大规模分布式系统的跟踪系统:Dapper设计给我们的启示
在2010年,google发表了一篇名为“Dapper, a Large-Scale Distributed Systems Tracing Infrastructure”的论文,在文中介绍了google生产环境中大规模分布式系统下的跟踪系统Dapper的设计和使用经验。而zipkin/pinpoint/hydra/watchman/鹰眼等系统都是基于这篇文章而实现的。重新再读这篇文章,简单整理如下。
为什么需要跟踪系统
故障快速定位
快速的故障定位非常重要,一个好的系统需要提供快速检测/隔离/修复问题的方式,传统方式缺乏这种机制,而快速定位则是这个机制的重要一环,由于缺乏快速定位机制,当关键业务相关应用服务停止或者性能恶化,对业务有直接影响时,由于缺乏有效和快速的应对措施,往往由最终用户的反馈作为整个定位的开始一环,往往已经是损失很难挽回的时间点了。
恶性循环的形成
由于缺乏快速定位机制,既存那些长期的性能低下问题以及重复出现的问题很难精确定位,产生了大量的技术债务。而随着新的功能的不断添加,同样无法尽早或者预先发现问题导致问题也不断的累积。修改自身也可能会导致更多问题的引入,从而形成了恶性循环。
现状把握&决策支持
根据跟踪系统提供的数据可以提供及时和全面的性能报告,并且在此基础之上,能够做进一步的分析从而提供决策支持的所需数据,比如根据收集的信息可以对用户行为/模式分析:从而进一步地进行测量和管控。
背景
现代的应用服务,往往是非常复杂的,如下的情况非常常见:
软件的模块有不同团队开发
整体由多种编程语言实现
牵扯到多种操作系统和硬件
关联不同数据中心的众多服务器
…
在这样的背景下,跟踪系统更加复杂,传统方式的跟踪系统往往是系统整体机能的一部分,往往侵入性过强,往往会产生由监控代码段引入的缺陷出现,同时由于监控间隔的设定调整也往往会对整体性能带来较大的负担,尤其是实时跟踪的场合下。
启示1: 跟踪系统的需求
在Dapper的论文这样认为,有两个重要的需求需要予以满足:ubiquitous deployment和continuous monitoring。而这两个需求是对跟踪系统的使用范围(不要有死角)和运行方式(不要停)做了规范。
ubiquitous deployment(无所不在的部署)
原文摘录:Ubiquity is important since the usefulness of a tracing infrastructure can be severly impacted if even small parts of the system are not being monitored.
实际上,所谓的无所不在的部署,指的是追踪系统的监控对象应该是没有死角的,所以值得是范围上应该尽可能广地将系统纳入监控范围之内,尽量避免死角,即使是很小的一部分没有被监控到也会对追踪系统的有效性产生很大的影响。
continuous monitoring(持续的监控)
持续的监控指的是不要关闭追踪系统,因为很多异常的系统的行为往往非常难以再现,在追踪系统中保留这些信息显然非常重要。
启示2: 跟踪系统的三大设计要点
dapper在设计的时候考虑到了上述的背景,作为大规模集群的跟踪系统,需要满足如下三大设计要点:
低损耗(Low overhead)
跟踪系统自身不应当带来很高的新的性能,跟踪系统需要达成很低的损耗才行。但是多低是低?dapper论文中提到的是negligible,negligible有“微不足道的,可以忽略的”意思,这也是低的定义,如果从度量上来看,pinpoint的实现是3%一下,这个自然是在能够满足需求的情况下,越低越好。
应用级透明(Application-level transparency)
