天池工业蒸汽量预测代码及详解
文章目录
- 1、赛题介绍
- 2、数据梳理
- 3、建模过程
- 4、总结
1、赛题介绍
赛题背景
火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。
赛题描述
经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量。
数据说明
数据分成训练数据(train.txt)和测试数据(test.txt),其中字段”V0”-“V37”,这38个字段是作为特征变量,”target”作为目标变量。选手利用训练数据训练出模型,预测测试数据的目标变量,排名结果依据预测结果的MSE(mean square error)。
结果提交
选手需要提交测试数据的预测结果(txt格式,只有1列预测结果)。
结果评估
预测结果以mean square error作为评判标准。
赛题数据
https://tianchi.aliyun.com/competition/entrance/231693/information
2、数据梳理
官方页面提供了两个 txt 格式的数据,一个作为训练集’zhengqi_train.txt’是我们建模的依据,另一个为最后评分的‘zhengqi_test.txt’。
现在我们查看数据具体情况:
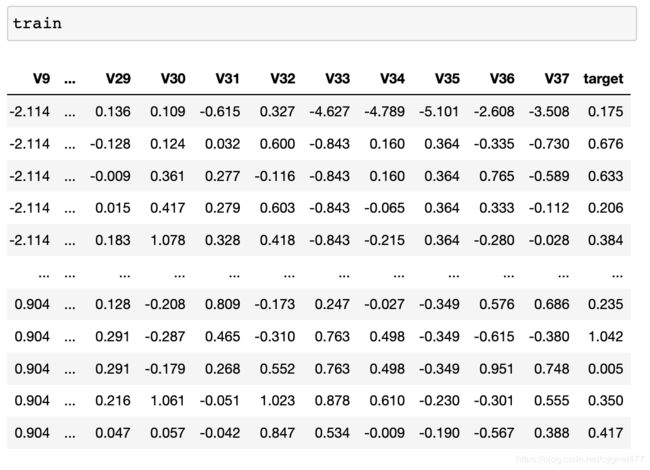
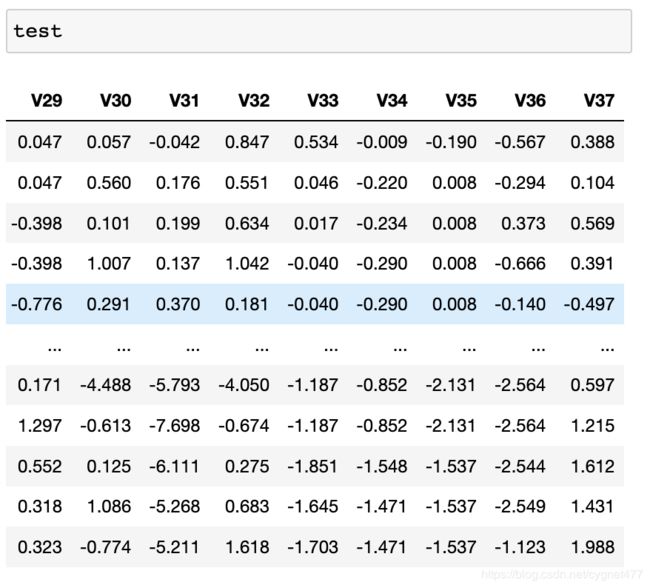
其中 train 数据包含从 V0-V37 的 38 个特征,以及目标值 target;test 则只包含从 V0-V37 的 38 个特征;
很明显这是一个回归问题,我们将采取各类回归模型来进行建模;
此次数据建模中,我们的核心思想是,采用多种建模方式来一一测试 MSE 值,最后选取 MSE 值较小的几类模型,通过平均的方式获得最后的目标值;
3、建模过程
导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression,Lasso,Ridge,ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor,AdaBoostRegressor,ExtraTreesRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler,StandardScaler,PolynomialFeatures
import warnings
warnings.filterwarnings('ignore')
导入数据
test=pd.read_csv('zhengqi_test.txt',sep='\t')
train=pd.read_csv('zhengqi_train.txt',sep='\t')
构建数据标签、数据合并
train['origin']='train'
test['origin']='test'
data=pd.concat([train,test])
特征探索
绘制出训练集与测试集中各个特征的核密度分布;
将训练集特征与测试集特征绘制在一个图表中的好处是,可以看出测试集与训练集的特征分布对比情况,且可以迅速挑选出特征不明显的予以剔除;
plt.figure(figsize=(10,38*6))
for i,col in enumerate(data.columns[:-2]):
cond=data['origin']=='train'
train_col=data[col][cond]
cond=data['origin']=='test'
test_col=data[col][cond]
axes = plt.subplot(38,1,i+1)
ax=sns.kdeplot(train_col,shade=True)
sns.kdeplot(test_col,shade=True,ax=ax)
删除特征
由上图可知,V5、V11、V17、V22四个特征,测试集与训练集中数据分布有较大差异,为了避免影响最后的训练模型,将其予以剔除;
rop_lables=['V5','V11','V17','V22']
data.drop(drop_lables,axis=1,inplace=True)
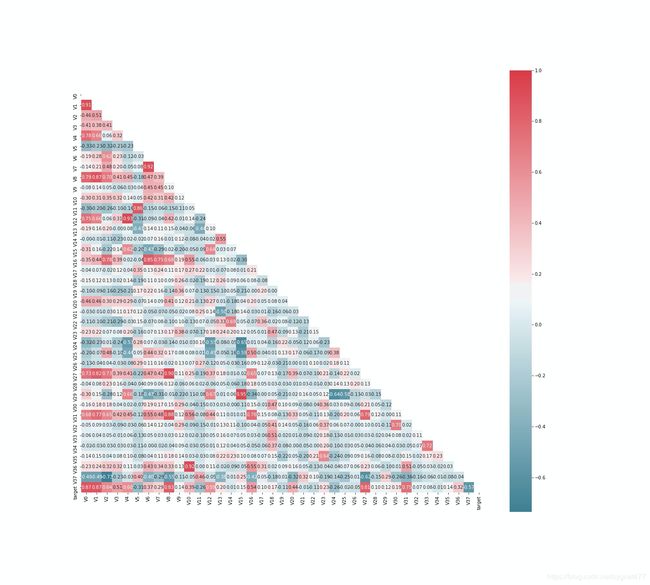
相关性系数
通过相关性系数,获取训练集中与目标值target相关性不高的特征,并予以剔除;
train_corr=train.corr()
cond=abs(train_corr['target'])<0.1
drop_lables=train_corr.loc['target'].index[cond]
#查看分布 分布良好的特征暂时不删除
drop_lables=['V14','V21']
data.drop(drop_lables,axis=1,inplace=True)
绘制相关性系数热力图
plt.figure(figsize=(20,18))
