java工程师笔试题目一
1.下面有关JVM内存,说法错误的是?
A.程序计数器是一个比较小的内存区域,用于指示当前线程所执行的字节码执行到了第几行,是线程隔离的
B.虚拟机栈描述的是Java方法执行的内存模型,用于存储局部变量,操作数栈,动态链接,方法出口等信息,是线程隔离的
C.方法区用于存储JVM加载的类信息、常量、静态变量、以及编译器编译后的代码等数据,是线程隔离的
D.原则上讲,所有的对象都在堆区上分配内存,是线程之间共享的
运行时数据区包括:程序计数器、虚拟机栈、本地方法栈、Java堆、方法区以及方法区中的运行时常量池
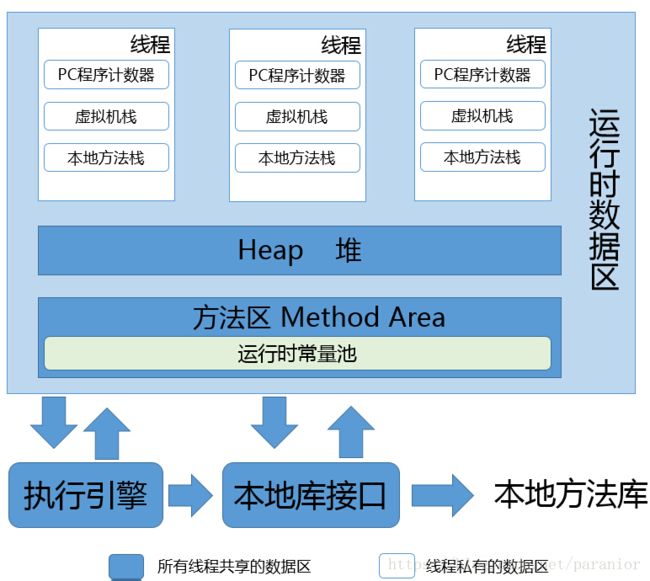
1、程序计数器: 线程私有,是当前线程所执行的字节码的行号指示器,如果线程正执行一个java方法,计数器记录正在执行的虚拟机字节码指令的地址,如果线程正在执行的是Native方法,则计数器值为空;
2、虚拟机栈: 即栈区, 线程私有 ,为虚拟机执行 Java 方法(字节码)服务,每个方法在执行的时会创建一个栈帧用于存放局部变量表、操作数栈、动态链接和方法出口等信息,每个方法的调用直至执行完成对应于栈帧的入栈和出栈;
3、本地方法栈: 为虚拟机使用的 N ative 方法服务,也是 线程私有 ;
4、Java 堆: 在虚拟机启动时创建, 线程共享 ,唯一目的是存放对象实例,是垃圾收集器管理的主要区域——” GC 堆“,可以细分为新生代和老年代,新生代又可以细分为 Eden 空间、 From Survivor 空间和 To Survivor 空间;物理上可以不连续,但逻辑上连续,可以选择固定大小或者扩展;
5、方法区: 线程共享 ,用于存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。被称为“永久代”,是因为 HotSpot 虚拟机的设计团队把 GC 分代收集扩展到方法区,即使用永久代来实现方法区,像 GC 管理 Java 堆一样管理方法区,从而省去专门为方法区编写内存管理代码,内存回收目标是针对常量池的回收和堆类型的卸载;
2. 下面有关SPRING的事务传播特性,说法错误的是?
