DSTC9介绍
1. 数据集
logs.json文件是实例列表,每个实例是用户从开始到结束对话的一部分
- speaker:每一轮的说话人(“U"代表"User”,“S"代表"System”)
- text:说话内容
labels.json文件是logs.json中每个实例的最后回合的真实的标签和人工响应。 按照和输入实例相同的顺序包括以下对象的列表:
- target:该回合是否属于knowledge-seeking(boolean:true/false)
- knowledge:[
domain:在knowledge.json中涉及的相关知识片段所属领域(string)
entity_id:在knowledge.json中涉及的相关知识片段的实体标志(特定领域知识是integer, 对范领域知识是string *)
doc_id:在knowledge.json中涉及的相关知识片段的文档标志(integer)] - response:系统响应的真实知识(string)
NOTE:knowledge和response只有在target是True时才有值
knowledge.json包含的是用于任务中的非结构知识源,它包含范领域或特定实体的知识片段,格式如下:
- domain_id:domain标志(string:“hotel”, “restaurant”, “train”, “taxi”, etc)
- entity_id:实体标志(string or integer:* for domain-wide knowledge)
- name:实体名字(string;only exists for entity-specific knowledge)
- doc_id:文档标志(integer)
- title:文档标题(string)
- body:文档主体(string)
2. 任务
DSTC9 track1赛道将对话中不需要额外知识库,当前的任务型对话模型就能解决的情况和需要额外知识库的情况分开,本次主要聚焦需要额外知识库的情况。
Task1: Knowledge-seeking Turn Detection(是否需要知识)
goal:对于给定的句子和对话历史确定是否继续当前情景还是触发知识库分支
input:当前user的句子,对话历史,知识库片段
output:二分类(True or False)
Task2: Knowledge Selection(选择知识)
goal:给定每轮的对话状态,从领域知识库中选择合适知识源
input:当前用户语句,对话历史,知识片段
output:top-k的候选知识
Task3:Knowledge-grounded Response Generation(根据知识来产生响应)
goal:使用输入句子,对话历史,和所选的知识片段来产生系统响应
input:当前用户输入语句,对话历史,选择的知识片段
output:系统响应
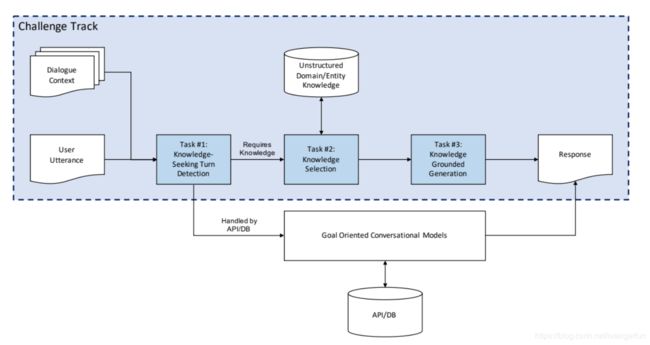
3. baseline介绍
3.1 Task1
3.1.1 数据处理
knowledge.json数据格式:
{
domain:{
entity_id:{
entity_name: "name"
docs:{
doc_id: {
title: title
body: body
}
doc_id: {
}
....
}
}
entity_id:{
}
...
}
}
_prepare_conversations返回值tokenized_dialogs
[{
"id":1,
"log":[
{
"speaker": "U",
"text": "Looking for a place to eat in the city center."
}
],
"label":{
"target": true,
"knowledge": [
{
"domain": "hotel",
"entity_id": 11,
"doc_id": 12
}
],
"response": "Yes. This property has accessible parking. Any other question?"
"response_tokenized": [1 4 5 9 10 12 16]
}
},
{},
...]
_create_examples函数返回值self.examples:
[{
"history": truncated_history,
"knowledge": used_knowledge,
"candidates": knowledge_candidates,
"response": tokenized_gt_resp,
"response_text": gt_resp,
"label": label,
"knowledge_seeking": target,
"dialog_id": dialog_id
},
{},
...
