开源软件架构-第二十四章 VTK
原文链接:http://www.aosabook.org/en/vtk.html
VTK是一个被广泛应用于数据处理和可视化的软件系统。它可用于科学计算、医学影像分析、计算几何、渲染、图像处理和信息学等领域。在本章中,我们将简要介绍VTK,包括一些使其成为一个成功系统的基本设计模式。
要想真正理解一个软件系统,不仅要了解它解决了什么问题,还要了解它出现时的特定文化背景。对于VTK来说,它表面上看起来是用于科学数据的三维可视化系统,但它出现时的文化背景为它增添了意义深远的背景故事,这有助于解释为什么软件为什么是被这样设计和部署的。
在构思和编写VTK时,其最初的作者(Will Schroeder,Ken Martin,Bill Lorensen)是GE公司研发部门的研究人员,他们曾向一个称为LYMB的系统投入了大量精力,该系统是一种用C语言实现的类似Smalltalk的开发环境。虽然这在当时是一个伟大的系统,但作为研究人员的我们在尝试推广这套系统时始终受到来自两个方面的障碍:1)知识产权问题和2)非标准的专有软件。知识产权之所以是一个问题,是因为一旦GE公司的律师介入,试图在公司之外分发软件几乎是不可能的。其次,即使我们在GE公司内部部署软件,我们的许多客户仍然不愿意学习专有的非标准系统,因为一旦他离开公司,为了掌握该系统而做出的努力无法随他一同转移到新的雇主那里,而且这种软件没有标准工具集所提供的广泛支持。因此,最终VTK的主要动机就是开发一个开放标准(或协作平台),通过它我们可以轻松地将技术转移到我们的客户。因此,为VTK选择一个开源许可证或许是我们所做出的最重要的设计决策。
事后看来,最终选择非互惠、自由的许可(即BSD而不是GPL)是作者做出的一个具有代表性的决定,因为它最终使得基于服务和咨询的业务成为可能,这也成就了Kitware。在我们做出这个决定时,我们最想要做的就是减少与学术界、研究实验室和商业实体合作之间的障碍。我们后来发现许多组织都避免使用互惠许可证,因为它们可能造成严重破坏。事实上,我们认为互惠许可证会减慢开源软件被接受的速度,但这是另一个问题。这里的要点是:对于任何软件系统来说,做出的主要设计决策之一就是版权许可的选择。重要的是要重新审查项目的目标,然后适当地解决知识产权问题。
1 VTK是什么?
VTK最初被定义为科学数据可视化系统。该领域之外的许多人天真地将可视化视为一种特殊的几何渲染:查看虚拟对象并与它们交互。虽然这确实是可视化的一部分,但通常数据可视化还包括将数据转换为感官输入的整个过程,通常是图像,但也包括触觉、听觉和其他形式。数据形式不仅包括几何和拓扑结构(诸如网格或复杂空间分解之类的抽象),还包括核心结构的属性,例如标量(如温度或压力)、向量(如速度)、张量(如应力和应变)以及渲染属性(如曲面法线和纹理坐标)等。
需要注意的是,表示空间信息的数据通常被认为是科学可视化的一部分。然而,还有更多抽象的数据形式,比如市场人口统计、网页、文档以及其他信息,这些形式只能通过抽象关系(即非时空)来表示,例如非结构化文档、表格、图形和树。这些抽象数据通常通过信息可视化的方法来处理。在社区的帮助下,VTK现在能够进行科学和信息可视化方面的工作。
作为可视化系统,VTK的作用是以这些形式获取数据并最终将它们转换为人类感官可理解的形式。因此,VTK的核心要求之一是它能够创建、获取、处理、表示和最终呈现数据的这种创建数据流管线的能力。因此,工具包必须构建为灵活的系统,其设计在很多层面上都反映了这一点。例如,我们特意将VTK设计为具有许多可互换组件的工具包,这些组件可以组合起来用于处理各种数据。
2 架构特性
在深入了解VTK特殊的架构特性之前,先介绍一些顶层的概念,它们对系统的开发和使用都产生了重大影响。其中之一是VTK的混合封装设施(hybrid wrapper facility)。该设施从VTK的C ++实现中自动创建与Python、Java和Tcl的绑定(也可以添加其他语言)。大多数要求高性能的开发人员都将使用C ++来进行开发。使用者和应用程序开发人员也可以使用C ++,但通常会首选上述解释语言。这种混合编译/解释性环境结合了两者的优点:计算密集型算法的高性能和原型设计或开发的灵活性。实际上,这种多语言计算方法已经受到科学计算界的许多人的青睐,许多团队将VTK作为他们软件开发的范本。
在软件过程方面,VTK采用CMake来控制构建过程; CDash / CTest用于测试; CPack用于跨平台部署。事实上,VTK几乎可以在任何计算机上编译,包括因其简陋开发环境而众所周知的超级计算机。此外,网页、wiki、邮件列表(用户和开发人员)、文档生成工具(即Doxygen)和错误跟踪器(Mantis)这些外围工具也都让VTK变得更加完善。
