Spark Sql 原理讲解
Spark Sql简介
1.hive和Spark的比较
hive:将sql解析成MR任务。
Spark :修改hive的内存管理、物理计划、执行三个模块
2.两者的解耦
Spark对Hive的强依赖,使用Hive的语法解析器、查询优化器等。
满足Spark一栈式技术栈的设计理念:Spark Sql
3.Spark on Hive 和Hive on Spark
Spark on Hive:只是将hive作为数据仓库、Spark 只做计算引擎。
Hive on Spark :Hive作为数据仓库,并负责一部分的解析、优化计算,Spark 作为hive的底层执行引擎之一还负责一部分的计算。
4.Spark Sql的数据源
常用的有:Hive、ES、HDFS、MySql。
注意:a.RDD-DataFrame-DStream之间都可以相互转化。
b.使用操作,查询Spark,都需要使用SqlContext对象。
c.SparkSql中的大部分的Sql函数都可以使用Hive中的函数
5.Spark on Hive 整合
配置关键:在Spark 的conf 下面配置hive-site.xml中的mysql元数据位置和端口号;
hive.metastore.uris
thrift://node1:9083
Spark Sql的运行架构
Spark Sql语句组成及对应的查询过程

1、解析和执行:
逻辑解析时:project模块、DataSource模块、Filter模块
执行时:Result模块、DataSource模块、Opertion模块
一个查询语句的执行流程:

2、执行流程分为五步:
a.query:执行流程、编写Sql查询语句
b.Parse解析查询语句:解析SQL语句形成逻辑解析树。sql语法是否错误:缺少标准字段、表是否存在等。
c.Bind:将解析后的逻辑解析树与数据库字典进行绑定、形成执行计划树。表的位置、字段信息、执行逻辑存在数据库的字典中,因此需要绑定。
d.Optimize:根据查询引擎提供的多个执行树,筛选出来最优的执行计划。
e.Execute:执行过程operation->DataSource->Result
3、.执行流程的实现原理
SparkSql会将sql进行解析(parse),然后形成一个Tree的操作,即:query->parse->bind->optimize->execute
实现原理:对Tree的操作采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。在整个sql语句的处理过程当中,Tree和Rule相互配合,完成解析、绑定(在SparkSQL中称为Analysis)、优化、物理计划等过程,最终可以生成的可以执行的物理计划。
Tree和Rule


SparkSQL的运行架构
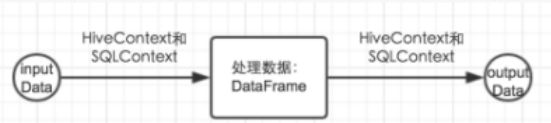
SparkSql架构图
1、架构图解析:
a.把数据读入到SparkSql中,SparkSql进行数据处理或者算法实现。
- 数据源:内置数据源和外部数据源。
SparkSql的实现:HiveContext(官方推荐使用HiveContext);SqlContext
HiveContext:支持Sql语法解析器和HiveSql语法解析器,HiveContext是SqlContext的子类。HiveContext只是用来处理hive数据仓库中读入的操作。
SqlContext:只支持语法解析器,SqlContext可以处理SparkSql能够支持的剩下的所有数据源。
两者处理的粒度是限制在数据的读写上,同是对表级别的操作。
默认为HiveSql语法解析器:可配置切换。
2、组织数据源:DataFrame、DataSet
DataFrame:带schemal的分布式数据表,数据时按照ROW对象进行储存的。
区别:
DataFrame只处理按照Row进行储存的数据,并且只能使用DataFrame中提供的方法,我们只能使用一部分RDD提供的操作。
DataSet让我们能够像操作RDD一样操作Spark Sql中的数据。
b.把处理后的数据输出到相应的输出源中。
3、SparkSql数据源案例
->json数据源:通过读取一json文件创建一个DF,不能是嵌套的json,RDD中的数据类型是String,但数据格式是json格式,通过入去json格式的RDD转成DF。
->非json数据源:非json格式的RDD转换成DF,两种方式:
第一种:反射方式,1.自定义的类必须是public修饰符,2、自定义的类必须实现序列化接口,3.生成的DF的列的顺序与自定义类中字段的顺序不一致,按照字典排序。
第二种:动态创建schema的方式(推荐使用):列的信息可以存储的外部存储系统
->关系型数据库数据源:读取MySql中的数据创建创建一个DF
->Hive数据源
Spark on Hive 读取Hive中的数据创建一个DF
整合SparkSql和Hive
步骤:
1.开启hive的metastore服务hive --service metastore &
2.在Spark的客户端安装包的conf目录下创建一个hive -site.xml文件。
hive.metastore.uris
thrift://node1:9083
Spark Shell测试
读取Hive中的数据:
1.select * from tablename
2.val df = HiveContext.table("tablename")parqent数据源:parquet可以自动推测分区
4.SparkSql数据的存储(储存DataFrame处理后的数据方式)
##1.存储到Hvie中,若tablename表名不存在,自动创建
df.write.saveAsTable("tablename");
##2.可以将数据写入到MySql中
df.rdd().foreachPartition();
##3.存储到HDFS中
usersDF.write.format("json").mode(SaveMode.Ignore).save("hdfs://node1:9000/output/user.json");
format(xxx):以什么格式存储
mode(xxx)以什么方式存储:Ignore、overWrite、append、errorIfExits
save(xxx):存储路径path
5.SqlContext和HiveContext的运行过程
SqlContext运行过程:query->parse->bind->optimize->execute
->sql语句经过sqlParse解析成UnresolvedLogicalPlan
