File and Directories 《APUE》Chapter-4
文件与目录
4.1 Introduction
上一章节以一般文件的IO操作为核心,讲解open,read,write等函数的使用。本章我们着眼于文件系统额外的特性以及文件的属性。一些函数可以用以修改文件属性:改变所有者,改变权限等等。本章也会涉及到Unix文件系统结构的细节和symbolic links(符号链接),最后讲解操作目录的函数。
4.2 stat,fstat,and lstat Functions
用于获得文件所有信息
链接:http://blog.csdn.net/feather_wch/article/details/50658706
4.3 File Types
Unix、Linux系统中有很多类型的文件。
| File Types | |
|---|---|
| Regular file | 最常见的文件。系统并没有区分数据是文本还是二进制的,一般文件内容的翻译取决于执行该文件的应用程序。 |
| Directory file | 包含其他文件的名称以及这些文件信息的指针,任何拥有读取目录权限的进程都可以读取目录的内容,但是只有内核可以直接write 目录文件。进程必须使用本章的系统调用才可以改变目录 |
| Block Special File | 提供在例如disk drives这些设备上固定尺寸单元里进行 buffered I/O访问的能力(providing buffered IO access in fixed-size units to devices such as disk drives) |
| Character special file | (providing unbuffered IO access in variable-sized units to devices. All devices on a system are either block special file or character special file) |
| FIFO. | A type of file used for communication between processes. It’s sometimes called a named pipe. We describe FIFOs in Section 15.5. |
| Socket. | A type of file used for network communication between processes. A socket can also be used for non-network communication between processes on a single host. We use sockets for interprocess communication in Chapter 16. |
| Symbolic link | A type of file that points to another file. We talk more about symbolic links in Section 4.17. |
我们可以通过图4.1中的宏(macros)来决定文件的类型。这些宏的参数就是stat结构体中的st_mode

POSIX.1允许实现表示IPC(interprocess communication) objects的类型,如消息队列,信号量,共享内存。相对于Figure 4.1中的宏使用stat结构体的st_mode,图片4.2中的宏(macros)的参数是指向stat结构体的指针。

Example
判断文件类型
#include 我们说过一般文件是主要的(predominant)文件,我们这就来看看实际系统中各种文件的比例。

4.4 Set-User-ID and Set-Group-ID
Every process has six or more IDs associated with it. These are shown in Figure 4.5.

| IDs | 解释 |
|---|---|
| real user ID and real group ID | These two fields are taken from our entry in the password file when we log in. Normally, these values don’t change during a login session, although there are ways for a superuser process to change them, which we describe in Section 8.11. |
| effective user ID, effective group ID, and supplementary group IDs | determine our file access permissions, as we describe in the next section. (We defined supplementary group IDs in Section 1.8.) |
| saved set-user-ID and saved set-group-ID | contain copies of the effective user ID and the effective group ID, respectively, when a program is executed. We describe the function of these two saved values when we describe the setuid function in Section 8.11. |
Normally, the effective user ID equals the real user ID, and the effective group ID equals the real group ID. Every file has an owner and a group owner. The owner is specified by thest_uid member of the stat structure; the group owner, by the st_gid member.
When we execute a program file, the effective user ID of the process is usually the real user ID, and the effective group ID is usually the real group ID. However, we can also set a special flag in the file’s mode word (st_mode) that says, ‘‘When this file is executed, set the effective user ID of the process to be the owner of the file (st_uid).’’ Similarly, we can set another bit in the file’s mode word that causes the effective group ID to be the group owner of the file (st_gid). These two bits in the file’s mode word are called the set-user-ID bit and the set-group-ID bit.
