9 概率图模型(一):有向图-贝叶斯网络
1 背景
概率图模型使用图的方式表示概率分布。为了在图中添加各种概率,首先总结一下随机变量分布的一些性质。
1.1 概率的基本性质
我们假设现在有一组高维随机变量, p ( x 1 , x 2 , ⋯ , x n ) p(x_1,x_2,\cdots,x_n) p(x1,x2,⋯,xn).它有两个非常基本的概率,也就是条件概
率和边缘概率,以及根据这两个基本的概率,我们可以得到两个基本的运算法则:Sum Rule 和Product Rule。并且根据这两个基本的法则,我们可以推出Chain Rule 和Bayesian Rule。
- 边缘概率: p ( x 1 ) p(x_1) p(x1)
- 条件概率: p ( x i ∣ x j ) p(x_i|x_j) p(xi∣xj)
- Sum Rule: p ( x 1 ) = ∫ p ( x 1 , x 2 ) d x 2 p(x_1)=\int p(x_1,x_2)dx_2 p(x1)=∫p(x1,x2)dx2
- Product Rule: p ( x 1 , x 2 ) = p ( x 1 ∣ x 2 ) p ( x 2 ) p(x_1,x_2)=p(x_1|x_2)p(x_2) p(x1,x2)=p(x1∣x2)p(x2)
- Chain Rule: p ( x 1 , x 2 , ⋯ , x p ) = ∏ i = 1 p p ( x i ∣ x i + 1 , x i + 2 ⋯ x p ) p(x_1,x_2,\cdots,x_p)=\prod\limits_{i=1}^pp(x_i|x_{i+1,x_{i+2} \cdots}x_p) p(x1,x2,⋯,xp)=i=1∏pp(xi∣xi+1,xi+2⋯xp)
- Bayesian Rule: p ( x 2 ∣ x 1 ) = p ( x 1 , x 2 ) p ( x 1 ) = p ( x 1 , x 2 ) ∫ p ( x 1 , x 2 ) d x 2 = p ( x 2 ∣ x 1 ) p ( x 1 ) ∫ p ( x 2 ∣ x 1 ) p ( x 1 ) d x 2 p\left(x_{2} | x_{1}\right)=\frac{p\left(x_{1}, x_{2}\right)}{p\left(x_{1}\right)}=\frac{p\left(x_{1}, x_{2}\right)}{\int p\left(x_{1}, x_{2}\right) d x_{2}}=\frac{p\left(x_{2} | x_{1}\right) p\left(x_{1}\right)}{\int p\left(x_{2} | x_{1}\right) p\left(x_{1}\right) d x_{2}} p(x2∣x1)=p(x1)p(x1,x2)=∫p(x1,x2)dx2p(x1,x2)=∫p(x2∣x1)p(x1)dx2p(x2∣x1)p(x1)
1.2 条件独立性
为什么要引入条件独立性呢?可以看到,在链式法则中,如果数据维度特别高,那么的采样和计算非常困难,计算 p ( x 1 , x 2 , ⋯ , x p ) = ∏ i = 1 p p ( x i ∣ x i + 1 , x i + 2 ⋯ x p ) p(x_1,x_2,\cdots,x_p)=\prod\limits_{i=1}^pp(x_i|x_{i+1,x_{i+2} \cdots}x_p) p(x1,x2,⋯,xp)=i=1∏pp(xi∣xi+1,xi+2⋯xp)会爆炸,因此我们需要在一定程度上作出简化,来说说我们简化运算的思路。
- 假设每个维度之间都是相互独立的,那么我们 p ( x 1 , x 2 , ⋯ , x p ) = ∏ i = 1 p p ( x N ) p(x_1,x_2,\cdots,x_p)=\prod\limits_{i=1}^pp(x_N) p(x1,x2,⋯,xp)=i=1∏pp(xN)。比如,朴素贝叶斯就是这样的设计思路,也就是 p ( x ∣ y ) = ∏ i = 1 N p ( x i ∣ y ) p(x|y)=\prod\limits_{i=1}^Np(x_i|y) p(x∣y)=i=1∏Np(xi∣y)。但是,这个假设太强了,实际情况中的依赖比这个要复杂很多。所以我们像放弱一点,增加之间的依赖关系,于是我们有提出了马尔科夫性质(Markov Propert)。
