概率破玄机,统计解迷离
概率破玄机,统计解迷离
概率论起源于中世纪的欧洲,那时盛行掷骰子赌博,提出了许多有趣的概率问题。当时法国的帕斯卡(Blaise Pascal)、费尔马(Pierre de Fermat)和旅居巴黎的荷兰数学家惠更斯(Christiaan Huygens)都对此类问题感兴趣,他们用组合数学研究了许多与掷骰子有关的概率计算问题。20世纪30年代柯尔莫哥洛夫(Andrey Nikolaevich Kolmogorov)提出概率公理化, 随后概率论迅速发展成为数学领域里一个独立分支。
随机现象背后是隐藏某些规律的,概率论的一项基本任务就是揭示这些规律。现在概率论已经发展成为数学领域里一个相对充满活力的学科,并且在工程、国防、生物、经济和金融等领域得到了广泛的应用。
统计学是一门具有方法论性质的应用性科学, 它在概率论基楚上, 发展出一系列的原理和方法,研究如何采集和整理反映事物总体资训的数字资料,并依据这些复杂的资料(称为样本)对总体的特征和现象背后隐藏的规律进行分析和推断。
法国数学家拉普拉斯(Pierre-Simon marquis de Laplace)有句名言:“生活中最重要的问题,绝大部分其实只是概率问题”。当代国际著名的统计学家 C. R.劳(Rao)说过:“如果世界中的事件完全不可预测的随机发生, 则我们的生活是无法忍受的。而与此相反, 如果每一件事都是确定的、完全可以预测的,则我们的生活将是无趣的。”
我长期从事概率论和随机分析研究,对概率统计学科的本质有些领悟,曾写过下面这首“悟道诗”:
无序隐有序,统计解迷离。
本文试图通过若干日常生活中的一些例子来向大家展示概率是如何破玄机和统计是如何解迷离的。
1.什么是随机和随意?
在社会和自然界中,我们经常遇到一些事件,因为有很多不确定的偶然因素很难判断它会发生或不发生, 这样的事件就是所谓的随机事件或偶然事件。
概率则是对随机事件发生的可能性大小的一个度量。必然要发生的事件的概率规定为 1 ,不可能发生的事件的概率规定为 0 ,其他随机事件发生的概率介乎 0 与 1 之间。
例如,拋一枚匀质的硬币,出现正面或反面的概率均为二分之一;掷一个匀质的骰子,每个面出现朝上的概率均为六分之一。在这两个例子中,每个简单事件(或“场景”)都是等可能发生的。一个复合事件(如掷骰子出现的点数是偶数)发生的概率就等于使得该复合事件发生的场景数目与可能场景总数之比。
什么是随意?随意就是带有主观意识的一种随机。
比方说,我们知道掷一枚匀质硬币出现正面或反面的概率都是 1/2 。如果让某人臆想一个相继掷 50 次硬币的可能结果,并用 1 和 0 分別表示出现“正面”和“反面”,在一张纸上写下来, 由于他考虑到接连多次出现正面或反面的可能性较小,在他写 1 和 0 时,可能有意识避免连写三个或四个以上的 1 或 0 ,这样产生的 0−1 序列就是“随意的”。它看似随机,但与真实做一次掷 50 次硬币记录下的結果在统计特性上是有区別的。
随机现象背后是隐藏某些规律的, 概率论的一项基本任务就是揭示这些规律。
2.靠直觉做判断常常会出错
下面是一个靠直觉做判断容易出错的例子。 某人新来邻居是一对夫妇, 只知道这对夫妇有两个非双胞胎孩子。 某天, 看到爸爸领着一男孩出门了, 问这对夫妇的另一孩子也是男孩的概率是多大?许多人可能给出的答案是 1/2 , 因为生男生女的概率都是 1/2 。但实际上正确答案应该是 1/3 ,因为在已知该家至少有一男孩的前提下,他家两个小孩可能的场景是三个(按孩子出生先后次序) :“男男”,“男女”,“女男”。只有“男男”才符合“另一孩子也是男孩”这一场景。如果突然从这家传出婴儿的啼哭声,“另一孩子也是男孩”的概率就变成 1/2 了,因为这时可以断定出了门的那个男孩是老大,可能的场景就变成两个了(按出生先后次序) :男男,男女。
从这两个简单初等概率问题可以悟出一个道理:靠直觉做判断常常会出错。计算一个随机事件发生的概率, 重要的是要对此事件得以发生的所有可能场景有正确的判断。
3.改变生育政策会引起性別比例失衡吗?
