助GC回收。 items[takeIndex] = null; // 设置“下一个被取出元素的索引” takeIndex = inc(takeIndex); // 将“队列中元素数量”-1 --count; // 唤醒notFull上的等待线程。 notFull.signal(); return x; } 说明:extract()在删除元素之后,会唤醒notFull上的等待线程。 4. 遍历 下面对ArrayBlockingQueue的遍历方法进行说明。 public Iterator return new Itr(); } Itr是实现了Iterator接口的类,它的源码如下: private class Itr implementsIterator // 队列中剩余元素的个数 private int remaining; // Number of elements yet to be returned // 下一次调用next()返回的元素的索引 private int nextIndex; // Index of element to be returned by next // 下一次调用next()返回的元素 private E nextItem; // Elementto be returned by next call to next // 上一次调用next()返回的元素 private E lastItem; // Elementreturned by last call to next // 上一次调用next()返回的元素的索引 private int lastRet; // Index oflast element returned, or -1 if none Itr() { // 获取“阻塞队列”的锁 final ReentrantLock lock = ArrayBlockingQueue.this.lock; lock.lock(); try { lastRet = -1; if ((remaining = count) > 0) nextItem = itemAt(nextIndex =takeIndex); } finally { // 释放“锁” lock.unlock(); } } public boolean hasNext() { return remaining > 0; } public E next() { // 获取“阻塞队列”的锁 final ReentrantLock lock = ArrayBlockingQueue.this.lock; lock.lock(); try { // 若“剩余元素<=0”,则抛出异常。 if (remaining <= 0) throw new NoSuchElementException(); lastRet = nextIndex; // 获取第nextIndex位置的元素 E x = itemAt(nextIndex); // checkfor fresher value if (x == null) { x = nextItem; // we are forced to report old value lastItem = null; // but ensure remove fails } else lastItem = x; while (--remaining > 0 && // skip over nulls (nextItem = itemAt(nextIndex= inc(nextIndex))) == null) ; return x; } finally { lock.unlock(); } } public void remove() { final ReentrantLock lock = ArrayBlockingQueue.this.lock; lock.lock(); try { int i = lastRet; if (i == -1) throw newIllegalStateException(); lastRet = -1; E x = lastItem; lastItem = null; // only remove if item still at index if (x != null && x == items[i]) { boolean removingHead = (i ==takeIndex); removeAt(i); if (!removingHead) nextIndex = dec(nextIndex); } } finally { lock.unlock(); } } } import java.util.*; import java.util.concurrent.*; /* * ArrayBlockingQueue是“线程安全”的队列,而LinkedList是非线程安全的。 * * 下面是“多个线程同时操作并且遍历queue”的示例 * (01)当queue是ArrayBlockingQueue对象时,程序能正常运行。 * (02)当queue是LinkedList对象时,程序会产生ConcurrentModificationException异常。 * *@author skywang */ public class ArrayBlockingQueueDemo1{ // TODO: queue是LinkedList对象时,程序会出错。 //private static Queue private static Queue public static void main(String[] args) { // 同时启动两个线程对queue进行操作! new MyThread("ta").start(); new MyThread("tb").start(); } private static void printAll() { String value; Iterator iter = queue.iterator(); while(iter.hasNext()) { value = (String)iter.next(); System.out.print(value+", "); } System.out.println(); } private static class MyThread extends Thread { MyThread(String name) { super(name); } @Override public void run() { int i = 0; while (i++ < 6) { // “线程名” + "-" + "序号" String val =Thread.currentThread().getName()+i; queue.add(val); // 通过“Iterator”遍历queue。 printAll(); } } } } (某一次)运行结果: ta1, ta1, tb1, ta1, tb1, ta1, ta2, tb1, ta1, ta2, tb1, tb2, ta2, ta1, tb2, tb1, ta3, ta2, ta1, tb2, tb1, ta3, ta2, tb3, tb2, ta1, ta3, tb1, tb3, ta2, ta4, tb2, ta1, ta3, tb1, tb3, ta2, ta4, tb2,tb4, ta3, ta1, tb3, tb1, ta4, ta2, tb4, tb2,ta5, ta3, ta1, tb3, tb1, ta4, ta2, tb4, tb2,ta5, ta3, tb5, tb3, ta1, ta4, tb1, tb4, ta2, ta5, tb2,tb5, ta3, ta6, tb3, ta4, tb4, ta5, tb5, ta6, tb6, 结果说明:如果将源码中的queue改成LinkedList对象时,程序会产生ConcurrentModificationException异常。 本章介绍JUC包中的LinkedBlockingQueue。内容包括: LinkedBlockingQueue介绍 LinkedBlockingQueue原理和数据结构 LinkedBlockingQueue函数列表 LinkedBlockingQueue源码分析(JDK1.7.0_40版本) LinkedBlockingQueue示例 LinkedBlockingQueue是一个单向链表实现的阻塞队列。该队列按 FIFO(先进先出)排序元素,新元素插入到队列的尾部,并且队列获取操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低。 此外,LinkedBlockingQueue还是可选容量的(防止过度膨胀),即可以指定队列的容量。如果不指定,默认容量大小等于Integer.MAX_VALUE。 LinkedBlockingQueue的数据结构,如下图所示: 说明: 1. LinkedBlockingQueue继承于AbstractQueue,它本质上是一个FIFO(先进先出)的队列。 