对应用级透明是非常重要的一个设计要点,而此点也正是dapper的这篇文章引起热烈反响的因素之一。应用时不断增长的,如果跟踪系统在设计上无法做到对于应用程序的较小侵入性,会导致维护的成本以及出现额外缺陷的机率大大提高。理想的做法是能达到文章中所提到的那样:程序员应该不需要意识到有追踪系统的存在。而在实际的实践中,比如引入zipkin或者pinpoint,或多或少还是需要一定的成本,至少跟踪系统的植入点不会与业务逻辑紧密耦合这种程度是可以实现的,但是完全无意识追踪系统的存在,在具体的实现上还是需要结合系统特点,不是一蹴而就的目标。
扩展性(Scalability)
至少未来几年的服务和集群的扩展,跟踪系统应该具有相关的扩展性能够适应。
启示3: 跟踪系统的KPI
- 采样率:根据google的实践经验,采样率效率1/16时即能避免明显延迟,性能损耗在实验误差范围之内。跟踪大量服务时,采样率调整到1/1024能有足够跟踪数据,同时能保证性能损耗非常低。Dapper的第一个生产版本对所有进程采用1/1024的统一采样率,后来演进为可变采样率。
- 损耗:跟踪系统自身的性能影响对于系统应该是能够忽略不计的,pinpoint控制在3%之内。
- 实效性:跟踪数据产生之后,分析的速度需要及时快速,理想状况数据在一分钟之内能够统计出来,以便对于生产环境的异常状况作出快速反应。
启示4: 可以关闭的跟踪系统
考虑到性能和安全的因素,生产环境的跟踪系统应该也可以关闭。虽然前面提到一个重要的需求就是持续的监控,但是理想和现实之间还是有许多事情需要认证面对的,实际上,google早期生产环境中dapper就是默认关闭的,知道对其稳定性和低损耗有了足够信息之后才将其打开了。
启示5: 准确定位延迟问题
当一个系统涉及到多个子系统和多个开发团队的情况下,端到端的性能问题的根本原因的定位可以通过跟踪系统来进行。google通过使用dapper提供了这种情况下的急需数据,其实践有如下经验:
1. 问题往往来源于一些意想不到的服务之间的交互,问题的纠正往往比较容易,而在dapper引入之前发现较为困难
2. 简化跟踪的接口,使用唯一的追踪ID,便于集成和检测
启示6: 跟踪系统给开发团队能带来什么
根据google的实践,跟踪系统能够帮助开发团队快速定位需要优化的应用,以及确定关键路径上非必要的串行请求。另外还能根据其结果评估各种方式下的性能成本,根据切实的数据提供决策支持。
启示7: 安全和隐私的考虑
跟踪系统能够记录一定的信息用于解释系统异常的原因,然后,这些数据可能包含一些不应该透露的内部信息,而这些信息可能正在调试的工程师也无权访问。所以,需要考虑是否存在安全和隐私相关的问题,然后进行适当的处理,在这一点上很多工具还没有做太多的强化,主要原因应该在于相关的工具场景目前还是主要局限在用户请求的调用链的性能分析了。但是安全和隐私数据的问题是需要考虑的一个重要因素。
启示8: dapper系统的核心构成
dapper是通过trace tree和span构建跟踪系统的。
span
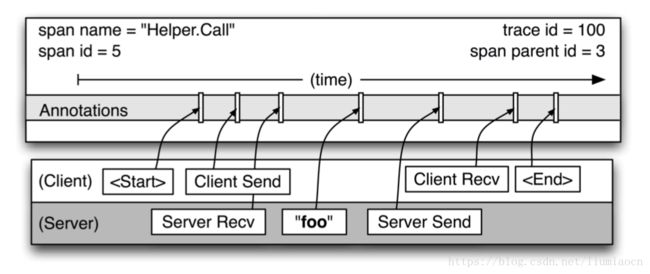
span是用用于记录一个服务调用的过程的结构,一个典型的跟踪系统中,一次RPC调用会对应到一个的span上,dapper中定义了span相关的如下信息:
- span名称:用于记录span的名称
- spanid:用于记录span的Id,一般用全局唯一的64位整数表示
- 父spanid:父span的spanid,用于描述跟踪树结构
- 事件信息:cs/cr/sr/ss四种事件类型,span不同的事件类型对应不同的时间戳,根据这些时间戳,可计算出不同阶段的耗时信息。