下面这个例子更加说明单靠直觉做判断容易出错。假定有一项新的生育政策, 规定头胎生男孩的不可以生第二胎,但允许头胎生女孩的生第二胎(当然也可以选择不再生),试问:这一政策会引起性別比例失衡吗? 从直觉上看,似乎这一政策有利于生男孩,但这一担心是多余的, 因为生男生女的概率都是 1/2 ,第一胎的小孩性別比例不会失衡,第二胎的小孩性別比例也不会失衡,总体来说,生育政策不回造成性別比例失衡。由于女人生小孩的胎数有一致的上界(比如说不超过 20 胎),用概率分析可以断言:即使有政策,允许妇女直到首次生出男孩才终止生育, 理论上讲也不会引起性別比例失衡。
如何解释现实中存在的性別比例失衡呢? 一方面,由于过去曾允许怀孕期间做性別检验, 有的妇女发现怀的是女孩就堕胎了; 另一方面, 一些人重男轻女思想造成幼年女孩夭折的比例高于男孩。
4.“生日悖论”
n 个人中至少有两人生日相同的概率是多少?这是有名的“生日问题”。令人难以置信的是:随机选取的 23 人中至少两人生日相同的概率居然超过 50% , 50 人中至少两人生日相同的概率居然达到 97% !例如,假定一个中学有二十个班,每个班平均有 50 个学生,你可以调查一下, 大概会有十几个班都有至少两个生日相同的学生。这和人们的直觉是抵触的。因此这一结果被称为“生日悖论”。
其实有关概率的计算很简单, 首先计算 50 个人生日都不相同的概率。 第一个人的生日有 365 个可能性,第二个人如果生日与第一个人不同,他的生日有 364 个可能性,依次类推,直到第 50 个人的生日有 316 个可能性,所以 50 人生日都不同的可能组合方式就是 365 乘 364 乘 363 一直乘到 316 ,但由于每个人的生日是独立的,总的可能组合是 365 的 50 次方,这样一来, 50 个人生日都不相同的概率就等于两个组合数之比,这个概率非常小,只有 3% ,至少两个人生日相同的概率等于 1 减去 3% ,得到 97% ,这样概率就计算出来了。
注意: 如果预先选定一个生日,随机选取 125 人、 250 人、 500 人、 1000 人,出现某人生日正好是选定生日的概率分別大约只有 30%、50%、75%、94% ,比想象的小得多。
5.“三枚银币”骗局
某人在街头设一赌局。他向观众出示了放在帽子里的三枚银币(记为甲、乙、丙),银币甲的两面涂了黑色,银币丙的两面涂了红色,银币乙一面涂了黑色,另一面涂了红色。
游戏规则是:他让一个观众从帽子里任意取出一枚银币放到桌面上(这里不用“投掷银币”是为了避免暴露银币两面的颜色),然后由设局人猜银币另一面的颜色,如果猜中了,该参与者付给他1元钱,如果猜错了,他付给该参与者1元钱。
试问:这一赌局是公平的吗? 从直觉上看, 无论取出的银币所展示的一面是黑色或红色,另一面是红色或黑色的概率都是 1/2 , 这一赌局似乎是公平的。但实际上不公平,设局者只要每次“猜”背面和正面是同一颜色,他的胜算概率是 2/3 , 因为从这三张牌随机选取一枚银币,其两面涂相同颜色的概率就是 2/3 。如果有许多人参与赌局, 大概有 1/3 的人会赢钱, 2/3 的人会输钱。
下面进一步用“场景分析”来戳穿“三枚银币”骗局。假定参与者取出并放到桌面上的银币展示面是黑色,则这枚银币只可能是银币甲或乙。“银币展示面是黑色”这一随机事件有三种可能场景:银币甲的“某一面”和“另一面”,或银币乙的“涂黑一面“。因此,这枚银币是银币甲的概率是 2/3 。展示面是红色情形完全类似。因此, 每次“猜”另一面和展示面是同一颜色的胜算概率是 2/3 。
下面这个例子是从“三枚银币”骗局衍生出来的。假设在你面前放置三个盒子,盒子里分别放了金币两枚、银币两枚、金银币各一枚。你随机选取一个盒子并从中摸出一枚钱币,发现是一枚金币。试问:该盒子装有两枚金币的概率有多大? 请你给出答案。
6.在猜奖游戏中改猜是否增大中奖概率?