2.1 核心特性
由于VTK是面向对象的系统,因此在VTK中对类的访问和数据成员实例化都要被小心地管理起来。通常,所有数据成员都是受保护的(protected)或私有的(private)。可以通过Set和Get方法来访问它们,这两个方法可用于多种类型的形参:布尔数据、模态数据、字符串和向量。其中许多方法实际上是通过将宏插入类的头文件的方式来创建的。 例如:
vtkSetMacro(Tolerance,double);
vtkGetMacro(Tolerance,double);
扩展宏定义:
virtual void SetTolerance(double);
virtual double GetTolerance();
除了简单的让代码更加清晰之外,使用这些宏的原因还有很多。在VTK中,有一些重要的数据成员用来控制调试、更新对象的修改时间(MTime)以及恰当地管理引用计数。这些宏正确地操纵这些数据,强烈建议使用它们。例如,当对象的MTime未得到正确管理时,VTK中会出现一个严重的bug。在这种情况下,代码可能无法执行,也可能被过多地执行。
VTK的优势之一是它相对简单的数据表示和数据管理方法。通常,特定类型的各种数据阵列(例如,vtkFloatArray)用于表示连续的信息。例如,三个三维空间中地点将用含有九个元素(x,y,z,x,y,z等)的vtkFloatArray表示。这些数组中存在元组的概念,因此一个3D的点是3元组,而一个对称的3×3张量矩阵可以由一个6元组表示(可以节省对称空间)。采用这种设计是有目的的,因为在科学计算中,与操纵数组的系统(例如Fortran)的接口是很常见的,并且在大的连续内存块中分配和释放内存要高效得多。此外,通信、串行化和执行IO这些操作通常对于连续数据更高效。这些核心数据数组(各种类型)代表了VTK中的大部分数据,并具有各种便于插入和访问信息的方法,包括快速访问的方法,以及在添加更多数据时根据需要自动分配内存的方法。数据数组是vtkDataArray抽象类的子类,这意味着通用的虚方法可用于简化编码。但是,为了达到更高的性能,静态的、模板化的函数被引入,这样就可以根据不同的参数类型进行切换,然后实现对连续数据数组的直接访问。
虽然模板(template)因性能原因而被广泛使用,但通常C ++模板在公共类API中不可见。STL也是这样:我们通常使用PIMPL1设计模式来隐藏复杂的模板实现。这为我们提供了很大的帮助,尤其是在将代码包装到如前所述的解释代码中时。避免公共API中模板的复杂性意味着:从应用程序开发者的角度来看,VTK实现基本上不需要考虑数据类型的选择问题。当然,在其外壳下,代码执行是由数据类型驱动的,而数据类型则通常在运行时访问数据时确定。
一些用户想知道为什么VTK使用引用计数进行内存管理而不是使用垃圾回收等对用户更加友好的方法。基本的答案是VTK需要完全控制何时删除数据,因为数据量可能非常巨大。例如,一组大小为1000×1000×1000字节的体数据的数据量是1GB。留下这些数据让垃圾收集器来决定是否释放它并不是一个好主意。在VTK中,大多数类(vtkObject的子类)具有内建的引用计数功能。每个对象都包含一个引用计数,它在该对象被实例化时初始化为1。每次使用该对象都会进行注册,同时引用计数加1。类似地,当将该对象注销(或等效地认为该对象被删除)时,引用计数就会减一。最终,当对象的引用计数减少到0时,该对象就会自行销毁。典型示例如下所示:
vtkCamera *camera = vtkCamera::New(); //reference count is 1
camera->Register(this); //reference count is 2
camera->Unregister(this); //reference count is 1
renderer->SetActiveCamera(camera); //reference count is 2
renderer->Delete(); //ref count is 1 when renderer is deleted
camera->Delete(); //camera self destructs
还有另外一个重要原因说明为什么引用计数对于VTK很重要:它提供了有效复制数据的能力。例如,假设一个数据对象D1由许多数据数组组成:点、多边形、颜色、标量和纹理坐标。现在假设处理该数据以生成新的数据对象D2,数据对象D2与D1相同,除此之外还加上了向量数据(用于定位点)。一种浪费资源的方法是完全复制(深拷贝)D1以创建D2,然后将新的向量数据数组添加到D2。或者,我们可以创建一个空的D2,然后将数组从D1传递给D2(浅拷贝),使用引用计数来跟踪数据所有权,最后将新的向量数组添加到D2。后面这种方法避免了复制数据,正如前文所述,这对于一个优秀的可视化系统至关重要。我们在本章后面内容可以看到,数据处理管线例行地执行着这种操作,即,将数据从算法的输入复制到输出,因此引用计数对于VTK是至关重要的。