2. LinkedBlockingQueue实现了BlockingQueue接口,它支持多线程并发。当多线程竞争同一个资源时,某线程获取到该资源之后,其它线程需要阻塞等待。 3. LinkedBlockingQueue是通过单链表实现的。 (01) head是链表的表头。取出数据时,都是从表头head处获取。 (02) last是链表的表尾。新增数据时,都是从表尾last处插入。 (03) count是链表的实际大小,即当前链表中包含的节点个数。 (04) capacity是列表的容量,它是在创建链表时指定的。 (05) putLock是插入锁,takeLock是取出锁;notEmpty是“非空条件”,notFull是“未满条件”。通过它们对链表进行并发控制。 LinkedBlockingQueue在实现“多线程对竞争资源的互斥访问”时,对于“插入”和“取出(删除)”操作分别使用了不同的锁。对于插入操作,通过“插入锁putLock”进行同步;对于取出操作,通过“取出锁takeLock”进行同步。 此外,插入锁putLock和“非满条件notFull”相关联,取出锁takeLock和“非空条件notEmpty”相关联。通过notFull和notEmpty更细腻的控制锁。 -- 若某线程(线程A)要取出数据时,队列正好为空,则该线程会执行notEmpty.await()进行等待;当其它某个线程(线程B)向队列中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。此时,线程A会被唤醒从而得以继续运行。 此外,线程A在执行取操作前,会获取takeLock,在取操作执行完毕再释放takeLock。 -- 若某线程(线程H)要插入数据时,队列已满,则该线程会它执行notFull.await()进行等待;当其它某个线程(线程I)取出数据之后,会调用notFull.signal()唤醒“notFull上的等待线程”。此时,线程H就会被唤醒从而得以继续运行。 此外,线程H在执行插入操作前,会获取putLock,在插入操作执行完毕才释放putLock。 关于ReentrantLock 和Condition等更多的内容,可以参考: (01) Java多线程系列--“JUC锁”02之 互斥锁ReentrantLock (02) Java多线程系列--“JUC锁”03之 公平锁(一) (03) Java多线程系列--“JUC锁”04之 公平锁(二) (04) Java多线程系列--“JUC锁”05之 非公平锁 (05) Java多线程系列--“JUC锁”06之 Condition条件 // 创建一个容量为Integer.MAX_VALUE 的 LinkedBlockingQueue。 LinkedBlockingQueue() // 创建一个容量是Integer.MAX_VALUE 的 LinkedBlockingQueue,最初包含给定 collection 的元素,元素按该 collection 迭代器的遍历顺序添加。 LinkedBlockingQueue(Collection c) // 创建一个具有给定(固定)容量的LinkedBlockingQueue。 LinkedBlockingQueue(int capacity) // 从队列彻底移除所有元素。 void clear() // 移除此队列中所有可用的元素,并将它们添加到给定 collection 中。 int drainTo(Collection c) // 最多从此队列中移除给定数量的可用元素,并将这些元素添加到给定 collection 中。 int drainTo(Collection c,int maxElements) // 返回在队列中的元素上按适当顺序进行迭代的迭代器。 Iterator // 将指定元素插入到此队列的尾部(如果立即可行且不会超出此队列的容量),在成功时返回 true,如果此队列已满,则返回 false。 boolean offer(E e) // 将指定元素插入到此队列的尾部,如有必要,则等待指定的时间以使空间变得可用。 boolean offer(E e, long timeout, TimeUnitunit) // 获取但不移除此队列的头;如果此队列为空,则返回 null。 E peek() // 获取并移除此队列的头,如果此队列为空,则返回 null。 E poll() // 获取并移除此队列的头部,在指定的等待时间前等待可用的元素(如果有必要)。 E poll(long timeout, TimeUnit unit) // 将指定元素插入到此队列的尾部,如有必要,则等待空间变得可用。 void put(E e) // 返回理想情况下(没有内存和资源约束)此队列可接受并且不会被阻塞的附加元素数量。 int remainingCapacity() // 从此队列移除指定元素的单个实例(如果存在)。 boolean remove(Object o) // 返回队列中的元素个数。 int size() // 获取并移除此队列的头部,在元素变得可用之前一直等待(如果有必要)。 E take() // 返回按适当顺序包含此队列中所有元素的数组。 Object[] toArray() // 返回按适当顺序包含此队列中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。 // 返回此 collection 的字符串表示形式。 String toString() 下面从LinkedBlockingQueue的创建,添加,删除,遍历这几个方面对它进行分析。 1. 创建 下面以LinkedBlockingQueue(int capacity)来进行说明。 public LinkedBlockingQueue(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); this.capacity = capacity; last = head = new Node } 说明: (01) capacity是“链式阻塞队列”的容量。 (02) head和last是“链式阻塞队列”的首节点和尾节点。它们在LinkedBlockingQueue中的声明如下: // 容量 private final int capacity; // 当前数量 private final AtomicInteger count = newAtomicInteger(0); private transient Node private transient Node // 用于控制“删除元素”的互斥锁takeLock和 锁对应的“非空条件”notEmpty private final ReentrantLock takeLock = newReentrantLock(); private final Condition notEmpty =takeLock.newCondition(); // 用于控制“添加元素”的互斥锁putLock和 锁对应的“非满条件”notFull private final ReentrantLock putLock = newReentrantLock(); private final Condition notFull =putLock.newCondition(); 链表的节点定义如下: static class Node Eitem; // 数据 Node Node(E x) { item = x; } } 2. 添加 下面以offer(E e)为例,对LinkedBlockingQueue的添加方法进行说明。 public boolean offer(E e) { if (e == null) throw new NullPointerException(); // 如果“队列已满”,则返回false,表示插入失败。 final AtomicInteger count = this.count; if (count.get() == capacity) return false; int c = -1; // 新建“节点e” Node final ReentrantLock putLock = this.putLock; // 获取“插入锁putLock” putLock.lock(); try { // 再次对“队列是不是满”的进行判断。 // 若“队列未满”,则插入节点。 if (count.get() < capacity) { // 插入节点 enqueue(node); // 将“当前节点数量”+1,并返回“原始的数量” c = count.getAndIncrement(); // 如果在插入元素之后,队列仍然未满,则唤醒notFull上的等待线程。 if (c + 1 < capacity) notFull.signal(); } }finally { // 释放“插入锁putLock” putLock.unlock(); } // 如果在插入节点前,队列为空;则插入节点后,唤醒notEmpty上的等待线程 if (c == 0) signalNotEmpty(); return c >= 0; } 说明:offer()的作用很简单,就是将元素E添加到队列的末尾。 