这一问题出自美国的一个电视游戏节目, 问题的名字来自该节目的主持人蒙提 • 霍尔, 上世纪90年代曾在美国引起广泛和热烈的讨论。假定在台上有三扇关闭的门,其中一扇门后面有一辆汽车, 另外两扇门后面各有一只山羊。 主持人是知道哪扇门后面有汽车的。 当竞猜者选定了一扇门但尚未开启它的时候,节目主持人去开启剩下两扇门中的一扇,露出的是山羊。主持人会问参赛者要不要改猜另一扇未开启的门。问题是:改猜另一扇未开启的门是否比不改猜赢得汽车的概率要大?正确的答案是:改猜能增大赢得汽车的概率,从原来的 1/3 增大为 2/3 。这是因为竞猜者选定的一扇门后面有汽车的概率是 1/3 ,在未选定的两扇门后面有汽车的概率是 2/3 ,主持人开启其中一扇门把这门后面有汽车给排除了,所以另一扇未开启的门后面有汽车的概率是 2/3 。
也许有人对此答案提出质疑,认为在剩下未开啟的两扇门后有汽车的概率都是 1/2 ,因此不需要改猜。为消除这一质疑,不妨假定有 10 扇门的情形,其中一扇门后面有一辆汽车,另外 9 扇门后面各有一只山羊。 当竞猜者猜了一扇门但尚未开启时, 主持人去开启剩下 9 扇门中的 8 扇,露出的全是山羊。显然:原先猜的那扇门后面有一辆汽车的概率只是 1/10 ,这时改猜另一扇未开啟的门赢得汽车的概率是 9/10 。
7.条件概率和全概率公式
在上面好几个例子中,都涉及“条件概率问题”。设 A、B 是两个事件,如果已知 A 和 B 各自发生的概率为 P(A) 和 P(B), 又知道 A 和 B 同时都发生的概率为 P(AB) ,则在事件 A 发生的条件下事件 B 发生的概率(称为事件 B 关于事件 A 的条件概率,记为 P(B|A) 显然为 P(B|A)=P(AB)/P(A) 。这里所谓的“条件事件 A ”和“事件 B ”的发生,在时间上没有先后次序。在实际问题中,通常“条件事件 A ”表示结果,即知道事件 A 已经发生了, 而“事件 B ”则表示导致这一结果的可能原因。关于这一点,千万不要把“条件”二字误导为“原因”了。
现在设 A1,...,An 是 n 个事件,假定其中之一会发生,但其中任意两个事件不会同时发生,已知这些事件发生的概率分别为 P(A1),...,P(An) 。另外,假定另有某事件 B ,已知条件概率 P(B|A1),...,P(B|An) 。试问:事件 B 发生的概率 P(B) 是多大?显然, P(B) 可以通过以下的“全概率公式”给出:
8.“ 竞赛规则 “藏玄机
假定有甲、乙两个乒乓球运动员参加比赛,已知甲的实力强于乙。现有两个备选的竞赛规则:“ 3 局 2 胜制”,或“ 5 局 3 胜制”。试问:哪一种竞赛规则对甲有利?