当然,引用计数也存在一些臭名昭著的问题。偶尔会存在引用循环,循环中的对象以一种相互支持的配置相互引用。在这种情况下,需要智能干预,或者在VTK中,一种在vtkGarbageCollector中实现的特殊工具用于管理循环中涉及的对象。当识别出这样的类(这被期望发生在开发阶段)时,该类将自己注册到垃圾收集器中并重载其自己的Register和UnRegister方法。然后紧接着对象销毁(或注销/unregister)方法对局部的引用计数网络进行拓扑分析,搜索已经分离了的相互引用的对象群。然后被垃圾回收器删除。
VTK中的大多数实例化都是通过作为静态类成员实现的对象工厂来实现的。典型语法如下所示:
vtkLight *a = vtkLight::New();
这里要认识到的重要事实是:实际实例化的可能不是vtkLight,它可能是vtkLight的子类(例如,vtkOpenGLLight)。采用对象工厂的动机多种多样,最重要的是应用程序的可移植性和设备的独立性。例如,前文中我们在渲染场景中创建了一个光源。在特定平台上的特定应用程序中,vtkLight :: New可能会生成一个OpenGL光源,但是在不同的平台上,可能会有其他渲染库或方法在图形系统中创建光源。到底要实例化什么样的派生类取决于运行时的系统信息。在早期的VTK中,有包括gl、PHIGS、Starbase、XGL和OpenGL等无数的选择。虽然其中大部分已经消失,但出现了包括DirectX和基于GPU方法在内的新方法。随着时间的推移,使用VTK编写的应用程序不必更改,因为开发者已经派生出了对应于特定新设备的vtkLight子类和其他渲染类以支持不断发展的技术。对象工厂的另一个重要用途是使运行时替换性能增强变动成为可能。例如,vtkImageFFT可以被替换为访问专用硬件或数值计算库的类。
2.2 数据表示
VTK的优势之一是它表示复杂数据形式的能力。这些数据形式包括简单的表及有限元网格之类的复杂结构。所有这些数据形式都是vtkDataObject的子类,如图1所示(注意这是许多数据对象类继承图的一部分)。
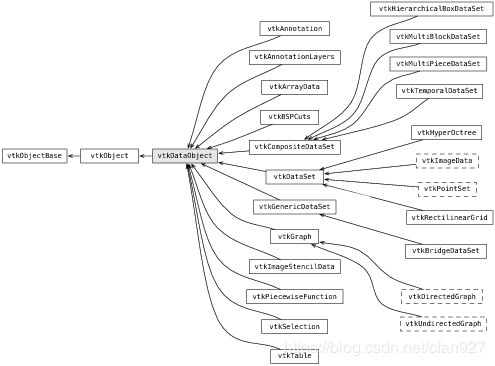
图1 数据对象类
vtkDataObject类最重要的特点之一是它可以被可视化管线处理(见下节)。在上图所示的类中,只有少数常用的类会被用于大多数实际的应用程序中。vtkDataSet和其派生类常被用于科学可视化(如图2)。例如,vtkPolyData用于表示多边形网格; vtkUnstructuredGrid用于表示网格,vtkImageData用于表示2D和3D的像素和体素数据。
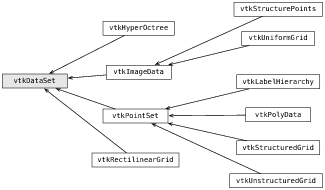
图 2 数据集类
2.3 管线架构
VTK由几个重要的子系统组成。其中与可视化组件最相关的子系统是数据流/管线架构。从概念上讲,管线架构由三个基本的类对象组成:表示数据的对象(前文中的vtkDataObject),通过处理、变换、滤波或映射等操作将数据对象从一种形式转换到另一种形式的对象(vtkAlgorithm),以及用于控制交错数据和处理对象(如管线)连接图的执行管线对象(vtkExecutive)。
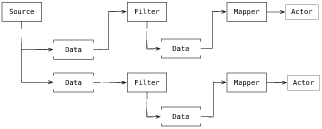
图3 典型的管线
虽然概念很简单,但实际上实现流水线架构非常具有挑战性。一个原因是数据的表示可能很复杂。例如,某些数据集由层次化的或分组的数据组成,因此执行这种数据需要进行特殊的迭代或递归。更复杂的是,并行处理(无论是使用共享存储器还是可扩展的分布式方法)需要将数据分成片段,其中可能需要片段重叠以便一致地计算边界信息,例如导数。
算法对象也同样引入了自身特殊的复杂性。一些算法可能需要多个输入和/或产生不同类型的多个输出。一部分可以对数据进行局部操作(例如,计算一个网格的中心),而另外一部分则需要全局信息,例如计算直方图。任何情况下,算法都将其输入看作是不变量,算法只是读取输入并产生输出。这是因为数据可以作为多个算法的输入,并且一个算法践踏另一个算法的输入并不是一个好主意。
最后,执行对象的复杂成都取决于执行策略的细节。在某些情况下,我们可能希望在滤波器之间缓存中间结果。这减少了管线中因某些内容发生变化时必须重新执行的计算量。另一方面,用于可视化的数据集可能很庞大,在这种情况下,我们希望在不再需要计算时释放数据。最后,有一些复杂的执行策略,例如数据的多分辨率处理,其需要管线以迭代的方式执行。
