SparkSql
目录(SparkSql)
- 本质(是什么)(我在试着讲明白)
- 作用(干什么)(我在试着讲明白)
- 架构(有什么)(我在试着讲明白)
- Spark SQL由core,catalyst,hive和hive-thriftserver4个部分组成。
- 1.Catalyst执行优化器
- UDF
- UDAF
- 开窗函数
- 优缺点(我在试着讲明白)
- 优点
- 缺点
- 流程(怎么运作)(我在试着讲明白)
- Sql运行流程
- sparkSql 运行原理分析
- 1.使用SesstionCatalog保存元数据
- 2.使用Antlr生成未绑定的逻辑计划
- 3.使用Analyzer绑定逻辑计划
- 4.使用Optimizer优化逻辑计划
- 5.使用SparkPlanner生成可执行计划的物理计划
- 6.使用QueryExecution执行物理计划
- 常用(必会)(我在试着讲明白)
- 创建DataFrame的方式
- 保存DataFrame的目标源
- 常见问题(必知)(我在试着讲明白)
- RDD和DataFrame的区别
- 配置 Spark on Hive
- 异议
本质(是什么)(我在试着讲明白)
SparkSql 的官网是: http://spark.apache.org/sql/
sparkSql 是 spark on hive 一种基于 内存 的 交互式查询 应用服务。
spark 负责 解析优化、执行引擎。hive 负责存储
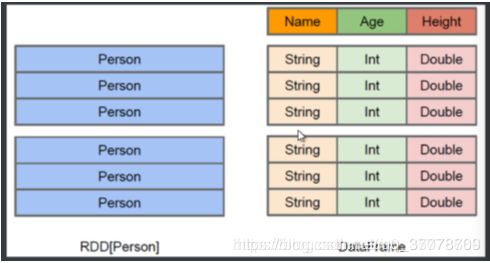
sparkSql 底层是 DataFrame(可以理解成一个二维表格,有数据、列的schema信息)
作用(干什么)(我在试着讲明白)
hive :将hive sql 转换成 mr,减少了mr查询的复杂性,但慢!
使spark脱离hive,不依赖hive 的解析优化
sparkSql 用来处理结构化的一个模块。提供一个抽象的数据集DataFrame,作为分布式Sql查询引擎的应用。
架构(有什么)(我在试着讲明白)
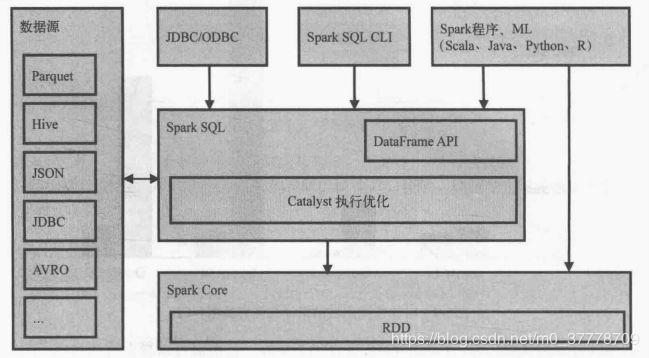
Spark SQL由core,catalyst,hive和hive-thriftserver4个部分组成。
core: 负责处理数据的输入/输出,从不同的数据源获取数据(如RDD,Parquet文件和JSON文件等),然后将结果查询结果输出成Data Frame。
catalyst: 负责处理查询语句的整个处理过程,包括解析,绑定,优化,生成物理计划等。
hive: 负责对hive数据的处理。
hive-thriftserver:提供client和JDBC/ODBC等接口。
而sparksql的查询优化器是catalyst,它负责处理查询语句的解析,绑定,优化和生成物理执行计划等过程,catalyst是sparksql最核心部分。
sparkSql是spark Core之上的一个模块,sql最终都通过Catalyst翻译成类似的spark程序代码被sparkCore执行,过程也有 job、stage、task的概念
1.Catalyst执行优化器
1.1 Catalyst最主要的数据结构是树,所有的SQL语句都会用树结构来存储,树中的每个节点都有一个类,以及0或多个子节点。Scala中定义的新的节点类型都是TreeNode这个类的子类,这些对象是不可变的。
1.2 Catalyst另外一个重要的概念是规则,基本上,所有的优化都是基于规则的。
1.3 执行过程
1 分析阶段
分析逻辑树,解决引用
使用Catalyst规则和Catalog对象来跟踪所有数据源中的表,以解决所有未辨识的属性
2 逻辑优化
3 物理计划
Catalyst会生成很多计划,并基于成本进行对比
接受一个逻辑计划作为输入,生产一个或多个物理计划
4 代码生成
将Spark SQL代码编译成Java字节码
UDF
user defined function,用户自定义函数
用法:
java:sqlContext.udf().register(“StrLen”, new UDF1
