【ANTLR学习笔记】1:在IDEA中生成简易加减表达式的解析器
ANTLR可以支持生成多种编程语言为载体的Lexer和Parser,可以自动处理LL(*)文法(注意不是LR文法,这里ANTLR实际上是Another Tool for Language Recognition的缩写),目前先在IDEA中用最方便的插件学习一下生成Java版本的。
IDEA中的配置
首先在IDEA中安装插件,从File->Setting->Plugins搜索并安装ANTLR v4 grammer plugin,并重启IDEA。
创建一个项目模块,如果项目模块不是Maven格式,要将其转换。对于干净的新创建的模块直接右键Add Framework Support->Maven即可。
语法规则定义
在main/resource目录下添加calculator.g4文件,这是语法规则文件:
grammar calculator;
start:
expression EOF
;
expression:
| INT
| expression (PLUS | MINUS) expression
;
PLUS : '+';
MINUS : '-';
INT : '0'..'9'+;
注意其中grammer要和.g4文件名一致。
接下来要检查定义的语法规则,这步不是必须的。右键这个.g4文件的start这一块(注意在不同的位置右键,出来的菜单是不同的),选择Test Rule Start,可以看到解析的Parse Tree。在左侧Input下面的框内提供输入,即可看到实时的Parse Tree:

解析器程序生成
右键这个.g4文件,选择Configure ANTLR,对其配置:
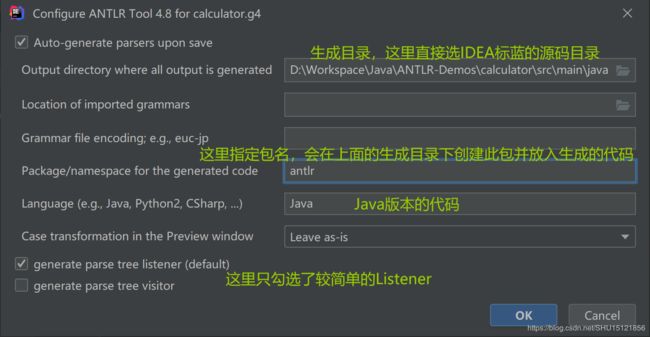
配置完成后,右键这个.g4文件,选择Generate ANTLR Recognizer即可自动生成解析程序:

Maven安装ANTLR4
虽然生成了解析程序,但是还没有安装ANTLR,所以里面导入包的地方就会报错。在pom.xml中的dependencies标签下添加:
<dependency>
<groupId>org.antlrgroupId>
<artifactId>antlr4-runtimeartifactId>
<version>4.8-1version>
dependency>
然后自动进行依赖下载即可。注意这里的版本要和ANTLR语法到代码的构建工具版本一致(当然不一致后面运行时会报错回来修改版本号就行)。
调用执行
这里在Main.java主方法中调用Lexer和Parser进行解析,并得到Parse Tree:
import antlr.calculatorLexer;
import antlr.calculatorParser;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
public class Main {
public static void main(String[] args) {
// 将输入字符串化为输入流(也可以是ANTLRInputStream)然后传入词法分析器
calculatorLexer lexer = new calculatorLexer(CharStreams.fromString("1+2+5"));
// 转换成Token流传入语法分析器
calculatorParser parser = new calculatorParser(new CommonTokenStream(lexer));
// 因为词法文件里最外层定义了start规则,这里就能从parser.start()解析并获取规则树
calculatorParser.StartContext tree = parser.start();
// 将其输出
System.out.println(tree.toStringTree(parser));
}
}
运行结果:
(start (expression (expression (expression 1) + (expression 2)) + (expression 5)) )
如果只想把Parser做完,只要执行parser.start()而不使用其返回值就可以,当输入不符合语法时候会报错。
特别注意,这里StartContext和start()只是因为当时.g4文件中定义了start规则才有的。这个规则名也不是必须叫这个的,如果这个规则改名为sta,那么这两个东西也会被StaContext和.sta()取代。
参考阅读
[1] Interpreter Assignment 1
[2] antlr4操作入门(java版本)
补充
使用ANTLR之类的工具就是为了省去手写编译器/解析器前端的麻烦且低效的工作,如果不是做自己的DSL解析(或者类似的东西),手写.g4文件也是非常麻烦而且不必要的,在antlr/grammars-v4这个仓库里集成了大家总结的各个语言的语法文件,可以直接拿来用。
一个问题就是这些文件的顶层规则(上文中的start规则)命名不一,而且很多不是放在文件开头的,一个技巧就是直接在IDEA中打开,然后看看右边滚动条:

这里是IDEA的静态分析器报告的,意在说明这条规则没有被使用,那么显然它就是顶层规则了。用这条规则尝试解析项目作业的测试用例:

非常好用。
而且从C.g4文件后面的Token声明来看,这里面是已经做了对嵌入式C的拓展了的。
发现了一点问题,关于解析C语言#define的问题见这个issue中的讨论。