为了演示其中一些概念并进一步解释管线架构,请看以下C ++示例:
vtkPExodusIIReader *reader = vtkPExodusIIReader::New();
reader->SetFileName("exampleFile.exo");
vtkContourFilter *cont = vtkContourFilter::New();
cont->SetInputConnection(reader->GetOutputPort());
cont->SetNumberOfContours(1);
cont->SetValue(0, 200);
vtkQuadricDecimation *deci = vtkQuadricDecimation::New();
deci->SetInputConnection(cont->GetOutputPort());
deci->SetTargetReduction( 0.75 );
vtkXMLPolyDataWriter *writer = vtkXMLPolyDataWriter::New();
writer->SetInputConnection(deci->GetOuputPort());
writer->SetFileName("outputFile.vtp");
writer->Write();
在此示例中,reader对象读取一个大型非结构化网格(或网格)数据文件。下一个滤波器从该网格生成等值面。vtkQuadricDecimation滤波器通过抽取(即减少表示等光线的三角形的数量)来减小等值面数据集的大小,该等值面是多边形数据集。最后,在抽取完成之后,将新的削减后的数据文件写回磁盘。当writer对象调用Write方法时(即,在需要数据时),会触发流水线的执行。
如此示例所示,VTK的管线执行机制是命令驱动的。当像writer或mapper(数据渲染对象)之类的接收器需要数据时,它就会向其输入发出请求。如果作为输入的滤波器已经有了合适的数据,那么它就会简单的返回执行控制权。但是,如果输入没有合适的数据,则需要去计算它。因此,它必须首先向其输入请求数据。此过程将沿着管线持续上溯,直到达到具有“合适数据”的滤波器或源,或达到管线的开头,此时滤波器将以正确的顺序执行,并且数据将流向管道中请求它的点。
在这里,我们扩展讲解“适当的数据”的含义。默认情况下,在执行VTK源或滤波器之后,管道会缓存其输出,以避免将来不必要的执行操作。这样做是为了以内存为代价最小化计算量和/或输入输出量,并且这是可配置的行为。管线不仅缓存数据对象,还缓存有关生成这些数据对象的条件的元数据。该元数据包括在计算数据对象时捕获的时间戳(如,ComputeTime)。因此在这种最简单的情况下,“合适的数据”是在其发生改变时其上游的所有管线对象计算得到的数据。通过考虑以下示例,更容易证明此行为。我们将以下内容添加到上一个VTK程序的末尾:
vtkXMLPolyDataWriter *writer2 = vtkXMLPolyDataWriter::New();
writer2->SetInputConnection(deci->GetOuputPort());
writer2->SetFileName("outputFile2.vtp");
writer2->Write();
如前所述,第一个writer-> Write的调用会触发整个管线的执行。当调用writer2-> Write()时,通过比较缓存中的时间戳和decimation滤波器的修改时间(MTime),管线会知道decimation滤波器、contour滤波器和reader的缓存输出是最新的。因此,数据请求不会传播到比writer2更远的地方。现在,让我们考虑以下变化。
cont->SetValue(0, 400);
vtkXMLPolyDataWriter *writer2 = vtkXMLPolyDataWriter::New();
writer2->SetInputConnection(deci->GetOuputPort());
writer2->SetFileName("outputFile2.vtp");
writer2->Write();
现在,管线执行程序会发现在contour和decimation滤波器上一次执行之后又修改了contour滤波器。因此,这两个滤波器的缓存是过时的,必须重新执行。但是,由于在contour滤波器之前未对reader进行修改,因此其缓存有效,读取器不必重新执行。
