备忘:Python爬虫(urllib.request和BeautifulSoup)
学习urllib.request和beautifulsoup,并从dribbble和behance上爬取了一些图片,记录一下
一、urllib.request
1. url的构造
构造请求的url遇到的主要问题是如何翻页的问题,dribbble网站是下拉到底自动加载下一页,地址栏的url没有变化,如下:

但是通过检查,我们可以发现request url里关于page的字段,如下:

因此,我们构造如下的url:
for i in range(25): # 最多25页
url = 'https://dribbble.com/shots?page=' + str(i + 1) + '&per_page=24'2. header的构造
不同网页需要的header的内容不一样,参照检查里request header来构造。例如dribbble需要Referer,即从哪一个页面跳转到这个当前页面的,一般填写网站相关页面网址就可以。
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;",
"Referer": "https://dribbble.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36"}3. urllib.request获取页面内容
用url和header实例化一个urllib.request.Request(url, headers),然后url.request.urlopen()访问网页获取数据,使用read()函数即可读取页面内容。
def open_url(url):
# 将Request类实例化并传入url为初始值,然后赋值给req
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;",
"Referer": "https://dribbble.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36"}
req = urllib.request.Request(url, headers=headers)
# 访问url,并将页面的二进制数据赋值给page
res = urllib.request.urlopen(req)
# 将page中的内容转换为utf-8编码
html = res.read().decode('utf-8')
return html这里需要注意的是,有的页面返回的数据是“text/html; charset=utf-8”格式,直接decode('utf-8')编码即可,而有的页面返回的是“application/json; charset=utf-8”格式数据,例如behance:

此时就需要json.loads()来获取数据,得到的是列表,用操作列表的方式拿到html数据:
html = json.loads(res.read())
return html['html']二、BeautifulSoup
BeautifulSoup将复杂的html文档转换为树形结构,每一个节点都是一个对象。
1.创建对象
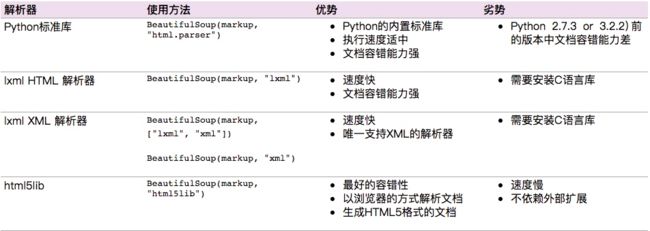
soup = BeautifulSoup(open_url(url), 'html.parser')‘html.parser’是解析器,BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装,常见解析器:
2. 标签选择器
标签选择筛选功能弱但是速度快,通过这种“soup.标签名” 我们就可以获得这个标签的内容,但通过这种方式获取标签,如果文档中有多个这样的标签,返回的结果是第一个标签的内容
# 获取p标签
soup.p
# 获取p标签的属性的两种方法
soup.p.attrs['name']
soup.p['name']
# 获取第一个p标签的内容
soup.p.string
# 获取p标签下所有子标签,返回一个列表
soup.p.contents
# 获取p标签下所有子标签,返回一个迭代器
for i,child in enumerate(soup.p.children):
print(i,child)
# 获取父节点的信息
soup.a.parent
# 获取祖先节点
list(enumerate(soup.a.parents))
# 获取后面的兄弟节点
soup.a.next_siblings
# 获取前面的兄弟节点
soup.a.previous_siblings
# 获取下一个兄弟标签
soup.a.next_sibling
# 获取上一个兄弟标签
souo.a.previous_sinbling3. 标准选择器
find_all(name,attrs,recursive,text,**kwargs)可以根据标签名,属性,内容查找文档,返回一个迭代器,例如:
# 获取所有class为js-project-module--picture的所有img标签,并选择每个标签的src构成一个列表
image.src = [item['src'] for item in soup.find_all('img', {"class": "js-project-module--picture"})]
# .string获取div的内容,strip()去除前后空格
desc = soup.find_all('div', {"class": "js-basic-info-description"})
if desc:
image.desc = [item.string.strip() for item in desc]find(name,attrs,recursive,text,**kwargs),返回匹配的第一个元素
其他一些类似的用法:
find_parents()返回所有祖先节点,find_parent()返回直接父节点
find_next_siblings()返回后面所有兄弟节点,find_next_sibling()返回后面第一个兄弟节点
find_previous_siblings()返回前面所有兄弟节点,find_previous_sibling()返回前面第一个兄弟节点
find_all_next()返回节点后所有符合条件的节点, find_next()返回第一个符合条件的节点
find_all_previous()返回节点后所有符合条件的节点, find_previous()返回第一个符合条件的节点
三、从dribbble爬取图片完整代码
1.批量获取图片页面链接
# -*- coding: utf-8 -*-
import random
import urllib.request
from bs4 import BeautifulSoup
import os
import time
def open_url(url):
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;",
"Referer": "https://dribbble.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36"}
req = urllib.request.Request(url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
return html
# 打开/创建“dribbble_list.txt”文件,O_CREAT:不存在即创建、O_WRONLY:只写、O_APPEND:追加
fd = os.open('dribbble_list.txt', os.O_CREAT | os.O_WRONLY | os.O_APPEND)
for i in range(25):
url = 'https://dribbble.com/shots?page=' + str(i + 1) + '&per_page=24'