- 假设每个维度之间是符合马尔科夫性质(Markov Propert) 的。所谓马尔可夫性质就是,对于一个序列 { x 1 , x 2 , ⋯ , x N } \left\{x_{1}, x_{2}, \cdots, x_{N}\right\} {x1,x2,⋯,xN},第 i i i项仅仅只和第 i − 1 i-1 i−1 项之间存在依赖关系。用符号的方法我们可以表示为: X j ⊥ X i + 1 ∣ x i , j < i X_{j} \perp X_{i+1} | x_{i}, jXj⊥Xi+1∣xi,j<i
在HMM 里面就是这样的齐次马尔可夫假设,但是还是太强了,我们还是要想办法削弱。自然界中经常会出现,序列之间不同的位置上存在依赖关系,因此我们提出了条件独立性。 - 条件独立性:条件独立性假设是概率图的核心概念。它可以大大的简化联合概率分布。而用图我们可以大大的可视化表达条件独立性。我们可以描述为: X A ⊥ X B ∣ X C X_A\perp X_B|X_C XA⊥XB∣XC
而 X A , X B , X C X_A,X_B,X_C XA,XB,XC 是变量的集合,彼此之间互不相交。
1.3 概率图的算法分类
概率图模型采用图的特点表示上述的条件独立性假设,节点表示随机变量,边表示条件概率。大致可以分为三类,表示(Representation),推断(Inference) 和学习(Learning)。
1.3.1 Representation
知识表示的方法,可以分为有向图,Bayesian Network;和无向图,Markov Network,这两种图
通常用来处理变量离散的情况。对于连续性的变量,我们通常采用高斯图,同时可以衍生出,Gaussian
Bayesian Network 和Guassian Markov Network。
1.3.2 Inference
推断可以分为精准推断和近似推断。所谓推断就是给定已知求概率分布。近似推断中可以分为确
定性推断(变分推断) 和随机推断(MCMC),MCMC 是基于蒙特卡罗采样的。
1.3.3 Learning
学习可以分为参数学习和结构学习。在参数学习中,参数可以分为变量数据和非隐数据,我们可
以采用有向图或者无向图来解决。而隐变量的求解我们需要使用到EM 算法,这个EM 算法在后面的
章节会详细推导。而结构学习则是,需要我们知道使用那种图结构更好,比如神经网络中的节点个数,
层数等等,也就是现在非常热的Automate Machine Learning。

2 有向图-贝叶斯网络 Bayesian Network
概率图模型中,图是用来表达的,将概率嵌入到了图中之后,使得表达变得非常的清晰明了。在我们的联合概率计算中,出现了一些问题: p ( x 1 , x 2 , ⋯ , x N ) = p ( x i ) ∏ i = 1 N p ( x i ∣ x 1 : i − 1 ) p\left(x_{1}, x_{2}, \cdots, x_{N}\right)=p\left(x_{i}\right) \prod_{i=1}^{N} p\left(x_{i} | x_{1: i-1}\right) p(x1,x2,⋯,xN)=p(xi)i=1∏Np(xi∣x1:i−1)
这样的计算维度太高了,所以我们引入了条件独立性,表达为 X A ⊥ X B ∣ X C X_{A} \perp X_{B} | X_{C} XA⊥XB∣XC。
已知联合分布中,各个随机变量之间的依赖关系,那么可以通过拓扑排序(根据依赖关系)可以获得一个有向图。而如果已知一个图,也可以直接得到联合概率分布的因子分解: p ( x 1 , x 2 , ⋯ , x N ) = ∏ i = 1 N p ( x i ∣ x p a { i } ) . p\left(x_{1}, x_{2}, \cdots, x_{N}\right)=\prod_{i=1}^{N} p\left(x_{i} | x_{p a\{i\}}\right). p(x1,x2,⋯,xN)=i=1∏Np(xi∣xpa{i}).