在“ 3 局 2 胜制”规则下,只有“甲甲”、“甲乙甲”和“乙甲甲”这三种可能场景导致甲最终获胜。因此,设在单局中甲胜的概率为 p ,则甲最终获胜的概率为这三种场景的概率之和,等于 f(p)[1+2(1+p)]P2 。同理,在“ 5 局 3 胜制”规则下,进行三局甲获胜只有“甲甲甲”这一场景;进行四局甲获胜有“甲乙甲甲“、”乙甲甲甲“、”甲甲乙甲”三种可能场景;进行五局甲获胜有六种可能场景(具体描述留给读者)。因此甲最终获胜的概率为这十种场景的概率之和,等于 g(p)=[1+3(1−p)+6(1−p)2]p3 。当 p>1/2 时,容易证明 g(p)>f(p) 。因此,“ 5 局 3 胜制” 规则对甲有利。
9.为什么在多人博弈中弱者有时反倒有利?
假定甲、乙、丙三个商家为抢占市场而进行竞争。在竞争中,甲淘汰乙和丙的概率分别是 0.6 和 0.8 ,乙淘汰甲和丙的概率分别是 0.4 和 0.7 ,丙淘汰甲和乙的概率分别为 0.2 和 0.3 。竞争的结局可以是两败俱伤,或者两个依旧幸存,也可能是一个幸存、另一个被淘汰。竞争的规则是:每个商家只能选中一名对手来竞争,未被淘汰的进入下一轮竞争。问:到第二轮结束时, 各个商家幸存下来的概率有多大?
首先,从非合作博弈角度分析,第一轮的最优策略是: 甲和乙竞争,丙与乙结成“暂时联盟”,共同对付三者中最强的甲。第一轮结束时,丙肯定幸存下来;甲和乙都被淘汰的概率是 0.312 ,它等于甲淘汰乙的概率 (0.6) 乘以甲被乙和(或)丙淘汰的概率 (1−0.6×0.8) ;甲和乙都幸存的概率是 0.192 ,它等于甲未被乙和丙淘汰的概率 (0.6×0.8) 乘以乙未被甲淘汰的概率 (0.4) ;甲倖存、乙被淘汰的概率是 0.288 ,它等于甲未被乙和丙淘汰的概率 (0.6×0.8) 乘以乙被甲淘汰的概率 (0.6) ;乙倖存、甲被淘汰的概率是 0.208 ,它等于乙未被甲淘汰的概率 (0.4) 乘以甲被乙和(或)丙淘汰的概率 (1−0.6×0.8) 。如果甲和乙都被淘汰,丙单独幸存,竞争结束。否则进入第二轮竞争,这时分两种情形:(1)如果第一轮结束时甲和乙都倖存,则与第一轮情形相同; (2)如果第一轮结束时甲(或乙)幸存,这时甲(或乙)和丙竞争,甲(或乙)继续幸存的概率是 0.8(或0.7) ,丙继续幸存的概率是 0.2(或0.3) 。利用全概率公式计算,第二轮结束时,甲最终幸存下来的概率是 0.322 ,它等于 0.192×0.192+0.192×0.288+0.288×0.8 ; 类似可以推出乙和丙最终幸存下来的概率分别是 0.222 和 0.624 。由此可见,丙幸存下来的概率最大。
当然,这一模型是理想化的数学模型,但它给我们很好的启示。弱者在竞争的夹缝中幸存下来的例子在商界层出不穷。
10.计算条件概率的贝叶斯公式
设 A、B 是两个事件,如果已知 A 和 B 各自发生的概率为 P(A)和P(B) ,又知道事件关于事件的条件概率 P(B|A) ,如何求事件 A 关于事件 B 的条件概率?由于 A 和 B 同时发生的概率为 P(AB)=P(B|A)P(A), 所以有
这就是18世纪中叶英国学者贝叶斯(Bayes)提出的“由结果推测原因”的概率公式,即著名的“贝叶斯公式”。
下面考虑多个场景情形。设 A1,...,An 是 n 个事件,假定其中之一会发生,但其中任意两个事件不会同时发生,已知这些事件发生的概率分别为 P(A1),...,P(An) 。另外,假定另有某事件 B ,已知条件概率 P(B|A1),...,P(B|An) 。这里每个事件 Aj 通常代表导致事件 B 发生的可能场景。试问:在已知事件 B 发生的条件下,某个事件 Aj 发生的概率是多大? 由贝叶斯公式,我们有
其中 P(B) 由全概率公式给出:
合并这两个公式,我们得到“贝叶斯公式”的最一般形式。
下面举一个简单的例子。假定有甲、乙两个容器,容器甲里有 7 个红球和 3 个白球,容器乙里有 1 个红球和 9 个白球,随机从这两个容器中抽出一个球,发现是红球,问这个红球是来自容器甲的概率是多大?