例如,文件的所有者是超级用户,且文件的set user ID被设置。当该程序运行的时候,其拥有超级用户特权,即使执行该文件的real user ID是一般用户。
又例如,Unix系统允许用户修改自己的密码,passwd(1),该命令就是set-user-ID的程序。然后就能修改密码文件中的内容,典型的是/etc/passwd or /etc/shadow这些文件。
因为set-user-ID程序能获得额外特权的特殊性,需要额外小心。这种类型的程序我们会在chapter-8讨论。
回到stat function,set-user-IDbit and set-group-IDbit被包含在文件的st_mode中。这两位可以使用常量S_ISUID(suer)和 S_ISGID(group)来测试。
4.5 File Access Permission
st_mode也包含文件访问权限的一些bits,一共有9种访问权限,被分为了3类。如下图:

chmod(1)命令就是改变权限的典型命令。允许我们指定 u for user(owner),g for group, o for other.我们将这些视作 owner, group, and world.
如下总结了一些关于权限的注意点
- 第一,只要我们想要打开任何类型的文件,路径中所有目录或者文件都要有可执行权限(execute permission)。
这就是为什么目录的(execute permission bit)可执行权限允许位 被称为search bit的原因。这里的目录的read permission bit和execute permission bit是有区别的。read权限用于读取目录和获得目录中所有文件名的列表。execute权限用于该目录是我们需要访问的路径中的一部分,我们需要穿过(pass through)该目录。 read权限,用于确定我们是否能以read的方式打开文件write权限,用于确定我们是否能以write的方式打开文件- 我们在
open指定了O_TRUNC标志,我们必须要有该文件的write权限。 - 我们必须拥有目录的
write和execute权限,才能在目录中创建新文件 - 当删除某文件时,我们需要拥有其目录的
write和execute权限,而不需要拥有文件本身的readorwrite权限。 - 当我们通过7个
exec函数执行文件的时候,我们需要拥有该文件execute权限。该文件也需要是一般文件。
内核执行进程打开,创建,删除文件操作时的文件权限测试取决于文件的所有者 (st_uid and st_gid), 和the effective IDs of the process (effective user ID and effective group ID), and the supplementary group IDs of the process, if supported. The two owner IDs are properties of the file, whereas the two effective IDs and the supplementary group IDs are properties of the process.
内核的测试步骤如下
1. If the effective user ID of the process is 0 (the superuser), access is allowed. This gives the superuser free rein throughout the entire file system.
2. If the effective user ID of the process equals the owner ID of the file (i.e., the process owns the file), access is allowed if the appropriate user access permission bit is set. Otherwise, permission is denied. By appropriate access permission bit, we mean that if the process is opening the file for reading, the user-read bitmust be on. If the process is opening the file for writing, the user-write bit must be on. If the process is executing the file, the user-execute bitmust be on.
3. If the effective group ID of the process or one of the supplementary group IDs of the process equals the group ID of the file, access is allowed if the appropriate group access permission bit is set. Otherwise, permission is denied.
4. If the appropriate other access permission bit is set, access is allowed. Otherwise, permission is denied.
These four steps are tried in sequence. Note that if the process owns the (step 2), access is granted or denied based only on the user access permissions; group permissions are never looked at. Similarly, if the process does not own the but belongs to an appropriate group, access is granted or denied based only on group access permissions; the other permissions are not looked at.
4.6 Ownership of New Files and Directory
第三章我们使用openorcreat创建新文件时,并没有提到如何安排新文件userID和groupID的值。在section4.20使用mkdir的时候我们会看到如何创建新目录。新目录的ownership相关规则和新文件的ownership相关规则是一样的。新文件的user ID被设置为process的effective user ID。POSIX1允许选择如下选项来绝对新文件的group ID
- The group ID of a new file can be the effective group ID of the process.
- The group ID of a new file can be the group ID of the directory in which the file is being created.
Several Linux file systems allow the choice between the two options to be selected using a mount(1) command option. The default behavior for Linux 3.2.0 and Solaris 10 is to determine the group ID of a new file depending on whether the set-group-ID bit is set for the directory in which the file is created. If this bit is set, the new file’s group ID is copied from the directory;otherwise, the new file’s group ID is set to the effective group ID of the process.