此处描述的场景是命令驱动管线的最简单示例。VTK中的管线要复杂得多。当滤波器或接收器需要数据时,它可以提供额外的信息来请求特定的数据子集。例如,滤波器可以通过流式传输数据来执行堆外内存分析。让我们改变前面的例子来演示。
vtkXMLPolyDataWriter *writer = vtkXMLPolyDataWriter::New();
writer->SetInputConnection(deci->GetOuputPort());
writer->SetNumberOfPieces(2);
writer->SetWritePiece(0);
writer->SetFileName("outputFile0.vtp");
writer->Write();
writer->SetWritePiece(1);
writer->SetFileName("outputFile1.vtp");
writer->Write();
在这里,writer请求上游管线加载并以两个片段来处理数据,这两个片段都是以独立数据流的形式传输的。你可能已经注意到,之前描述的简单执行逻辑在此处不起作用。通过这种逻辑,当第二次调用Write函数时,管道不应该重新执行,因为上游没有任何改变。因此,为了了解决这个更复杂的案例,执行对象有额外的逻辑来处理这样的片断请求。 VTK的管线执行实际上包含多个关卡。数据对象的计算实际上是最后一个关卡。在此之前的关卡是一个请求关卡。在这里接收器和滤波器可以告诉上游它们想要的即将到来的计算。在上面的示例中,writer将通知其输入它需要2个片段中的第0个片段。此请求实际上将一直传播到reader。当管线执行时,reader将知道它需要读取一个数据的子集。此外,在对象的元数据中,存有缓存数据的对应信息。当下次滤波器从其输入请求数据时,此元数据将与当前请求进行比较。因此,在该示例中,管线将重新执行以处理不同的片段请求。
滤波器可以请求很多种类型的数据。这包括特定时间戳、特定结构化范围或重影层的数量(即,用于计算邻域信息的边界层)。此外,在请求传递期间,允许每个滤波器修改来自下游的请求。例如,不能流式传输的滤波器(例如,流线型滤波器)可以忽略该片段请求并要求整个数据。
2.4 渲染子系统
乍一看,VTK有一个简单的面向对象的渲染模型,其中的类对应于构成3D场景的组件。 例如,vtkActor是由vtkRenderer与vtkCamera一起渲染的对象,同时在vtkRenderWindow中可能存在多个vtkRenderer。渲染场景由一个或多个vtkLights照亮。每个vtkActor的位置由vtkTransform控制,并且通过vtkProperty来指定vtkActor的外观。最后,vtkActor的几何表示由vtkMapper定义。Mappers在VTK中发挥着重要作用,它们用于终止数据处理管道,并提供与渲染系统的接口。考虑这个示例,我们抽取数据并将结果写入文件,然后使用mapper可视化并与结果交互:
vtkOBJReader *reader = vtkOBJReader::New();
reader->SetFileName("exampleFile.obj");
vtkTriangleFilter *tri = vtkTriangleFilter::New();
tri->SetInputConnection(reader->GetOutputPort());
vtkQuadricDecimation *deci = vtkQuadricDecimation::New();
deci->SetInputConnection(tri->GetOutputPort());
deci->SetTargetReduction( 0.75 );
vtkPolyDataMapper *mapper = vtkPolyDataMapper::New();
mapper->SetInputConnection(deci->GetOutputPort());
vtkActor *actor = vtkActor::New();
actor->SetMapper(mapper);
vtkRenderer *renderer = vtkRenderer::New();
renderer->AddActor(actor);
vtkRenderWindow *renWin = vtkRenderWindow::New();
renWin->AddRenderer(renderer);
vtkRenderWindowInteractor *interactor = vtkRenderWindowInteractor::New();