其中,pa{i} 表示为 x i x_{i} xi的父亲节点。而概率图可以有效的表达条件独立性,直观性非常的强,我们接下来看看概率图中经典的三种结构。
2.1 概率图的三种基本结构
对于一个概率图,我们可以使用拓扑排序来直接获得,条件独立性的关系。如果存在一个关系由一个节点 x i x_{i} xi 指向另一个节点 x j x_{j} xj,我们可以记为 p ( x j ∣ x i ) p(x_{j}|x_{i}) p(xj∣xi)。我们现在需要定义一些规则来便于说明,对于一个概率图如下所示:
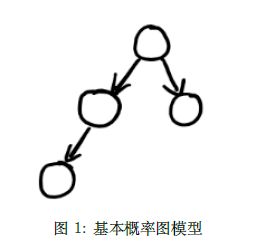
对于一个箭头——>来说,箭头所在的方向称为Head,另一端被称为Tail。
2.1.1 Tail to Tail 结构
Tail to Tail 的模型结构图,如下图所示,由于b 节点在a 节点和c 节点的Tail 部分,所以被我们称为Tail to Tail 结构。

我们使用因子分析来计算联合概率可以得到: p ( a , b , c ) = p ( b ) p ( a ∣ b ) p ( c ∣ b ) p(a,b,c) = p(b)p(a|b)p(c|b) p(a,b,c)=p(b)p(a∣b)p(c∣b)
使用链式法则,同样我们也可以得到:
p ( a , b , c ) = p ( b ) p ( a ∣ b ) p ( c ∣ b , a ) p(a,b,c) = p(b)p(a|b)p(c|b,a) p(a,b,c)=p(b)p(a∣b)p(c∣b,a)
对比一下上述两个公式,可以对比得到: p ( c ∣ b ) = p ( c ∣ b , a ) p(c|b) = p(c|b,a) p(c∣b)=p(c∣b,a)
实际上,这里就已经就可以看出 a ⊥ c a \perp c a⊥c 了,因为a 的条件增不增加都不会改变c 的概率,所以a 和c 之间是相互独立的。
p ( c ∣ b ) p ( a ∣ b ) = p ( c ∣ b , a ) p ( a ∣ b ) = p ( a , c ∣ b ) ( 后 一 个 等 号 同 乘 以 p ( a ) 可 看 出 ) ⇒ p ( c ∣ b ) p ( a ∣ b ) = p ( a , d ∣ b ) \begin{array}{l} p(c | b) p(a | b)=p(c | b, a) p(a | b)=p(a, c | b) (后一个等号同乘以p(a)可看出)\\ \quad \Rightarrow p(c | b) p(a | b)=p(a, d |b) \end{array} p(c∣b)p(a∣b)=p(c∣b,a)p(a∣b)=p(a,c∣b)(后一个等号同乘以p(a)可看出)⇒p(c∣b)p(a∣b)=p(a,d∣b)
这样,我们就可以看得很明白了。这就是条件独立性,在 a a a 的条件下, b b b 和 c c c 是独立的。实际在概率图中就已经蕴含这个分解了,只看图我们就可以看到这个性质了,这就是图的直观性,条件独立性和图是一样的。那么 a ⊥ c a\perp c a⊥c 可以被我们看为:给定b 的情况下,如果 b b b 被观测到,那么 a a a 和 c c c 之间是阻塞的,也就是相互独立。
2.1.2 Head to Tail 结构

其实,和Head to Head 结构的分析基本是上一模一样的,我们可以得到 a ⊥ c ∣ b a \perp c |b a⊥c∣b。也就是给定 b b b的条件下, a a a 和 c c c 之间是条件独立的。也就是 b b b 被观测的条件下,路径被阻塞。
使用因子分解可以得到: p ( a , b , c ) = p ( a ) p ( a ∣ b ) p ( c ∣ b ) p(a,b,c) = p(a)p(a|b)p(c|b) p(a,b,c)=p(a)p(a∣b)p(c∣b)