A.PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行
B.PROPAGATION_REQUIRED:支持当前事务,如果当前没有事务,就抛出异常
C.PROPAGATION_REQUIRES_NEW:新建事务,如果当前存在事务,把当前事务挂起
D.PROPAGATION_NESTED:支持当前事务,新增Savepoint点,与当前事务同步提交或回滚
事务属性的种类: 传播行为、隔离级别、只读和事务超时
a) 传播行为定义了被调用方法的事务边界
传播行为 |
意义 |
PROPERGATION_MANDATORY |
表示方法必须运行在一个事务中,如果当前事务不存在,就抛出异常 |
PROPAGATION_NESTED |
表示如果当前事务存在,则方法应该运行在一个嵌套事务中。否则,它看起来和 PROPAGATION_REQUIRED 看起来没什么俩样 |
PROPAGATION_NEVER |
表示方法不能运行在一个事务中,否则抛出异常 |
PROPAGATION_NOT_SUPPORTED |
表示方法不能运行在一个事务中,如果当前存在一个事务,则该方法将被挂起 |
PROPAGATION_REQUIRED |
表示当前方法必须运行在一个事务中,如果当前存在一个事务,那么该方法运行在这个事务中,否则,将创建一个新的事务 |
PROPAGATION_REQUIRES_NEW |
表示当前方法必须运行在自己的事务中,如果当前存在一个事务,那么这个事务将在该方法运行期间被挂起 |
PROPAGATION_SUPPORTS |
表示当前方法不需要运行在一个是事务中,但如果有一个事务已经存在,该方法也可以运行在这个事务中 |
b) 隔离级别
在操作数据时可能带来 3 个副作用,分别是脏读、不可重复读、幻读。为了避免这 3 中副作用的发生,在标准的 SQL 语句中定义了 4 种隔离级别,分别是未提交读、已提交读、可重复读、可序列化。而在 spring 事务中提供了 5 种隔离级别来对应在 SQL 中定义的 4 种隔离级别,如下:
隔离级别 |
意义 |
ISOLATION_DEFAULT |
使用后端数据库默认的隔离级别 |
ISOLATION_READ_UNCOMMITTED |
允许读取未提交的数据(对应未提交读),可能导致脏读、不可重复读、幻读 |
ISOLATION_READ_COMMITTED |
允许在一个事务中读取另一个已经提交的事务中的数据(对应已提交读)。可以避免脏读,但是无法避免不可重复读和幻读 |
ISOLATION_REPEATABLE_READ |
一个事务不可能更新由另一个事务修改但尚未提交(回滚)的数据(对应可重复读)。可以避免脏读和不可重复读,但无法避免幻读 |
ISOLATION_SERIALIZABLE |
这种隔离级别是所有的事务都在一个执行队列中,依次顺序执行,而不是并行(对应可序列化)。可以避免脏读、不可重复读、幻读。但是这种隔离级别效率很低,因此,除非必须,否则不建议使用。 |
c) 只读
如果在一个事务中所有关于数据库的操作都是只读的,也就是说,这些操作只读取数据库中的数据,而并不更新数据,那么应将事务设为只读模式( READ_ONLY_MARKER ) , 这样更有利于数据库进行优化 。
因为只读的优化措施是事务启动后由数据库实施的,因此,只有将那些具有可能启动新事务的传播行为 (PROPAGATION_NESTED 、 PROPAGATION_REQUIRED 、 PROPAGATION_REQUIRED_NEW) 的方法的事务标记成只读才有意义。
如果使用 Hibernate 作为持久化机制,那么将事务标记为只读后,会将 Hibernate 的 flush 模式设置为 FULSH_NEVER, 以告诉 Hibernate 避免和数据库之间进行不必要的同步,并将所有更新延迟到事务结束。
d) 事务超时
如果一个事务长时间运行,这时为了尽量避免浪费系统资源,应为这个事务设置一个有效时间,使其等待数秒后自动回滚。与设
置“只读”属性一样,事务有效属性也需要给那些具有可能启动新事物的传播行为的方法的事务标记成只读才有意义。
3. 下面有关servlet和cgi的描述,说法错误的是?
A. servlet处于服务器进程中,它通过多线程方式运行其service方法
B. CGI对每个请求都产生新的进程,服务完成后就销毁
C. servlet在易用性上强于cgi,它提供了大量的实用工具例程,例如自动地解析和解码HTML表单数据、读取和设置HTTP头、处理Cookie、跟踪会话状态等
D. cgi在移植性上高于servlet,几乎所有的主流服务器都直接或通过插件支持cgi
CGI(Common Gateway Interface),通用网关接口
通用网关接口,简称CGI,是一种根据请求信息动态产生回应内容的技术。通过CGI,Web 服务器可以将根据请求不同启动不同的外部程序,并将请求内容转发给该程序,在程序执行结束后,将执行结果作为回应返回给客户端。也就是说,对于每个请求,都要产生一个新的进程进行处理。因为每个进程都会占有很多服务器的资源和时间,这就导致服务器无法同时处理很多的并发请求。另外CGI程序都是与操作系统平台相关的,虽然在互联网爆发的初期,CGI为开发互联网应用做出了很大的贡献,但是随着技术的发展,开始逐渐衰落。
Servlet
Servlet最初是在1995年由James Gosling 提出的,因为使用该技术需要复杂的Web服务器支持,所以当时并没有得到重视,也就放弃了。后来随着Web应用复杂度的提升,并要求提供更高的并发处理能力,Servlet被重新捡起,并在Java平台上得到实现,现在提起Servlet,指的都是Java Servlet。Java Servlet要求必须运行在Web服务器当中,与Web服务器之间属于分工和互补关系。确切的说,在实际运行的时候Java Servlet与Web服务器会融为一体,如同一个程序一样运行在同一个Java虚拟机(JVM)当中。与CGI不同的是,Servlet对每个请求都是单独启动一个线程,而不是进程。这种处理方式大幅度地降低了系统里的进程数量,提高了系统的并发处理能力。另外因为Java Servlet是运行在虚拟机之上的,也就解决了跨平台问题。如果没有Servlet的出现,也就没有互联网的今天。