interactor->SetRenderWindow(renWin);
renWin->Render();
这里创建了一个actor、renderer和render window,并添加了一个将管线连接到渲染系统的mapper。另外注意添加vtkRenderWindowInteractor,其实例可以捕获鼠标和键盘事件并将其转换为相机操作或其他操作。此转换过程通过vtkInteractorStyle定义(更多内容见下文)。默认情况下,会在后台设置许多实例和数据值。例如,会创建一个单位转换矩阵,以及一个默认(头部)光源和属性。
随着时间的推移,这个对象模型变得更加复杂。大部分复杂性来自于专门用于渲染过程方面的派生类。vtkActor现在是vtkProp的特化(派生类)(就像在舞台上找到的道具一样),并且有大量这种prop用于渲染2D叠加图形和文本、专用3D对象、甚至对高级渲染技术的支持,如体渲染或GPU实现(见图4)。
同样,随着VTK支持的数据模型的增长,将数据与渲染系统连接的各种映射器(mapper)也在增长。另一个重要扩展领域是转换(transformation)的层次结构。最初的简单线性4×4变换矩阵,已变成支持非线性变换(包括薄板样条变换)的强大层次结构。例如,原始的vtkPolyDataMapper现在有了特定于设备的子类(例如,vtkOpenGLPolyDataMapper)。近年来,它被一种复杂的图形管线所取代,被称为图24.4所示的“painter”管线。
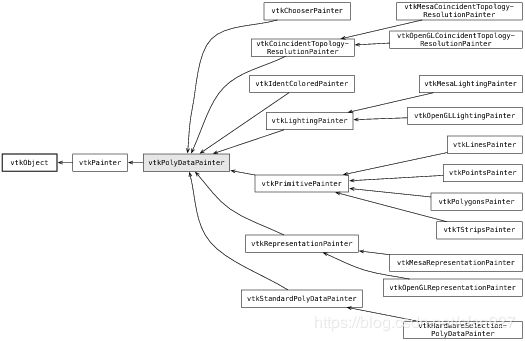
图 4 显示功能类
painter的设计支持各种数据渲染技术,这些技术可以组合以提供特殊的渲染效果。这个功能大大超过了最初在1994年实现的简单的vtkPolyDataMapper。
可视化系统的另一个重要方面是子系统的选择。在VTK中,存在“拾取器”(“pickers”)的类层次结构,对于vtkProp的选择,大致分类为基于硬件的方法以及软件方法(例如,光线投射);以及在拾取操作之后提供不同级别信息的对象。例如,某些拾取器仅提供XYZ世界空间中的位置,而不指示他们选择了哪个vtkProp; 而其它的拾取器不仅提供选定的vtkProp,还提供由特定点或单元格构成、用于定义prop几何结构的网格。
2.5 事件和交互
与数据交互是可视化的重要组成部分。在VTK中,这以各种方式发生。在最简单的级别,用户可以通过命令(命令/观察者设计模式)观察事件并做出适当的响应。vtkObject的所有子类都维护一个观察者列表,这些观察者将自己注册到对象中。在注册期间,观察者指定他们感兴趣的特定事件,并添加在事件发生时调用的相关命令。要了解其工作原理,请考虑以下示例,其中滤波器(此处为多边形抽取滤波器)具有一个观察者,该观察者监听StartEvent、ProgressEvent和EndEvent三个事件。当滤波器开始执行时会定期调用这些事件,并滤波器执行完毕后结束调用。在下文中,vtkCommand类有一个Execute方法,该方法打印出与执行算法所需时间相关的信息:
class vtkProgressCommand : public vtkCommand
{
public:
static vtkProgressCommand *New() { return new vtkProgressCommand; }
virtual void Execute(vtkObject *caller, unsigned long, void *callData)
{
double progress = *(static_cast<double*>(callData));
std::cout << "Progress at " << progress<< std::endl;
}
};
vtkCommand* pobserver = vtkProgressCommand::New();
vtkDecimatePro *deci = vtkDecimatePro::New();
deci->SetInputConnection( byu->GetOutputPort() );
deci->SetTargetReduction( 0.75 );
deci->AddObserver( vtkCommand::ProgressEvent, pobserver );
虽然这是一种很原始的交互形式,但它是许多使用VTK的应用程序的基础要素。例如,上面的简单代码可以很容易地转换并用于显示和管理GUI进度条。此命令/观察者子系统也是VTK中3D小部件的核心,这些小部件是用于查询、操作和编辑数据的复杂交互对象,如下所述。