使用链式法则,可以得到:
p ( a , b , c ) = p ( b ) p ( a ∣ b ) p ( c ∣ b , a ) p(a,b,c) = p(b)p(a|b)p(c|b,a) p(a,b,c)=p(b)p(a∣b)p(c∣b,a)
对比一下上述两个公式,可以对比得到: p ( c ∣ b ) = p ( c ∣ b , a ) p(c|b) = p(c|b,a) p(c∣b)=p(c∣b,a)
实际上,这里就已经就可以看出 a ⊥ c ∣ b a \perp c | b a⊥c∣b 。
2.1.3 Head to Head 结构

在默认情况下 a ⊥ b a\perp b a⊥b,也就是若 c c c 被观测, a a a 和 b b b 之间是有关系的。我们可以推导一下默认情况。
使用因子分解: p ( a , b , c ) = p ( a ) p ( b ) p ( c ∣ a , b ) p(a,b,c) = p(a)p(b)p(c|a,b) p(a,b,c)=p(a)p(b)p(c∣a,b)
使用链式法则: p ( a , b , c ) = p ( b ) p ( a ∣ b ) p ( c ∣ b , a ) p(a,b,c) = p(b)p(a|b)p(c|b,a) p(a,b,c)=p(b)p(a∣b)p(c∣b,a)
对比一下上述两个公式,可以对比得到: p ( b ) = p ( b ∣ a ) p(b) = p(b|a) p(b)=p(b∣a)
可得 a ⊥ b a \perp b a⊥b 。但是当 c c c被观测后,上述关系不在成立。
2.1.4 三种结构对比
三种结构我们在上面都已经进行分析过了,其实大家发现Tail to Tail,Head to Tail 都比较正常,但是Head to Head 有点不对劲。因为不太符合条件独立性,因为当c 被观察到的时候,a 和b 之间反而有关系了。这实际上让人有点费解。
我们来举个例子:在图4 中的三个事件,我们引入一个故事。
- c:小明喝醉了。
- a:小明酒量小。
- b:小明心情不好。
我们想要知道 p ( a ∣ c ) = p ( a ∣ b , c ) p(a|c) = p(a|b,c) p(a∣c)=p(a∣b,c)是否会成立?如果等号成立的话a 和b 之间一定是相互独立的。这个我们在Tail to Tail 那一节就已经说过了。
我们假设小明喝醉了是因为小明心情不好的概率是0.8,那么当我们知道小明喝醉了并且小明今天的心情不好的情况下,知道他酒量小的概率一定是小于0.8 的。大家想想就知道了,其实很简单的。
那么给定了 c , a c,a c,a和 b b b之间反而无法分离了。这有点反常,反而使Inference 变得困难了,恰好反过来了。那么我们怎么解决这种情况呢?我们下一小节会解决这个问题。
2.2 D-Separation
上一小节中,我们已经大致介绍了概率图之间的三种基本拓扑结构。下面我们来介绍一下,这三种拓扑结构的运用,以及如何扩展到我们的贝叶斯模型中。
2.2.1 D-separation
假设我们有三个集合, X A , X B , X C X_{A},X_{B},X_{C} XA,XB,XC,这三个集合都是可观测的,并且满足 X A ⊥ X C ∣ X B X_{A}\perp X_{C}|X_{B} XA⊥XC∣XB。那我们想想,如果有一些节点连成的拓扑关系图,若其中一个节点 a ∈ X A , c ∈ X C a \in X_{A}, c \in X_{C} a∈XA,c∈XC,那么如果 a a a 和 c c c 之间相互独立,他们之间连接的节点需要有怎样的条件?我们通过一个图来进行描述。

根据上一小节可知,假如从 a a a 到 c c c 中间通过一个节点 b b b,那么路径什么时候是连通的?什么时候又是阻塞的呢?我们可以分两种情况来讨论,为什么是两种?上一节我们就已经讲解过,Tail to Tail 结构和Head to Tail 结构其实是一样的,但是Head to Head 结构是反常的。