在Servlet出现之后,随着使用范围的扩大,人们发现了它的一个很大的一个弊端。那就是 为了能够输出HTML格式内容,需要编写大量重复代码,造成不必要的重复劳动。为了解决这个问题,基于Servlet技术产生了JavaServet Pages技术,也就是JSP。Servlet和JSP两者分工协作,Servlet侧重于解决运算和业务逻辑问题,JSP则侧重于解决展示问题。 Servlet与JSP一起为Web应用开发带来了巨大的贡献,后来出现的众多Java Web应用开发框架都是基于这两种技术的,更确切的说,都是基于Servlet技术的。
CGI和servlet 的总结与对比:
1. CGI: 主要用Perl、Shell Script或C编写
Servlet:用java语言编写
2. CGI:每个请求都会启动一个新的进程,每个进程只为一个客户所服务,导致服务器内存和cpu开销大。
Servlet:每个请求会产生新的线程,而不是进程,减少系统中进程数量,并发处理能力强。多个客户能在同一个进程中的同时得到服务。
3. CGI进程在服务完成后就被销毁,所以效率上低于servlet。
Servlet进程(实例)处于服务器进程中,只有在服务器被卸载时才会被卸载。
4. CGI是不可移植的,是运行于特定平台上的。
Servlet是可移植的,运行于JVM上的。
4.下面有关servlet service描述错误的是?
A.不管是post还是get方法提交过来的连接,都会在service中处理
B.doGet/doPost 则是在 javax.servlet.GenericServlet 中实现的
C.service()是在javax.servlet.Servlet接口中定义的
D.service判断请求类型,决定是调用doGet还是doPost方法
注意以下几点:1.service方法是在servlet生命周期中的服务期,默认在HttpServlet类中实现,根据HTTP请求方法(GET、POST等),将请求分发到doGet、doPost等方法实现。
2.GenericServlet 抽象类给出了设计servlet的一些骨架,定义了servlet生命周期还有一些得到名字、配置、初始化参数的方法,其设计的是和应用层协议无关的。doget/dopost与Http协议有关,是在 javax.servlet.http.HttpServlet 中实现的。
3.doGet和doPost方法在HttpServlet类中实现,GenericServlet中实现了service()
4.常说所有的请求都先由service方法处理,而javax.servlet.GenericServlet接口实现了javax.servlet.Servle接口,且javax.servlet.http.HttpServlet 是 javax.servlet.GenericServlet 的子类。只有最先定义好了的service方法才可以处理所有的请求在HttpServlet中,service判断请求时是get还是post,然后根据方式调用doXXXX()方法
[Servlet是线程不安全的,在Servlet类中可能会定义共享的类变量,这样在并发的多线程访问的情况下,不同的线程对成员变量的修改会引发错误。]
protected void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String method = req.getMethod();
if (method.equals(METHOD_GET)) {
long lastModified = getLastModified(req);
if (lastModified == -1) {
// servlet doesn't support if-modified-since, no reason
// to go through further expensive logic
doGet(req, resp);
} else {
long ifModifiedSince = req.getDateHeader(HEADER_IFMODSINCE);
if (ifModifiedSince < (lastModified / 1000 * 1000)) {
// If the servlet mod time is later, call doGet()
// Round down to the nearest second for a proper compare
// A ifModifiedSince of -1 will always be less
maybeSetLastModified(resp, lastModified);
doGet(req, resp);
} else {
resp.setStatus(HttpServletResponse.SC_NOT_MODIFIED);
}
}
} else if (method.equals(METHOD_HEAD)) {
long lastModified = getLastModified(req);
maybeSetLastModified(resp, lastModified);
doHead(req, resp);
} else if (method.equals(METHOD_POST)) {
doPost(req, resp);
} else if (method.equals(METHOD_PUT)) {
doPut(req, resp);
} else if (method.equals(METHOD_DELETE)) {
doDelete(req, resp);
} else if (method.equals(METHOD_OPTIONS)) {
doOptions(req,resp);
} else if (method.equals(METHOD_TRACE)) {
doTrace(req,resp);
} else {
//
// Note that this means NO servlet supports whatever
// method was requested, anywhere on this server.