mask = np.zeros_like(train_corr, dtype=np.bool) # 构造与mcorr同维数矩阵 为bool型
mask[np.triu_indices_from(mask)] = True # 角分线右侧为True
# 颜色
cmap = sns.diverging_palette(220, 10, as_cmap=True) # 返回matplotlib colormap对象
g=sns.heatmap(train_corr,fmt='0.2f',square=True,annot=True,cmap=cmap,mask=mask)
plt.show()
特征标准化
std=StandardScaler()
#将除标签和目标值之外的特征标准化
data_fit=std.fit_transform(data.iloc[:,:-2])
data_fit#此处data_fit 为 array,需转化为dataframe格式
data_fit=pd.DataFrame(data_fit,columns=data.columns[:-2])
data.index=np.arange(len(data))#修改data行索引,重新排序
#将目标值+标签与标准化后的特征合并
data_std=pd.merge(data_fit,data.iloc[:,-2:],right_index=True,left_index=True)
过滤异常值
from sklearn.linear_model import RidgeCV
ridge=RidgeCV(alphas=[0.0001,0.001,0.01,0.1,0.2,0.5,1,2,3,4,5,10,20,30,50])
#提取x_train,y_train
x_train=data_std[data_std['origin']=='train'].iloc[:,:-2]
y_train=data_std[data_std['origin']=='train']['target']
#先用岭回归进行拟合,若异常(3σ原则)较为明显,则可将该样本过滤
ridge.fit(x_train,y_train)
y_train_predict=ridge.predict(x_train)
cond=(y_train-y_train_predict).abs() > 0.8*y_train.std()
cond.sum()
此处过滤异常样本的基本思想为:利用岭回归先对train 数据进行建模,建模后的获取 x_train的预测值y_train_predict,若真实值与预测值相减的绝对值 |y_train-y_train_predict| >α*y_train.std(),则判定该样本为异常值;此处α参数经过多次测试,取了0.8 较为合适;
将其过程可视化如下:
plt.figure(figsize=(12,6))
axes=plt.subplot(1,3,1)
axes.scatter(y_train,y_train_predict)
axes.scatter(y_train[cond],y_train_predict[cond],c='red')
axes=plt.subplot(1,3,2)
axes.scatter(y_train,y_train_predict-y_train)
axes.scatter(y_train[cond],(y_train_predict-y_train)[cond],c='red')
axes=plt.subplot(1,3,3)
(y_train - y_train_predict).plot.hist(bins = 50,ax = axes)
(y_train - y_train_predict).loc[cond].plot.hist(bins = 50,ax = axes,color = 'r')
plt.savefig('ridge.jpg')
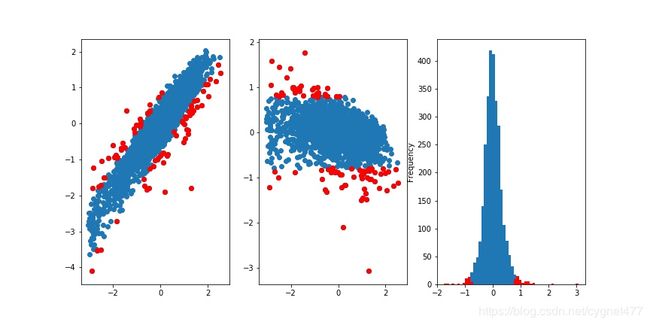 上述红点均为异常值
上述红点均为异常值
#获取行索引,异常值过滤
drop_index=x_train[cond].index
data_std.drop(drop_index,axis=0,inplace=True)
模型建立–预测结果 1
#创建一个计算误差、得分的函数
def model_test(estimators,data):
for key,estimator in estimators.items():
estimator.fit(data[0],data[2])
y_predict=estimator.predict(data[1])
mse=mean_squared_error(data[3],y_predict)
print('----------------MSE of %s-------------'%(key),mse)
scores=estimator.score(data[1],data[3])
