从零开始入门 K8s | 手把手带你理解 etcd
作者 | 曾凡松(逐灵) 阿里云容器平台高级技术专家
本文整理自《CNCF x Alibaba 云原生技术公开课》第 16 讲。
导读:etcd 是用于共享配置和服务发现的分布式、一致性的 KV 存储系统。本文从 etcd 项目发展所经历的几个重要时刻开始,为大家介绍了 etcd 的总体架构及其设计中的基本原理。希望能够帮助大家更好的理解和使用 etcd。
一、etcd 项目的发展历程
etcd 诞生于 CoreOS 公司,它最初是用于解决集群管理系统中 OS 升级的分布式并发控制以及配置文件的存储与分发等问题。基于此,etcd 被设计为提供高可用、强一致的小型 keyvalue 数据存储服务。
项目当前隶属于 CNCF 基金会,被 AWS、Google、Microsoft、Alibaba 等大型互联网公司广泛使用。

最初,在 2013 年 6 月份由 CoreOS 公司向 GitHub 中提交了第一个版本的初始代码。
到了 2014 年的 6 月,社区发生了一件事情,Kubernetes v0.4 版本发布。这里有必要介绍一下 Kubernetes 项目,它首先是一个容器管理平台,由谷歌开发并贡献给社区,因为它集齐了谷歌在容器调度以及集群管理等领域的多年经验,从诞生之初就备受瞩目。在 Kubernetes v0.4 版本中,它使用了 etcd 0.2 版本作为实验核心元数据的存储服务,自此 etcd 社区得到了飞速的发展。
很快,在 2015 年 2 月份,etcd 发布了第一个正式的稳定版本 2.0。在 2.0 版本中,etcd 重新设计了 Raft 一致性算法,并为用户提供了一个简单的树形数据视图,在 2.0 版本中 etcd 支持每秒超过 1000 次的写入性能,满足了当时绝大多数的应用场景需求。2.0 版本发布之后,经过不断的迭代与改进,其原有的数据存储方案逐渐成为了新时期的性能瓶颈,之后 etcd 启动了 v3 版本的方案设计。
2017 年 1 月份的时候,etcd 发布了 3.1 版本,v3 版本方案基本上标志着 etcd 技术上全面成熟。在 v3 版本中 etcd 提供了一套全新的 API,重新实现了更高效的一致性读取方法,并且提供了一个 gRPC 的 proxy 用于扩展 etcd 的读取性能。同时,在 v3 版本的方案中包含了大量的 GC 优化,在性能优化方面取得了长足的进步,在该版本中 etcd 可以支持每秒超过 10000 次的写入。
2018 年,CNCF 基金会下的众多项目都使用了 etcd 作为其核心的数据存储。据不完全统计,使用 etcd 的项目超过了 30 个,在同年 11 月份,etcd 项目自身也成为了 CNCF 旗下的孵化项目。进入 CNCF 基金会后,etcd 拥有了超过 400 个贡献组,其中包含了来自 AWS、Google、Alibaba 等 8 个公司的 9 个项目维护者。
2019 年,etcd 即将发布全新的 3.4 版本,该版本由 Google、Alibaba 等公司联合打造,将进一步改进 etcd 的性能及稳定性,以满足在超大型公司使用中苛刻的场景要求。
二、架构及内部机制解析
总体架构
etcd 是一个分布式的、可靠的 key-value 存储系统,它用于存储分布式系统中的关键数据,这个定义非常重要。
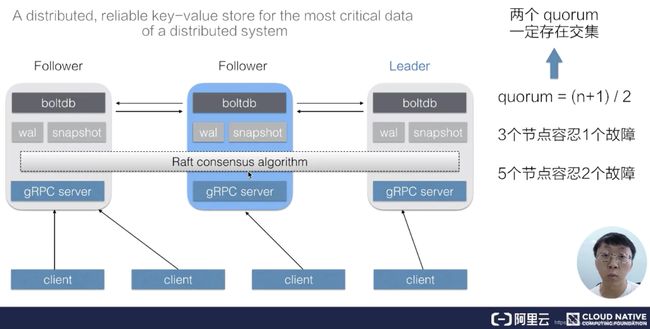
一个 etcd 集群,通常会由 3 个或者 5 个节点组成,多个节点之间通过 Raft 一致性算法的完成分布式一致性协同,算法会选举出一个主节点作为 leader,由 leader 负责数据的同步与数据的分发。当 leader 出现故障后系统会自动地选取另一个节点成为 leader,并重新完成数据的同步。客户端在多个节点中,仅需要选择其中的任意一个就可以完成数据的读写,内部的状态及数据协同由 etcd 自身完成。