soup = BeautifulSoup(open_url(url), 'html.parser')
srcs = soup.find_all('a', {"class": "dribbble-link"})
src_list = [src['href'] for src in srcs]
for src in src_list:
os.write(fd, bytes(src, 'UTF-8'))
os.write(fd, bytes('\n', 'UTF-8'))
time.sleep(random.random()*5)
2. 获取图片和信息
import os
import random
import urllib.request
import re
import time
from bs4 import BeautifulSoup
class Image:
title = ''
src = ''
desc = []
tags = []
colors = []
view = []
like = []
save = []
def open_url(url):
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;",
"Referer": "https://dribbble.com/shots",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36"}
try:
req = urllib.request.Request(url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
except:
return None
return html
def get_number(x):
return int(re.sub('\D', "", x))
def get_img_info(html):
# 实例化一张图
image = Image()
soup = BeautifulSoup(html, 'html.parser')
# 标题
image.title = soup.find('div', {"class": "slat-header"}).find('h1').string.strip()
# 地址
image.src = soup.find('div', {"class": "detail-shot"}).find('img')['src']
# 描述
desc = soup.find('div', {"class": "shot-desc"})
if desc:
image.desc = [item.string.strip() for item in desc.find_all(text=True)]
# 标签
image.tags = [item.string for item in soup.find_all('a', {"rel": "tag"})]
# 颜色
image.colors = [item.string for item in soup.find_all('a', {"style": re.compile('background-color.*')})]
# 浏览量
view = soup.find('div', {"class": "shot-views"})
if view:
image.view = [str(get_number(item)) for item in view.stripped_strings]
# 喜欢
like = soup.find('div', {"class": "shot-likes"})
if like:
image.like = [str(get_number(item)) for item in like.stripped_strings]
# 收藏
save = soup.find('div', {"class": "shot-saves"})
if save:
image.save = [str(get_number(item)) for item in save.stripped_strings]
return image
def save_text(root_path, img, num):
text = {
'src': img.src,
'desc': ';'.join(img.desc),
'tags': ';'.join(img.tags),
'colors': ';'.join(img.colors),
'score': ';'.join([img.title, ''.join(img.view), ''.join(img.like), ''.join(img.save)])
}
text_list = ['src', 'desc', 'tags', 'colors', 'score']
for item in text_list:
save_path = root_path + item + '.txt'
fd = os.open(save_path, os.O_CREAT | os.O_WRONLY | os.O_APPEND)
write_str = str(num).zfill(3) + ' ' + text[item] + '\n'
os.write(fd, bytes(write_str, 'UTF-8'))
os.close(fd)
def read_dribbble_data(data_folder):
import pandas as pd
import os
columns = ['url']
df = pd.read_csv(os.path.join(data_folder, 'dribbble_list.txt'), names=columns)
return df
def to_url(img_url):
return 'https://dribbble.com{img_url}'.format(img_url=img_url)
if __name__ == '__main__':
data_folder = './'
df = read_dribbble_data(data_folder)
urls = map(to_url, df['url'].values)
for i, url in enumerate(urls):
print(url)
# 获取并解析网页
html = open_url(url)
if html:
image = get_img_info(open_url(url))
# 获取并保存图片
# save_path_img = 'img/' + image.title + '.jpg'
save_path_img = 'img/' + str(i+556).zfill(3) + '.jpg'
urllib.request.urlretrieve(image.src, save_path_img)
# 保存“标题 地址 描述 标签 颜色 浏览量 喜欢 收藏”
save_path_text_root = 'dribbble_text/'
save_text(save_path_text_root, img=image, num=i+556)
time.sleep(random.random()*5)
四、从behance爬取图片完整代码
1. 批量获取图片页面链接
# -*- coding: utf-8 -*-
import random
import urllib.request
from bs4 import BeautifulSoup
import os
import time
import json
def open_url(url):
headers = {"Accept": "*/*",
"Referer": "https://www.behance.net/search?field=48&content=projects&sort=appreciations&time=week",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36",