参考上面的示例,重点要注意的是VTK中的事件是预定义的,但是也有用于用户自定义事件的接口。类vtkCommand定义了一组枚举事件(例如,上例中的vtkCommand :: ProgressEvent)以及一个用户事件。UserEvent(它只是一个整数值)通常用作一组应用程序中用户定义事件的起始偏移值。因此,例如vtkCommand :: UserEvent + 100可能会引用到VTK定义事件集之外的特定事件。
从用户的角度来看,VTK小部件在场景中显示为actor,除了用户可以通过操纵手柄或其他几何特征与其交互(手柄操作和几何特征操作基于前面描述的拾取功能)。使用此小部件非常直观:用户抓住球形手柄并移动它们,或者抓住线并移动它。然而,在幕后,发出事件(例如,InteractionEvent),则一个编写合理的应用程序就可以观察这些事件,然后采取适当的行动。例如,它们经常在vtkCommand :: InteractionEvent上触发,如下所示:
vtkLW2Callback *myCallback = vtkLW2Callback::New();
myCallback->PolyData = seeds; // streamlines seed points, updated on interaction
myCallback->Actor = streamline; // streamline actor, made visible on interaction
vtkLineWidget2 *lineWidget = vtkLineWidget2::New();
lineWidget->SetInteractor(iren);
lineWidget->SetRepresentation(rep);
lineWidget->AddObserver(vtkCommand::InteractionEvent,myCallback);
VTK小部件实际上是使用两个对象构建的:vtkInteractorObserver的子类和vtkProp的子类。vtkInteractorObserver简单地观察渲染窗口中的用户交互(即鼠标和键盘事件)并处理它们。vtkProp的子类(即actor)由vtkInteractorObserver简单地操作。通常,这种操作包括修改vtkProp的几何信息、突出显示手柄、更改光标外观和/或变换数据。当然,这些小部件的特殊细节要求编写子类来控制其行为的细微差别,并且系统中当前有超过50个不同的小部件。
2.6 VTK中可用的库概述
VTK是一个大型软件工具包。目前,该系统包含大约150万行代码(包括注释但不包括自动生成的包装层软件)和大约1000个C ++类。为了管理系统的复杂性并减少构建和链接时间,系统已被划分为数十个子目录。表24.1列出了这些子目录,并简要概述了这些库所提供的功能。
| 模块文件夹 | 说明 |
|---|---|
| Common | VTK核心类 |
| Filtering | 用于管理管线数据流的类 |
| Rendering | 渲染、拾取、图像查看,以及交互 |
| VolumeRendering | 体绘制技术 |
| Graphics | 三维几何处理 |
| GenericFiltering | 非线性三维几何处理 |
| Imaging | 图像处理管线 |
| Hybrid | 需要使用图形学和图像处理功能的类 |
| Widgets | 复杂的交互 |
| IO | VTK的输入和输出 |
| Infovis | 信息可视化 |
| Parallel | 并行处理(控制器和通信器) |
| Wrapping | 对于Tcl、Python和Java封装的支持 |
| Examples | 内容广泛、文档齐全的示例 |
表1 VTK的子目录
3 回顾及展望
VTK是一个非常成功的系统。虽然第一行代码是在1993年编写的,但在撰写本文时,VTK仍然在不断发展壮大,并且发展速度正在加快。在本节中,我们将讨论一些经验教训和未来的挑战。
3.1 成长管理
VTK的发展历程中,最令人惊叹的方面一个就是该项目的长寿。其这种发展速度主要有以下几个原因:
- 新算法和功能被持续不断地添加。例如,信息学子系统(Titan,主要由桑迪亚国家实验室和Kitware开发)是最近添加的一个重要部分。还添加了其他图表和渲染类,以及对新的科学数据集类型的支持。另一个重要的补充是3D交互小部件。最后,基于GPU的渲染和数据处理的持续演进正在推动VTK的新功能产生;
- VTK不断增多的曝光和使用是一个自我延续的过程,这也为社区增加了更多的用户和开发者。例如,ParaView是最受欢迎的基于VTK的科学可视化应用程序,在高性能计算社区中备受推崇。3D Slicer是一个主要的生物医学计算平台,它主要基于VTK,并且每年获得数百万美元的资助;