->使用Analyzer集合数据字典(catalog)进行绑定,生成resolvedlogicalPlan
->使用optimizer对resolvedlogicalplan进行优化
->使用SpakrPlan将logicalplan转成physicalplan
->使用prepareForExecutioin()将physicalplan转换成可执行物理计划
->使用execute执行可执行物理计划
->生成SchemaRDD

SparkSql自定义函数及开窗函数
自定义函数 :UDF、UDAF
UDF用户自定义函数:实现继承UDF类重写evaluate方法,在方法中实现逻辑代码
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* hive的自定义函数
*/
public class ItcastFunc extends UDF{
//重载
public String evaluate(String input){
return input.toLowerCase();//将大写字母转换成小写
}
public int evaluate(int a,int b){
return a+b;//计算两个数之和
}
}UDAF:用户定义的聚合函数,接收多条数据,返回一条数据;(进来多条出去一条)
第一种:继承UserDefinedAggregateFuncation(),在Spark中注册UDAF,为其起一个名字。
1.继承UserDefinedAggregateFunction
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
object AverageUserDefinedAggregateFunction extends UserDefinedAggregateFunction {
// 聚合函数的输入数据结构
override def inputSchema: StructType = StructType(StructField("input", LongType) :: Nil)
// 缓存区数据结构
override def bufferSchema: StructType = StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
// 聚合函数返回值数据结构
override def dataType: DataType = DoubleType
// 聚合函数是否是幂等的,即相同输入是否总是能得到相同输出
override def deterministic: Boolean = true
// 初始化缓冲区
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// 给聚合函数传入一条新数据进行处理
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (input.isNullAt(0)) return
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
// 合并聚合函数缓冲区
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 计算最终结果
override def evaluate(buffer: Row): Any = buffer.getLong(0).toDouble / buffer.getLong(1)
}
2.注册使用
import org.apache.spark.sql.SparkSession
object SparkSqlUDAFDemo_001 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkStudy").getOrCreate()
spark.read.json("data/user").createOrReplaceTempView("v_user")
spark.udf.register("u_avg", AverageUserDefinedAggregateFunction)
// 将整张表看做是一个分组对求所有人的平均年龄
spark.sql("select count(1) as count, u_avg(age) as avg_age from v_user").show()
// 按照性别分组求平均年龄
spark.sql("select sex, count(1) as count, u_avg(age) as avg_age from v_user group by sex").show()
}
}第二种:继承Aggregator
update:map端的combiner
merge:reduce端的大聚合
1.继承Aggregator并重写方法
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders}
/**
* 计算平均值
*
*/
object AverageAggregator extends Aggregator[User, Average, Double] {
// 初始化buffer
override def zero: Average = Average(0L, 0L)
// 处理一条新的记录
override def reduce(b: Average, a: User): Average = {
b.sum += a.age
b.count += 1L
b
}
// 合并聚合buffer
override def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// 减少中间数据传输
override def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
override def bufferEncoder: Encoder[Average] = Encoders.product
// 最终输出结果的类型
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
/**
* 计算平均值过程中使用的Buffer
*
* @param sum
* @param count
*/
case class Average(var sum: Long, var count: Long) {
}
case class User(id: Long, name: String, sex: String, age: Long) {
}
2.进行调用
import org.apache.spark.sql.SparkSession
