对话系统Deep Learning lab-5 餐厅例子解析-配置文件gobot_dstc2.json
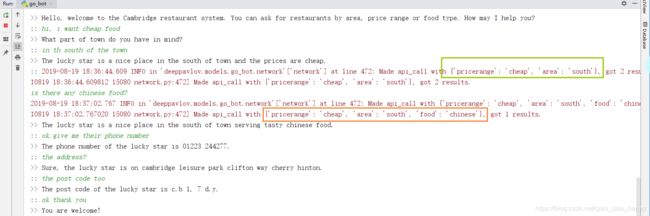
运行示例(命令行+python运行)
- 在命令行环境下的应用
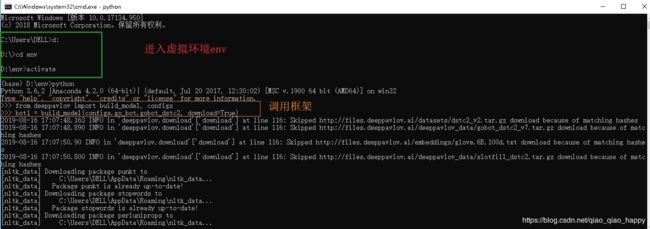

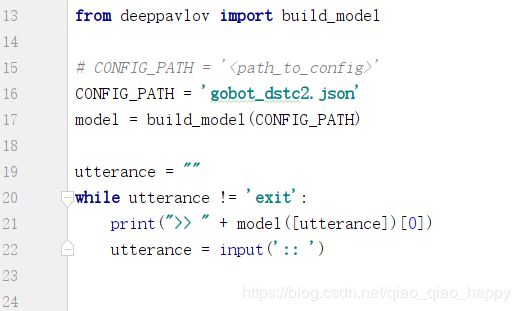
- 在pycharm中的运行代码,只有下列几行
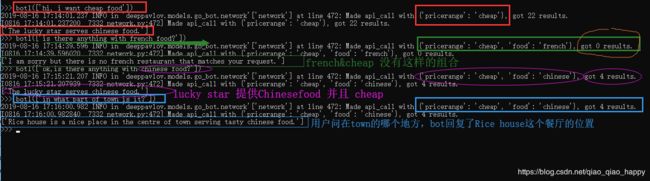
首先寻找cheap +south+chinese food ,并获取其phone number+ address + post code
然后寻找French food ,系统自动认为在原来的条件上,结合 cheap + french + north/south/east/west ,都got 0 results。
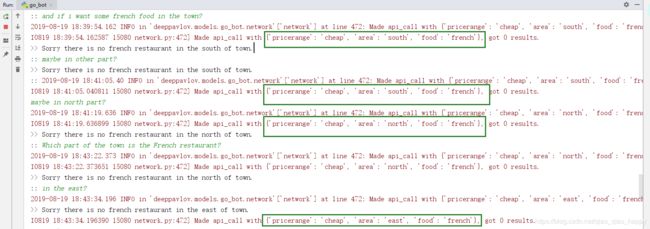
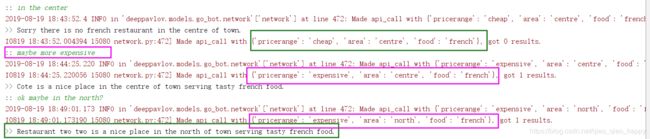
可能是因为价格的限制,于是调整为 expensive+french + centre/north ,都有相应的results。
代码解析
餐厅对话机器人基于Jason d. Williams,Kavosh Asadi,Geoffrey Zweig 提出的混合代码网络(Hybrid Code Networks,HCNs)架构,混合代码网络: 实用且高效的端到端对话控制,带有监督和强化学习-2017 这篇论文,引入了混合编码网络(hcn) ,该混合编码网络将 RNN 与特定领域的知识和系统动作模板相结合。
虚线对应可选模块,黑色方块对应训练模型,平行四边形是依赖于数据集的模块,必须由软件开发人员提供。

Embedder词嵌入模型(fasttext、word2vec、glove等)词句嵌入技术概览
fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。
fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
word2vec模型就是一个小型的神经网络。目前流行的有以下两种模型:如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』;如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』
GloVe的全称叫Global Vectors for Word Representation,称为全局词向量,是与word2vec相似的一种词向量表达。训练词向量的方法的核心思想是首先基于语料库构建词的共现矩阵,然后基于’词-词’共现矩阵和GloVe模型学习词向量。
Bags of words Embedder 词袋模型。
词袋模型是最基础的文本表示模型,就是把每一篇文章看成一袋子单词,并忽略每个词出现的顺序。具体就是将整段文本以词为单位分开,每篇文章可以表示成一个长向量,向量中的每一维代表一个单词,而该维对应的权重代表这个词在文章中的重要程度
go_bot模型注释:
The network handles dialogue policy management. 网络处理对话策略管理
Inputs features of an utterance and predicts label of a bot action(classification task).
一句话的输入特征并预测机器人动作的标签(分类任务)。
An LSTM with a dense layer for input features and a dense layer for it’s output.
具有用于输入特性的密集层和用于输出特性的密集层的LSTM。
Softmax is used as an output activation function.
Softmax被用作一个输出激活函数。
Todo:
为跟踪器添加docstring。
add docstring for trackers.
# DocStrings 文档字符串用于解释文档程序
DeepPavlov通过Json配置文件实现开发流程控制和数据流pipeline的控制。
model = build_model(CONFIG_PATH) 构建并返回配置文件gobot_dstc2.json中描述的模型model,
其中build_model方法定义为:
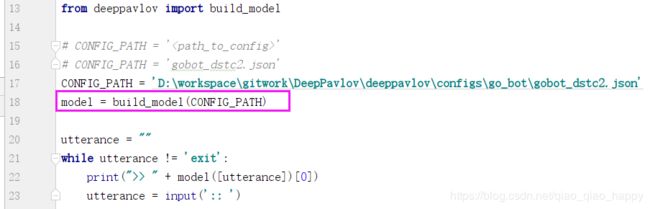

