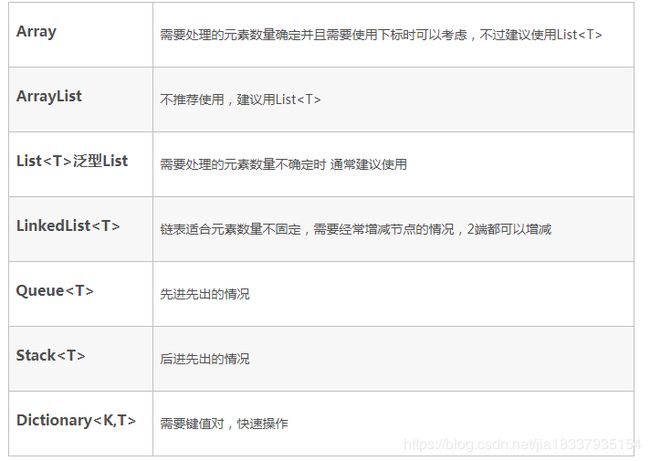
C#常用的数据结构
U3D面试的时候,面试官经常会问到C#数据结构的问题。
在这里记录一下在工作中常碰到的几种数据结构:Array,ArrayList,List,LinkedList,Queue,Stack,Dictionary
1.数组是最简单的数据结构。其具有如下特点:
数组存储在连续的内存上。
数组的内容都是相同类型。
数组可以直接通过下标访问。
数组创建
1 int size = 10;
2 int[] test = new int[size];
创建一个新的数组时将在 CLR 托管堆中分配一块连续的内存空间,来盛放数量为size,类型为所声明类型的数组元素。如果类型为值类型,则将会有size个未装箱的该类型的值被创建。如果类型为引用类型,则将会有size个相应类型的引用被创建。
由于是在连续内存上存储的,所以它的索引速度非常快,访问一个元素的时间是恒定的也就是说与数组的元素数量无关,而且赋值与修改元素也很简单。
string[] test2 = new string[3];
//赋值
test2[0] = "chen";
test2[1] = "j";
test2[2] = "d";
//修改
test2[0] = "chenjd";
但是有优点,那么就一定会伴随着缺点。由于是连续存储,所以在两个元素之间插入新的元素就变得不方便。而且就像上面的代码所显示的那样,声明一个新的数组时,必须指定其长度,这就会存在一个潜在的问题,那就是当我们声明的长度过长时,显然会浪费内存,当我们声明长度过短的时候,则面临这溢出的风险。这就使得写代码像是投机,小匹夫很厌恶这样的行为!针对这种缺点,下面隆重推出ArrayList。
2.ArrayList:
为了解决数组创建时必须指定长度以及只能存放相同类型的缺点而推出的数据结构。ArrayList是System.Collections命名空间下的一部分,所以若要使用则必须引入System.Collections。正如上文所说,ArrayList解决了数组的一些缺点。
不必在声明ArrayList时指定它的长度,这是由于ArrayList对象的长度是按照其中存储的数据来动态增长与缩减的。
ArrayList可以存储不同类型的元素。这是由于ArrayList会把它的元素都当做Object来处理。因而,加入不同类型的元素是允许的。
ArrayList的操作:
ArrayList test3 = new ArrayList();
//新增数据
test3.Add("i");
test3.Add("j");
test3.Add("d");
test3.Add("is");
test3.Add(25);
test3[4] = 26;
test3.RemoveAt(4);
说了那么一堆”优点“,也该说说缺点了吧。为什么要给”优点”打上引号呢?那是因为ArrayList可以存储不同类型数据的原因是由于把所有的类型都当做Object来做处理,也就是说ArrayList的元素其实都是Object类型的,辣么问题就来了。
ArrayList不是类型安全的。因为把不同的类型都当做Object来做处理,很有可能会在使用ArrayList时发生类型不匹配的情况。
如上文所诉,数组存储值类型时并未发生装箱,但是ArrayList由于把所有类型都当做了Object,所以不可避免的当插入值类型时会发生装箱操作,在索引取值时会发生拆箱操作。这能忍吗?