enqueue()的源码如下: private void enqueue(Node // assert putLock.isHeldByCurrentThread(); // assert last.next == null; last = last.next = node; } enqueue()的作用是将node添加到队列末尾,并设置node为新的尾节点! signalNotEmpty()的源码如下: private void signalNotEmpty() { final ReentrantLock takeLock = this.takeLock; takeLock.lock(); try { notEmpty.signal(); }finally { takeLock.unlock(); } } signalNotEmpty()的作用是唤醒notEmpty上的等待线程。 3. 取出 下面以take()为例,对LinkedBlockingQueue的取出方法进行说明。 public E take() throws InterruptedException{ Ex; int c = -1; final AtomicInteger count = this.count; final ReentrantLock takeLock = this.takeLock; // 获取“取出锁”,若当前线程是中断状态,则抛出InterruptedException异常 takeLock.lockInterruptibly(); try { // 若“队列为空”,则一直等待。 while (count.get() == 0) { notEmpty.await(); } // 取出元素 x = dequeue(); // 取出元素之后,将“节点数量”-1;并返回“原始的节点数量”。 c = count.getAndDecrement(); if (c > 1) notEmpty.signal(); }finally { // 释放“取出锁” takeLock.unlock(); } // 如果在“取出元素之前”,队列是满的;则在取出元素之后,唤醒notFull上的等待线程。 if (c == capacity) signalNotFull(); return x; } 说明:take()的作用是取出并返回队列的头。若队列为空,则一直等待。 dequeue()的源码如下: private E dequeue() { // assert takeLock.isHeldByCurrentThread(); // assert head.item == null; Node Node h.next = h; // help GC head = first; Ex = first.item; first.item = null; return x; } dequeue()的作用就是删除队列的头节点,并将表头指向“原头节点的下一个节点”。 signalNotFull()的源码如下: private void signalNotFull() { final ReentrantLock putLock = this.putLock; putLock.lock(); try { notFull.signal(); }finally { putLock.unlock(); } } signalNotFull()的作用就是唤醒notFull上的等待线程。 4. 遍历 下面对LinkedBlockingQueue的遍历方法进行说明。 public Iterator return new Itr(); } iterator()实际上是返回一个Iter对象。 Itr类的定义如下: private class Itr implementsIterator // 当前节点 private Node // 上一次返回的节点 private Node // 当前节点对应的值 private E currentElement; Itr() { // 同时获取“插入锁putLock” 和 “取出锁takeLock” fullyLock(); try { // 设置“当前元素”为“队列表头的下一节点”,即为队列的第一个有效节点 current = head.next; if (current != null) currentElement = current.item; } finally { // 释放“插入锁putLock” 和 “取出锁takeLock” fullyUnlock(); } } // 返回“下一个节点是否为null” public boolean hasNext() { return current != null; } private Node for (;;) { Node if (s == p) return head.next; if (s == null || s.item != null) return s; p = s; } } // 返回下一个节点 public E next() { fullyLock(); try { if (current == null) throw newNoSuchElementException(); E x = currentElement; lastRet = current; current = nextNode(current); currentElement = (current == null) ? null : current.item; return x; } finally { fullyUnlock(); } } // 删除下一个节点 public void remove() { if (lastRet == null) throw new IllegalStateException(); fullyLock(); try { Node lastRet = null; for (Node p != null; trail = p, p = p.next) { if (p == node) { unlink(p, trail); break; } } } finally { fullyUnlock(); } } } import java.util.*; import java.util.concurrent.*; /* * LinkedBlockingQueue是“线程安全”的队列,而LinkedList是非线程安全的。 * * 下面是“多个线程同时操作并且遍历queue”的示例 * (01)当queue是LinkedBlockingQueue对象时,程序能正常运行。 * (02)当queue是LinkedList对象时,程序会产生ConcurrentModificationException异常。 * *@author skywang */ public class LinkedBlockingQueueDemo1 { // TODO: queue是LinkedList对象时,程序会出错。 //private static Queue private static Queue public static void main(String[] args) { // 同时启动两个线程对queue进行操作! new MyThread("ta").start(); new MyThread("tb").start(); } private static void printAll() { String value; Iterator iter = queue.iterator(); while(iter.hasNext()) { value = (String)iter.next(); System.out.print(value+", "); } System.out.println(); } private static class MyThread extends Thread { MyThread(String name) { super(name); } @Override public void run() { int i = 0; while (i++ < 6) { // “线程名” + "-" + "序号" String val =Thread.currentThread().getName()+i; queue.add(val); // 通过“Iterator”遍历queue。 