Using the second option—inheriting the directory’s group ID—assures us that all files and directories created in that directory will have the same group ID as the directory. This group ownership of files and directories will then propagate down the hierarchy from that point. This is used in the Linux directory /var/mail, for example.
Linux 3.2.0, we have to enable the set-group-ID bit, and the
mkdirfunction has to propagate a directory’sset-group-ID bitautomatically for this to work. (This is described in Section 4.21.)
4.7 access and faccessat Function
基于real userID and group ID测试访问权限(如,read,write,execute)。
链接:http://blog.csdn.net/feather_wch/article/details/50654443
4.8 umask Function
umask - set file mode creation mask
链接:http://blog.csdn.net/feather_wch/article/details/50658475
4.9 chmod,fchmod,and fchmodat Functions
用于改变文件的访问权限
链接:http://blog.csdn.net/feather_wch/article/details/50658529
4.10 Sticky Bit
The S_ISVTX bit has an interesting history. On versions of the UNIX System that predated demand paging, this bit was known as the sticky bit. If it was set for an executable program file, then the first time the program was executed, a copy of the program’s text was saved in the swap area when the process terminated. (The text portion of a program is the machine instructions.) The program would then load into memory more quickly the next time it was executed, because the swap area was handled as a contiguous file, as compared to the possibly random location of data blocks in a normal UNIX file system. The sticky bit was often set for common application programs, such as the text editor and the passes of the C compiler. Naturally, there was a limit to the number of sticky files that could be contained in the swap area before running out of swap space, but it was a useful technique. The name sticky came about because the text portion of the file stuck around in the swap area until the system was rebooted. Later versions of the UNIX System referred to this as the saved-text bit; hence the constant S_ISVTX. With today’s newer UNIX systems, most of which have a virtual memory systemand a faster file system, the need for this technique has disappeared.
On contemporary systems, the use of the sticky bit has been extended. The Single UNIX Specification allows the sticky bit to be set for a directory. If the bit is set for a directory, a file in the directory can be removed or renamed only if the user has write permission for the directory and meets one of the following criteria(规范):
• Owns the file
• Owns the directory
• Is the superuser
The directories /tmp and /var/tmp are typical candidates for the sticky bit—they are directories in which any user can typically create files. The permissions for these two directories are often read, write, and execute for everyone (user, group, and other). But users should not be able to delete or rename files owned by others.
The saved-text bit is not part of POSIX.1. It is part of the XSI option defined in the Single UNIX Specification, and is supported by Linux 3.2.0.
4.11 chown,fchown,fchownat,and lchown Functions
用于改变user ID and group ID
链接:http://blog.csdn.net/feather_wch/article/details/50658735
4.12 File Size
The st_size member of the stat structure contains the size of the file in bytes. This field is meaningful only for regular files, directories, and symbolic links.
For aregular file, a file size of 0 is allowed. We’ll get an end-of-file indication on the first read of the file.
For a directory, the file size is usually a multiple of a number, such as 16 or 512. We talk about reading directories in Section 4.22.
For a symbolic link, the file size is the number of bytes in the filename.
For example, in the following case, the file size of 7 is the length of the pathname usr/lib:
lrwxrwxrwx 1 root 7 Sep 25 07:14 lib -> usr/lib
(Note that symbolic links do not contain the normal C null byte at the end of the name, as the length is always specified by st_size.)
Most contemporary(同时代的) UNIX systems provide the fields st_blksize andst_blocks.
1. The first is the preferred block size for I/O for the file,
2. The latter is the actual number of 512-byte blocks that are allocated.
Recall from Section 3.9 that we encountered the minimum amount of time required to read a file when we used st_blksize for the read operations. The standard I/O library, which we describe in Chapter 5, also tries to read or write st_blksize bytes at a time, for efficiency.
Be aware that different versions of the UNIX System use units other than 512-byte blocks for
st_blocks. Use of this value is nonportable.