print('----------------Score of %s-------------'%(key),scores)
print('\n')
#将所有算法放进一个字典,根据最后输出结果可知:由于 lasso 等算法误差较大,故舍去;而Linear、Ridge算法由于过拟合,训练集中误差较小,而测试集误差很大,故也舍去;
estimators={}
#estimators['KNN']=KNeighborsRegressor()
#estimators['Linear']=LinearRegression()
#estimators['ridge'] = Ridge()
#estimators['lasso'] = Lasso()
#estimators['elasticnet'] = ElasticNet()
estimators['forest'] = RandomForestRegressor()
estimators['gbdt'] = GradientBoostingRegressor()
#estimators['ada'] = AdaBoostRegressor()
estimators['extreme'] = ExtraTreesRegressor()
estimators['svm_rbf'] = SVR(kernel='rbf')
#estimators['svm_poly'] = SVR(kernel='poly')
estimators['light'] = LGBMRegressor()
estimators['xgb'] = XGBRegressor()
#获取分割后的数据
cond=data_std['origin']=='train'
x=data_std[cond].iloc[:,:-2]
y=data_std[cond]['target']
data_model=train_test_split(x,y,test_size=0.2)
x_test=data_std[data_std['origin']=='test'].iloc[:,:-2]
#查看各类算法的平均得分及误差
model_test(estimators,data_model)
最后输出结果为:
----------------MSE of KNN------------- 0.14407663957142858
----------------Score of KNN------------- 0.8279221612057038
----------------MSE of Linear------------- 0.08034253722099605
----------------Score of Linear------------- 0.9040429440236547
----------------MSE of ridge------------- 0.0802383113854996
----------------Score of ridge------------- 0.904167426081066
----------------MSE of lasso------------- 0.8378137347195871
----------------Score of lasso------------- -0.000642277690338755
----------------MSE of elasticnet------------- 0.4890212283648852
----------------Score of elasticnet------------- 0.4159378206496642
----------------MSE of forest------------- 0.08790644563696427
----------------Score of forest------------- 0.8950089950300532
----------------MSE of gbdt------------- 0.084364881166206
----------------Score of gbdt------------- 0.8992388602038354
----------------MSE of ada------------- 0.10796008174004974
----------------Score of ada------------- 0.8710579480674716
----------------MSE of extreme------------- 0.08511244064821429
----------------Score of extreme------------- 0.898346013032935
----------------MSE of svm_rbf------------- 0.10279139773209457
----------------Score of svm_rbf------------- 0.8772311623799739