printAll(); } } } } (某一次)运行结果: tb1, ta1, tb1, ta1, ta2, tb1, ta1, ta2, ta3, tb1, ta1, ta2, ta3, ta4, tb1, ta1, tb1, ta2, ta1, ta3, ta2, ta4,ta3, ta5, ta4, tb1, ta5, ta1, ta6, ta2, tb1, ta3, ta1, ta4, ta2, ta5, ta3,ta6, ta4, tb2, ta5, ta6, tb2, tb1, ta1, ta2, ta3, ta4, ta5, ta6, tb2,tb3, tb1, ta1, ta2, ta3, ta4, ta5, ta6, tb2,tb3, tb4, tb1, ta1, ta2, ta3, ta4, ta5, ta6, tb2,tb3, tb4, tb5, tb1, ta1, ta2, ta3, ta4, ta5, ta6, tb2,tb3, tb4, tb5, tb6, 结果说明: 示例程序中,启动两个线程(线程ta和线程tb)分别对LinkedBlockingQueue进行操作。以线程ta而言,它会先获取“线程名”+“序号”,然后将该字符串添加到LinkedBlockingQueue中;接着,遍历并输出LinkedBlockingQueue中的全部元素。线程tb的操作和线程ta一样,只不过线程tb的名字和线程ta的名字不同。 当queue是LinkedBlockingQueue对象时,程序能正常运行。如果将queue改为LinkedList时,程序会产生ConcurrentModificationException异常。 本章介绍JUC包中的LinkedBlockingDeque。内容包括: LinkedBlockingDeque介绍 LinkedBlockingDeque原理和数据结构 LinkedBlockingDeque函数列表 LinkedBlockingDeque源码分析(JDK1.7.0_40版本) LinkedBlockingDeque示例 LinkedBlockingDeque是双向链表实现的双向并发阻塞队列。该阻塞队列同时支持FIFO和FILO两种操作方式,即可以从队列的头和尾同时操作(插入/删除);并且,该阻塞队列是支持线程安全。 此外,LinkedBlockingDeque还是可选容量的(防止过度膨胀),即可以指定队列的容量。如果不指定,默认容量大小等于Integer.MAX_VALUE。 LinkedBlockingDeque的数据结构,如下图所示: 说明: 1. LinkedBlockingDeque继承于AbstractQueue,它本质上是一个支持FIFO和FILO的双向的队列。 2. LinkedBlockingDeque实现了BlockingDeque接口,它支持多线程并发。当多线程竞争同一个资源时,某线程获取到该资源之后,其它线程需要阻塞等待。 3. LinkedBlockingDeque是通过双向链表实现的。 3.1 first是双向链表的表头。 3.2 last是双向链表的表尾。 3.3 count是LinkedBlockingDeque的实际大小,即双向链表中当前节点个数。 3.4 capacity是LinkedBlockingDeque的容量,它是在创建LinkedBlockingDeque时指定的。 3.5 lock是控制对LinkedBlockingDeque的互斥锁,当多个线程竞争同时访问LinkedBlockingDeque时,某线程获取到了互斥锁lock,其它线程则需要阻塞等待,直到该线程释放lock,其它线程才有机会获取lock从而获取cpu执行权。 3.6 notEmpty和notFull分别是“非空条件”和“未满条件”。通过它们能够更加细腻进行并发控制。 -- 若某线程(线程A)要取出数据时,队列正好为空,则该线程会执行notEmpty.await()进行等待;当其它某个线程(线程B)向队列中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。此时,线程A会被唤醒从而得以继续运行。 此外,线程A在执行取操作前,会获取takeLock,在取操作执行完毕再释放takeLock。 -- 若某线程(线程H)要插入数据时,队列已满,则该线程会它执行notFull.await()进行等待;当其它某个线程(线程I)取出数据之后,会调用notFull.signal()唤醒“notFull上的等待线程”。此时,线程H就会被唤醒从而得以继续运行。 此外,线程H在执行插入操作前,会获取putLock,在插入操作执行完毕才释放putLock。 关于ReentrantLock 和Condition等更多的内容,可以参考: (01) Java多线程系列--“JUC锁”02之 互斥锁ReentrantLock (02) Java多线程系列--“JUC锁”03之 公平锁(一) (03) Java多线程系列--“JUC锁”04之 公平锁(二) (04) Java多线程系列--“JUC锁”05之 非公平锁 (05) Java多线程系列--“JUC锁”06之 Condition条件 // 创建一个容量为Integer.MAX_VALUE 的 LinkedBlockingDeque。 LinkedBlockingDeque() // 创建一个容量为Integer.MAX_VALUE 的 LinkedBlockingDeque,最初包含给定 collection 的元素,以该 collection 迭代器的遍历顺序添加。 LinkedBlockingDeque(Collection c) // 创建一个具有给定(固定)容量的LinkedBlockingDeque。 LinkedBlockingDeque(int capacity) // 在不违反容量限制的情况下,将指定的元素插入此双端队列的末尾。 boolean add(E e) // 如果立即可行且不违反容量限制,则将指定的元素插入此双端队列的开头;如果当前没有空间可用,则抛出 IllegalStateException。 void addFirst(E e) // 如果立即可行且不违反容量限制,则将指定的元素插入此双端队列的末尾;如果当前没有空间可用,则抛出 IllegalStateException。 void addLast(E e) // 以原子方式(atomically) 从此双端队列移除所有元素。 void clear() // 如果此双端队列包含指定的元素,则返回 true。 boolean contains(Object o) // 返回在此双端队列的元素上以逆向连续顺序进行迭代的迭代器。 Iterator // 移除此队列中所有可用的元素,并将它们添加到给定 collection 中。 int drainTo(Collection c) // 最多从此队列中移除给定数量的可用元素,并将这些元素添加到给定 collection 中。 int drainTo(Collection c,int maxElements) // 获取但不移除此双端队列表示的队列的头部。 E element() // 获取,但不移除此双端队列的第一个元素。 E getFirst() // 获取,但不移除此双端队列的最后一个元素。 E getLast() // 返回在此双端队列元素上以恰当顺序进行迭代的迭代器。 Iterator // 如果立即可行且不违反容量限制,则将指定的元素插入此双端队列表示的队列中(即此双端队列的尾部),并在成功时返回 true;如果当前没有空间可用,则返回 false。 boolean offer(E e) // 将指定的元素插入此双端队列表示的队列中(即此双端队列的尾部),必要时将在指定的等待时间内一直等待可用空间。 boolean offer(E e, long timeout, TimeUnitunit) // 如果立即可行且不违反容量限制,则将指定的元素插入此双端队列的开头,并在成功时返回 true;如果当前没有空间可用,则返回 false。 boolean offerFirst(E e) // 将指定的元素插入此双端队列的开头,必要时将在指定的等待时间内等待可用空间。 boolean offerFirst(E e, long timeout,TimeUnit unit) // 如果立即可行且不违反容量限制,则将指定的元素插入此双端队列的末尾,并在成功时返回 true;如果当前没有空间可用,则返回 false。 boolean offerLast(E e) // 将指定的元素插入此双端队列的末尾,必要时将在指定的等待时间内等待可用空间。 boolean offerLast(E e, long timeout,TimeUnit unit) // 获取但不移除此双端队列表示的队列的头部(即此双端队列的第一个元素);如果此双端队列为空,则返回 null。 E peek() // 获取,但不移除此双端队列的第一个元素;如果此双端队列为空,则返回 null。 E peekFirst() // 获取,但不移除此双端队列的最后一个元素;如果此双端队列为空,则返回 null。 E peekLast() // 获取并移除此双端队列表示的队列的头部(即此双端队列的第一个元素);如果此双端队列为空,则返回 null。 E poll() // 获取并移除此双端队列表示的队列的头部(即此双端队列的第一个元素),如有必要将在指定的等待时间内等待可用元素。 E poll(long timeout, TimeUnit unit) // 获取并移除此双端队列的第一个元素;如果此双端队列为空,则返回 null。 