Holes in a File
In Section 3.6, we mentioned that a regular file can contain‘‘holes.’’(空洞) We showed an example of this in Figure 3.2. Holes are created by seeking past the current end of file and writing some data.
As an example, consider the following:
$ls -l core
-rw-r--r-- 1 sar 8483248 Nov 18 12:18 core
$du -s core
272 coreThe size of the file core is slightly more than 8 MB, yet the du command reports that the amount of disk space used by the file is 272 512-byte blocks (139,264 bytes).
Obviously, this file has many holes.
ducommand:On Linux, the units reported depend on the whether thePOSIXLY_CORRECTenvironment is set. When it is set, theducommand reports1,024-byte block units; when it is not set, the command reports512-byte block units.
As we mentioned in Section 3.6, the read function returns data bytes of 0 for any byte positions that have not been written. If we execute the following command, we can see that the normal I/O operations read up through the size of the file:
$wc -c core
8483248 coreThe wc(1) command with the -c option counts the number of characters (bytes) in the file.
If we make a copy of this file, using a utility such as cat(1), all these holes are :
written out as actual data bytes of 0
$ cat core > core.copy
$ ls -l core*
-rw-r--r-- 1 sar 8483248 Nov 18 12:18 core
-rw-rw-r-- 1 sar 8483248 Nov 18 12:27 core.copy
$ du -s core*
272 core
16592 core.copyHere, the actual number of bytes used by the new file is 8,495,104 (512 × 16,592). The difference between this size and the size reported by ls is caused by the number of blocks used by the file system to hold pointers to the actual data blocks(ls和du的结果是不同的,因为文件系统保存了指向实际数据块的指针,这样就占据了额外的blocks).
4.13 File Trunction
截断文件
链接:http://blog.csdn.net/feather_wch/article/details/50658978
4.14 File System
To appreciate the concept of links to a file, we need a conceptual understanding of the structure of the UNIX file system. Understandingthe difference between ani-node and a directory entry that points to an i-node is also useful.
文件系统有很多种,有的是大小写敏感的,有的是大小写不敏感的。
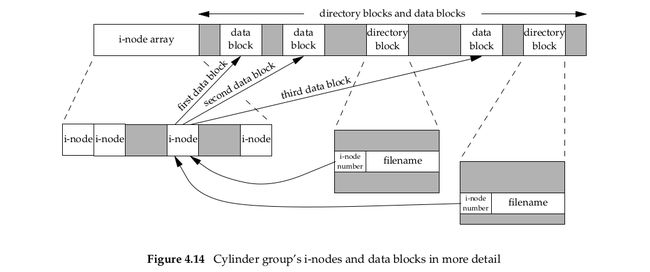
We can think of a disk drive being divided into one or more partitions. Each partition can contain a file system, as shown in Figure 4.13. Thei-nodes are fixed-length entries that contain most of the information about a file.

If we examine the i-node and data block(上图最后的i-nodes,data blocks区域) portion of a cylinder(柱面) group in more detail, we could have the arrangement shown in Figure 4.14(下图).
