英伟达架构师详解:训练一辆Waymo无人车,到底需要多少数据?
目前的深度神经网络如果应用到无人车领域,需要令人惊叹的计算能力。今天NVIDIA DGX-1这样的单台计算机的运算能力,与2010年世界上最大的超级计算机的计算性能相当。(https://www.nvidia.com/en-us/data-center/dgx-systems/)
即使是这样的技术进步,也难以满足现代神经网络和大规模数据训练对计算能力的需求(图1)。

图 1. 神经网络对计算能力的爆炸式增长
对于与安全相关的系统(如自动驾驶汽车)来说,计算能力尤其重要,其检测精度远比对互联网行业要高。无论天气条件、能见度或路面质量如何,这些系统都要毫无瑕疵地运行。
为了达到这种性能水平,神经网络需要对代表性的数据集进行训练,包括所有可能的驾驶行为、天气和环境条件。在实践中,这些都将转化为海量的训练数据。
同时,神经网络需要有足够多的参数来学习这些数据集,才不会遗忘过去的训练。在这种情况下,每次将数据集大小增加n时,对计算能力的需求增加了n2,这带来了复杂的工程挑战。取决于网络架构的复杂度,单个GPU的训练可能需要几年—也可能是几十年的时间,同时挑战着超越硬件、网络、存储和算法。
在本文中,英伟达架构师Adam Grzywaczewski将详解与自动驾驶汽车相关的计算复杂性,以帮助新的AI团队(及其IT同事)规划支持研究或工程过程所需的资源。
▍需要多少数据?
每个制造商对数据采集、采样、压缩和存储的问题都有着不同的方法。这些方法的确切细节或数据量并不对外公开。部分制造商公开了他们的车队规模和汽车配置,依靠这些信息,我提出关于收集过程的四个保守假设,用来粗略估算自动驾驶所需的数据量。
车辆规模
像 Waymo(前Google自动驾驶汽车项目)这样的公司报告说,他们每天有数以百辆的车辆在收集数据。Waymo在2016年12月将其车队扩建至100辆车,并于2017年5月报告称已收集了三百万英里的数据。
其他制造商正在建造类似规模的自动驾驶汽车队,2017年6月,通用汽车公司宣布已经生产了130辆自动驾驶汽车,并预计该车队将迅速增长至180辆。福特在2016年8月宣布部署100辆自动驾驶汽车。据此,我保守估计一个标准车队有100辆车。
假设1:车队规模 = 100 辆
需要指出的是,很少有人认为自动驾驶汽车可以单用物理车队收集的数据来解决。许多公司,如Waymo,正大力投入研发模拟器,并建设虚拟数据采集队伍,其数量远大于上述数字。在撰写本文时,Waymo已通过仿真模拟器收集了超过十亿英里的数据,说明他们的虚拟车队由数以千计的模拟车辆组成。
数据收集时长
由于技术尚不成熟,因此没有可行的办法来准确估计需要多少数据,以下计算基于公开的信息。撰写本文时,Waymo报告:
3百万英里的真实环境测试
10亿英里的模拟试驾
每1000英里的脱离率为0.2(平均而言,人类需要每5000英里干预一次行使)
对于一种产品来说,这样的脱离率显然是是难以让人接受的,这表明试驾的300万英里还远远不够。但在此,我将使用这些数据,保守估算自动驾驶汽车初始研发所需数据集。
Waymo还报告,其新的扩展车队将允许它在7个月内收集100万英里的数据,相当于21个月300万英里。再一次,秉持更加保守谨慎的态度,我会将收集数据时长的预期大幅度减少到12个月,下降到每个车每天行驶8小时,每年行驶260天,由此得到假设2.