设“球是从容器甲抽出”为事件 A ,“抽出的球是红球”为事件 B 则有:
11.如何评估疾病诊断的确诊率?
假想有一种通过检验胃液来诊断胃癌的方法,胃癌患者检验结果为阳性的概率为 99.9% , 非胃癌患者检验结果为阳性(“假阳性”)的概率为 0.1% 。问题是:
(1) 检验结果为陽性者確实患胃癌的概率(即确诊率)是多大?
(2) 如果“假阳性”的概率降为 0.01% 、 0.001% 和 0 ,确诊率分別上升多少?
(3) 用重复检验方法能提高确诊率吗?
我们用“+”表示“检验结果为阳性”,用 H 表示被检者为“胃癌患者“,则由贝叶斯公式,确诊率为: P(H|+)=P(+|H)P(H)/P(+) 。从这一公式看出,我们要预先知道被检者所在地区胃癌患病率 P(H) 。假定该地区胃癌患病率为 0.01% 。问题 (1) 的答案是:确诊率为 1/11 ; 问题 (2) 的答案是:如果“假阳性”的概率降为 0.01%、0.001% 和 0 ,确诊率分別上升为 50%、90.9% 和 100% ;问题 (3) 的答案是:有一定的提高,但大幅度提高的可能性很小。原因是 “假阳性” 主要是检验技术本身问题造成的,重复检验的结果相关性很大,不能按独立事件对待。
12.如何设计对敏感性问题的社会调查?
设想要对研究生论文抄袭现象进行社会调查。如果直接就此问题进行问卷调查,就是说要你直说你是否抄袭,即使这样的调查是无记名的,也会使被调查者感到尴尬。设计如下方案可使被调查者愿意做出真实的回答:在一个箱子里放进 1 个红球和 1 个白球。被调查者在摸到球后记住颜色并立刻将球放回, 然后根据球的颜色是红和白分別回答如下问题 : 你的生日是否在7月1日以前?你做论文时是否有过抄袭行为?回答时只要在一张预备好的白纸上打√或打×,分別表示是或否。假定被调查者有 150 人,统计出共有 60 个√。问题是:有抄袭行为的比率大概是多少?已知: P(红)=0.5,P(√|红)=0.5,P(√)=0.4, 求条件概率 P(√|白) ,用贝叶斯公式算出的答案是 30% 。
13.如何理解社会和大自然中出现的奇迹?
对单个彩民和单次抽奖来说,中乐透头奖的概率大概是 2250 万分之一。到 2008 年,在“纽约乐透”史上发生过 3 次有一人中过两次头奖的事件。例如, 2007 年 8 月 30 日美国纽约的安杰洛夫妇喜中“纽约乐透”头奖,获得 500 万美元奖金。他们 1996 年与另外 3 人共分了 1000 万美元头奖。这堪称一个奇迹。“纽约乐透”每周三和六晚间各开奖一次,每年开奖 104 次, 40 年间经历约 4100 次开奖。假定以前中过“纽约乐透”头奖的人还经常买“纽约乐透”彩票, 而且每次下的注数都比较大, 那么在 40 年间他们之中有三人两次中头奖的概率就不是非常小了。
在河北省著名旅游景点野三坡的蚂蚁岭左侧,断崖边缘有一塊直径十米、高四米的“风动石”,此石著地面积不足覆盖面积的 1/20 ,尤其基部接触处只有两个支点。这也算是一个奇迹。