//
String errMsg = lStrings.getString("http.method_not_implemented");
Object[] errArgs = new Object[1];
errArgs[0] = method;
errMsg = MessageFormat.format(errMsg, errArgs);
resp.sendError(HttpServletResponse.SC_NOT_IMPLEMENTED, errMsg);
}
}
5.下列有关Servlet的生命周期,说法不正确的是?
A.在创建自己的Servlet时候,应该在初始化方法init()方法中创建Servlet实例
B.在Servlet生命周期的服务阶段,执行service()方法,根据用户请求的方法,执行相应的doGet()或是doPost()方法
C.在销毁阶段,执行destroy()方法后会释放Servlet 占用的资源
D.destroy()方法仅执行一次,即在服务器停止且卸载Servlet时执行该方法
Servlet的生命周期
1.加载:容器通过类加载器使用Servlet类对应的文件来加载Servlet
2.创建:通过调用Servlet的构造函数来创建一个Servlet实例-------仅调用一次
3.初始化:通过调用Servlet的init()方法来完成初始化工作,这个方法是在Servlet已经被创建,但在向客户端提供服务之前调用。-------仅调用一次
4.处理客户请求:Servlet创建后就可以处理请求,当有新的客户端请求时,Web容器都会创建一个新的线程来处理该请求。接着调用Servlet的Service()方法来响应客户端请求(Service方法会根据请求的method属性来调用doGet()和doPost())------调用n次
5.卸载:容器在卸载Servlet之前需要调用destroy()方法,让Servlet释放其占用的资源----只调用一次
6.下面有关struts1和struts2的区别,描述错误的是?
A.Struts1要求Action类继承一个抽象基类。Struts 2 Action类可以实现一个Action接口
B.Struts1 Action对象为每一个请求产生一个实例。Struts2 Action是单例模式并且必须是线程安全的
C.Struts1 Action 依赖于Servlet API,Struts 2 Action不依赖于容器,允许Action脱离容器单独被测试
D.Struts1 整合了JSTL,Struts2可以使用JSTL,但是也支持OGNL
整理一下:
特 点 |
struts1 |
struts2 |
Action 类分析 |
Struts1 要求 Action 类继承一个抽象基类 而不是使用接口; |
Struts2 的 Action 类可以实现一个 Action 接口,也可以实现其他接口。 使可选和定制的服务成为可能。Struts2提供一个ActionSupport基类去实现常用的接口。Action接口不是必须的,任何有execute标识的POJO对象都可以用作Struts2的Action对象。 |
Servlet 依赖分析 |
Struts1 Action 依赖于Servlet API ,因为当一个Action被调用时HttpServletRequest 和 HttpServletResponse 被传递给execute方法。 |
Struts 2 Action不依赖于容器,允许Action脱离容器单独被测试。如果需要,Struts2 Action仍然可以访问初始的request和response。但是,其他的元素减少或者消除了直接访问HttpServetRequest 和 HttpServletResponse的必要性。 |
实例模式 |
Struts1 Action是单例模式并且必须是线程安全的,因为仅有Action的一个实例来处理所有的请求。单例策略限制了Struts1 Action能作的事,并且要在开发时特别小心。Action资源必须是线程安全的或同步的。 |
Struts2 Action对象为每一个请求产生一个实例,因此没有线程安全问题。(实际上,servlet容器给每个请求产生许多可丢弃的对象,并且不会导致性能和垃圾回收问题) |
表达式语言 |
Struts1 整合了 JSTL ,因此使用 JSTL EL 。这种 EL 有基本对象图遍历,但是对集合和索引属性的支持很弱。 |