----------------MSE of svm_poly------------- 0.20920052602955114
----------------Score of svm_poly------------- 0.7501414906616557
----------------MSE of light------------- 0.07864206409721353
----------------Score of light------------- 0.906073902969801
----------------MSE of xgb------------- 0.08401340501246428
----------------Score of xgb------------- 0.8996586455146498
根据最后输出结果可知:由于 lasso 等算法误差较大,故舍去;而Linear、Ridge算法由于过拟合,训练集中误差较小,而测试集误差很大,故也舍去;
#将x_test基于各类模型的预测结果做平均
y_test_pred=[]
for key,model in estimators.items():
model.fit(x_train,y_train)
y_=model.predict(x_test)
y_test_pred.append(y_)
y_t_predict=np.mean(y_test_pred,axis=0)
#将获得的预测结果y保存为txt格式
pd.Series(y_t_predict).to_csv('./predict.txt',index=False)
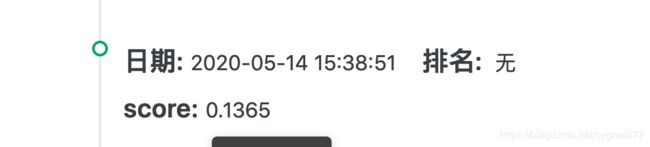
由此,我们获得了第一个测试数据预测结果 predict,将其上传至天池官网,获得最后误差评估为:0.1365
模型建立–预测结果 2
基于上面的建模结果,我们将建模获得的测试集中各个模型的预测结果再次作为新的特征进行建模,由此我们由 32 个特征增加至 38 个特征(效果不好的模型未使用)
#将第一次不同模型的预测的结果作为新特征,再次进行学习
for key,model in estimators.items():
model.fit(x_train,y_train)
y_train_feature=model.predict(x_train)
x_train[key]=y_train_feature
y_test_feature=model.predict(x_test)
x_test[key]=y_test_feature
#由此,x_train\x_test都增加了基于上述6个模型的预测结果作为特征
#最后效果不太好,预测误差变大
y_test_pred=[]
for key,model in estimators.items():
model.fit(x_train,y_train)
y_=model.predict(x_test)
y_test_pred.append(y_)
y_t_predict=np.mean(y_test_pred,axis=0)
pd.Series(y_t_predict).to_csv('./predict2.txt',index=False)
由此,我们获得了第二个测试数据预测结果 predict2,将其上传至天池官网,获得最后误差评估为:0.1453,略高于第一次建模的结果;

模型建立–预测结果3
第三次尝试,我们将上述数据的标准化的过程改为归一化,其他照旧,看是否能得到更好的建模结果;
#归一化
data_features=data.iloc[:,:-2]
mm=MinMaxScaler(feature_range=(0,1))
data_features=mm.fit_transform(data_features)
data_features=pd.DataFrame(data_features,columns=data.columns[:-2])
data_mm=pd.merge(data_features,data.iloc[:,-2:],right_index=True,left_index=True)
#岭回归过滤异常值
from sklearn.linear_model import RidgeCV
ridge=RidgeCV(alphas=[0.0001,0.001,0.01,0.1,0.2,0.5,1,2,3,4,5,10,20,30,50])
#提取x_train,y_train
x_train=data_mm[data_mm['origin']=='train'].iloc[:,:-2]
y_train=data_mm[data_mm['origin']=='train']['target']
#先用岭回归进行拟合,若异常较为明显,则可过滤,3σ原则
ridge.fit(x_train,y_train)
y_train_predict=ridge.predict(x_train)