E pollFirst() // 获取并移除此双端队列的第一个元素,必要时将在指定的等待时间等待可用元素。 E pollFirst(long timeout, TimeUnit unit) // 获取并移除此双端队列的最后一个元素;如果此双端队列为空,则返回 null。 E pollLast() // 获取并移除此双端队列的最后一个元素,必要时将在指定的等待时间内等待可用元素。 E pollLast(long timeout, TimeUnit unit) // 从此双端队列所表示的堆栈中弹出一个元素。 E pop() // 将元素推入此双端队列表示的栈。 void push(E e) // 将指定的元素插入此双端队列表示的队列中(即此双端队列的尾部),必要时将一直等待可用空间。 void put(E e) // 将指定的元素插入此双端队列的开头,必要时将一直等待可用空间。 void putFirst(E e) // 将指定的元素插入此双端队列的末尾,必要时将一直等待可用空间。 void putLast(E e) // 返回理想情况下(没有内存和资源约束)此双端队列可不受阻塞地接受的额外元素数。 int remainingCapacity() // 获取并移除此双端队列表示的队列的头部。 E remove() // 从此双端队列移除第一次出现的指定元素。 boolean remove(Object o) // 获取并移除此双端队列第一个元素。 E removeFirst() // 从此双端队列移除第一次出现的指定元素。 boolean removeFirstOccurrence(Object o) // 获取并移除此双端队列的最后一个元素。 E removeLast() // 从此双端队列移除最后一次出现的指定元素。 boolean removeLastOccurrence(Object o) // 返回此双端队列中的元素数。 int size() // 获取并移除此双端队列表示的队列的头部(即此双端队列的第一个元素),必要时将一直等待可用元素。 E take() // 获取并移除此双端队列的第一个元素,必要时将一直等待可用元素。 E takeFirst() // 获取并移除此双端队列的最后一个元素,必要时将一直等待可用元素。 E takeLast() // 返回以恰当顺序(从第一个元素到最后一个元素)包含此双端队列所有元素的数组。 Object[] toArray() // 返回以恰当顺序包含此双端队列所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。 // 返回此 collection 的字符串表示形式。 String toString() 下面从LinkedBlockingDeque的创建,添加,取出,遍历这几个方面对LinkedBlockingDeque进行分析 1. 创建 下面以LinkedBlockingDeque(int capacity)来进行说明。 public LinkedBlockingDeque(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); this.capacity = capacity; } 说明:capacity是“链式阻塞队列”的容量。 LinkedBlockingDeque中相关的数据结果定义如下: // “双向队列”的表头 transient Node // “双向队列”的表尾 transient Node // 节点数量 private transient int count; // 容量 private final int capacity; // 互斥锁 , 互斥锁对应的“非空条件notEmpty”, 互斥锁对应的“未满条件notFull” final ReentrantLock lock = newReentrantLock(); private final Condition notEmpty =lock.newCondition(); private final Condition notFull =lock.newCondition(); 说明:lock是互斥锁,用于控制多线程对LinkedBlockingDeque中元素的互斥访问;而notEmpty和notFull是与lock绑定的条件,它们用于实现对多线程更精确的控制。 双向链表的节点Node的定义如下: static final class Node Eitem; // 数据 Node Node Node(E x) { item = x; } } 2. 添加 下面以offer(E e)为例,对LinkedBlockingDeque的添加方法进行说明。 public boolean offer(E e) { return offerLast(e); } offer()实际上是调用offerLast()将元素添加到队列的末尾。 offerLast()的源码如下: public boolean offerLast(E e) { if (e == null) throw new NullPointerException(); // 新建节点 Node final ReentrantLock lock = this.lock; // 获取锁 lock.lock(); try { // 将“新节点”添加到双向链表的末尾 return linkLast(node); }finally { // 释放锁 lock.unlock(); } } 说明:offerLast()的作用,是新建节点并将该节点插入到双向链表的末尾。它在插入节点前,会获取锁;操作完毕,再释放锁。 linkLast()的源码如下: private boolean linkLast(Node // 如果“双向链表的节点数量” > “容量”,则返回false,表示插入失败。 if (count >= capacity) return false; // 将“node添加到链表末尾”,并设置node为新的尾节点 Node node.prev = l; last = node; if (first == null) first = node; else l.next = node; // 将“节点数量”+1 ++count; // 插入节点之后,唤醒notEmpty上的等待线程。 notEmpty.signal(); return true; } 说明:linkLast()的作用,是将节点插入到双向队列的末尾;插入节点之后,唤醒notEmpty上的等待线程。 3. 删除 下面以take()为例,对LinkedBlockingDeque的取出方法进行说明。 public E take() throws InterruptedException{ return takeFirst(); } take()实际上是调用takeFirst()队列的第一个元素。 takeFirst()的源码如下: public E takeFirst() throwsInterruptedException { final ReentrantLock lock = this.lock; // 获取锁 lock.lock(); try { E x; // 若“队列为空”,则一直等待。否则,通过unlinkFirst()删除第一个节点。 while ( (x = unlinkFirst()) == null) notEmpty.await(); return x; }finally { // 释放锁 lock.unlock(); } } 说明:takeFirst()的作用,是删除双向链表的第一个节点,并返回节点对应的值。它在插入节点前,会获取锁;操作完毕,再释放锁。 unlinkFirst()的源码如下: private E unlinkFirst() { // assert lock.isHeldByCurrentThread(); Node if (f == null) return null; // 删除并更新“第一个节点” Node Eitem = f.item; f.item = null; f.next = f; // help GC first = n; if (n == null) last = null; else n.prev = null; // 将“节点数量”-1 --count; // 删除节点之后,唤醒notFull上的等待线程。 notFull.signal(); return item; } 说明:unlinkFirst()的作用,是将双向队列的第一个节点删除;删除节点之后,唤醒notFull上的等待线程。 4. 遍历 下面对LinkedBlockingDeque的遍历方法进行说明。 public Iterator return new Itr(); } iterator()实际上是返回一个Iter对象。 Itr类的定义如下: private class Itr extends AbstractItr { // “双向队列”的表头 Node // 获取“节点n的下一个节点” Node } Itr继承于AbstractItr,而AbstractItr的定义如下: private abstract class AbstractItr implementsIterator // next是下一次调用next()会返回的节点。 