| Figure 4.14 补充说明 | context |
|---|---|
unlink不意味着delte,hard link |
Two directory entries point to the samei-node entry. Every i-node has a link count that contains the number of directory entries that point to it. Only when the link count goes to 0 can the file be deleted (thereby releasing the data blocks associated with the file). This is why the operation of ‘‘unlinking a file’’ does not always mean ‘‘deleting the blocks associated with the file.’’ This is why the function that removes a directory entry is called unlink, not delete. In the stat structure, the link count is contained in the st_nlink member. hese types of links are called hard links. Recall from Section 2.5.2 that the POSIX.1 constant LINK_MAX specifies the maximum value for a file’s link count. |
symbolic link |
The other type of link is called a symbolic link. With a symbolic link, the actual contents of the file—the data blocks—store the name of the file that the symbolic link points to. In the following example, the filename in the directory entry is the three-character string lib and the 7 bytes of data in the file are usr/lib: lrwxrwxrwx 1 root 7 Sep 25 07:14 lib -> usr/lib。The file type in thei-node would beS_IFLNK so that the system knows that this is a symbolic link. |
i-node保存大部分信息,除了filename和i-node number保存在directory entry里面 |
The i-node contains all the information about the file: the file type, the file’s access permission bits, the size of the file, pointers to the file’s data blocks, and so on. Most of the information in the stat structure is obtained from the i-node. Only two items of interest are stored in the directory entry: the filename and the i-node number. The other items—the length of the filename and the length of the directory record—are not of interest to this discussion. The data type for the i-node number is ino_t. |
| a directory entry不能在不同的文件系统指向一个i-node | Because the i-node number in the directory entry points to an i-node in the same file system, a directory entry can’t refer to an i-node in a different file system. This is why the ln(1) command(命令详解链接:http://www.cnblogs.com/joeblackzqq/archive/2011/03/20/1989625.html) (make a new directory entry that points to an existing file) can’t cross file systems. We describe the link function in the next section. |
| 文件重命名 | When renaming a file without changing file systems, the actual contents of the file need not be moved—all that needs to be done is to add a new directory entry that points to the existing i-node and then unlink the old directory entry. The link count will remain the same. For example, to rename the file/usr/lib/footo/usr/foo, the contents of the file foo need not be moved if the directories /usr/lib and /usr are on the same file system(同一文件系统,文件内容不需要移动). This is how the mv(1) commandusually operates. |
We’ve talked about the concept of a link count for a regular file, but what about the link count field for a directory? Assume that we make a new directory in the working directory, as in
$mkdir testdir结果如下图:
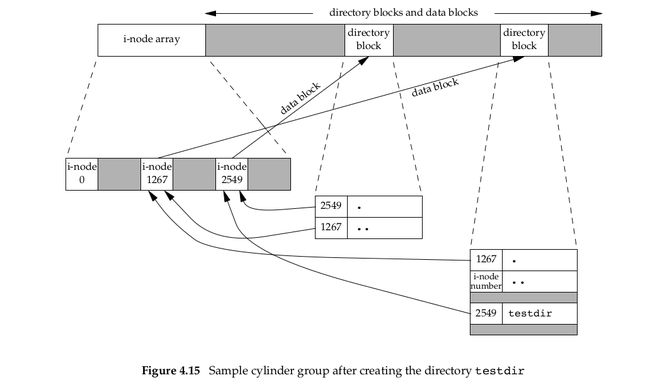
i-node 2549是创建的新目录testdir,link count = 2,被称之为leaf directory(页目录,不包含任何其他目录)。i-node 1267就是当前目录,因为创建了新目录,所以1267的link count增加了1,为3.
4.15 link, linkat, unlink, unlinkat, and remove Functions
用于创建链接,解除链接或者remove文件或者目录
链接:http://blog.csdn.net/feather_wch/article/details/50662781
4.16 rename and renameat Functions
改变文件的名字或者位置
链接:http://blog.csdn.net/feather_wch/article/details/50662933
4.17 Symbolic Links
链接符号是间接指向文件的,不像硬链接(hard links)直接指向文件的i-node节点。symbolic link用于回避(get around)hard links的限制:
1. hard link 需要link和文件 reside(属于,居住) in the same file system
2. 只有超级用户可以创建目录的hard link(when supported by the underlying file system)
There are no file system limitations on a symbolic link and what it points to, and anyone can create a symbolic link to a directory. Symbolic links are typically used to ‘‘move’’ a file or an entire directory hierarchy to another location on a system.
When using functions that refer to a file by name, we always need to know whether the function follows a symbolic link. If the function follows a symbolic link, a pathname argument to the function refers to the file pointed to by the symbolic link. Otherwise, a pathname argument refers to the link itself, not the file pointed to by the link.(在系统调用使用文件名时需要确定是不是链接符号,有些函数follows连接符号,这样会引用链接符号指向的文件。否则会引用符号本身)
Figure 4.17 summarizes whether the functions described in this chapter follow a symbolic link.

