ICRA 2020 | 实时语义立体匹配
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

本文由知乎作者青青韶华授权转载,不得擅自二次转载。原文链接:https://zhuanlan.zhihu.com/p/121010657
论文题目:Real-Time Semantic Stereo Matching
论文地址:https://arxiv.org/abs/1910.00541v2
本文介绍在ICRA 2020上发表的论文《Real-Time Semantic Stereo Matching》,这篇论文提出了第一个实时的语义立体匹配网络RTSSNet,即将语义分割和双目深度估计两个任务用同一个端到端的网络来实现,并且达到实时的速度,在2080ti上最快可以达到60FPS。
ICRA是机器人的顶级会议,上面也会发表一些关于立体匹配的论文,这相当于是机器视觉领域。本文可以和在ICRA 2019上发表的AnyNet对比来看。
Motivation
论文的动机来源于实际场景的需求。场景理解在机器人、自主导航、增强现实和许多其他领域都是至关重要的。为了完成这项任务,一个可以自动理解场景的智能体必须推断感知场景的3D结构(即知道它看到的东西在哪,深度信息)和它的内容(即知道它看到了什么,语义信息)。为了解决这两个问题,一个更好的选择是利用神经网络从双目图像中推断语义分割和深度估计信息。因此,本文将语义分割任务和双目深度估计任务合二为一,并且做到了实时的速度。
Method
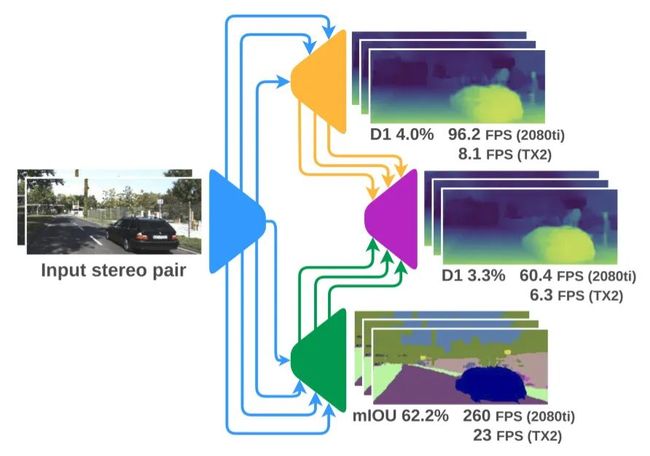
上图是RTSSNet的简略框架图,主要分为四个模块:
1. 特征提取模块(蓝色),语义分割和立体匹配共享;
2. 视差估计模块(橙色),先估计一个粗糙的初始视差图;
3. 语义分割模块(绿色);
4. 协同视差优化模块(紫色),利用语义信息优化初始视差图。

(1)共享特征提取模块
特征提取模块类似一个编码结构,通过逐步的卷积和池化操作,将分辨率降至1/4,1/8,1/16,1/32,以便为两个任务提取通用的并且丰富的特征表示。特征图的通道数分别对应2c,4c,8c,16c。这里c取1对于视差估计就足够了,但是对于语义分割还有所欠缺。
(2)视差估计模块
视差估计模块类似解码结构,从各个分辨率的特征图开始预测视差,这里选取了1/4,1/8,1/16三种尺度(1/32由于分辨率太小而舍去),它们分别对应视差估计的三个阶段。从分辨率最小的开始作为第一阶段,利用左右图特征构建cost volume,再利用3D卷积聚合预测视差,stage1预测的是最粗糙的视差图。之后的stage2和stage3都是估计视差残差,和AnyNet类似,因为残差更容易学习和计算。利用残差和初始视差逐步优化视差。
(3)语义分割模块
语义分割类似深度估计模块,也是一个从粗糙到精细的逐阶段优化的过程,同样是3个阶段,与视差估计网络形成对称结构。
(4)协同视差优化模块
理论上前三步已经实现了实时的深度估计和语义分割,不过深度估计的精度还是太低了。因此在时间允许的条件下,可以进一步利用语义分割的特征来优化视差图。由于语义分割和视差估计两个模块是对称的,利用相同阶段两个网络的特征可以得到另外3个阶段的精修视差图。