- annotation:一般,事件信息在annotation中存放,另外自定义的信息也可以与之关联
| 缩写 | 全称 | 说明 |
|---|---|---|
| cs | client send | 客户端/消费者发起请求 |
| cr | client receive | 客户端/消费者接收到应答 |
| sr | server receive | 服务端/生产者接收到请求 |
| ss | server send | 服务端/生产者发送应答 |
trace tree

一个请求可能跟多个服务调用关联,每次服务的调用与一个span进行关联,而span之间通过父spanid进行连接,这样所组成的一个树形结构就是所谓的跟踪树,这个结构显示体现了某一请求的服务调用链的状况。比如论文中的例子即为一个典型的三层架构的例子:具体说明如下:
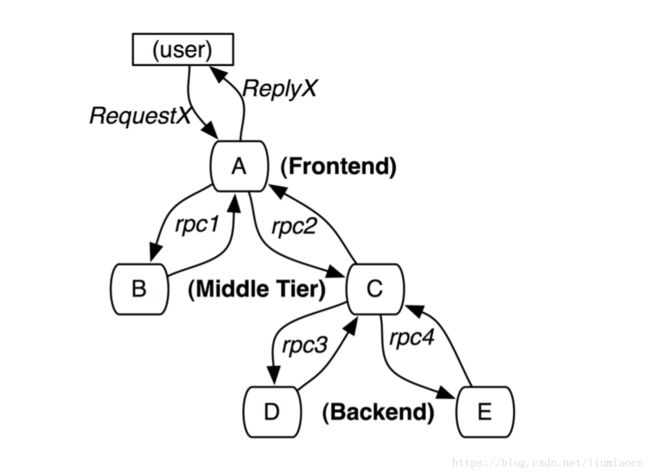
| 层次 | 服务名称 | 父span | 调用顺序 |
|---|---|---|---|
| 前端 | Frontend:A | 无 | 1 |
| 中间 | MiddleTier:B | A | 2 |
| 中间 | MiddleTier:C | A | 3 |
| 后端 | Backend:D | C | 4 |
| 后端 | Backend:E | C | 5 |
这样的一个树形结构,表现出来的调用顺序则是:A->B->C->D->E。这样的一个简洁的设计,就是dapper的主要构成,可以看出其与业务逻辑基本不相关的一个通用的模型,而在zipkin等的实现中,可以清晰地看到dapper的整体设计思路。
启示9: 定位全局网络流量和使用率
Dapper不是设计用来做链路级的监控的,但是在实践中发现,其比较适合去做集群之间活动性的应用及认为分析,显示集群之间最活跃的网络流量的应用级热点,与传统的的网络相关的工具相比,最重要的特点是dapper可以定位到应用程序级别的根本问题。
启示10:dapper不太适合的场景
dapper的模型的隐含前提是不同的子系统使用同一个被跟踪的请求所产生的连锁链式调用栈的情况。如果是多个追踪请求合并起来,而最终只使用其中的一个的情况则无法很好地对应。
dapper可以找出性能瓶颈,但是并不一定能准确定位到根本原因,因为定位出很慢的结果往往是由其他请求造成的,而这则需要进一步的分析。
dapper的设计主要是针对在线服务的系统,尤其是一个用户请求的系统行为,但是离线的情况下,则不能直接使用,需要一些人工的关联和干预行为。
Dapper的实现
| 工具名称 | 提供商 | 类型 | 源码地址 |
|---|---|---|---|
| Zipkin | 开源 | https://github.com/openzipkin/zipkin | |
| pinpoint | naver | 开源 | https://github.com/naver/pinpoint |
| appdash | sourcegraph | 开源 | https://github.com/sourcegraph/appdash |
| cat | 大众点评 | 开源 | https://github.com/dianping/cat |
| hydra | 京东 | 开源 | https://github.com/odenny/hydra |
| 鹰眼 | 阿里 | 闭源 | - |
| oneAPM | oneapm | 闭源 | - |
参考文献:google的dapper论文
- E文原版:http://research.google.com/pubs/pub36356.html
- 中文翻译:http://bigbully.github.io/Dapper-translation/