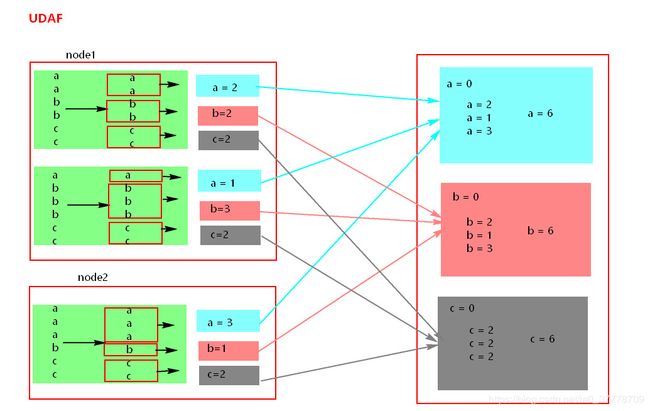
UDAF
user defined aggregate function,用户自定义聚合函数
count,avg,sum,min,max… 特点:多对一,select name ,count(*) from table group by name
是聚合函数,要继承 UserDefinedAggregateFunction() 实现8个方法,最重要三个方法
initialize
update
merge
开窗函数
优缺点(我在试着讲明白)
优点
意整性
统一的数据访问方式
兼容hive
提供了统一的数据连接方式(JDBC/ODBC)
缺点
流程(怎么运作)(我在试着讲明白)
Sql运行流程

1 . 语法和词法解析:对写入的sql语句进行词法和语法解析(parse),分辨出sql语句在哪些是关键词(如select ,from 和where),哪些是表达式,哪些是projection ,哪些是datasource等,判断SQL语法是否规范,并形成逻辑计划。
2 .绑定:将SQL语句和数据库的数据字典(列,表,视图等)进行绑定(bind),如果相关的projection和datasource等都在的话,则表示这个SQL语句是可以执行的。
3 .优化(optimize):一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划。
4 .执行(execute):执行前面的步骤获取最有执行计划,返回查询的数据集。
sparkSql 运行原理分析
1.使用SesstionCatalog保存元数据
在解析sql语句前需要初始化sqlcontext,它定义sparksql上下文,在输入sql语句前会加载SesstionCatalog,初始化sqlcontext时会把元数据保存在SesstionCatalog中,包括库名,表名,字段,字段类型等。这些数据将在解析未绑定的逻辑计划上使用。
2.使用Antlr生成未绑定的逻辑计划
Spark2.0版本起使用Antlr进行词法和语法解析,Antlr会构建一个按照关键字生成的语法树,也就是生成的未绑定的逻辑计划。
3.使用Analyzer绑定逻辑计划
在这个阶段Analyzer 使用Analysis Rules,结合SessionCatalog元数据,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划。
4.使用Optimizer优化逻辑计划
Opetimize(优化器)的实现和处理方式同Analyzer类似,在该类中定义一系列Rule,利用这些Rule对逻辑计划和Expression进行迭代处理,达到树的节点的合并和优化。
5.使用SparkPlanner生成可执行计划的物理计划
SparkPlanner使用Planning Strategies对优化的逻辑计划进行转化,生成可执行的物理计划。
6.使用QueryExecution执行物理计划
常用(必会)(我在试着讲明白)
创建DataFrame的方式
- 读取json格式的文件
- 读取json格式的RDD 、DataSet
- 读取RDD创建DataFrame
- 读取parquet格式数据加载DataFrame
- 读取Mysql找那个的数据加载成DataFrame
- 读取Hive中数据加载DataFrame
保存DataFrame的目标源
- parquet文件
- Mysql表中
- Hive表中
常见问题(必知)(我在试着讲明白)
RDD和DataFrame的区别
配置 Spark on Hive
配置 Spark on Hive
1.在客户端 …/conf/中创建hive-site.xml,让SparkSQL找到Hive原数据
hive.metastore.uris
thrift://node1:9083
2.在Hive的服务端启动metaStore 服务 : hive --service metastore &
3.使用spark-shell 测试 速度
异议
有差错或者需要补充的地方,还望大家评论指出,并详细论证,相互学习,共同进步哈!