]
一个字典表示一轮对话,其中:
history:list, 该轮对话的上下文 [[], []...]
knowledge:str, 该轮对话涉及的知识库, 已转成id形式
candidates:list, 在一个domain和entity_id下所涉及的所有的knowledge, 这里面村的是知识对应的键值
response:str, 一轮对话后涉及的响应, id形式
response_text:str, 形式
label:dict, 形如:{
# "target": true,
# "knowledge": [
# {
# "domain": "hotel",
# "entity_id": 11,
# "doc_id": 12
# }
# ],
# "response": "Yes. This property has accessible parking. Any other question?"
# "response_tokenized": [1 4 5 9 10 12 16]
# }
# }]
knowledge_seeking:boolean,是否要进行使用知识库
dialog_id:对话id
最后创建的train_dataset类每个iter返回值
def __getitem__(self, index):
example = self.examples[index]
instance, _ = self.build_input_from_segments(example["history"])
instance["label"] = example["knowledge_seeking"]
instance["dialog_id"] = example["dialog_id"]
return instance
instance是个dict, 形如:
{
input_ids: sequence = [bos, speaker1, .., speaker2, ..., speaker1..., ...konwledge_tag, history[-1], eos]
token_type_ids: 记录上面每部分是哪个说的,speaker1 or speaker2
mc_token_ids: len(sequence)-1, 记录一个history的长度
label: 是否要使用知识库
dialog_id: 对话id
}
最后经过DataLoader函数生成batch结果为:
input_ids: sequence = [bos, speaker1, .., speaker2, ..., speaker1..., ...konwledge_tag, history[-1], eos]
token_type_ids: 记录上面每部分是哪个说的,speaker1 or speaker2
mc_token_ids: len(sequence)-1, 最后一个词的索引,用于后面用最后一个词来分类
lm_labels:和input_ids shape相同,但里面的值全为-100
labels:是否要使用知识库
data_info: dict , dialog_id
3.1.2 训练
直接使用最后一个词来分类
train 入口
for _ in train_iterator:
local_steps = 0
tr_loss = 0.0
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
model.train()
loss, _, _, _ = run_batch_fn_train(args, model, batch)
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
tr_loss += loss.item()
train 辅助
def run_batch_detection(args, model, batch):
batch = tuple(input_tensor.to(args.device) for input_tensor in batch if isinstance(input_tensor, torch.Tensor))
input_ids, token_type_ids, mc_token_ids, lm_labels, labels = batch
model_outputs = model(
input_ids=input_ids, token_type_ids=token_type_ids,
mc_token_ids=mc_token_ids, labels=labels
)
cls_loss = model_outputs[0]
lm_logits, cls_logits = model_outputs[1], model_outputs[2]
return cls_loss, lm_logits, cls_logits, labels
model
class GPT2ClsDoubleHeadsModel(GPT2PreTrainedModel):
def __init__(self, config):
super().__init__(config)
config.num_labels = 1
self.transformer = GPT2Model(config)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.cls_head = SequenceSummary(config)
self.init_weights()
def get_output_embeddings(self):
return self.lm_head
def forward(
self,
input_ids=None,
past=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
mc_token_ids=None,
lm_labels=None,
labels=None,
):
transformer_outputs = self.transformer(
input_ids,
past=past,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
)
hidden_states = transformer_outputs[0]
# 使用hidden_states与词嵌入相乘,获得hidden_states中各个单词最相近单词得分[batch_size, seq_len, vocab_size]
lm_logits = self.lm_head(hidden_states)
# 从hidden_states中取出最后一个单词来分类[batch_size, num_classes]
cls_logits = self.cls_head(hidden_states, mc_token_ids).squeeze(-1)
outputs = (lm_logits, cls_logits) + transformer_outputs[1:]
if labels is not None:
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(cls_logits, labels)
outputs = (loss,) + outputs
if lm_labels is not None:
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = lm_labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
outputs = (loss,) + outputs
return outputs # (lm loss), (mc loss), lm logits, mc logits, presents, (all hidden_states), (attentions)
3.2 Task2
3.2.1 构造数据
构造数据类:入口
class KnowledgeSelectionDataset(BaseDataset):
....