object AverageAggregatorDemo_001 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkStudy").getOrCreate()
import spark.implicits._
val user = spark.read.json("data/user").as[User]
user.select(AverageAggregator.toColumn.name("avg")).show()
}
}UDTF:用来解决输入一条数据输出多条数据的需求
继承GenericUDTF,实现initialize, process, close三个方法。
首先会调用initialize方法进行初始化,此方法返回UDTF的返回行的信息(返回个数,类型)。
初始化完成后,会调用process方法,真正的处理过程在process中,每调用forward产生一条数据,如果产生多列,可以将多列数据放在数组中,然后将该数组传入该forward函数中。
最后调用close方法,最需要清理的方法进行清理。
package com.hadoop.hive.udtf;
import java.util.ArrayList;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class UDTFExplode extends GenericUDTF {
@Override
public void close() throws HiveException {
// TODO Auto-generated method stub
}
@Override
public void process(Object[] args) throws HiveException {
// TODO Auto-generated method stub
String input = args[0].toString();
String[] test = input.split(";");
for (int i = 0; i < test.length; i++) {
try {
String[] result = test[i].split(":");
forward(result);
} catch (Exception e) {
continue;
}
}
}
@Override
public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
if (args.length != 1) {
throw new UDFArgumentLengthException("ExplodeMap takes only one argument");
}
if (args[0].getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("ExplodeMap takes string as a parameter");
}
ArrayList fieldNames = new ArrayList();
ArrayList fieldOIs = new ArrayList();
fieldNames.add("col1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("col2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
} 开窗函数
窗口函数的引入是为了解决 想要既显示聚集前的数据,又要显示聚集后的数据。
开窗函数对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
开窗函数解决的问题,使用sql语句取topN问题
注意:使用开窗函数必须使用HiveContext(集群连接hive元数据-打jar包上传到集群)
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.SparkConf
/**
* SparkStreaming 窗口操作
* reduceByKeyAndWindow
* 每隔窗口滑动间隔时间 计算 窗口长度内的数据,按照指定的方式处理
*/
object WindowOperator {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("windowOperator")
conf.setMaster("local[2]")
val ssc = new StreamingContext(conf,Durations.seconds(5))
ssc.sparkContext.setLogLevel("Error")
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node5",9999)
val words: DStream[String] = lines.flatMap(line=>{line.split(" ")})
val pairWords: DStream[(String, Int)] = words.map(word=>{(word,1)})
// val ds : DStream[(String,Int)] = pairWords.window(Durations.seconds(15),Durations.seconds(5))
/**
* 窗口操作普通的机制
*
* 滑动间隔和窗口长度必须是 batchInterval 整数倍
*/
// val windowResult: DStream[(String, Int)] =
// pairWords.reduceByKeyAndWindow((v1:Int, v2:Int)=>{v1+v2},Durations.seconds(15),Durations.seconds(5))
/**
* 窗口操作优化的机制
*/
ssc.checkpoint("./data/streamingCheckpoint")
val windowResult: DStream[(String, Int)] = pairWords.reduceByKeyAndWindow(
(v1:Int, v2:Int)=>{v1+v2},
(v1:Int, v2:Int)=>{v1-v2},
Durations.seconds(15),
Durations.seconds(5))
windowResult.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}