「揭秘GP」Greenplum 数据库进军深度学习领域
深度学习(Deep Learning)开始成为企业计算的一个更重要的部分,这是因为人工神经网络在自然语言处理,图像识别,欺诈检测和推荐系统等领域非常有效。在过去的五到十年中,计算机的计算能力有了极大的增强,以及海量数据的出现,这一切促使人们对使用深度学习算法解决问题产生了兴趣。
另一方面,企业的业务系统大多基于SQL的基础架构,在软件和员工培训方面进行了大量投资。然而,深度学习的主要创新发生在SQL世界之外,因此企业使用深度学习算法是需要采用独立的深度学习基础设施。因此,在传统的SQL架构之外搭建深度学习系统,不仅需要考虑到额外的费用和工作量,也需要考虑开发新数据孤岛的风险。此外,在系统之间移动大型数据集效率不高。如果企业可以在MPP关系数据库中使用流行的深度学习框架(如Keras和TensorFlow)执行深度学习算法,那么,这将使企业能够利用他们在SQL中的现有投资,使深度学习更容易,更平易近人。
此外,另一个需要考虑因素是当今许多数据科学问题中需要应用多种模型。一般情况下,数据科学家在分析数据特征工程上经常花费大量时间采用多种方法来解决问题,在这种情况下数据分析的结果通常是多种模型的结合体。在这种情况下,使用同一个计算引擎进行所有的计算将比使用不同系统分别计算然后组合结果更有效率。为此,在数据库内部内建一组机器学习和分析功能,可以使这些计算数据库内执行,这样减少甚至消除在不同的计算环境之间的数据移动,极大的提高计算效率。
Greenplum上使用GPU加速深度学习算法
下图(图1)为Greenplum+GPU的架构图。Keras [1]和TensorFlow [2]等标准深度学习算法库部署在Greenplum的segment节点上,GPU同时也部署在segment节点上,每个节点上的segment共享GPU计算资源。
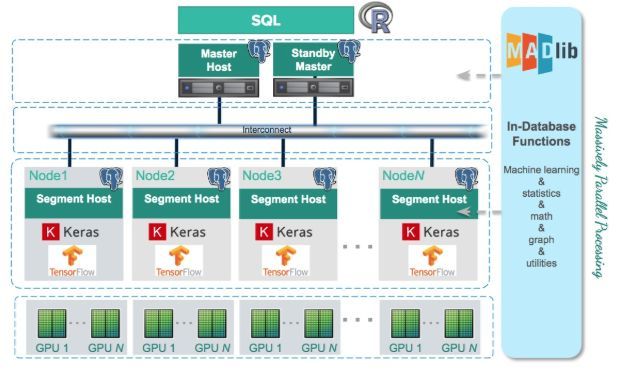
图1:用于深度学习的Greenplum架构
这种架构设计的目的是为了消除segment和GPU之间互连的传输延迟。在这种架构下,每个segment只需要处理本地数据得出结果,与Greenplum 集成在一起的开源机器学习库Apache MADlib负责将每个segment的模型合并在一起得到最终的模型。这种计算方式,利用了MPP的水平横向扩展功能。
MADlib程序设计
使用MADlib进行程序设计非常简单,只需要在SQL中调用Apache MADlib函数即可。在下面的示例中,我们使用MADlib提供的算法在CIFAR-10 [4]图像数据集上训练模型,具体的SQL如下:
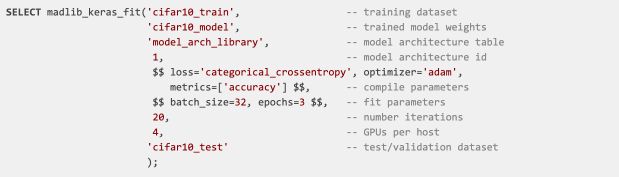
在这个SQL运行结束后,训练的模型存储在表model_arch_library中,model_arch_library中的数据是训练模型卷积神经网络(CNN)的JSON表示。CNN是一种特殊的神经网络,非常擅长图像分类[5]。在上面的SQL中,有一个有用的参数–GPU per host(每个节点的GPU数量),该参数指定每个segmeng节点上用于训练模型的GPU的个数。将参数指定0意味着使用CPU而不是GPU进行训练,这样的话可以在较小数据集上使用浅层神经网络的来调试和试运行。试运行甚至可以在PostgreSQL上。试运行通过之后可以转移到配备昂贵的GPU的Greenplum集群上使用整个数据集上训练深度神经网络。
模型训练完成后,我们可以使用上面训练的模型来进行图像分类,具体的SQL如下:

性能和可伸缩性