Node // nextItem是next()返回节点对应的数据。 EnextItem; // 上一次next()返回的节点。 private Node // 返回第一个节点 abstract Node // 返回下一个节点 abstract Node AbstractItr() { final ReentrantLock lock = LinkedBlockingDeque.this.lock; // 获取“LinkedBlockingDeque的互斥锁” lock.lock(); try { // 获取“双向队列”的表头 next = firstNode(); // 获取表头对应的数据 nextItem = (next == null) ? null : next.item; } finally { // 释放“LinkedBlockingDeque的互斥锁” lock.unlock(); } } // 获取n的后继节点 private Node // Chains of deleted nodes ending in null or self-links // are possible if multiple interior nodes are removed. for (;;) { Node if (s == null) return null; else if (s.item != null) return s; else if (s == n) return firstNode(); else n = s; } } // 更新next和nextItem。 void advance() { final ReentrantLock lock = LinkedBlockingDeque.this.lock; lock.lock(); try { // assert next != null; next = succ(next); nextItem = (next == null) ? null : next.item; } finally { lock.unlock(); } } // 返回“下一个节点是否为null” public boolean hasNext() { return next != null; } // 返回下一个节点 public E next() { if (next == null) throw new NoSuchElementException(); lastRet = next; E x = nextItem; advance(); return x; } // 删除下一个节点 public void remove() { Node if (n == null) throw new IllegalStateException(); lastRet = null; final ReentrantLock lock = LinkedBlockingDeque.this.lock; lock.lock(); try { if (n.item != null) unlink(n); } finally { lock.unlock(); } } } import java.util.*; import java.util.concurrent.*; /* * LinkedBlockingDeque是“线程安全”的队列,而LinkedList是非线程安全的。 * * 下面是“多个线程同时操作并且遍历queue”的示例 * (01)当queue是LinkedBlockingDeque对象时,程序能正常运行。 * (02)当queue是LinkedList对象时,程序会产生ConcurrentModificationException异常。 * *@author skywang */ public class LinkedBlockingDequeDemo1 { // TODO: queue是LinkedList对象时,程序会出错。 //private static Queue private static Queue public static void main(String[] args) { // 同时启动两个线程对queue进行操作! new MyThread("ta").start(); new MyThread("tb").start(); } private static void printAll() { String value; Iterator iter = queue.iterator(); while(iter.hasNext()) { value = (String)iter.next(); System.out.print(value+", "); } System.out.println(); } private static class MyThread extends Thread { MyThread(String name) { super(name); } @Override public void run() { int i = 0; while (i++ < 6) { // “线程名” + "-" + "序号" String val =Thread.currentThread().getName()+i; queue.add(val); // 通过“Iterator”遍历queue。 printAll(); } } } } (某一次)运行结果: ta1, ta1, tb1, tb1, ta1, ta1, tb1, tb1, tb2, tb2, ta2, ta2, ta1, ta1, tb1, tb1, tb2, tb2, ta2, ta2,tb3, tb3, ta3, ta3, ta1, tb1, ta1, tb2, tb1, ta2, tb2, tb3, ta2,ta3, tb3, tb4, ta3, ta4, tb4, ta1, ta4, tb1, tb5, tb2, ta1, ta2, tb1, tb3, tb2, ta3, ta2,tb4, tb3, ta4, ta3, tb5, tb4, ta5, ta4, ta1, tb5, tb1, ta5, tb2, tb6, ta2, ta1, tb3, tb1, ta3, tb2, tb4, ta2,ta4, tb3, tb5, ta3, ta5, tb4, tb6, ta4, ta6, tb5, ta5, tb6, ta6, 结果说明:示例程序中,启动两个线程(线程ta和线程tb)分别对LinkedBlockingDeque进行操作。以线程ta而言,它会先获取“线程名”+“序号”,然后将该字符串添加到LinkedBlockingDeque中;接着,遍历并输出LinkedBlockingDeque中的全部元素。线程tb的操作和线程ta一样,只不过线程tb的名字和线程ta的名字不同。 当queue是LinkedBlockingDeque对象时,程序能正常运行。如果将queue改为LinkedList时,程序会产生ConcurrentModificationException异常。 本章对Java.util.concurrent包中的ConcurrentHashMap类进行详细的介绍。内容包括: ConcurrentLinkedQueue介绍 ConcurrentLinkedQueue原理和数据结构 ConcurrentLinkedQueue函数列表 ConcurrentLinkedQueue源码分析(JDK1.7.0_40版本) ConcurrentLinkedQueue示例 ConcurrentLinkedQueue是线程安全的队列,它适用于“高并发”的场景。 它是一个基于链接节点的无界线程安全队列,按照 FIFO(先进先出)原则对元素进行排序。队列元素中不可以放置null元素(内部实现的特殊节点除外)。 ConcurrentLinkedQueue的数据结构,如下图所示: 说明: 1. ConcurrentLinkedQueue继承于AbstractQueue。 2. ConcurrentLinkedQueue内部是通过链表来实现的。它同时包含链表的头节点head和尾节点tail。ConcurrentLinkedQueue按照 FIFO(先进先出)原则对元素进行排序。元素都是从尾部插入到链表,从头部开始返回。 3. ConcurrentLinkedQueue的链表Node中的next的类型是volatile,而且链表数据item的类型也是volatile。关于volatile,我们知道它的语义包含:“即对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入”。ConcurrentLinkedQueue就是通过volatile来实现多线程对竞争资源的互斥访问的。 // 创建一个最初为空的ConcurrentLinkedQueue。 