The functions mkdir, mkfifo, mknod, and rmdir do not appear in this figure, as they return an error when the pathname is a symbolic link. Also, the functions that take a file descriptor argument, such as fstat and fchmod, are not listed, as the function that returns the file descriptor (usually open) handles the symbolic link. Historically, implementations have differed in whether chown follows symbolic links. In all modern systems, however, chown does follow symbolic links.
From linux version 2.1.81 onward, chown follows symbolic links.
One exception to the behavior summarized in Figure 4.17 occurs when the open function is called with both O_CREAT and O_EXCL set. In this case, if the pathname refers to a symbolic link, open will fail with errno set to EEXIST. This behavior is intended to close a security hole so that privileged processes can’t be fooled into writing to the wrong files.
Example:loops with symbolic links
$mkdir foo make a new directory
$touch foo/a create a 0-length file
$ln -s ../foo foo/testdir create a symbolic link
$ls -l foo
total 0
-rw-r----- 1 sar 0 Jan 22 00:16 a
lrwxrwxrwx 1 sar 6 Jan 22 00:16 testdir -> ../foo我们创建了如图所示的循环
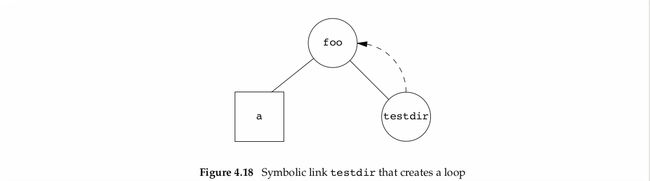
当你在solaris系统去使用标准函数ftw(3),会展开整个目录,导致无限循环。
foo/testdir/testdir/testdir/a.......
当然在Linux操作系统中ftw和nftw会记录所有目录避免一个目录出现超过1次,从而不会出现该情况。
这种情况的循环还是容易消除的,我们可以unlink文件foo/testdir,当unlink不会follow a symbolic link.但是如果我们创建hard link产生了循环,处理起来很困难,所以link只有在superuser特权(privilege)下才能创建目录的硬链接(hard link)。
With
symbolic linksand themkdirfunction, there is no longer any need for users to createhard linksto directories.
Example2: the file pointed by symbolic lin doesn’t exist
$ln -s /no/such/file myfile create a symbolic link
$ls myfile
myfile ls says it’s there
$cat myfile so we try to look at it
cat: myfile: No such file or directory
$ls -l myfile try -l option
lrwxrwxrwx 1 sar 13 Jan 22 00:26 myfile -> /no/such/file首先创建了/no/such/file的链接myfile,所以链接是存在的。然而/no/such/file实际的文件是不存在的,所以报错。
ls下显示的文件信息中l表示这是symbolic link文件。如果ls使用选项-F,如ls -F myfile会显示结果myfile@,‘@’表示该文件是链接标识。
4.18 Creating and Reading Symbolic Links
用于创建链接符号和读取链接符号的内容。
链接:http://blog.csdn.net/feather_wch/article/details/50663246
4.19 File Times
The actual resolution(分辨率,time filed时间域的分辨率) stored with each file’s attributes depends on the file system implementation.For file systems that store timestamps in second granularity(间隔尺寸)(对于那些以秒为间隔存储时间戳的文件系统), the nanoseconds fields will be filled with zeros(纳秒域用0填充). For file systems that store timestamps in a resolution higher than seconds, the partial seconds value will be converted into nanoseconds and returned in the nanoseconds fields.