现代的GPU具有高内存带宽而且每个芯片的处理单元数量是CPU的200倍,这是因为它们针对并行数据计算(如矩阵运算)进行了优化。CPU则设计的更为通用以执行更多种类的任务。因此使用GPU训练深度神经网络所带来的性能提升是众所周知的。图2显示了常规CPU Greenplum集群与GPU加速Greenplum集群之间的简单深度CNN [6]的性能提升。在这个测试中,我们使用了一个较小的Greenplum集群(具有4个segment)测试了CIFAR-10数据集的的训练时间,结果如下图所示:
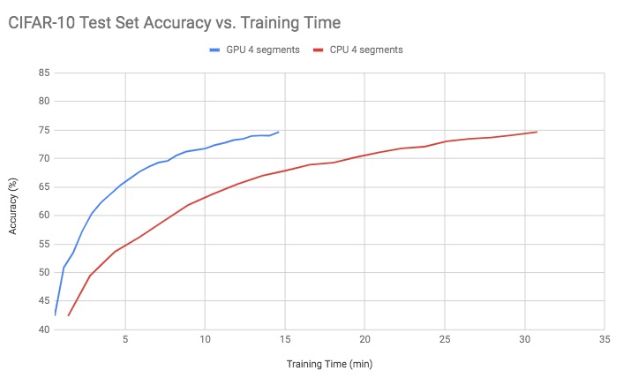
图2:Greenplum数据库GPU与CPU的培训性能*
仅仅使用CPU的情况下Greenplum集群需要超过30分钟的培训时间才能在测试集上达到75%的准确率,而使用GPU加速Greenplum集群在不到15分钟内达到75%的准确率。CIFAR-10图像分辨率仅为32×32 RGB,因此GPU的性能提升则低于高分辨率图像。对于具有256×256 RGB图像的Places数据集[7],我们发现使用GPU加速训练模型比仅使用CPU快6倍[8]。
使用GPU加速模型训练的关键益处是减少模型的训练时间,这意味着数据科学家可以更快地进行模型训练的迭代,并且可以更快地将新训练的模型部署到生产环境中。例如,在欺诈检测的用例下,更快的新模型训练和部署带来的直接益处是财务损失的减少。
推断(inference)的含义是使用训练模型对新数据进行分类。使用Greenplum这样的MPP数据库非常适合批量处理; 吞吐量随着数据库集群的大小以线性方式增加。例如,使用我们上面训练的CNN模型,表1显示了对50,000个新的32x32RGB图像执行批量推断所需的时间。
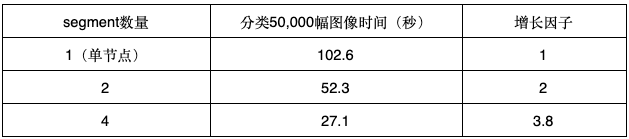
表1:Greenplum数据库集群上的批量分类测试结果
未来的工作
作为Apache MADlib项目的一部分,MADlib社区计划在每个版本中逐步添加新的深度学习功能。例如,一种常见的数据科学工作流程是参数的选择和调整。参数的调整不仅仅包括以模型的参数调整,也涉及模型结构的调整,例如网络层数和组成。这些一般涉及训练几十种到几百种模型的组合,以便找到具有最佳准确度/培训成本概况的组合。在这样大的训练压力下,使用Greenplum这样的MPP数据库,借助并行计算功能可以极大的提高模型训练的效率。
本文使用的测试环境
基础平台:Google Cloud Platform
Greenplum 版本:Greenplum 5
Segment节点配置:32个核心vCPU,150 GB内存
Segment节点GPU配置:NVIDIA Tesla P100 GPU
参考资料
[1] https://keras.io/
[2] https://www.tensorflow.org/
[3] http://madlib.apache.org/
[4] CIFAR-10 dataset,
https://www.cs.toronto.edu/~kriz/cifar.html
[5] Le Cun, Denker, Henderson, Howard, Hubbard and Jackel, Handwritten digit recognition with a back-propagation network, in: Proceedings of the Advances in Neural Information Processing Systems (NIPS), 1989, pp. 396–404.