ConcurrentLinkedQueue() // 创建一个最初包含给定collection 元素的 ConcurrentLinkedQueue,按照此 collection 迭代器的遍历顺序来添加元素。 ConcurrentLinkedQueue(Collection c) // 将指定元素插入此队列的尾部。 boolean add(E e) // 如果此队列包含指定元素,则返回true。 boolean contains(Object o) // 如果此队列不包含任何元素,则返回true。 boolean isEmpty() // 返回在此队列元素上以恰当顺序进行迭代的迭代器。 Iterator // 将指定元素插入此队列的尾部。 boolean offer(E e) // 获取但不移除此队列的头;如果此队列为空,则返回 null。 E peek() // 获取并移除此队列的头,如果此队列为空,则返回 null。 E poll() // 从队列中移除指定元素的单个实例(如果存在)。 boolean remove(Object o) // 返回此队列中的元素数量。 int size() // 返回以恰当顺序包含此队列所有元素的数组。 Object[] toArray() // 返回以恰当顺序包含此队列所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。 下面从ConcurrentLinkedQueue的创建,添加,删除这几个方面对它进行分析。 1 创建 下面以ConcurrentLinkedQueue()来进行说明。 public ConcurrentLinkedQueue() { head = tail = new Node } 说明:在构造函数中,新建了一个“内容为null的节点”,并设置表头head和表尾tail的值为新节点。 head和tail的定义如下: private transient volatile Node private transient volatile Node head和tail都是volatile类型,他们具有volatile赋予的含义:“即对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入”。 Node的声明如下: private static class Node volatile E item; volatile Node Node(E item) { UNSAFE.putObject(this, itemOffset, item); } boolean casItem(E cmp, E val) { return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val); } void lazySetNext(Node UNSAFE.putOrderedObject(this, nextOffset, val); } boolean casNext(Node return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val); } // Unsafe mechanics private static final sun.misc.Unsafe UNSAFE; private static final long itemOffset; private static final long nextOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class k = Node.class; itemOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("item")); nextOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("next")); } catch (Exception e) { throw new Error(e); } } } 说明: Node是个单向链表节点,next用于指向下一个Node,item用于存储数据。Node中操作节点数据的API,都是通过Unsafe机制的CAS函数实现的;例如casNext()是通过CAS函数“比较并设置节点的下一个节点”。 2. 添加 下面以add(E e)为例对ConcurrentLinkedQueue中的添加进行说明。 public boolean add(E e) { return offer(e); } 说明:add()实际上是调用的offer()来完成添加操作的。 offer()的源码如下: public boolean offer(E e) { // 检查e是不是null,是的话抛出NullPointerException异常。 checkNotNull(e); // 创建新的节点 final Node // 将“新的节点”添加到链表的末尾。 for (Node Node // 情况1:q为空 if (q == null) { // CAS操作:如果“p的下一个节点为null”(即p为尾节点),则设置p的下一个节点为newNode。 // 如果该CAS操作成功的话,则比较“p和t”(若p不等于t,则设置newNode为新的尾节点),然后返回true。 // 如果该CAS操作失败,这意味着“其它线程对尾节点进行了修改”,则重新循环。 if (p.casNext(null, newNode)) { if (p != t) // hop two nodes ata time casTail(t, newNode); // Failure is OK. return true; } } // 情况2:p和q相等 else if (p == q) p = (t != (t = tail)) ? t : head; // 情况3:其它 else p = (p != t && t != (t = tail)) ? t : q; } } 说明:offer(E e)的作用就是将元素e添加到链表的末尾。offer()比较的地方是理解for循环,下面区分3种情况对for进行分析。 情况1 -- q为空。这意味着q是尾节点的下一个节点。此时,通过p.casNext(null, newNode)将“p的下一个节点设为newNode”,若设置成功的话,则比较“p和t”(若p不等于t,则设置newNode为新的尾节点),然后返回true。否则的话(意味着“其它线程对尾节点进行了修改”),什么也不做,继续进行for循环。 p.casNext(null, newNode),是调用CAS对p进行操作。若“p的下一个节点等于null”,则设置“p的下一个节点等于newNode”;设置成功的话,返回true,失败的话返回false。 情况2 -- p和q相等。这种情况什么时候会发生呢?通过“情况3”,我们知道,经过“情况3”的处理后,p的值可能等于q。 此时,若尾节点没有发生变化的话,那么,应该是头节点发生了变化,则设置p为头节点,然后重新遍历链表;否则(尾节点变化的话),则设置p为尾节点。 情况3 -- 其它。 我们将p = (p != t && t != (t = tail))? t : q;转换成如下代码。 if (p==t) { p= q; } else { Node t= tail; if (tmp==t) { p=q; }else { p=t; } } 如果p和t相等,则设置p为q。否则的话,判断“尾节点是否发生变化”,没有变化的话,则设置p为q;否则,设置p为尾节点。 checkNotNull()的源码如下: private static void checkNotNull(Object v){ if (v == null) throw new NullPointerException(); } 3. 删除 下面以poll()为例对ConcurrentLinkedQueue中的删除进行说明。 public E poll() { // 设置“标记” restartFromHead: for (;;) { for (Node E item = p.item; // 情况1 // 表头的数据不为null,并且“设置表头的数据为null”这个操作成功的话; // 则比较“p和h”(若p!=h,即表头发生了变化,则更新表头,即设置表头为p),然后返回原表头的item值。 if (item != null && p.casItem(item, null)) { if (p != h) // hop two nodes ata time updateHead(h, ((q = p.next)!= null) ? q : p); return item; } // 情况2 // 表头的下一个节点为null,即链表只有一个“内容为null的表头节点”。则更新表头为p,并返回null。 else if ((q = p.next) == null) { updateHead(h, p); return null; } // 情况3 // 这可能到由于“情况4”的发生导致p=q,在该情况下跳转到restartFromHead标记重新操作。 