每个文件具有三个时间域,如下图:

In this chapter, we’ve described many operations that affect the i-node without changing the actual contents of the file: changing the file access permissions, changing the user ID, changing the number of links, and so on.(因此只会改变st_ctim,不会改变st_mtim)。
此外你会发现系统没有对于i-node的最后访问时间,因此access和stat不会改变三个时间中的任何一个。系统管理员用于删除文件的访问时间也是没有的,find(1)命令总是被用于该项操作。ls command除了图中的选项,-l和- 选项仅仅显示文件最后的修改时间。
t
下图就显示了会影响three times的函数。回到4.14节,我们知道directory是一个简单的包含directory entry的文件(filename, associated i-node number)。增加、删除、修改这些directory entries会影响那个目录的三种时间。

4.20 futimens, utimensat, and utimes Functions
这一系列函数能修改文件最后访问(last access)和最后修改(last modification)的时间。
链接:http://blog.csdn.net/feather_wch
4.21 mkdir, mkdirat, and rmdir Functions
Directories are created with the mkdir and mkdirat functions, and deleted with the rmdir function.
链接:http://blog.csdn.net/feather_wch/article/details/50673247
4.22 Reading Directories
读取目录的函数
链接:http://blog.csdn.net/feather_wch/article/details/50673555
4.23 chdir, fchdir, and getcwd Functions
如果你想要更改当前工作目录或者获取当前目录,可以使用这三个functions
链接:http://blog.csdn.net/feather_wch
4.24 Device Special Files
The two fields st_dev and st_rdevare often confused. We’ll need to use these fields in Section 18.9 when we write the ttyname function. The rules for their use are simple.
- Every file system is known by its major and minor device numbers, which are encoded in the primitive system data type
dev_t(每个文件系统都拥有主要和次要的设备数字,该数字会被翻译为原始的系统数据类型dev_t). The major number identifies the device driver and sometimes encodes which peripheral board to communicate with(主要的数字用于识别设备驱动,有些时候分辨外设主板和哪个通信); the minor number identifies the specific subdevice(次要数字鉴定特定的子设备). Recall from Figure 4.13 that a disk drive often contains several file systems(图4.13,我们知道磁盘驱动经常包含了一系列文件系统). Each file system on the same disk drive would usually have the same major number, but a different minor number(在同一磁盘驱动上每个文件系统拥有一样的主要编号,但是有不同的次要编号). - We can usually access the major and minor device numbers through two
macros(宏)defined by most implementations(我们经常通过宏来访问主要和次要设备编号): major and minor. Consequently, we don’t care how the two numbers are stored in adev_tobject(相应地,我们并不关心这两个数字如何存放在dev_t中). - On Linux 3.2.0, although dev_t is a
64-bitinteger, only12 bitsare used for themajor numberand 20 bits are used for theminor number. - The
st_devvalue for every filename on a system is the device number of the file system containing thatfilenameand its correspondingi-node. - Only
character special filesandblock special fileshave anst_rdevvalue. This value contains the device number for the actual device.(st_rdev包含实际设备的设备编号)
Example:
#include "feather.h" //自定义的头文件
#include Linux里: major和minor定义在文件
sys/types.h中`
编译好后测试:
$./a.out / /home/feather /dev/tty[01]
$/ 8 23 `显示根目录编号`
$/home/feather 8 24 `显示/home/feather 编号`
$/dev/tty0 0 6(character)redev = 33/144
$/dev/tty1 0 6(character)redev = 33/144$mount `用于显示哪个目录挂载在哪个设备上`设备类型仅为block special files的是那些可以包含random-access file system(随即访问文件系统)的设备—-disk drives、, floppy disk drives, and CD-ROMs。
终端设备(/dev/tty0)的filename和inode在设备(device) 0/6上(devtmpfs pseudo file system, 但是实际的设备编号是 33/144)
4.25 文件访问权限位总结
File access permission bits在一般文件和目录上的意思会有一些区别,总结在下表:

Summary
本章节以stat为核心,讲述了stat structure每一个成员的细节。涉及到了Unix文件和目录的属性,并且知道了文件和目录在文件系统中是如何安排的,and we’ve seen how to navigate(操作) the file system namespace.深入理解所有文件和目录的性质(property)和所有操作它们的基础操作。