- VTK的开发过程不断演进。近年来,软件处理工具CMake,CDash,CTest和CPack已集成到了VTK的构建环境中。最近,VTK代码库已经移植到Git和一个更复杂的工作流。这些改进确保VTK始终处于科学计算社区软件开发的领先位置。
虽然成长是令人兴奋的,验证了软件系统的创建,并预示着VTK的未来,但管理起来非常困难。因此,近期VTK将更注重管理社区和软件的成长。为此,已经采取了若干措施。
首先,正在建立正式的管理结构。建立了架构评审委员会,以指导社区和技术的发展,重点关注高层次的、战略性的问题。同时,VTK社区正在组建一个由意见领袖组成的公认的团队,以指导特定VTK子系统的技术开发。
其次,制定了一系列进一步模块化工具包的计划,部分是为了响应git引入的工作流功能,还要意识到用户和开发者通常希望使用工具包的小型子系统,并且不希望构建和链接整个工具包。此外,为了支持不断增长的社区,对于新功能和子系统的支持是非常重要的,即使它们不一定是工具包核心的一部分。通过创建低耦合的、模块化的模块集合,可以在适应大量外围代码贡献的同时保持核心的稳定性。
3.2 技术成长
除软件过程外,开发流程中还有许多技术创新。
- 协同处理是将可视化引擎集成到仿真代码中的功能,并定期生成用于可视化的数据。该技术大大减少了输出大量完整解决方案数据的需求;
- VTK中的数据处理管线仍然过于复杂。正在采取方法来简化和重构该子系统;
- 直接与数据交互的能力越来越受用户欢迎。虽然VTK拥有大量小部件,但一直会出现更多的交互技术,包括基于触摸屏和3D的方法。交互模块将会继续快速开发。
- 计算化学对材料设计师和工程师的重要性日益增加。VTK正在添加可视化和与化学数据交互的能力。
- VTK中的渲染系统因过于复杂而受到诟病,因此难以派生新类或支持新的渲染技术。此外,VTK并不直接支持场景图的概念,这也是许多用户所要求的。
- 最后,新形式的数据不断出现。例如,在医学领域中具有不同分辨率的分层体积数据集(例如,具有局部放大率的共聚焦显微镜)。
3.3 开放的科学
最后,Kitware以及VTK社区致力于开放科学。实际上,这说明我们将发布公开数据、公开刊物和开源,这也是我们创建可重复的科学系统所必需的特征。虽然VTK长期以来作为开源和开放数据系统进行分发,但一直缺乏文档过程。在有正式书籍[Kit10,SML06]的同时,还有各种各样的其他方法来收集包括最新源码在内的技术出版物。我们正在通过开发像VTK Journal3这样的新的期刊来改善这种情况,该期刊支持包含文档、源代码、数据和有效测试图像的文章。该期刊还支持自动化审查代码(使用VTK的质量软件测试流程)以及对提交文章的人工审查。
3.4 得到的教训
虽然VTK取得了成功,但有很多事情我们没有处理好:
- 设计模块化:我们在选择我们的类的模块化方面做得很好。例如,我们没有像为每个像素创建一个对象那样愚蠢,而是我们创建了更高层次的vtkImageClass,它在内部处理像素数据组成的数组。然而,在某些情况下,我们让我们的类变得太高级而且太复杂,在许多情况下我们不得不将它们重构为更小的部分,并且继续这个过程。一个基本的例子是数据处理管线。最初,管线是通过数据和算法对象的交互隐式实现的。我们最终意识到我们必须创建一个显式的管线执行对象来协调数据和算法之间的交互,并实现不同的数据处理策略;
- 遗漏的关键概念:我们最大的遗憾之一就是没有广泛使用C ++迭代器。在许多情况下,VTK中的数据遍历类似于科学编程语言Fortran。迭代器提供的额外灵活性对系统来说有很大的帮助。例如,对于处理局部区域的数据或仅处理满足某些迭代标准的数据是非常有优势的;
- 设计问题:当然,有一长串并非最优的设计决策。我们一直在努力应对数据执行流程,已经经历了很多代,每次都设计的更好一些。渲染系统也很复杂,并且难以从中派生出子类。另一个由最初的VTK概念产生的挑战是:我们将其视为用于查看数据的只读可视化系统。但是,目前的客户通常希望它能够编辑数据,这就需要完全不同的数据结构。
像VTK这样的开源系统的一大优势是,许多这些错误可以并且将会随着时间的推移而得到纠正。我们拥有一个活跃的、有能力的开发社区,每天都在改进系统,并且在可预见的未来,我们希望这种情况能够维持下去。
脚注
- http://en.wikipedia.org/wiki/Opaque_pointer
- 请参阅最新的VTK代码分析: http://www.ohloh.net/p/vtk/analyses/latest
- http://www.midasjournal.org/?journal=35