else if (p == q) continue restartFromHead; // 情况4 // 设置p为q else p = q; } } } 说明:poll()的作用就是删除链表的表头节点,并返回被删节点对应的值。poll()的实现原理和offer()比较类似,下面根将or循环划分为4种情况进行分析。 情况1:“表头节点的数据”不为null,并且“设置表头节点的数据为null”这个操作成功。 p.casItem(item, null) -- 调用CAS函数,比较“节点p的数据值”与item是否相等,是的话,设置节点p的数据值为null。 在情况1发生时,先比较“p和h”,若p!=h,即表头发生了变化,则调用updateHead()更新表头;然后返回删除节点的item值。 updateHead()的源码如下: final void updateHead(Node if (h != p && casHead(h, p)) h.lazySetNext(h); } 说明:updateHead()的最终目的是更新表头为p,并设置h的下一个节点为h本身。 casHead(h,p)是通过CAS函数设置表头,若表头等于h的话,则设置表头为p。 lazySetNext()的源码如下: void lazySetNext(Node UNSAFE.putOrderedObject(this, nextOffset, val); } putOrderedObject()函数,我们在前面一章“TODO”中介绍过。h.lazySetNext(h)的作用是通过CAS函数设置h的下一个节点为h自身,该设置可能会延迟执行。 情况2:如果表头的下一个节点为null,即链表只有一个“内容为null的表头节点”。 则调用updateHead(h, p),将表头更新p;然后返回null。 情况3:p=q 在“情况4”的发生后,会导致p=q;此时,“情况3”就会发生。当“情况3”发生后,它会跳转到restartFromHead标记重新操作。 情况4:其它情况。 设置p=q。 import java.util.*; import java.util.concurrent.*; /* * ConcurrentLinkedQueue是“线程安全”的队列,而LinkedList是非线程安全的。 * * 下面是“多个线程同时操作并且遍历queue”的示例 * (01)当queue是ConcurrentLinkedQueue对象时,程序能正常运行。 * (02)当queue是LinkedList对象时,程序会产生ConcurrentModificationException异常。 * *@author skywang */ public class ConcurrentLinkedQueueDemo1 { // TODO: queue是LinkedList对象时,程序会出错。 //private static Queue private static Queue public static void main(String[] args) { // 同时启动两个线程对queue进行操作! new MyThread("ta").start(); new MyThread("tb").start(); } private static void printAll() { String value; Iterator iter = queue.iterator(); while(iter.hasNext()) { value = (String)iter.next(); System.out.print(value+", "); } System.out.println(); } private static class MyThread extends Thread { MyThread(String name) { super(name); } @Override public void run() { int i = 0; while (i++ < 6) { // “线程名” + "-" + "序号" String val =Thread.currentThread().getName()+i; queue.add(val); // 通过“Iterator”遍历queue。 printAll(); } } } } (某一次)运行结果: ta1, tb1, ta1, ta1, tb1, ta2, ta1, tb1, ta2, tb2, ta1, tb1, ta2, tb2, tb3, ta1, tb1, ta2, tb2, tb3, tb4, ta1, tb1, ta2, tb2, tb3, tb4, tb5, ta1, tb1, ta2, tb2, tb3, tb4, tb5, tb6, tb1, ta2, tb2, tb3, tb4, tb5, tb6, ta1, tb1, ta2, tb2, tb3, tb4, tb5, tb6, ta3, ta1, tb1, ta2, tb2, tb3, tb4, tb5, tb6,ta3, ta4, ta1, tb1, ta2, tb2, tb3, tb4, tb5, tb6,ta3, ta4, ta5, ta1, tb1, ta2, tb2, tb3, tb4, tb5, tb6,ta3, ta4, ta5, ta6, 结果说明:如果将源码中的queue改成LinkedList对象时,程序会产生ConcurrentModificationException异常。 大神总结的目录:http://www.cnblogs.com/skywang12345/p/3323085.html(转载),仅供个人学习,如有抄袭请包容(我也忘了cry....)6) ConcurrentHashMap示例
五、 “JUC集合”05之 ConcurrentSkipListMap
1) 概要
2) ConcurrentSkipListMap介绍
3) ConcurrentSkipListMap原理和数据结构
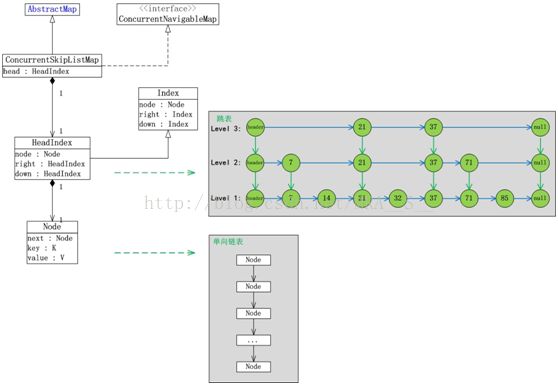
![]()

4) ConcurrentSkipListMap函数列表
5) ConcurrentSkipListMap源码分析(JDK1.7.0_40版本)
6) ConcurrentSkipListMap示例
六、 “JUC集合”06之 ConcurrentSkipListSet
1) 概要
2) ConcurrentSkipListSet介绍
3) ConcurrentSkipListSet原理和数据结构
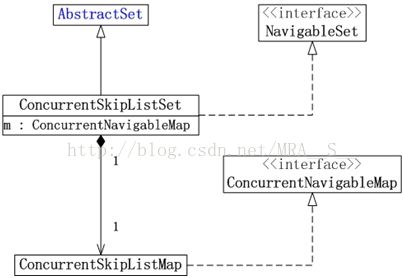
4) ConcurrentSkipListSet函数列表
5) ConcurrentSkipListSet源码(JDK1.7.0_40版本)
6) ConcurrentSkipListSet示例
七、 “JUC集合”07之 ArrayBlockingQueue
1) 概要
2) ArrayBlockingQueue介绍
3) ArrayBlockingQueue原理和数据结构

4) ArrayBlockingQueue函数列表
5) ArrayBlockingQueue源码分析(JDK1.7.0_40版本)
6) ArrayBlockingQueue示例
八、 “JUC集合”08之 LinkedBlockingQueue
1) 概要
2) LinkedBlockingQueue介绍
3) LinkedBlockingQueue原理和数据结构
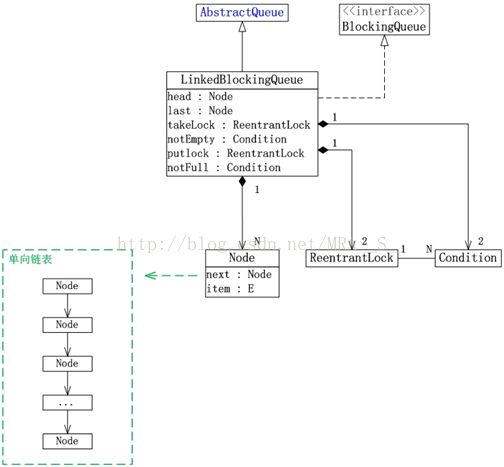
4) LinkedBlockingQueue函数列表
5) LinkedBlockingQueue源码分析(JDK1.7.0_40版本)
6) LinkedBlockingQueue示例
九、 “JUC集合”09之 LinkedBlockingDeque
1) 概要
2) LinkedBlockingDeque介绍
3) LinkedBlockingDeque原理和数据结构
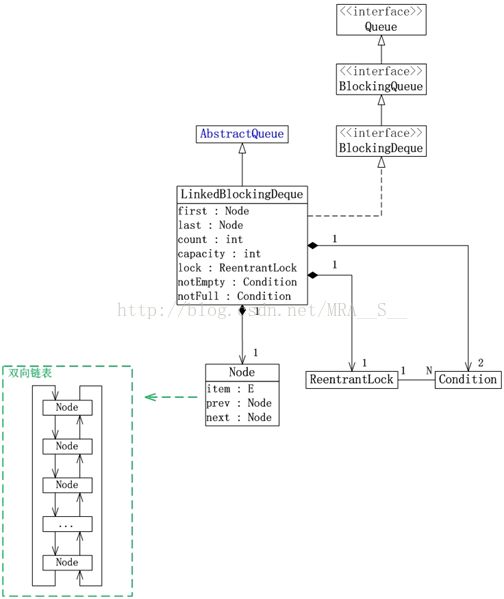
4) LinkedBlockingDeque函数列表
5) LinkedBlockingDeque源码分析(JDK1.7.0_40版本)
6) LinkedBlockingDeque示例
十、 “JUC集合”10之 ConcurrentLinkedQueue
1) 概要
2) ConcurrentLinkedQueue介绍
3) ConcurrentLinkedQueue原理和数据结构
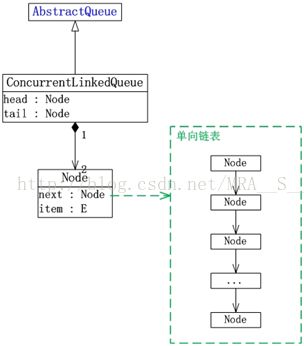
4) ConcurrentLinkedQueue函数列表
5) ConcurrentLinkedQueue源码分析(JDK1.7.0_40版本)
6) ConcurrentLinkedQueue示例