Struts2 可以使用 JSTL ,但是也支持一个更强大和灵活的表达式语言-- "Object Graph Notation Language" ( OGNL ). |
捕获输入 |
Struts1 使用 ActionForm 对象捕获输入 。所有的 ActionForm 必须继承一个基类。因为其他 JavaBean 不能用作 ActionForm ,开发者经常创建多余的类捕获输入。动态 Bean ( DynaBeans )可以作为创建传统 ActionForm 的选择,但是,开发者可能是在重新描述 ( 创建 ) 已经存 在的 JavaBean (仍然会导致有冗余的 javabean )。 |
Struts 2 直接使用 Action 属性作为输入属性,消除了对第二个输入对象的需求。 输入属性可能是有自己 ( 子 ) 属性的 rich 对象类型。 Action 属性能够通过 web 页面上的 taglibs 访问。 Struts2 也支持 ActionForm 模式。 rich 对象类型,包括业务对象,能够用作输入 / 输出对象。这种 ModelDriven 特性简化了 taglib 对 POJO 输入对象的引用。 |
可测性 |
测试 Struts1 Action 的一个主要问题是 execute 方法暴露了 servlet API (这使得测试要依赖于容器) 。一个第三方扩展-- Struts TestCase --提供了一套 Struts1 的模拟对象(来进行测试)。 |
Struts 2 Action 可以通过初始化、设置属性、调用方法来测试,“依赖注入”支持也使测试更容易。 |
A.Swing是AWT的子类
B.AWT在不同操作系统中显示相同的风格
C.AWT不支持事件类型,Swing支持事件模型
D.Swing在不同的操作系统中显示相同的风格
AWT和Swing都是java中的包。
AWT(Abstract Window Toolkit):抽象窗口工具包,早期编写图形界面应用程序的包。
Swing :为解决 AWT 存在的问题而新开发的图形界面包。Swing是对AWT的改良和扩展。
AWT和Swing的实现原理不同:
AWT :是通过调用操作系统的native方法实现的,所以在Windows系统上的AWT窗口就是Windows的风格,而在Unix系统上的则是XWindow风格。 AWT 中的图形函数与 操作系统 所提供的图形函数之间有着一一对应的关系,我们把它称为peers。 也就是说,当我们利用 AWT 来构件图形用户界面的时候,我们实际上是在利用 操作系统 所提供的图形库。由于不同 操作系统 的图形库所提供的功能是不一样的,在一个平台上存在的功能在另外一个平台上则可能不存在。为了实现Java语言所宣称的"一次编译,到处运行"的概念,AWT 不得不通过牺牲功能来实现其平台无关性,也就是说,AWT 所提供的图形功能是各种通用型操作系统所提供的图形功能的交集。由于AWT 是依靠本地方法来实现其功能的,我们通常把AWT控件称为重量级控件。
Swing :是所谓的Lightweight组件,不是通过native方法来实现的,所以Swing的窗口风格更多样化。但是,Swing里面也有heaveyweight组件。比如JWindow,Dialog,JFrame。Swing由纯Java写成,可移植性好,外观在不同平台上相同。所以Swing部件称为轻量级组件( Swing是由纯JAVA CODE所写的,因此SWING解决了JAVA因窗口类而无法跨平台的问题,使窗口功能也具有跨平台与延展性的特性,而且SWING不需占有太多系统资源,因此称为轻量级组件!!!)
AWT和Swing之间的区别:
1)AWT 是基于本地方法的C/C++程序,其运行速度比较快;Swing是基于AWT的Java程序,其运行速度比较慢。
2)AWT的控件在不同的平台可能表现不同,而Swing在所有平台表现一致。
在实际应用中,应该使用AWT还是Swing取决于应用程序所部署的平台类型。例如:
1)对于一个嵌入式应用,目标平台的硬件资源往往非常有限,而应用程序的运行速度又是项目中至关重要的因素。在这种矛盾的情况下,简单而高效的AWT当然成了嵌入式Java的第一选择。
2)在普通的基于PC或者是工作站的标准Java应用中,硬件资源对应用程序所造成的限制往往不是项目中的关键因素。所以在标准版的Java中则提倡使用Swing, 也就是通过牺牲速度来实现应用程序的功能。
8.下面哪一项不是加载驱动程序的方法?