cond=(y_train-y_train_predict).abs() > 0.8*y_train.std()
cond.sum()
#可视化表示
plt.figure(figsize=(12,6))
axes=plt.subplot(1,3,1)
axes.scatter(y_train,y_train_predict)
axes.scatter(y_train[cond],y_train_predict[cond],c='red')
axes=plt.subplot(1,3,2)
axes.scatter(y_train,y_train_predict-y_train)
axes.scatter(y_train[cond],(y_train_predict-y_train)[cond],c='red')
axes=plt.subplot(1,3,3)
(y_train - y_train_predict).plot.hist(bins = 50,ax = axes)
(y_train - y_train_predict).loc[cond].plot.hist(bins = 50,ax = axes,color = 'r')
#获取行索引,异常值过滤
drop_index=x_train[cond].index
data_mm.drop(drop_index,axis=0,inplace=True)
data_mm
#创建一个计算误差、得分的函数
def model_test(estimators,data):
for key,estimator in estimators.items():
estimator.fit(data[0],data[2])
y_predict=estimator.predict(data[1])
mse=mean_squared_error(data[3],y_predict)
print('----------------MSE of %s-------------'%(key),mse)
scores=estimator.score(data[1],data[3])
print('----------------Score of %s-------------'%(key),scores)
print('\n')
#将所有算法放进一个字典 由于 lasso 等算法误差较大,故舍去,回归算法过拟合,舍去
estimators={}
#estimators['KNN']=KNeighborsRegressor()
#estimators['Linear']=LinearRegression()
#estimators['ridge'] = Ridge()
#estimators['lasso'] = Lasso()
#estimators['elasticnet'] = ElasticNet()
estimators['forest'] = RandomForestRegressor()
estimators['gbdt'] = GradientBoostingRegressor()
#estimators['ada'] = AdaBoostRegressor()
estimators['extreme'] = ExtraTreesRegressor()
estimators['svm_rbf'] = SVR(kernel='rbf')
#estimators['svm_poly'] = SVR(kernel='poly')
estimators['light'] = LGBMRegressor()
estimators['xgb'] = XGBRegressor()
#获取分割后的数据
cond=data_mm['origin']=='train'
x=data_mm[cond].iloc[:,:-2]
y=data_mm[cond]['target']
data_model=train_test_split(x,y,test_size=0.2)
x_test=data_mm[data_mm['origin']=='test'].iloc[:,:-2]
model_test(estimators,data_model)
y_test_pred=[]
for key,model in estimators.items():
model.fit(x_train,y_train)
y_=model.predict(x_test)
y_test_pred.append(y_)
y_t_predict=np.mean(y_test_pred,axis=0)
pd.Series(y_t_predict).to_csv('./predict3.txt',index=False)
由此,我们获得了第三个测试数据预测结果 predict3,将其上传至天池官网,获得最后误差评估为:0.1347,略低于第一次建模的结果;

4、总结
其实还可以做更多的尝试,比如对新增特征,新增模型,对各类模型权重参数取值进行调整来获取最合适的模型,由于 篇幅有限,这里不再赘述。
上述过程,如有疑问,欢迎随时留言哦~