从概率论观点看,上述两个奇迹的发生并不奇怪,因为即使是极小概率事件,如果重复很多次,会有很大概率发生。假设一事件发生概率为 p ,重复 n 次还不发生的概率为 (1−p)n ,当 n 足够大,这一概率就很小,后而该事件发生的概率为 1−(1−p)n 就变得很大了。大自然中的奇迹是地壳在亿万年的中偶然发生的, 但这种奇迹在历史的长河中最终出现是一种必然现象。
14.从概率学家眼光看“华南虎照事件”
2007 年 10 月 12 日,陕西省林业厅宣布陕西发现华南虎,并公布据称为陕西安康市镇坪县城关镇文采村村民周正龙 2007 年 10 月 3 日拍摄到的华南虎照片。但这一轰动性的消息随即引来广大网友质疑,指可能是纸老虎造假。 11 月 16 日,一网友称“华南虎”的原型实为自家墙上年画。同时义乌年画厂证实确曾生产过老虎年画。 2007 年 12 月 3 日,来自六个方面的鉴定报告和专家意见汇总认为虎照为假。当我后网上看到虎照和年画对照图片后立刻做出“华南虎照”是假的判断,理由是虎照和年画相似率达到百分之九十九以上的概率几乎是零。
2007 年 12 月以来我在多次科普报告中都公开了我的这一观点。在网上可以搜索到我 2008 年 4 月在华中科技大学做报告的如下新闻报道:题目为:“四院士齐聚华科,同台共述概率之美”。报道中写道: “严加安院士分別揭示了‘生日悖论’等日常生活中人们常见问题背后隐藏的概率论原理。 他还以一个概率学家的身份判断华南虎照片肯定是假的, 理由是虎照和年画相似率达到百分之九十九以上的概率是零。”
2008 年 6 月 29 日,陕西省人民政府向新闻媒体宣布: 2007 年 10 月 5 日,陕西省镇坪县农民周正龙拍摄的野生华南虎照片为造假。 2008 年 11 月 17 日 8 时 30 分,陕西省安康市中级人民法院宣判周正龙有期徒刑两年半缓期 3 年, 并处罚金 2000 元。
15.从概率学家眼光看“华南虎照事件”
分组对比中占优势总体上一定占优势吗?答案是:不一定!下面是一个例子。假定有两种药( A 和 B ),要通过分组临床试验对比其疗效。以下是试验结果的统计表:从甲乙两组试验结果看,药物 A 的疗效都优于药物 B ,但总体来看药物B的疗效反而优于药物 A 。
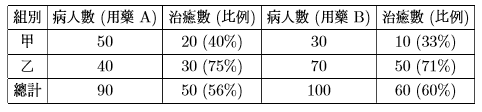
早在 20 世纪初, 当人们为探究两种因数是否具有某种相关性而进行分组研究时就发现了这种现象:在分组比较中都占优势的一方,在总评中反而居劣势。直到 1951 年英国统计学家辛普森在他发表的论文中才正式对这一现象寄语理论解释。后人就把这一现象称为 “辛普森悖论”。
16.“统计平均”的陷阱(例1)
下面这个例子在现实生活中更加典型,它是“辛普森悖论”的一种表现形式。假定有一公司现有员工 100 人,另有一研究所,职工 150 人。在一次普查体检中,发现公司有糖尿病患者 16 人,研究所有糖尿病患者 36 人。从糖尿病患者的患病率来看,研究所的情況比公司严重,其患病率分別是 24% 和 16% 。但实际情况恰恰相反,这怎么可能呢?