A.通过DriverManager.getConnection方法加载
B.调用方法 Class.forName
C.通过添加系统的jdbc.drivers属性
D.通过registerDriver方法注册
JDBC流程:
加载驱动 DriverManager. registerDriver(Driver driver)
获取连接 Connection conn = DriverManager.getConnection(url,user,pass);
通过连接创建statement Statement st = conn.createStatement();
解析sql获取结果集 ResultSet rs = st.excuteQuery(sql);
遍历结果集,获得数据 rs.getobject(xx)
释放资源,关闭连接
3.System.setProperty("jdbc.drivers", "com.mysql.jdbc.Driver");
9.关于sleep()和wait(),以下描述错误的一项是( )
A.sleep是线程类(Thread)的方法,wait是Object类的方法;
B.sleep不释放对象锁,wait放弃对象锁
C.sleep暂停线程、但监控状态仍然保持,结束后会自动恢复
D.wait后进入等待锁定池,只有针对此对象发出notify方法后获得对象锁进入运行状态
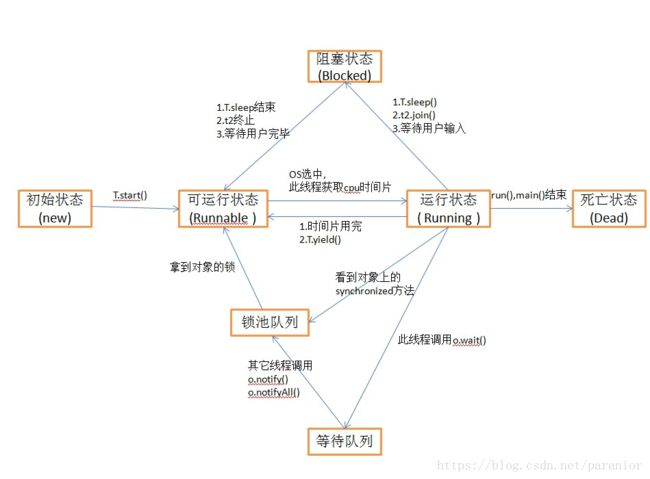
首先,sleep()是Thread类中的方法,而wait()则是Object类中的方法。
sleep()方法导致了程序暂停,但是他的监控状态依然保持着,当指定的时间到了又会自动恢复运行状态。在调用sleep()方法的过程中,线程不会释放对象锁。
wait()方法会导致线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备获取对象锁进入可运行状态。
注意是准备获取对象锁进入可运行状态,而不是运行状态。
10.在jdk1.5的环境下,有如下4条语句:
|
1
2
3
4
|
Integer i01 = 59;
int i02 = 59;
Integer i03 =Integer.valueOf(59);
Integer i04 = new Integer(59)。
|
A.System.out.println(i01== i02);
B.System.out.println(i01== i03);
C.System.out.println(i03== i04);
D.System.out.println(i02== i04);
Integer i01=59 的时候,会调用 Integer 的 valueOf 方法,
|
1
2
3
4
5
|
public
static
Integer valueOf(
int
i) {
assert
IntegerCache.high>=
127
;
if
(i >= IntegerCache.low&& i <= IntegerCache.high)
return
IntegerCache.cache[i+ (-IntegerCache.low)];
return
new
Integer(i); }
|
这个方法就是返回一个 Integer 对象,只是在返回之前,看作了一个判断,判断当前 i 的值是否在 [-128,127] 区别,且 IntegerCache 中是否存在此对象,如果存在,则直接返回引用,否则,创建一个新的对象。
在这里的话,因为程序初次运行,没有 59 ,所以,直接创建了一个新的对象。
int i02=59 ,这是一个基本类型,存储在栈中。
Integer i03 =Integer.valueOf(59); 因为 IntegerCache 中已经存在此对象,所以,直接返回引用。
Integer i04 = new Integer(59) ;直接创建一个新的对象。
System. out .println(i01== i02); i01 是 Integer 对象, i02 是 int ,这里比较的不是地址,而是值。 Integer 会自动拆箱成 int ,然后进行值的比较。所以,为真。
System. out .println(i01== i03); 因为 i03 返回的是 i01 的引用,所以,为真。
System. out .println(i03==i04); 因为 i04 是重新创建的对象,所以 i03,i04 是指向不同的对象,因此比较结果为假。
System. out .println(i02== i04); 因为 i02 是基本类型,所以此时 i04 会自动拆箱,进行值比较,所以,结果为真。
11.下面哪个不对?A. RuntimeException is the superclass of those exceptions that can be thrown during the normal operation of the Java Virtual Machine.
B. A method is not required to declare in its throws clause any subclasses of RuntimeExeption that might be thrown during the execution of the method but not caught
C. An RuntimeException is a subclass of Throwable that indicates serious problems that a reasonable application should not try to catch.