在 etcd 整个架构中,有一个非常关键的概念叫做 quorum,quorum 的定义是 (n 1)/2,也就是说超过集群中半数节点组成的一个团体,在 3 个节点的集群中,etcd 可以容许 1 个节点故障,也就是只要有任何 2 个节点可用,etcd 就可以继续提供服务。同理,在 5 个节点的集群中,只要有任何 3 个节点可用,etcd 就可以继续提供服务,这也是 etcd 集群高可用的关键。
在允许部分节点故障之后继续提供服务,就需要解决一个非常复杂的问题:分布式一致性。在 etcd 中,该分布式一致性算法由 Raft 一致性算法完成,这个算法本身是比较复杂的有机会再详细展开,这里仅做一个简单的介绍以方便大家对其有一个基本的认知。Raft 一致性算法能够工作的一个关键点是:任意两个 quorum 的成员之间一定会有一个交集(公共成员),也就是说只要有任意一个 quorum 存活,其中一定存在某一个节点(公共成员),它包含着集群中所有的被确认提交的数据。正是基于这一原理,Raft 一致性算法设计了一套数据同步机制,在 Leader 任期切换后能够重新同步上一个 quorum 被提交的所有数据,从而保证整个集群状态向前推进的过程中保持数据的一致。

etcd 内部的机制比较复杂,但 etcd 给客户提供的接口是简单直接的。如上图所示,我们可以通过 etcd 提供的客户端去访问集群的数据,也可以直接通过 http 的方式(类似 curl 命令)直接访问 etcd。在 etcd 内部,其数据表示也是比较简单的,我们可以直接把 etcd 的数据存储理解为一个有序的 map,它存储着 key-value 数据。同时 etcd 为了方便客户端去订阅数据的变更,也支持了一个 watch 机制,通过 watch 实时地拿到 etcd 中数据的增量更新,从而实现与 etcd 中的数据同步等业务逻辑。
API 介绍
接下来我们看一下 etcd 提供的接口,这里将 etcd 的接口分为了 5 组:

- 第一组是 Put 与 Delete。上图可以看到 put 与 delete 的操作都非常简单,只需要提供一个 key 和一个 value,就可以向集群中写入数据了,删除数据的时候只需要指定 key 即可;
- 第二组是查询操作。etcd 支持两种类型的查询:第一种是指定单个 key 的查询,第二种是指定的一个 key 的范围;
- 第三组是数据订阅。etcd 提供了 Watch 机制,我们可以利用 watch 实时订阅到 etcd 中增量的数据更新,watch 支持指定单个 key,也可以指定一个 key 的前缀,在实际应用场景中的通常会采用第二种形势;
- 第四组事务操作。etcd 提供了一个简单的事务支持,用户可以通过指定一组条件满足时执行某些动作,当条件不成立的时候执行另一组操作,类似于代码中的 if else 语句,etcd 确保整个操作的原子性;
- 第五组是 Leases 接口。Leases 接口是分布式系统中常用的一种设计模式,其用法后面会具体展开。
数据版本机制
要正确使用 etcd 的 API,必须要知道内部对应数据版本号的基本原理。
首先 etcd 中有个 term 的概念,代表的是整个集群 Leader 的任期。当集群发生 Leader 切换,term 的值就会 1。在节点故障,或者 Leader 节点网络出现问题,再或者是将整个集群停止后再次拉起,都会发生 Leader 的切换。
