spring Boot环境下dubbo+zookeeper的一个基础讲解与示例
一、 学习背景
1. 前言
对于我们不管工作还是生活中,需要或者想去学习一些东西的时候,大致都考虑几点:
a) 我们为什么需要学习这个东西?
b) 这个东西是什么?
c) 这个东西能为我们做什么?
d) 如何去学?
结合以上几点,我们一起学习下Dubbo这个框架!
2. 学习背景
互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,Dubbo是一个分布式服务框架,在这种情况下诞生的。现在核心业务抽取出来,作为独立的服务,使前端应用能更快速和稳定的响应。
3. Dubbo是什么
Dubbo是Alibaba开源的分布式服务框架,它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解耦合(或者最大限度地松耦合)。从服务模型的角度来看,Dubbo采用的是一种非常简单的模型,要么是提供方提供服务,要么是消费方消费服务,所以基于这一点可以抽象出服务提供方(Provider)和服务消费方(Consumer)两个角色。关于注册中心、协议支持、服务监控等内容
4. Dubbo能做什么
当网站变大后,不可避免的需要拆分应用进行服务化(微服务),以提高开发效率,调优性能,节省关键竞争资源等。
当服务越来越多时,服务的URL地址信息就会爆炸式增长,配置管理变得非常困难,F5硬件负载均衡器的单点压力也越来越大。
当进一步发展,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。
接着,服务的调用量越来越大,服务的容量问题就暴露出来,这个服务需要多少机器支撑?什么时候该加机器?等等……
在遇到这些问题时,都可以用Dubbo来解决。
5. 如何去学习Dubbo
百度搜索Dubbo
a) 官网:http://dubbo.io/ 去查看关于dubbo的官方定义,了解这是个什么东西。
b) Dubbo框架设计者的专访:http://www.iteye.com/magazines/103看一下阿里巴巴人士如何评价dubbo的。
c) Dubbo的入门使用:http://blog.csdn.net/congcong68/article/details/41113239
d) Dubbo框架的详解与原理:http://shiyanjun.cn/archives/325.html看不懂就先会用。
二、 开启学习之路
1. Dubbo架构图
总体设计架构:

基础架构:

上图中,蓝色的表示与业务有交互,绿色的表示只对Dubbo内部交互。上述图所描述的调用流程关系如下:
0. 服务容器负责启动,加载,运行服务提供者,这个图上没标识出来,服务端启动就是0.
1. 服务提供者在启动时,向注册中心注册自己提供的服务。
2. 服务消费者在启动时,向注册中心订阅自己所需的服务。
3. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
4. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
5. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
2. Dubbo与zookeeper
Dubbo为什么要与zookeeper/Consule一起使用?
dubbo主要是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。简单的说,dubbo就是个服务框架,如果没有分布式的需求,其实是不需要用的.告别Web Service模式中的WSdl,以服务者与消费者的方式在dubbo上注册.
zookeeper用来注册服务和进行负载均衡,哪一个服务由哪一个机器来提供必需让调用者知道,简单来说就是ip地址和服务名称的对应关系。zookeeper通过心跳机制可以检测挂掉的机器并将挂掉机器的ip和服务对应关系从列表中删除。
看图识物:

上图所示,假如我有四台服务器,每台服务器都提供相同的服务,如果我消费者去掉用的时候,肯定要在四个当中选择某一个去调用,可是选择哪一个就是一个难题,当然这就涉及到负载均衡问题了,或者我们在消费者这边加代码逻辑判断达到负载均衡的效果。还有每次调用的时候都不知道要去掉哪个服务,都要查询当前有哪些服务提供者,这是很耗开销的,当服务提供越来越多的时候,越来越乱。
最终方案:

利用zookeeper生成的节点树,服务器提供者在启动的时候,将提供的服务名称和地址以节点的方式注册都服务器zookeeper服务器配置中心,消费者通过服务器配置中心获取需要的服务名称节点下的服务地址。因为znode有非持久节点的特性,服务器可以动态的从服务配置中心一处,并且触发消费者的watcher方法!!!
消费者只有在第一次调用的时候直接本地缓存服务器列表信息,而不需要重新发起请求到服务器配置中心区获取相应 的服务器列表,直到服务器地址列表有变化(机器下线或者上线),变更之后消费者watcher进行服务地址的重新查询。正是因为这种无中心化的结构,使得服务消费者在服务信息没变更时候,几乎不依赖配置中心,解决了负载均衡设备导致的单点故障的问题,大大减少了服务配置中心的压力
3. Zookeeper的安装
此处以windows环境下为例
注:linux安装参考http://blog.csdn.net/lk10207160511/article/details/50526404
在apache的官方网站提供了好多镜像下载地址,然后找到对应的版本,目前最新的是3.3.6
下载地址:
http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.3.6/zookeeper-3.3.6.tar.gz
把下载的zookeeper的文件解压到指定目录

修改conf下增加一个zoo.cfg
内容如下:
# The number of milliseconds of eachtick 心跳间隔毫秒每次
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and gettinganacknowledgement
syncLimit=5
# the directory where the snapshotisstored. //镜像数据位置
dataDir=D:\\data\\zookeeper
#日志位置
dataLogDir=D:\\logs\\zookeeper
# the port at which the clientswillconnect 客户端连接的端口
clientPort=2181
注:如果启动有报错提示cfg文件有错误,可以用zoo_sample.cfg内内容替代也是可以的
进入到bin目录,并且启动zkServer.cmd,这个脚本中会启动一个Java进程
这个时候zookeeper已经安装成功了.
4. 配置dubbo-admin的管理页面
下载dubbo-admin-2.4.1.war包,解压到tomcat中。
如图所示:

修改dubbo.properties文件,里面指向Zookeeper ,使用的是Zookeeper 的注册中心。

然后启动tomcat服务,用户名和密码:root,并访问服务,显示登陆页面,说明dubbo-admin部署成功,如图所示:

目前我们还没有注册服务,所以内容都是空的。
5. 程序演示
现在我们来看个简单的dubbo-demo项目,此项目只分解了两个工程,一个服务提供者,一个消费者。此项目只适用于演示使用。因为,你在非分布式的项目上使用dubbo,多此一举。
如图:
![]()
6. 服务提供者
演示工程结构如下:
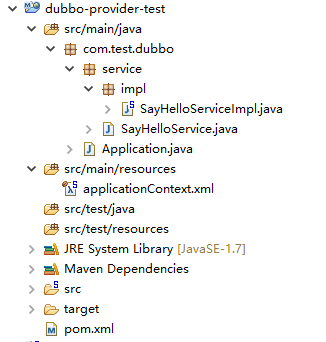
首先看下咱们的pom文件,引入Dubbo和Zookeeper的jar包.没啥好说的。

然后我们写自己的接口与实现,通常分布式设计下接口应该与实现分开,让接口与bean单独起工程模块,以便服务提供者与消费者都可以调用。如果服务端有自己不暴漏的方法,可单写接口类,也可中间加层,看业务而定。

重点看下我们dobbo配置
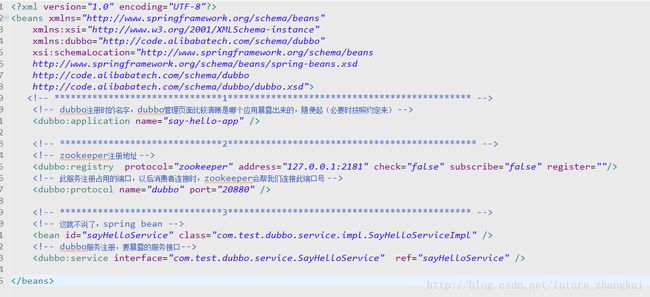
属性说明:
dubbo:registry 标签一些属性的说明:
a) register是否向此注册中心注册服务,如果设为false,将只订阅,不注册。
b) check注册中心不存在时,是否报错。
c) subscribe是否向此注册中心订阅服务,如果设为false,将只注册,不订阅。
d) timeout注册中心请求超时时间(毫秒)。
e) address可以Zookeeper集群配置,地址可以多个以逗号隔开等。
dubbo:service标签的一些属性说明:
a) interface服务接口的路径
b) ref引用对应的实现类的Bean的ID
c) registry向指定注册中心注册,在多个注册中心时使用,值为
d) register 默认true ,该协议的服务是否注册到注册中心。
接下来我们启动服务提供者服务,这里我们常用的应该是启动一个java程序,因为我们的工程中并没有涉及web方面的业务,尽量不适用tomcat 启动Web容器。