(5)目标函数
RTSSNet一共输出9个结果:3个粗糙的视差图 ,3个语义分割结果 ,3个精修的视差图 ,分别对应三个阶段 。视差图都采用smooth L1 loss,而语义分割采用多类交叉熵。由于loss种类很多,作者提出了一种双层损失权重策略:
其中 是总的loss, 对应三个阶段,分别是1/4,1/2和1; 分别对应三种结果,其值为1,2,2。语义分割交叉熵也根据类概率加权,以减轻不平衡数据集的影响。此外,对于多任务学习,作者希望语义分割不受内部权重机制的选择和类分布的影响。因此,设计了以下称重方案:
其中 Wj是 j 个类别的权重,N是类别总数,P是类别概率,k是控制类别权重方差的参数。这么做是为了避免类别不均衡造成的影响。最后,在粗糙的语义标注情况下,根据ground truth中剩余未标记区域的百分比对分割损失进行重新加权得到:
其中 设为0.1, 分别是未标记像素个数和总像素个数。
Experiments
作者在KITTI数据集上进行评测,首先看RTSSNet和AnyNet的比较:
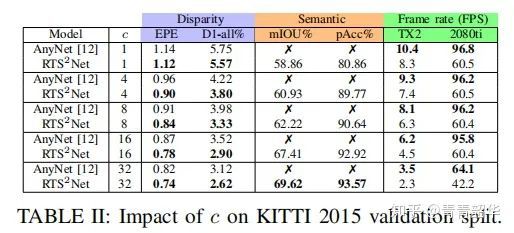
可以看到在KITTI2015验证集上,RTSSNet在c取不同值时准确率都要高一些,但是速度会慢不少,毕竟RTSSNet还需要输出一个语义分割的结果。
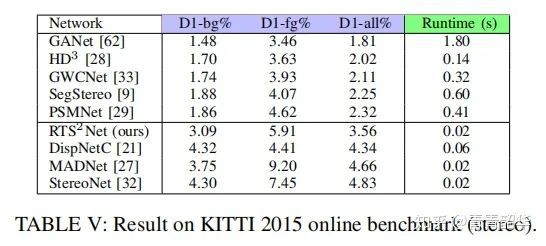
在KITTI 2015基准测试上,比SOTA网络的速度要快很多;和实时性网络相比,比MADNet和StereoNet的准确率都要高一些,在实时网络中表现SOTA。
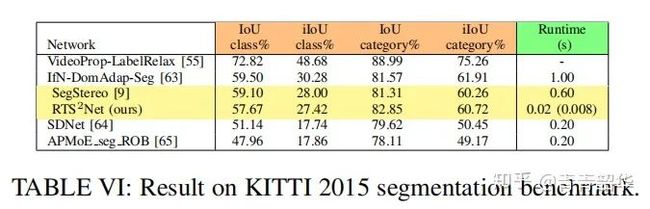
在语义分割上比SegStereo准确率还略高,但是速度要快很多。不过相比于一些实时分割网络,还是要差一些。
Conclusion
实时语义分割已经有很多工作了,但是实时双目深度估计在最近才开始有较多的相关工作,仍然处于一个起步的阶段,还有很多值得挖掘的地方。这篇论文首次将二者结合起来,在实时网络中的性能都是很不错的,这也是实际应用场景中需要的速度和准确率兼并的模型。
上述内容,如有侵犯版权,请联系作者,会自行删文。
推荐阅读:
吐血整理|3D视觉系统化学习路线
那些精贵的3D视觉系统学习资源总结(附书籍、网址与视频教程)
超全的3D视觉数据集汇总
大盘点|6D姿态估计算法汇总(上)
大盘点|6D姿态估计算法汇总(下)
机器人抓取汇总|涉及目标检测、分割、姿态识别、抓取点检测、路径规划
汇总|3D点云目标检测算法
汇总|3D人脸重建算法
那些年,我们一起刷过的计算机视觉比赛
总结|深度学习实现缺陷检测
深度学习在3-D环境重建中的应用
汇总|医学图像分析领域论文
大盘点|OCR算法汇总
汇总|3D点云目标检测算法
重磅!3DCVer-知识星球和学术交流群已成立
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导,700+的星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
欢迎加入我们公众号读者群一起和同行交流,目前有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加群或投稿