假设 2: 数据收集时长 = 1 年 = 2080 小时/车
这意味着,拥有100辆每辆装有5台照相机的车队将在一年内产生超过一百万小时的视频录像。这些数据需要被捕获,从汽车传输到数据中心、存储、处理,然后用于训练。更为重要的是,由于使用了监督学习算法,所有数据都需要由人工标注。如果数据标注团队规模太小,那标注每个行人、汽车、车道和其他细节可能会成为一大瓶颈。
一辆无人车产生的数据量
典型的自动驾驶汽车中配备有多个传感器,包括诸如雷达、相机、激光雷达、超声波传感器等,传感器采集的数据分布在车辆控制器网络、Flexray、汽车以太网和许多其他网络。
典型的测试车配备有多个摄像机、雷达和其他传感器,为计算机系统提供了更多的可见性和冗余性,可以保护汽车免受恶劣天气条件或单个组件故障的困扰(图2)。

图 2. 典型的自动驾驶汽车配备包括像机、雷达和激光雷达等多种传感器,使车辆具有360度的可视性。
特定制造商或供应商没有公开具体设备详情,但是一些供应商提供了有关问题的数量级的信息。
Dell EMC和Altran发表的一篇文章显示,仅仅一个面向前方的2800 MBits/s的雷达,每小时会产生超过1.26 TB的数据,典型的数据采集车每天产生数据超过30TB。类似地,以每秒30帧的速度工作的两百万像素的摄像机(每像素24位)每秒产生1440兆比特数据,因此装备五个摄像机可以每天产生超过24 TB的数据。
鉴于有关不同自动驾驶汽车的确切车辆仪表的公开信息很少,我必须对数据量进行非常保守的估计。为了确保最终的计算能力需求不被夸大,简单起见,我将仅考虑由相机产生的数据。此外,我会假设车辆只配备了五台摄像机,尽管在很多情况下还会配备更多。摄像机配置通常采用以每秒30帧的速度运行的两百万像素摄像头。
这种简化的设置每小时仍将产生超过3TB的原始视频数据,我进一步将数据量减少到每小时1TB(以适应硬件或采样率的变化)。
假设 3: 单车产生数据量 = 1 TB+/h
数据预处理
最后的假设涉及数据预处理,这通常是在原始视频流上执行的。可以采取两个步骤来安全地减少数据量,而不会严重影响神经网络的性能:
1. 数据采样:由于视频帧高度相关,在初始的研发阶段,可以考虑重新采样输入数据集,以帮助控制问题的计算复杂度。虽然在实践中可能没有做到这一点,但是将数据从30帧每秒重新采样到1帧每秒可以将用于计算的数据集大小减少约30倍。
2. 压缩:压缩很少能做到无损,所以在实践中可能不会应用压缩。为了减少用于计算的数据量,我假设夸张的进行70x压缩,由于图像质量会显着降低,这不能用于实际压缩。再次重申,我选则估计的数据量是最保守的。
如果我现在将这两个方法相乘在一起,我得到的数据量约为原先的0.0005。
假设 4: 预处理减少后的数据量 = ~原始数据的0.0005倍
预处理后的总数据量
所有这些假设都是保守估计的,如果我现在把这四个假设结合起来,那么一辆汽车每小时就会产生1TB +的数据,每100辆车运行8小时/天* 260个工作日/年的车辆会产生204.8PB的数据。
总原始数据量= 204 PB
如上文所说,如果这些数据在现实训练中可用,这些数据将经过大量处理和采样的过程。这将使数据量达到适中的104 TB。
预处理后的总数据量 = 104 TB
▍训练耗时多久?
我计算出预处理后的总数据量是100TB,这对训练过程意味着什么?由于汽车检测网络的神经网络架构不公开,我将使用一些最先进的图像分类网络进行进一步的计算。这些分类网络在非常类似于用于诸如行人检测、对象分类、路径规划等任务的解决方案。
运行AlexNet—一个计算量最小的图像分类模型,加上一个较小的ImageNet数据集,在单个Pascal GPU上大约需要150MB/s的吞吐量。对于更复杂的网络,如ResNet 50,这个数字接近〜28 MB/s。对于像Inception V3这样的最先进的网络,大约是19MB/s。
如果我现在假设汽车网络将会与ImageNet数据使用的网络的迭代次数相同(让我们使用50个迭代来简化计算),这意味着单个GPU将需要:
50 迭代 * 104 TB 数据/19 MB/s = 9.1 年去训练Inception-v3类似的网络
6.2 年 训练ResNet-50类似的网络
1.2 年 训练AlexNet类似的网络
像NVIDIA DGX-1这样的最先进的深度学习系统被设计成几乎线性地扩展,提供高达八倍的计算能力。但是,单个系统并不能解决问题。即使有8个Tesla P100(Pascal)GPU,训练时间也需要:
1.13 年训练Imagenet V3类似的网络;
0.77 年训练ResNer 50类似的网络;
0.14年 训练AlexNet类似的网络.
新的Volta GPU架构(https://devblogs.nvidia.com/parallelforall/inside-volta/)进一步解决了一些挑战(在撰写本文时,ResNet 50的训练速度是Tesla V1002.5倍),但并没有改变问题的数量级。特别是在实践中,可能需要复杂得多的网络来适应数据中的信息
▍训练需要多少台计算机?