D. NullPointerException is one kind of RuntimeException
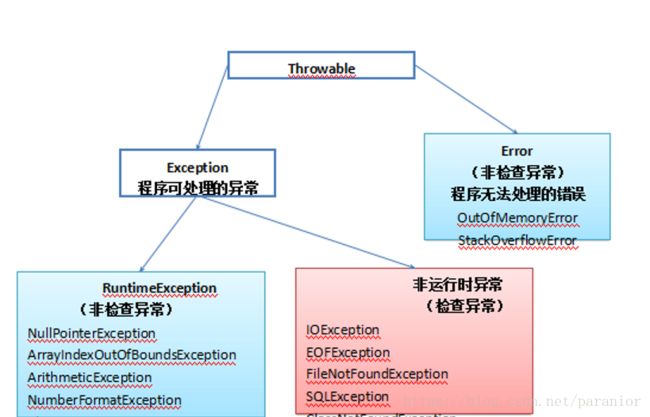
runtimeException是运行时的异常,在运行期间抛出异常的超类,程序可以选择是否try-catch处理。
其他的检查性异常(非运行时的异常,如IOException),是必须try-catch的,否则程序在编译的时候就会发现错误。
[1、java中所有的异常的超类为Throwable(可抛出的,看起来像个接口,实际上是个类),Exception继承Throwable
2、java中的异常分为编译时异常与运行时异常,编译时异常直接继承Exception类,编译时异常要求程序员必须在编写时对其进行处理,否则编译无法通过,或try catch或throw;运行时异常,继承于RuntimeException类(Exception的一个子类),在编写代码阶段不对其处理也可以通过编译]
12.关于struts项目中的类与MVC模式的对应关系,说法错误的是
A.Jsp文件实现视图View的功能
B.ActionServlet这一个类是整个struts项目的控制器
C.ActionForm、Action都属于Model部分
D.一个struts项目只能有一个Servlet
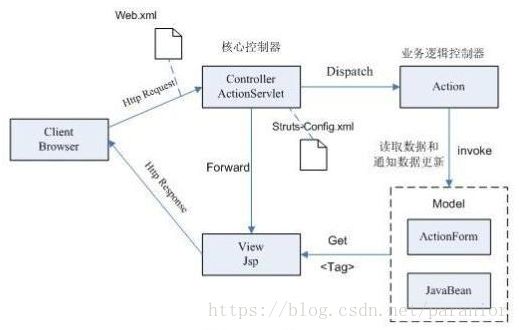
Struts工作原理
MVC即Model-View-Controller的缩写,是一种常用的设计模式。MVC 减弱了业务逻辑接口和数据接口之间的耦合,以及让视图层更富于变化。
Struts 是MVC的一种实现,它将 Servlet和 JSP 标记(属于 J2EE 规范)用作实现的一部分。Struts继承了MVC的各项特性,并根据J2EE的特点,做了相应的变化与扩展。
控 制:有一个XML文件Struts-config.xml,与之相关联的是Controller,在Struts中,承担MVC中Controller角 色的是一个Servlet,叫ActionServlet。ActionServlet是一个通用的控制组件。这个控制组件提供了处理所有发送到 Struts的HTTP请求的入口点。它截取和分发这些请求到相应的动作类(这些动作类都是Action类的子类)。另外控制组件也负责用相应的请求参数 填充 Action From(通常称之为FromBean),并传给动作类(通常称之为ActionBean)。动作类实现核心商业逻辑,它可以访问java bean 或调用EJB。最后动作类把控制权传给后续的JSP 文件,后者生成视图。所有这些控制逻辑利用Struts-config.xml文件来配置。
视图:主要由JSP生成页面完成视图,Struts提供丰富的JSP 标签库: Html,Bean,Logic,Template等,这有利于分开表现逻辑和程序逻辑。
模 型:模型以一个或多个java bean的形式存在。这些bean分为三类:Action Form、Action、JavaBean or EJB。Action Form通常称之为FormBean,封装了来自于Client的用户请求信息,如表单信息。Action通常称之为ActionBean,获取从 ActionSevlet传来的FormBean,取出FormBean中的相关信息,并做出相关的处理,一般是调用Java Bean或EJB等。
流程:在Struts中,用户的请求一般以*.do作为请求服务名,所有的*.do请求均被指向 ActionSevlet,ActionSevlet根据Struts-config.xml中的配置信息,将用户请求封装成一个指定名称的 FormBean,并将此FormBean传至指定名称的ActionBean,由ActionBean完成相应的业务操作,如文件操作,数据库操作等。 每一个*.do均有对应的FormBean名称和ActionBean名称,这些在Struts-config.xml中配置。
核心:Struts的核心是ActionSevlet,ActionSevlet的核心是Struts-config.xml。
13.对于JVM内存配置参数:
-Xmx10240m -Xms10240m -Xmn5120m -XXSurvivorRatio=3,其最小内存值和Survivor区总大小分别是()
A.5120m,1024m
B.5120m,2048m
C.10240m,1024m
D.10240m,2048m

首先必须知道几个参数的含义:
-Xmx :堆的最大值-Xms :堆的最小值
-Xmn :堆年轻代大小
-XXSurvivorRatio:Eden区和Survior区的占用比例.