def __getitem__(self, index):
example = self.examples[index]
this_inst = {
"dialog_id": example["dialog_id"],
"input_ids": [],
"token_type_ids": [],
"mc_token_ids": []
}
if self.split_type != "train":
# if eval_all_snippets is set, we use all snippets as candidates
if self.args.eval_all_snippets:
candidates = list(self.snippets.keys())
else:
candidates = example["candidates"]
else:
if self.args.negative_sample_method == "all":
candidates = list(self.snippets.keys())
elif self.args.negative_sample_method == "mix":
candidates = example["candidates"] + random.sample(list(self.snippets.keys()), k=len(example["candidates"]))
elif self.args.negative_sample_method == "oracle":
candidates = example["candidates"]
else: # although we have already checked for this, still adding this here to be sure
raise ValueError("negative_sample_method must be all, mix, or oracle, got %s" % self.args.negative_sample_method)
# candidate候选键值
candidate_keys = candidates
this_inst["candidate_keys"] = candidate_keys
# candidate的候选内容
candidates = [self.snippets[cand_key] for cand_key in candidates]
if self.split_type == "train":
candidates = self._shrink_label_cands(example["knowledge"], candidates)
label_idx = candidates.index(example["knowledge"])
this_inst["label_idx"] = label_idx
for cand in candidates:
instance, _ = self.build_input_from_segments(
cand,
example["history"]
)
this_inst["input_ids"].append(instance["input_ids"])
this_inst["token_type_ids"].append(instance["token_type_ids"])
this_inst["mc_token_ids"].append(instance["mc_token_ids"])
return this_inst
返回值:this_inst
this_inst = {
"dialog_id": example["dialog_id"], 样本标号
"input_ids": [instances["input_ids"]], 输入序列,同task1
"token_type_ids": [instance["token_type_ids"]], 记录上面每部分是哪个说的,speaker1 or speaker2, 同task1
"mc_token_ids": [instance["mc_token_ids"]], 最后一个词的索引,用于后面用最后一个词来分类
"candidate_keys": candidate_keys, 候选知识的键值
"label_idx": label_idx, 候选知识的label id
}
最后经过DataLoader函数后返回数据
input_ids: 输入序列
token_type_ids:每个词属于哪个说的,speaker1 or speaker2
mc_token_ids: 每个句子最后一个词的索引
lm_labels:shape 同input_ids, 但是里面填充的值为-100
label_idx:候选知识的label_id
data_info:{
"dialog_ids": [ins["dialog_id"] for ins in batch],
"candidate_keys": [ins["candidate_keys"] for ins in batch]
}
3.2.2 训练
训练入口
global_step, tr_loss = train(args, train_dataset, eval_dataset, model, tokenizer, run_batch_fn_train, run_batch_fn_eval)
def train(args, train_dataset, eval_dataset, model: PreTrainedModel, tokenizer: PreTrainedTokenizer, run_batch_fn_train, run_batch_fn_eval) -> Tuple[int, float]:
....
train_dataloader = DataLoader(
train_dataset,
sampler=train_sampler,
batch_size=args.train_batch_size,
collate_fn=train_dataset.collate_fn
)
....
for _ in train_iterator:
local_steps = 0
tr_loss = 0.0
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
model.train()
loss, _, _, _ = run_batch_fn_train(args, model, batch)
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
if args.fp16:
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
global_step += 1
local_steps += 1
epoch_iterator.set_postfix(Loss=tr_loss/local_steps)
辅助训练函数
loss, _, _, _ = run_batch_fn_train(args, model, batch)
def run_batch_selection_train(args, model, batch):
batch = tuple(input_tensor.to(args.device) for input_tensor in batch if isinstance(input_tensor, torch.Tensor))
input_ids, token_type_ids, mc_token_ids, lm_labels, mc_labels = batch
model_outputs = model(
input_ids=input_ids, token_type_ids=token_type_ids,
mc_token_ids=mc_token_ids, mc_labels=mc_labels
)
mc_loss = model_outputs[0]
lm_logits, mc_logits = model_outputs[1], model_outputs[2]
return mc_loss, lm_logits, mc_logits, mc_labels
model
def forward(
self,
input_ids=None,
past=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
mc_token_ids=None,
lm_labels=None,
mc_labels=None,
):
transformer_outputs = self.transformer(
input_ids,
past=past,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
)
hidden_states = transformer_outputs[0]
lm_logits = self.lm_head(hidden_states)
mc_logits = self.multiple_choice_head(hidden_states, mc_token_ids).squeeze(-1)
outputs = (lm_logits, mc_logits) + transformer_outputs[1:]
if mc_labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(mc_logits.view(-1, mc_logits.size(-1)), mc_labels.view(-1))
outputs = (loss,) + outputs
if lm_labels is not None:
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = lm_labels[..., 1:].contiguous()
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
outputs = (loss,) + outputs
return outputs # (lm loss), (mc loss), lm logits, mc logits, presents, (all hidden_states), (attentions)
reference
Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access
Neural Baseline Models for DSTC9 Track 1
DSTC9 Track 1 Dataset
baseline code
DSTC9 官网