上一节说明了单个系统如何解决自主驾驶所需的大量数据和计算能力。随着更密集的计算系统(如DGX-1与Volta GPU)的出现,现在可以构建一个集群解决方案,提供超凡的计算资源。
上面提出的数值估计表明了集群计算的必要性。如果需要等待两年看实验结果,即使是最大、最有才华的团队也没有人能够坚持下来,甚至100天也太长了。为了使团队有效地工作,这个迭代时间需要下降到几天,如果是几个小时就更好了。
为了方便进一步计算,我将以七天为目标。而且,如果团队同时工作的人数不止一个,那么每个人(或至少有一小部分,我假定20%)都应该在合理的时间内获得实验结果。
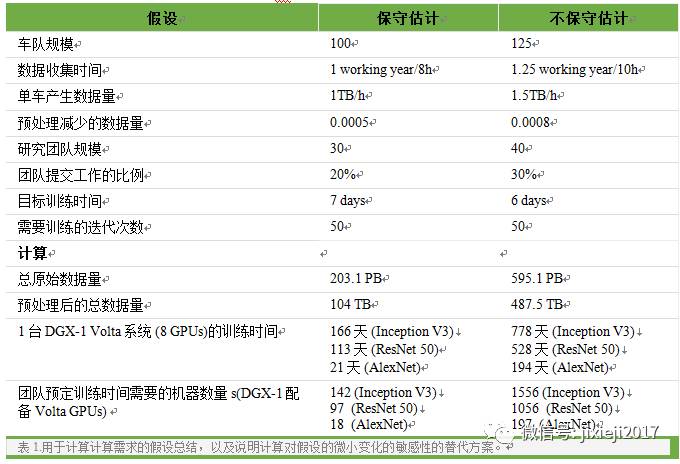
要了解需要多少计算能力,我们需要进一步计算。假设一个30人的中型团队,其中只有6人将随时提交工作,每次工作时间为7天:
356 个DGX-1 Pascal 系统训练Inception V3 系统(平均每个团队成员10个)
241个 系统训练 ResNet 50 (平均每个团队成员8个)
45 个系统训练 AlexNet (平均每个团队成员2个)
最新的Volta基准测显示用Tesla V100(Volta)GPU的DGX-1 的速度提高了2.5倍:
142 个DGX-1 Volta 系统训练 Inception V3 (平均每个团队成员4-5个)
97 个系统训练ResNet 50 or similar (平均每个团队成员3个)
18 个系统训练AlexNet or similar (平均每个团队成员1个)
表 1总结了我的假设和估算,并对比了不保守的估计:
▍线性缩放的挑战
上面提出的所有计算预估,都假定集群可以实现完美的线性缩放(本文中,我指的是Dean等人所述的数据并行性作为实现这种缩放的机制)。这意味着,随着GPU数量的增加,训练时间将按比例减少。所以如果你的GPU数量翻倍,训练时间就会减少50%。这是一个艰难的壮举。
一个人不能简单希望地将多个显卡放入一个集群,然后看到GPU数量和训练时间成完美的反比。相反,对大多数汽车的图像分割网络来说,如果通过PCI-e总线连接多个GPU,您会注意到,当增加2-3个以上的卡时,性能的提升是有限的(这取决于网络的计算复杂度和参数数量)。
本节将简要介绍线性缩放,并阐述基础设施的关键设计因素,同时指出了有关进一步获取信息的适当文献。有关更详细的信息,请参阅NVIDIA DGX-1系统架构白皮书。
网络
通信开销是子线性缩放(代码质量问题除外)的最根本原因之一。
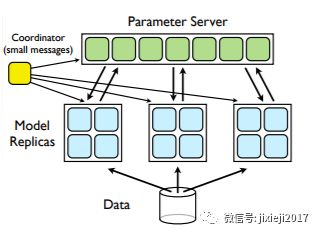
图 3. Dean描述的同步数据并行
为了在多个GPU上使用数据并行来训练神经网络,每个GPU都要获得相同的模型副本和一小部分数据(图3)。一旦神经网络正向传递完成,就开始计算和交换数据。在这个阶段,GPU需要在非常有限的时间内交换大量的数据。
如果交换数据花费的时间比GPU执行反向传递的时间长得多,那么所有的机器都要等待直到该通信完成。
事实证明,绝大多数情况下,为避免通信瓶颈,GPU所需的数据速率都超出了PCI-e网络的能力。为了解决这个问题,NVIDIA开发了一种名为NVLink的专用GPU互连,其第二个版本能为每台Tesla V100 GPU提供超过300GB/s的双向带宽。