第二个版本号叫做 revision,revision 代表的是全局数据的版本。当数据发生变更,包括创建、修改、删除,其 revision 对应的都会 1。特别的,在集群中跨 Leader 任期之间,revision 都会保持全局单调递增。正是 revision 的这一特性,使得集群中任意一次的修改都对应着一个唯一的 revision,因此我们可以通过 revision 来支持数据的 MVCC,也可以支持数据的 Watch。
对于每一个 KeyValue 数据节点,etcd 中都记录了三个版本:
- 第一个版本叫做 create_revision,是 KeyValue 在创建时对应的 revision;
- 第二个叫做 mod_revision,是其数据被操作的时候对应的 revision;
- 第三个 version 就是一个计数器,代表了 KeyValue 被修改了多少次。
这里可以用图的方式给大家展示一下:
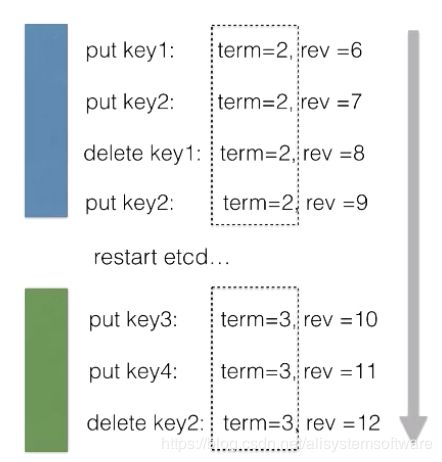
在同一个 Leader 任期之内,我们发现所有的修改操作,其对应的 term 值始终都等于 2,而 revision 则保持单调递增。当重启集群之后,我们会发现所有的修改操作对应的 term 值都变成了 3。在新的 Leader 任期内,所有的 term 值都等于3,且不会发生变化,而对应的 revision 值同样保持单调递增。从一个更大的维度去看,可以发现在 term=2 和 term=3 的两个 Leader 任期之间,数据对应的 revision 值依旧保持了全局单调递增。
mvcc & streaming watch
了解 etcd 的版本号控制后,接下来如何使用 etcd 多版本号来实现并发控制以及数据订阅(Watch)。
在 etcd 中支持对同一个 Key 发起多次数据修改,每次数据修改都对应一个版本号。etcd 在实现上记录了每一次修改对应的数据,也就就意味着一个 key 在 etcd 中存在多个历史版本。在查询数据的时候如果不指定版本号,etcd 会返回 Key 对应的最新版本,当然 etcd 也支持指定一个版本号来查询历史数据。

因为 etcd 将每一次修改都记录了下来,使用 watch 订阅数据时,可以支持从任意历史时刻(指定 revision)开始创建一个 watcher,在客户端与 etcd 之间建立一个数据管道,etcd 会推送从指定 revision 开始的所有数据变更。etcd 提供的 watch 机制保证,该 Key 的数据后续的被修改之后,通过这个数据管道即时的推送给客户端。
如下图所示,etcd 中所有的数据都存储在一个 b tree 中(灰色),该 b tree 保存在磁盘中,并通过 mmap 的方式映射到内存用来支持快速的访问。灰色的 b tree 中维护着 revision 到 value 的映射关系,支持通过 revision 查询对应的数据。因为 revision 是单调递增的,当我们通过 watch 来订阅指定 revision 之后的数据时,仅需要订阅该 b tree 的数据变化即可。
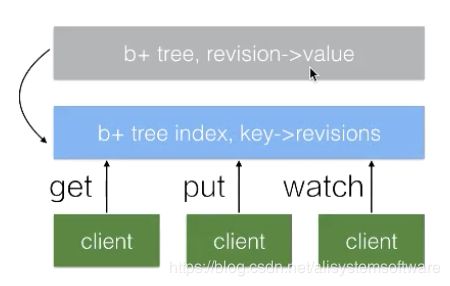
在 etcd 内部还维护着另外一个 btree(蓝色),它管理着 key 到 revision 的映射关系。当客户端使用 key 查询数据时,首先需要经过蓝色的 btree 将 key 转化为对应的 revision,再通过灰色的 btree 查询到对应的数据。
细心的读者会发现,etcd 将每一次修改都记录下来会导致数据持续增长,这会带来内存及磁盘的空间消耗,同时也会影响 b tree 的查询效率。为了解决这一问题,在 etcd 中会运行一个周期性的 Compaction 的机制来清理历史数据,将一段时间之前的同一个 Key 的多个历史版本数据清理掉。最终的结果是灰色的 b tree 依旧保持单调递增,但可能会出现一些空洞。
mini-transactions