"Host": "www.behance.net",
"Connection": "keep-alive",
"X-BCP": "523bc8eb-c6a4-4eeb-a73d-0bf9ec1c06d9",
"X-NewRelic-ID": "VgUFVldbGwACXFJSBAUF",
"X-Requested-With": "XMLHttpRequest"}
req = urllib.request.Request(url, headers=headers)
res = urllib.request.urlopen(req)
html = json.loads(res.read())
return html['html']
fd = os.open('behance_list.txt', os.O_CREAT | os.O_WRONLY | os.O_APPEND)
for i in range(200):
url = 'https://www.behance.net/search?ordinal=' + str((i+100) * 48) + '&per_page=48&field=48&content=projects&sort=appreciations&time=week&location_id=×tamp=0&mature=0'
print(url)
soup = BeautifulSoup(open_url(url), 'html.parser')
srcs = soup.find_all('a', {"class": "js-project-cover-image-link"})
src_list = [src['href'] for src in srcs]
for src in src_list:
os.write(fd, bytes(src, 'UTF-8'))
os.write(fd, bytes('\n', 'UTF-8'))
time.sleep(random.random()*5)
os.close(fd)2. 获取图片和信息
# -*- coding: utf-8 -*-
import os
import random
import urllib.request
import re
import time
from bs4 import BeautifulSoup
class Image:
title = ''
src = []
desc = []
tags = []
data = []
def open_url(url):
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Referer": "https://www.behance.net/gallery/70675447/YELLOWSTONE",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36",
"Host": "www.behance.net",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": 1,
"Cookie": "巴啦啦小魔仙全身变"
}
try:
req = urllib.request.Request(url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
except:
return None
return html
def get_number(x):
return int(re.sub('\D', "", x))
def get_img_info(html):
# 实例化一张图
image = Image()
soup = BeautifulSoup(html, 'html.parser')
# 地址
image.src = [item['src'] for item in soup.find_all('img', {"class": "js-project-module--picture"})]
# 标题
image.title = soup.find('div', {"class": "js-project-title"}).string.strip()
# 描述
desc = soup.find_all('div', {"class": "js-basic-info-description"})
if desc:
image.desc = [item.string.strip() for item in desc]
# 标签
tags = soup.find_all('a', {"class": "object-tag"})
if tags:
image.tags = [item.string.strip() for item in tags]
# 浏览 点赞 评论
data = soup.find_all('div', {"class": "project-stat"})
if data:
image.data = [item.string.strip() for item in data][:2]
return image
def save_text(root_path, img, num):
text = {
'title': image.title.replace(' ', '_'),
'score': ' '.join(img.data),
'desc': ';' + (';'.join(img.desc)).replace('\n', ';'),
'tags': ';' + ';'.join(img.tags),
'src': ';' + ';'.join(img.src)
}
text_list = ['title', 'score', 'desc', 'tags', 'src']
for item in text_list:
save_path = root_path + item + '.txt'
fd = os.open(save_path, os.O_CREAT | os.O_WRONLY | os.O_APPEND)
write_str = str(num).zfill(5) + ' ' + text[item] + '\n'
os.write(fd, bytes(write_str, 'UTF-8'))
os.close(fd)
def read_dribbble_data(data_folder):
import pandas as pd
import os
columns = ['url']
df = pd.read_csv(os.path.join(data_folder, 'behance_list.txt'), names=columns)
return df
if __name__ == '__main__':
data_folder = './'
urls = read_dribbble_data(data_folder)['url'].values
for i, url in enumerate(urls):
print(url)
# 获取并解析网页
html = open_url(url)
if html:
image = get_img_info(open_url(url))
# 获取并保存图片
for j, src in enumerate(image.src):
save_path_img = './behance_img/' + str(i).zfill(5) + '_' + str(j).zfill(3) + src[-4:]
urllib.request.urlretrieve(src, save_path_img)
time.sleep(random.random()*3)
# 保存“标题 浏览量 喜欢 收藏 描述 标签 ”
save_path_text_root = './behance_text/'
save_text(save_path_text_root, img=image, num=i)
time.sleep(random.random()*5)