现在我们换一种统计方式来考察结果,分成年轻人( 24∼45 岁)和中、老年人( 46∼65 岁) 两个组来计算患病率。该公司有 90 位年轻人,其中患糖尿病 12 人(患病率 13.3% ),有中、老年人 10 人,其中患糖尿病 4 人(患病率 40% );该研究所有 50 位年轻人,患糖尿病 4 人(患病率 8% ),有中、老年人 100 人,其中患糖尿病 32 人(患病率 32% )。
后一种统计方式的结果表明,公司的人,无论是年轻人还是中、老年人,患糖尿病的比例都显著高于研究所的相应人群, 这可能和他们经常加班和中午吃盒饭有关。 这一分组统计结果比总体统计结果更有说服力。
17.“统计平均” 的陷阱(例2)
下面的例子再次表明分组平均往往比总体平均更有说服力。假定某大学数学系有教授 15 人、副教授 40 人、讲师和助教 25 人, 这三累人的平均年收入分別是 15 万、 12 万、 8 万, 该单位职工平均年收入为 10 万。又假定科学院某研究所有研究员 60 人、副研究员 30 人、助研 30 人, 这三类人的平均年收入分別是 14 万、 11 万、 7 万, 但该研究所职工平均年收入为 11.5 万, 高出那个系职工平均年收入 1.5 万。 这一例子表明 : 由于与单位人员构成比例不同, 单位职工平均年收入这一指标不能真实反映单位职工的收入状况。
这一例子给了我们启示: 有些新闻报道中的统计平均数字没有实际意义。例如, 2010 年 2 月中国国家统计局公布称, 2009 年中国 70 个大中城市房价同比上涨 1.5% , 这与大城市居民的实际感受完全背离, 被网友戏称为“房价被拉低”。事实上,“ 70 个大中城市房价的平均涨幅或跌幅”在统计学上没有实际意义。接受这次教训,国家统计局于 2011 年 2 月 16 日正式宣布, 今后将不再发布全国 70 城市房价涨幅平均数, 理由是“平均数在个数差异较大的情況下, 往往会削峰填谷, 抹平个体间的差异。”这是一个明智的决定。
18.统计调查资料的差异
前几年, 曾经在报刊和网路上出现一条耸人听闻的新闻 :“中国国家有关部门公布的一个专项调查结果表明, 我国知识份子平均寿命为 58 岁, 低于全国平均寿命 10 岁左右; 北京中关村知识份子平均死亡年龄为 53.34 岁, 比 10 年前缩短了 5.18 岁。”
这一消息可信吗? 大部分人肯定不相信。问题出在哪里? 可以猜测, 这一资料是根据知识份子中在职期间死亡的资料统计出来的。中关村知识份子在职期间平均死亡年龄为 53.34 岁并不奇怪, 因为男女平均退休的年龄是 57.5 岁。 这条新闻错误在于把知识份子在职期间死亡的平均年龄夸大为知识份子平均寿命。其实绝大多数知识份子是在他们退休以后的若干年内才死亡的, 我国知识份子平均寿命至少应该超过 70 岁。
19.“抽样调查”的陷阱
在做抽样调查时,如果资料的采集缺乏代表性, 可能导致错误的结论,下面是一个著名的例子。在1936 年美国大选中,罗斯福总统以 62.5 的得票率获胜连任,击败了共和党候选人兰登。在选举前, 1935 年才由美国统计学家盖洛普创立的美国民意研究所, 只用了 5 万多个调查问卷,便成功预测了罗斯福会赢得大选(尽管后来实际得票率比预测高了约 7% )。与此成鲜明对照的是,老牌的著名杂志《文学文摘》依据高达约 240 万份的问卷调查结果,却预测兰登将以 57% 对 43% 的绝对优势大胜罗斯福。选举后不久,《文学文摘》 由于这一重大丑闻就倒闭了。
《文学文摘》 的预测为什么会失败?问题就出在抽样调查样本的代表性有严重偏差。首先,该杂志寄出了大约 1 千万份问卷, 选择的对象主要来自杂志的订户和一些俱乐部的会员,这些人大都相对比较富裕。当时美国刚从经济大萧条中恢复,富人比较倾向支持兰登, 而穷人较多倾向支持罗斯福。另外,问卷的回收率太低,只有 24% ,这进一步降低了样本的代表性,因为收入较低者回答问卷的比例通常要比收入较高者低。
该例子说明, 在做统计调查时,要精心设计好方案。例如,采用分层抽样,并随机选择调查物件,这样才能使抽样调查的样本具有代表性。