在理解了 mvcc 机制及 watch 机制之后,继续看 etcd 提供的 mini-transactions 机制。etcd 的 transaction 机制比较简单,基本可以理解为一段 if-else 程序,在 if 中可以提供多个操作,如下图所示:

If 里面写了两个条件,当 Value(key1) 大于 “bar” 并且 Version(key1) 的版本等于 2 的时候,执行 Then 里面指定的操作:修改 Key2 的数据为 valueX,同时删除 Key3 的数据。如果不满足条件,则执行另外一个操作:Key2 修改为 valueY。
在 etcd 内部会保证整个事务操作的原子性。也就是说 If 操作所有的比较条件,其看到的视图一定是一致的。同时它能够确保多个操作的原子性不会出现 Then 中的操作仅执行了一半的情况。
通过 etcd 提供的事务操作,我们可以在多个竞争中去保证数据读写的一致性,比如说前面已经提到过的 Kubernetes 项目,它正是利用了 etcd 的事务机制,来实现多个 KubernetesAPI server 对同样一个数据修改的一致性。
lease 的概念及用法
lease 是分布式系统中一个常见的概念,用于代表一个分布式租约。典型情况下,在分布式系统中需要去检测一个节点是否存活的时,就需要租约机制。
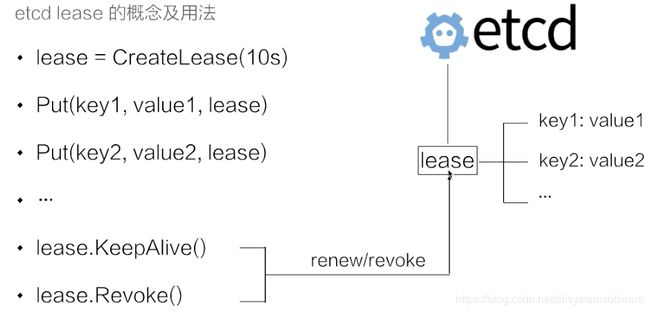
上图示例中的代码示例首先创建了一个 10s 的租约,如果创建租约后不做任何的操作,那么 10s 之后,这个租约就会自动过期。接着将 key1 和 key2 两个 key value 绑定到这个租约之上,这样当租约过期时 etcd 就会自动清理掉 key1 和 key2,使得节点 key1 和 key2 具备了超时自动删除的能力。
如果希望这个租约永不过期,需要周期性的调用 KeeyAlive 方法刷新租约。比如说需要检测分布式系统中一个进程是否存活,可以在进程中去创建一个租约,并在该进程中周期性的调用 KeepAlive 的方法。如果一切正常,该节点的租约会一致保持,如果这个进程挂掉了,最终这个租约就会自动过期。
在 etcd 中,允许将多个 key 关联在同一个 lease 之上,这个设计是非常巧妙的,可以大幅减少 lease 对象刷新带来的开销。试想一下,如果有大量的 key 都需要支持类似的租约机制,每一个 key 都需要独立的去刷新租约,这会给 etcd 带来非常大的压力。通过多个 key 绑定在同一个 lease 的模式,我们可以将超时间相似的 key 聚合在一起,从而大幅减小租约刷新的开销,在不失灵活性同时能够大幅提高 etcd 支持的使用规模。
三、典型的使用场景介绍
元数据存储
Kubernetes 将自身所用的状态存储在 etcd 中,其状态数据的高可用交给 etcd 来解决,Kubernetes 系统自身不需要再应对复杂的分布式系统状态处理,自身的系统架构得到了大幅的简化。

Server Discovery (Naming Service)
第二个场景是 Service Discovery,也叫做名字服务。在分布式系统中,通常会出现的一个模式就是需要多个后端(可能是成百上千个进程)来提供一组对等的服务,比如说检索服务、推荐服务。
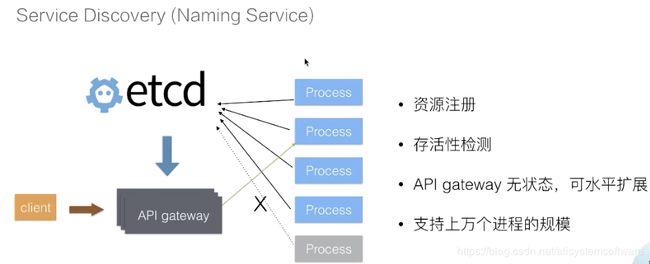
对于这样一种后端服务,通常情况下为了简化后端服务的运维成本(节点故障时随时被替换),后端的这一进程会被类似 Kubernetes 这样的集群管理系统所调度,这样当用户(或上游服务)调用过来时,我们就需要一个服务发现机制来解决服务路由问题。这一服务发现问题可以利用 etcd 来高效解决,方式如下:
- 在进程内部启动之后,可以将自身所在的地址注册到 etcd;