所以我们就分开进行讨论。
- 如果是Tail to Tail 结构和Head to Tail 结构,那么中间节点 b 1 , b 2 b1,b2 b1,b2 必然要位于可观测集合 X B 中 , 那 么 X_{B}中,那么 XB中,那么a$ 和 c c c 才是相互独立的。
- 如果是Head to Head 结构,那就不一样了,在一般情况下 a ⊥ c a\perp c a⊥c,那就是 b ∉ X B b \notin X_{B} b∈/XB,包括他的子节点都不可以被观测到,不然就连通了。
如果,符合上述两条规则,那么我们就可以称 a a a 和 c c c 之间是D-Separation 的。也就是存在集合 X A , X B , X C X_{A},X_{B},X_{C} XA,XB,XC,当 X B X_{B} XB中的随机变量被观测的情况下, X A X_{A} XA与 X C X_{C} XC中的随机变量相互独立,则称 X B X_{B} XB是 X A , X C X_{A},X_{C} XA,XC的D-Separation。实际上还有一个名字,叫做全局马尔科夫性质(Global Markov Property)。D-Separation 非常的关键,我们可以直接用这个性质来检测两个集合关于另外一个集合被观测的条件是不是条件独立。
2.2.2 Markov Blanket
定义:在随机变量的全集 U U U中,对于给定的变量 X ∈ U X \in U X∈U和变量集合 M B ∈ U MB \in U MB∈U,若有 X ⊥ ( U − M B − X ) ∣ M B X \perp ( U-MB-X )|MB X⊥(U−MB−X)∣MB 则称能满足上述条件的最小变量集MB为X的马尔科夫毯(Markov Blanket)。
D 划分应用在贝叶斯定理中:定义 x − i x_{-i} x−i为 { x 1 , x 2 , ⋯ , x i − 1 , x i + 1 , ⋯ , x N } \left\{x_{1}, x_{2}, \cdots, x_{i-1}, x_{i+1}, \cdots, x_{N}\right\} {x1,x2,⋯,xi−1,xi+1,⋯,xN},这个序列中不包括 x i x_{i} xi,那么,假设除了 x i x_{i} xi节点,其它的节点都是可观测的,那么我们需要计算概率: p ( x i ∣ x − i ) = p ( x i , x − i ) p ( x − i ) = p ( x ) ∫ x 1 p ( x ) d x i = ∏ j = 1 N p ( x j ∣ x p a ( j ) ) ∫ x i ∏ j = 1 N p ( x j ∣ x p a ( j ) ) d x i p\left(x_{i} | x_{-i}\right)=\frac{p\left(x_{i}, x_{-i}\right)}{p\left(x_{-i}\right)}=\frac{p(x)}{\int_{x_{1}} p(x) d x_{i}}=\frac{\prod_{j=1}^{N} p\left(x_{j} | x_{p a(j)}\right)}{\int_{x_{i}} \prod_{j=1}^{N} p\left(x_{j} | x_{p a(j)}\right) d x_{i}} p(xi∣x−i)=p(x−i)p(xi,x−i)=∫x1p(x)dxip(x)=∫xi∏j=1Np(xj∣xpa(j))dxi∏j=1Np(xj∣xpa(j))
我们分析一下上述等式,我们可以分成两部分,将和 x i x_{i} xi 相关的部分记为 Δ ˉ \bar{\Delta} Δˉ,将和 x i x_{i} xi不相关的部分记为 Δ \Delta Δ,那么上式可改写为