注:为何说频繁的没有必要的装箱和拆箱不能忍呢?且听小匹夫慢慢道来:所谓装箱 (boxing):
就是值类型实例到对象的转换(百度百科)。那么拆箱:就是将引用类型转换为值类型咯(还是来自百度百科)。下面举个栗子~
//装箱,将值类型转成引用类型
int info = 1989;
object obj=(object)info;
//拆箱,引用类型转换成值类型
object obj = 1;
int info = (int)obj;
显然,从原理上可以看出,装箱时,生成的是全新的引用对象,这会有时间损耗,也就是造成效率降低。那么为了解决ArrayList不安全类型与装箱拆箱的缺点,所以出现了泛型的概念,作为一种新的数组类型引入。也是工作中经常用到的数组类型。和ArrayList很相似,长度都可以灵活的改变,最大的不同在于在声明List集合时,我们同时需要为其声明List集合内数据的对象类型,这点又和Array很相似,其实List内部使用了Array来实现。
List test4 = new List();
//新增数据
test4.Add(“Fanyoy”);
test4.Add(“Chenjd”);
//修改数据
test4[1] = “murongxiaopifu”;
//移除数据
test4.RemoveAt(0);
这么做最大的好处就是:(1)即确保了类型安全;(2)也取消了装箱和拆箱的操作;(3)它融合了Array可以快速访问的优点以及ArrayList长度可以灵活变化的优点。
也就是链表了。和上述的数组最大的不同之处就是在于链表在内存存储的排序上可能是不连续的。这是由于链表是通过上一个元素指向下一个元素来排列的,所以可能不能通过下标来访问。如图

既然链表最大的特点就是存储在内存的空间不一定连续,那么链表相对于数组最大优势和劣势就显而易见了。
- 向链表中插入或删除节点无需调整结构的容量。因为本身不是连续存储而是靠各对象的指针所决定,所以添加元素和删除元素都要比数组要有优势。
- 链表适合在需要有序的排序的情境下增加新的元素,这里还拿数组做对比,例如要在数组中间某个位置增加新的元素,则可能需要移动移动很多元素,而对于链表而言可能只是若干元素的指向发生变化而已。
- 有优点就有缺点,由于其在内存空间中不一定是连续排列,所以访问时候无法利用下标,而是必须从头结点开始,逐次遍历下一个节点直到寻找到目标。所以当需要快速访问对象时,数组无疑更有优势。
综上,链表适合元素数量不固定,需要经常增减节点的情况。
关于链表的使用,MSDN上有详细的例子。
在Queue这种数据结构中,最先插入在元素将是最先被删除;反之最后插入的元素将最后被删除,因此队列又称为“先进先出”(FIFO—first in first out)的线性表。通过使用Enqueue和Dequeue这两个方法来实现对 Queue 的存取。
一些需要注意的地方:
- 先进先出的情景。
- 默认情况下,Queue的初始容量为32, 增长因子为2.0。
- 当使用Enqueue时,会判断队列的长度是否足够,若不足,则依据增长因子来增加容量,例如当为初始的2.0时,则队列容量增长2倍。
- 乏善可陈。
关于Queue的使用方法,MSDN上也有相应的例子。

与Queue相对,当需要使用后进先出顺序(LIFO)的数据结构时,我们就需要用到Stack了。
一些需要注意的地方:
- 后进先出的情景。
- 默认容量为10。
- 使用pop和push来操作。
- 乏善可陈。
同样,在这里你也可以看到大量Stack的例子。
字典:
提到字典就不得不说Hashtable哈希表以及Hashing(哈希,也有叫散列的),因为字典的实现方式就是哈希表的实现方式,只不过字典是类型安全的,也就是说当创建字典时,必须声明key和item的类型,这是第一条字典与哈希表的区别。关于哈希表的内容推荐看下这篇博客哈希表。关于哈希,简单的说就是一种将任意长度的消息压缩到某一固定长度,比如某学校的学生学号范围从0000099999,总共5位数字,若每个数字都对应一个索引的话,那么就是100000个索引,但是如果我们使用后3位作为索引,那么索引的范围就变成了000999了,当然会冲突的情况,这种情况就是哈希冲突(Hash Collisions)了。扯远了,关于具体的实现原理还是去看小匹夫推荐的那篇博客吧,当然那篇博客上面那个大大的转字也是蛮刺眼的。。。
回到Dictionary
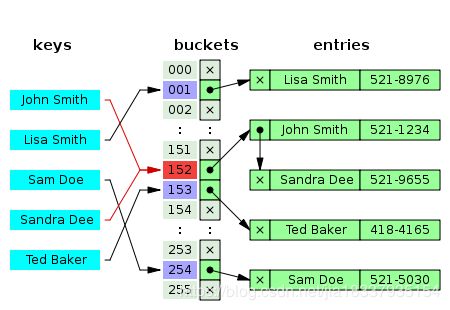
因此,我们面临的情况就是,即便我们新建了一个空的字典,那么伴随而来的是2个长度为3的数组。所以当处理的数据不多时,还是慎重使用字典为好,很多情况下使用数组也是可以接受的。