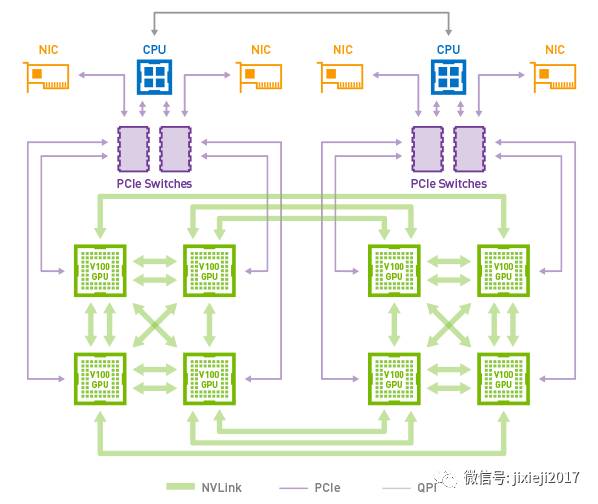
图 4. DGX-1与Volta GPU的NVLink拓扑结构。
NVLINK解决了单GPU多系统中的通信挑战,允许应用程序在DGX-1(图4)上扩展到8个GPU,远远优于仅具有PCI-e互连的类似系统。为了扩展到多台机器,必须要考虑多节点通信和Infiniband在网络拓扑中的作用。为了达到最高的多服务器训练性能,请考虑一个完整的胖树网络设计,如图5所示,以最大限度地提高总可用带宽。
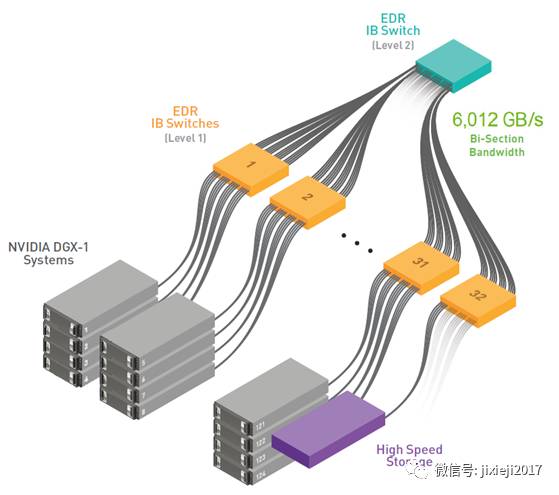
图 5. 推荐的深度学习工作负载网络拓扑
NVLink和Infiniband是通信媒体,但本身并不提供开放式分布式深度学习机制。为了解决这个问题,NVIDIA集合通信库(NCCL)(https://developer.nvidia.com/nccl)隐藏了集群内GPU通信的复杂性,并与所有流行的深度学习框架进行了整合(在不同程度上)。
算法和软件
NCCL不是必须纳入神经网络实施的唯一逻辑。即使几乎所有的深度学习框架都允许并行化工作负载,也要通过不同的工程设计来实现。此外,不同的深度学习框架提供不同的实施质量,为了跟上变化和解决错误,以不同的速度发展,使其更容易或更复杂。没有任何深度学习的框架可以随便的得到支持。
建立和维护一套软件工具需要工程资源来,令让人惊讶的是,这些资源在项目开始时经常被忽略。除非将此过程销售给第三方,否则就需要雇佣一定数量的软件工程师,人数多少取决于研究人员需要的构建和维护工具集。
为了加速人工智能研究,并允许组织专注于自动驾驶汽车的算法开发(与深度学习框架维护和优化相反),NVIDIA以月为周期发布为所有关键的深度学习框架提供优化好的的容器(http://docs.nvidia.com/deeplearning/dgx/)。这些容器不仅消除了管理不断变化的深度学习环境的复杂性的需要,而且还提供卓越的性能。NVIDIA的优化和测试可以节省您的团队相当多的工程量(图6)。
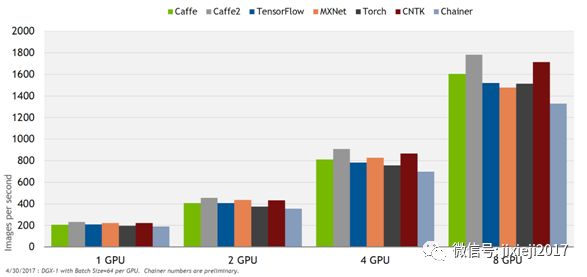
图 6在DGX-1和Pascal GPU,ResNet 50 FP32 表现出的NVIDIA优化后的深度学习框架的性能
存储STORAGE
解决方案的另一个经常被忽视的元素是存储。理论上面临的挑战很简单:必须为GPU提供足够的数据,让其保持工作状态。数据加载管道中的任何延迟将不可避免地导致GPU空闲,让整个流程严重延迟。数据传输对带宽要求很高,特别是在处理高分辨率图像时,单个节点常以超过3GB/s处理数据。
对于较小的数据集,问题变得简单。由于神经网络在每次迭代训练时访问相同的数据,因此数据可以本地缓存在高性能SSD(更小的数据集甚至可以保存在RAM)上,并从本地SSD的高速传输到GPU(请注意,第一次迭代将导致首次访问网络文件服务器的费用)。这样的解决方案已经广泛应用于像DGX-1这样的深度学习系统。