p ( x i ∣ x − i ) = Δ ⋅ Δ ˉ ∫ x i Δ ⋅ Δ ˉ d x i = Δ ⋅ Δ ˉ Δ ⋅ ∫ x i Δ ˉ d x i = = Δ ˉ ∫ x 1 Δ ˉ d x i p\left(x_{i} | x_{-i}\right)=\frac{\Delta \cdot \bar{\Delta}}{\int_{x_{i}} \Delta \cdot \bar{\Delta} d x_{i}}=\frac{\Delta \cdot \bar{\Delta}}{\Delta \cdot \int_{x_{i}} \bar{\Delta} d x_{i}}==\frac{\bar{\Delta}}{\int_{x_{1}} \bar{\Delta} d x_{i}} p(xi∣x−i)=∫xiΔ⋅ΔˉdxiΔ⋅Δˉ=Δ⋅∫xiΔˉdxiΔ⋅Δˉ==∫x1ΔˉdxiΔˉ
那么xi 和其他所有点的关系可以被化简为只和 x i x_{i} xi相关的点的关系。那么,我们将这个关系大致抽象出来,通过图来进行分析,找一找哪些节点是和 x i x_{i} xi相关的,直观性也是概率图模型的一大优点。假设 x i x_{i} xi是可以被观测到的:

P ( x i ∣ x − i ) P(x_{i}|x_{-i}) P(xi∣x−i) 首先包括一部分为 P ( x i ∣ x − i ) P(x_{i}|x_{-i}) P(xi∣x−i),第二部分为 p ( x c h i l d ( i ) ∣ x i , x p a ( c h i l d ( x i ) ) ) p(x_{child(i)}|x_{i},x_{pa(child(xi))}) p(xchild(i)∣xi,xpa(child(xi)))。为什么第二部分可以这样写呢?首先 x i x_{i} xi 作为两个父亲节点,得到两个孩子节点,毫无疑问对吧,那么我们可以写成 p ( x c h i l d ( i ) ∣ x i ) p(x_{child(i)}|x_i) p(xchild(i)∣xi)。但是和 p ( x c h i l d ( i ) p(x_{child(i)} p(xchild(i)相关的变量除了 x i x_{i} xi 肯定还有其他的,也就是 x p a ( c h i l d ( x i ) ) x_{pa(child(xi))} xpa(child(xi)),所以我们就可以得到 p ( x c h i l d ( i ) ∣ x i , x p a ( c h i l d ( x i ) ) ) p(x_{child(i)}|x_{i},x_{pa(child(xi))}) p(xchild(i)∣xi,xpa(child(xi)))。
实际上,这些 x i x_{i} xi周围的节点,也就是我用阴影部分画出的那些,可以被称为Markov Blanket。从图上看就是留下和父亲,孩子,孩子的另一个双亲,其他的节点可以忽略,也就是和周围的关系的连接。
换句话说,一个人的马尔可夫毯就是和你有关系的所有人(按式2-16定义)。如果想要调查这个人,总不能把全社会的所有人都调查一下吧(大量的特征冗余),其实只要找出这个人的马尔可夫毯人群调查一下就好了(特征选择)。特别地,如果这个社会是贝叶斯网络,马尔可夫毯人群只包括自己的家人,相当于人只与自己的家人有关系,和其他人没关系,是一种简化的模型。
贝叶斯网络,它是一个有向无环图(Directed Acyclic Graph, DAG),结点之间的连结都是有向箭头,且不能沿着箭头走一圈。贝叶斯网络是马尔可夫链的推广,马尔可夫链限定了结构只能是一条链,而贝叶斯网络则不再限定结构是一个链,但二者都遵守马尔可夫假设,即一个结点只依赖于它的上一个节点(一阶马尔可夫假设)。
参考:https://www.cnblogs.com/wt869054461/p/9899929.html