知识补充:
VM内存区域总体分两类,heap区 和 非heap 区 。
- heap区: 堆区分为Young Gen(新生代),Tenured Gen(老年代-养老区)。其中新生代又分为Eden Space(伊甸园)、Survivor Space(幸存者区)。
- 非heap区: Code Cache(代码缓存区)、Perm Gen(永久代)、Jvm Stack(java虚拟机栈)、Local Method Statck(本地方法栈)。
为什么要区分新生代和老生代?
堆中区分的新生代和老年代是为了垃圾回收,新生代中的对象存活期一般不长,而老年代中的对象存活期较长,所以当垃圾回收器回收内存时,新生代中垃圾回收效果较好,会回收大量的内存,而老年代中回收效果较差,内存回收不会太多。
不同代采用的算法区别?
基于以上特性,新生代中一般采用复制算法,因为存活下来的对象是少数,所需要复制的对象少,而老年代对象存活多,不适合采用复制算法,一般是标记整理和标记清除算法。
因为复制算法需要留出一块单独的内存空间来以备垃圾回收时复制对象使用,所以将新生代分为eden区和两个survivor区,每次使用eden和一个survivor区,另一个survivor作为备用的对象复制内存区。
上面铺垫了那么多,现在进入正题:我们只需要知道Survior区有两个,就是图中的S0和S1,而Eden区只用一个, -XXSurvivorRatio参数是Eden区和单个Survior区的比例,所以应该有(3+1+1)*Survior=5012m,图中问的是Survior总大小(需乘2),显然是d.
14.看以下代码: 文件名称:forward.jsp
|
1
2
3
4
5
6
|
<html>
<head><title> 跳转
<body>
<jsp:forward page="index.htm"/>
|
A.http://127.0.0.1:8080/myjsp/forward.jsp
B.http://127.0.0.1:8080/myjsp/index.jsp
C.http://127.0.0.1:8080/myjsp/index.htm
D.http://127.0.0.1:8080/myjsp/forward.htm
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
1. public class HasStatic{
2. private static int x=100;
3. public static void main(String args[]){
4. HasStatic hs1=new HasStatic();
5. hs1.x++;
6. HasStatic hs2=new HasStatic();
7. hs2.x++;
8. hs1=new HasStatic();
9. hs1.x++;
10. HasStatic.x--;
11. System.out.println("x="+x);
12. }
13. }
|
A.程序通过编译,输出结果为:x=103
B.10行不能通过编译,因为x是私有静态变量
C.5行不能通过编译,因为引用了私有静态变量
D.程序通过编译,输出结果为:x=102
首先要了解static的意思。
static表示“全局”或者“静态”的意思,用来修饰成员变量和成员方法,也可以形成静态static代码块,但是Java语言中没有全局变量的概念。(main是HasStatic的静态方法,在其内部可直接访问静态变量,不存在因为私有变量不能通过编译的问题;如果在其他类中,包括HasStatic的派生类中,均不能访问其私有静态变量)
static变量在第一次使用的时候初始化,但只会有一份成员对象。
所以这里不仅可以调用,而且每一次调用都确实修改了x的值,也就是变化情况是这样的:
x=101
x=102
x=103
x=102
A.动态INCLUDE:用jsp:include动作实现
B.静态INCLUDE:用include伪码实现,定不会检查所含文件的变化,适用于包含静态页面<%@ include file="included.htm" %>
C.静态include的结果是把其他jsp引入当前jsp,两者合为一体;动态include的结构是两者独立,直到输出时才合并
D.静态include和动态include都可以允许变量同名的冲突.页面设置也可以借用主文件的
动态 INCLUDE 用 jsp:include 动作实现
静态 INCLUDE 用 include 伪码实现 , 定不会检查所含文件的变化 , 适用于包含静态页面 <%@ include file="included.htm" %> 。先将文件的代码被原封不动地加入到了主页面从而合成一个文件,然后再进行翻译,此时不允许有相同的变量。
以下是对 include 两种用法的区别 , 主要有两个方面的不同 ;
一 : 执行时间上 :
<%@ include file="relativeURI"%> 是在翻译阶段执行
二 : 引入内容的不同 :
<%@ include file="relativeURI"%>
引入静态文本 (html,jsp), 在 JSP 页面被转化成 servlet 之前和它融和到一起 .
***rnd()用作生成随机数
Math.ceil()用作向上取整
Math.floor()用作向下取整
Math.round() 用作四舍五入取整