此时我们看下dubbo控制台,我们的服务已经注册进zookeeper中,服务完成。
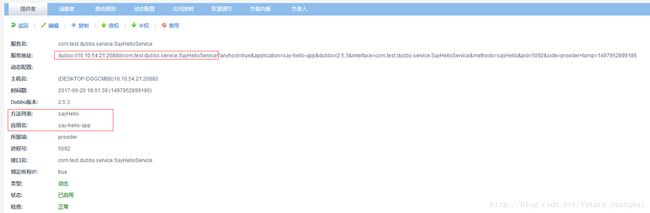
7. 服务消费者
我们写一个消费者工程项目,结构如下:

Pom文件与服务者要引用的基本一样,都是dubbo与zookeeper。
我们同样写一个接口类,与服务端的接口一致,此处如果服务端的接口分层出来,我们可以直接引用的,则不用写此步了。

我们写一个控制器代码,调取接口。

配置我们dubbo配置文件,让zookeeper给我们订阅需要的服务,此处配置接口的订阅也可使用注解形式,但对此,如果初期我们的项目用户量不是特别大,我们不想使用分布式的时候,就不好拆除dubbo了。

配置说明:
dubbo:reference 的一些属性的说明:
a) interface调用的服务接口
b) check 启动时检查提供者是否存在,true报错,false忽略
c) registry 从指定注册中心注册获取服务列表,在多个注册中心时使用,值为
d) loadbalance 负载均衡策略,可选值:random,roundrobin,leastactive,分别表示:随机,轮循,最少活跃调用。此处可在zookeeper单独配置,如下:

再次查看我们的dubbo控制台,发现消费者已经被注册到zookeeper中。
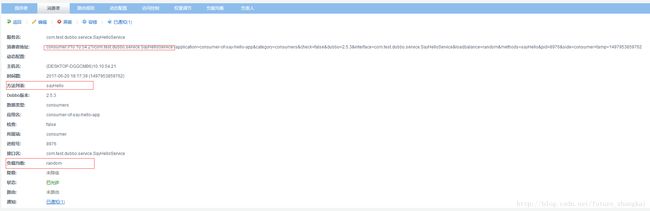
消费者服务完成,我们来写个测试。

8. Dubbo泛化调用(扩展篇)
Q:一个PHP工程师想调用某个Java接口,他并不能按照你约定,去写一个个的接口,此时该怎么办?
A:Dubbo并不是跨语言的RPC框架,但并不是不能解决这个问题,使用dubbo的泛化调用,然后利用web返回json,这样完成跨语言的调用。
总结:泛化调用,最最直接的表现就是服务消费者不需要有任何接口的实现,就能完成服务的调用。
泛化的使用比较简单,服务提供者咱们还用上面工程,不需改变。泛化调用,肯定是调用方
去实现泛化。
看下我们的配置文件,如下:

有两个地方需要注意一下,第一个是interface,其实该接口在消费者端并不存在,这是与往常写的不一样的地方,第二个地方需要注意的地方就是generic=”true”这样的标签,表示该接口支持泛型调用.
来看下我们怎么用程序调用,如下一个测试:

从spring的上下文中读到引用的接口bean,之后却把它强转为GenericService类,通用写法。然后调用GenericService的$invoke的方法。
该方法有三个参数,第一个参数是你调用远程接口的具体方法名,第二个参数是这个方法的入参的类型,最后一个参数是值。如下:

一个PHP程序员想要搭建一个简单的web项目,可是你却叫他依赖于spring的配置文件,他肯定不乐意,dubbo也帮你想到了,泛型调用,服务消费端可以不依赖spring的配置文件。如下:

小结:泛化调用可以方便用户对dubbo服务消费者端的扩展,可以方便,丰富了服务消费者的调用方式,甚至可以做变相的Rest调用,这些都是可以的,不过,它的缺点也是很明显的,参数传递复杂,不方便使用。但是这种方式是不能缺失的。