20.分组混合血标本筛查检验
某医院对一群人进行体检,其中有一项是艾滋病血清检验。如果对每个人的血液标本单独检验,成本将很高。采用“分组混合血标本筛查检验”可以节省成本和时间。假定采集到 N 个血标本,把每个血标本平分成两份,一份留做备用。另一份平均分成 M 组,将每组的血标本混合在一起进行检验。如果某组血液检测为阳性,再用该组的每个备用血标本进行逐个筛查。
问题是:如何根据数量 N 和患艾滋病的概率 p 来确定分组数 M ,或每组的血标本个数 k ,其中 k=N/M (假定 k 为整数),使得平均检验次数达到最低?令 q=1−p ,一组血标本检验是阴性的概率为 qk ,一组血标本检验是阳性的概率为 1−qk 。如果某组血液检测为阳性, 则该组共计需要进行 k+1 次检验。因此平均检验总次数为 N/k[qk+(k+1)(1−qk)] 。由此通过电脑计算可以确定最佳的 k 。
21.概率分析在不确定投资决策中并非万能
假定有两个投资项目。第一个项目分两阶段进行, 第一阶段以 0.90 概率进入下一阶段,以 0.10 概率出局。 进入第二阶段后,以 0.90 的概率取得成功,获得 400 万元的利润;第二个项目以 0.80 的概率直接盈利 400 万元。尽管从概率论分析来看,第一个项目以 0.81 的概率获得 400 万元的利润,优于第二个项目,但多数人选择第二个项目,原因是两次面临风险比一次面临风险给人造成的心理压力更大。
再举一个例子。假定投资者有两个投资项目可供选择:项目 A 确保盈利 400 万元;项目 B 以 70% 的概率盈利 500 万元,以 30% 的概率盈利 200 万元。尽管项目 B 的平均盈利 410 万元,高于项目 A ,但大多数人为了规避风险,宁愿选择项目 A 而不选择 B 。另外,假定投资者有一项目分两阶段进行,在第一阶段确保盈利 300 万元,第二阶段有两个项目 C 和 D 可供他选择:项目 C 确保再盈利 100 万元;项目 D 以 70% 的概率盈利 200 万元,以 30% 的概率亏损 100 万元。这时,大多数人可能更倾向于选择 D 。尽管从概率分析来看,项目 A 或 B 分别等同于盈利 300 万元前提下的项目 C 或 D ,但在两种不同的投资境况下,投资者做出了不同的决策,原因是对两种境况下的风险认知不同。
22.抽样调查的结论依赖于样本量的大小
现在有一种说法:抽烟者患老年痴呆症的比率较低。为了检验这一说法是否可信,设想某医疗机构在某个城市从 65∼75 岁的人群中随机调查了 1000 人,分别统计抽烟者和非抽烟者老年痴呆症患病人数。调查结果是: 1000 人中有 250 人是抽烟者,其中老年痴呆症患者 10 人; 750 人是非吸烟者,其中有45人患老年痴呆症。这两类人患老年痴呆症的比率分别是 4% 和 6% 。表面上看,差异比较显著,但能否根据这一差异就来断定吸烟有助于预防老年痴呆症呢?我们可以用统计中的“假设检验”来回答这一问题。从统计学知道,如果“吸烟不降低老年痴呆症患病率”这一假设成立,如下定义的统计量近似服从均值为 0 方差为 1 的正态分布:
其中 n1 和 n2 分别是吸烟者和非吸烟者的人数, p1 和 p2 分别为吸烟者和非吸烟者患老年痴呆症比率, p 为这两类人总体患老年痴呆症比率。根据抽样调查结果算得 ξ=1.2 。从标淮正态分佈表查出, ξ≥1.2 的概率超过 15% ,因此这一结果还不足以否定“吸烟不降低老年痴呆症患病率”这一假设。但是,如果抽样调查的人数扩大到 4000 人,假定两类人也相应地扩大 4 倍,而且患病率仍然分别是 4% 和 6% ,这时算得 ξ=2.4 。从标淮常态分布表查出的概率小于 1% 。这时我们可以有 99% 的把握断定吸烟能够降低老年痴呆症患病率了。这一例子告诉我们,抽样调查的结论不仅要看统计资料,还要看抽样调查的样本量的大小。
摘自《数学传播》(38卷2期)
——严加安(任教中科院数学与系统科学研究院应用数学研究所)