- API 网关够通过 etcd 及时感知到后端进程的地址,当后端进程发生故障迁移时会重新注册到 etcd 中,API 网关也能够及时地感知到新的地址;
- 利用 etcd 提供的 Lease 机制,如果提供服务的进程运行过程中出现了异常(crash),API 网关也可以摘除其流量避免调用超时。
在这一架构中,服务状态数据被 etcd 接管,API 网关本身也是无状态的,可以水平地扩展来服务更多的客户。同时得益于 etcd 的良好性能,可以支持上万个后端进程的节点,使得这一架构可以服务于大型的企业。
Distributed Coordination: leader election
在分布式系统中,有一种典型的设计模式就是 Master Slave。通常情况下,Slave 提供了 CPU、内存、磁盘以及网络等各种资源 ,而 Master 用来调和这些节点以使其对外提供一个服务(比如分布式存储,分布式计算)。典型的分布式存储服务(HDFS)以及分布式计算服务(Hadoop)它们都是采用了类似这样的设计模式。这样的设计模式会有一个典型的问题:Master 节点的可用性。当 Master 故障以后,整个集群的服务就挂掉了,没有办法再服务用户的请求。
为了解决这个问题,典型的做法就是启动多个 Master 节点。因为 Master 节点内会包含控制逻辑,多个节点之间的状态同步是非常复杂的,这里最典型的做法就是通过选主的方式,选出其中一个节点作为主节点来提供服务,另一个节点处于等待状态。
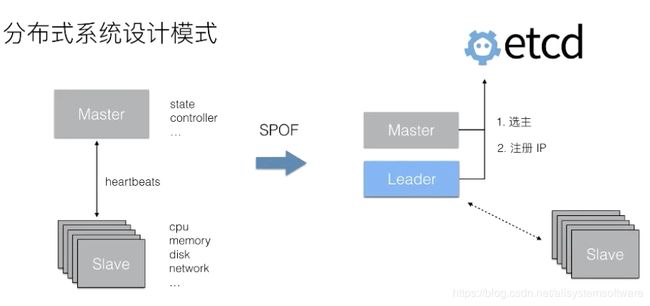
通过 etcd 提供的机制可以很容易的实现分布式进程的选主功能,比如可以通过对同一个 key 的事务写来实现抢主的逻辑。一般而言,被选主的 Leader 会将自己的 IP 注册到 etcd 中,使得 Slave 节点能够及时获取到当前的 Leader 地址,从而使得系统按照之前单个 Master 节点的方式继续工作。当 Leader 节点发生异常之后,通过 etcd 能够选取出一个新的节点成为主节点,并且注册新的 IP 之后,Slave 又能够拉取新的主节点的 IP,继续恢复服务。
Distributed Coordination 分布式系统并发控制
在分布式系统中,当我们去执行一些任务,比如说去升级 OS、或者说升级 OS 上的软件的时候、又或者去执行一些计算任务的时候,出于对后端服务的瓶颈或者是业务稳定性的考虑,通常情况下需要控制任务的并发度。如果该任务缺少一个调和的 Master 节点,可以通过 etcd 来完成这样的分布式系统工作。
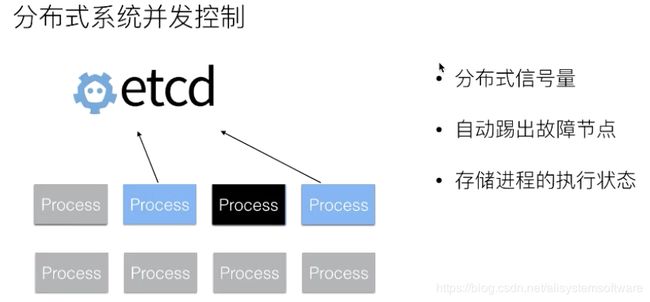
在这个模式中通过 etcd 去实现一个分布式的信号量,并且可以利用 etcd leases 机制来实现自动地剔除掉故障节点。在进程执行过程中,如果进程的运行周期比较长,我们可以将进程运行过程中的一些状态数据存储到 etcd,从而使得当进程故障之后且需要恢复到其他地方时,能够从 etcd 中去恢复一些执行状态,而不需要重新去完成整个的计算逻辑,以此来加速整个任务的执行效率。
本文总结
本文分享的主要内容就到此为止了,这里为大家简单总结一下:
- 第一部分,为大家介绍了 etcd 项目是如何诞生的,以及在 etcd 发展过程中经历的几个重要时刻;
- 第二部分,为大家介绍了 etcd 的架构以及其内部的基本操作接口,在理解 etcd 是如何实现高可用的基础之上,展示了 etcd 数据的一些基本操作以及其内部的实现原理;
- 第三部分,介绍了三种典型的 etcd 使用场景,以及在对应的场景下,分布式系统的设计思路。
“ 阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”