在汽车方面,问题则更复杂。正如我估计,最保守的情况是处理100TB的数据。如果数据传输一次后,系统能在多次迭代中重复使用,那么DGX-1中使用的本地高速缓存是可行的。
然而,汽车产生的数据集远远超出了训练机本地存储的能力,因此本地缓存的使用作用有限。在这种情况下,显然需要更高性能的存储后端。NVIDIA正在研究HPC文件系统经常使用的闪存存储或闪存加速存储的部署。
CPU和内存
CPU在组织训练过程以及数据加载、日志记录、快照和扩充过程中起着至关重要的作用。如果CPU无法满足GPU对数据的需求,GPU将闲置下来。值得注意的是,即使面对ImageNet这样更简单的网络,八个Pascal GPU可以轻松地让整个服务器级CPU饱和。
这对于像Samsung Research这样的组织来说也是一个重大的问题,尽管降低了神经网络本身可用的GPU资源,Samsung Research已经开始尝试将数据扩充管线迁移到GPU。在对不同CPU配置进行基准测试时,我们观察到了对端到端训练性能的影响。RAM需要保持相同的均衡(连接的GPU内存的2x至3x)。
▍计算工作流程的其他阶段
AI工程的工作流程远远大于深度学习模式的大规模训练。团队需要提供工具,以便他们有效地对候选模型进行原型构造、测试、优化和部署(图8)。所有这些步骤都需要大量的计算资源。如果没有正确的工具支持,建立一个大型研究团队就没有任何意义。
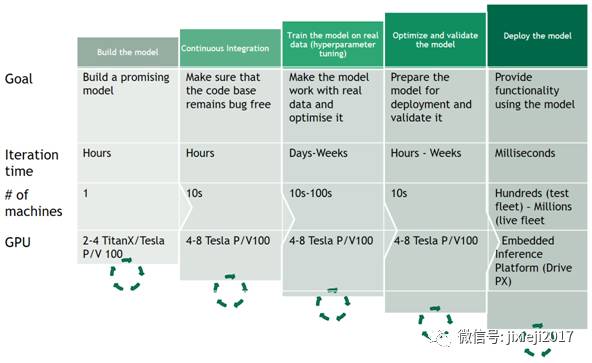
图 8. 自动驾驶AI模型发展和测试的不同阶段
但挑战远比这更多。数据工程和运营、数据传输和存储、数据标注(设想300万英里驾驶数据的任务)、原型设计、测试和优化基础设施需要与团队成比例地成长。
▍规模规划Plan for Scale
用于实现自动驾驶汽车的深度神经网络的计算要求是巨大的。在这篇文章的每一个阶段,我已经大幅削减了数据量(有时甚至一个数量级或更多),而且由此产生的计算清楚地表明,自主驾驶的汽车研究无法在小型GPU上实现。
即使用特斯拉V100 GPU的DGX-1这样功能强大的设备,在处理100TB数据集时,单次训练迭代也需要几个月的时间。没有办法避免大规模的分布式训练。构建这种基础设施以及支持它的软件是有的,但还不能达到目的。
人类历史上第一次有足够的计算能力来实现自动驾驶汽车训练的计算复杂性。当然,计算资源不是你需要的一切。你需要建立一个研究和数据工程团队,需要一个系统团队来管理业务。
你还需要创建和部署车队,以收集数据并验证结果,然后将工作结果与车辆相结合。你还要面临很多后勤和财务挑战,但找出解决自动驾驶这个问题的方法还要看工程/研究工作(预算和时间只要保障研究)。
来源:英伟达
编译:北辰
★推荐阅读★
全球首支AI基金:365天无间断工作
马斯克OpenAI实验室的17岁高中生
细数李彦宏的40位“出走门徒”
苹果AI人才报告:斯坦福等名校被挖空
Airbnb使用AI技术 让设计图秒变代码
被新浪科技的编辑套路后
清华大学计算机专业排名全球第一
深度学习库大排名:TensorFlow第一
用大数据和机器学习揭示十二星座(下)
谷歌中国首席工程师详解TensorFlow
长期招聘志愿者
加入「AI从业者社群」请备注个人信息
添加小鸡微信 liulailiuwang