梳理一下:D-Separation 是在概率图中,帮助我们快速的判断条件独立性。对于一个节点,它和哪些节点相关,它和和父亲,孩子,孩子的另一个双亲这三种节点相关,这三种点的集合就是Markov Blanket。在概率图中,我们用 p ( x 1 , x 2 , ⋯ , x N ) = p ( x i ) ∏ i = 1 N p ( x i ∣ x 1 : i − 1 ) p\left(x_{1}, x_{2}, \cdots, x_{N}\right)=p\left(x_{i}\right) \prod_{i=1}^{N} p\left(x_{i} | x_{1: i-1}\right) p(x1,x2,⋯,xN)=p(xi)∏i=1Np(xi∣x1:i−1)和 p ( x 1 , x 2 , ⋯ , x N ) = ∏ i = 1 N p ( x i ∣ x p a { i } ) p\left(x_{1}, x_{2}, \cdots, x_{N}\right)=\prod_{i=1}^{N} p\left(x_{i} | x_{p a\{i\}}\right) p(x1,x2,⋯,xN)=∏i=1Np(xi∣xpa{i})两种表达形式是等价的。第一种是最完备的表达方法,第二种的表达是简化版本,蕴含了概率图中得到的条件独立性关系简化的结果。
2.3 例子
实际应用的模型中,对这些条件独立性作出了假设,从单一到混合,从有限到无限(时间,空间)可以分为单一,混合,时间和连续四个角度,下面看一下这个四个方法是一步一步越来越难的。
2.3.1 单一
单一最典型的代表就是Naive Bayesian,这是一种classification 的模型。对于 p ( x ∣ y ) p(x|y) p(x∣y) 的问题来说,假设各维度之间相互独立,单一的条件独立性假设 p ( x ∣ y ) = ∏ i = 1 p p ( x i ∣ y ) p(x|y)=\prod\limits_{i=1}^pp(x_i|y) p(x∣y)=i=1∏pp(xi∣y),在 D 划分后,所有条件依赖的集合就是单个元素。
概率图模型表示如下所示:

很显然是一个Tail to Tail 的模型,我们很简单可以得出 x 1 ⊥ x 2 ⊥ ⋯ ⊥ x N x_{1}\perp x_{2} \perp \cdots \perp x_{N} x1⊥x2⊥⋯⊥xN。
2.3.2 混合
最常见的就是Gaussian Mixture Model (GMM),这是一种聚类模型,将每个类别拟合一个分布,计算数据点和分布之间的关系来确定,数据点所属的类别。我们假设Z 是一个隐变量,并且Z 是离散的变量, z 1 , z 2 , ⋯ , z k z_1,z_2,\cdots,z_k z1,z2,⋯,zk, p ( x ∣ z ) = N ( μ , Σ ) p(x|z)=\mathcal{N}(\mu,\Sigma) p(x∣z)=N(μ,Σ),我们用模型可以表示为:

2.3.3 时间
时间上我们大致可以分成两种。第一种是Markov chain,这是随机过程中的一种;第二种事GaussianProcessing,实际上就是无限维的高斯分布。
实际上时间和混合可以一起看,我们称之为动态系统模型。并且,我们就可以衍生出三种常见的模型,这里讲的比较的模糊,在后面的章节我们会进行详细的分析。第一种是隐马尔可夫模型(HMM),这是一种离散的模型;第二种是线性动态系统(LDS),这是一种线性的连续的模型,包括典型的KalmanFilter。第三种是Particle Filter,一种非高斯的,非线性的模型。
2.3.4 连续
高斯叶斯网络Guassian Bayesian Network
2.3.5
组合上面的分类如:GMM 与时序结合:动态模型
a. HMM(离散)
b. 线性动态系统 LDS(Kalman 滤波)
c. 粒子滤波(非高斯,非线性)