其中应用到的配置文件为gobot_dstc2.json,下面来分析这个配置文件。
用于训练管道的配置应该有
chainer
+dataset_reader数据集读取器、dataset_iterator 数据集迭代器和train训练器
+metadata
{
"dataset_reader": {
"class_name": ...,
...
},
"dataset_iterator": {
"class_name": ...,
...
},
"chainer": {
...
},
"train": {
...
}
"metadata": {
...
}
}
整体包括以下五部分

dataset_reader类 数据读取
主要负责数据读取
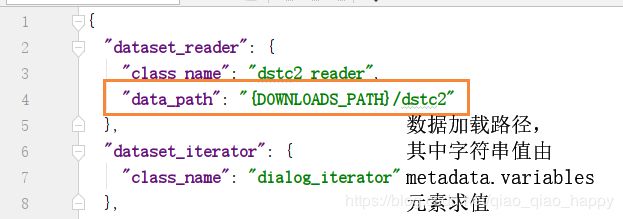
dstc2_reader类
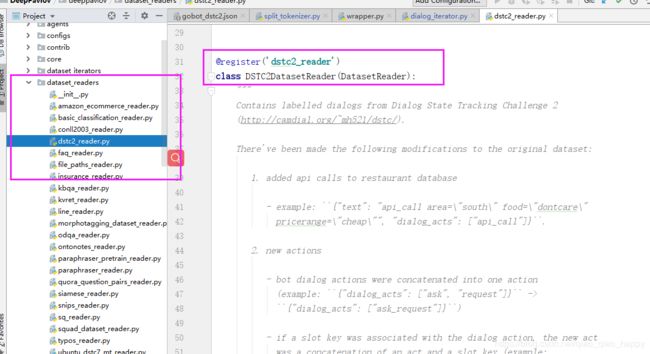
注意,因为在配置文件中的每个字符串值都被解释为格式字符串,其中字段由metadata.variables元素求值。

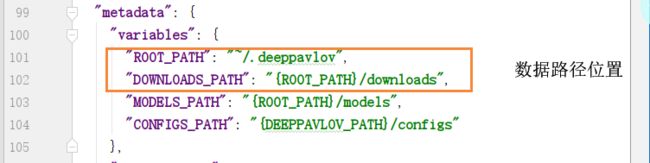
所以,根据上述路径,我的数据加载地址在
C:\Users\DELL.deeppavlov\downloads\dstc2
大概有这样一些数据
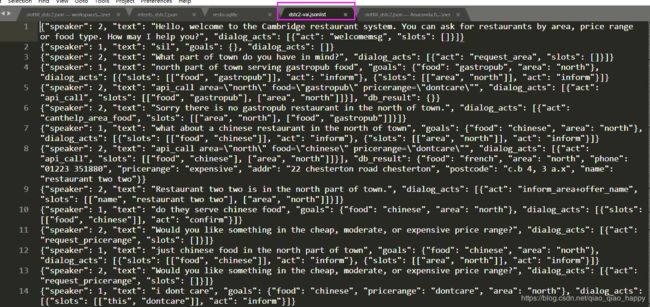
dialog_iterator类 数据迭代
数据迭代器,从dataset_reader中获得数据,然后按batch抽取数据,供后面的模型训练使用。
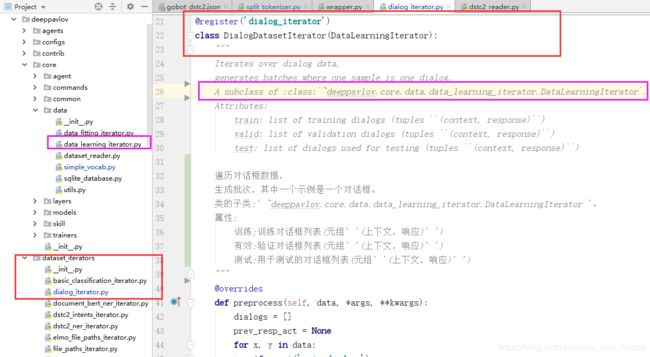
chainer
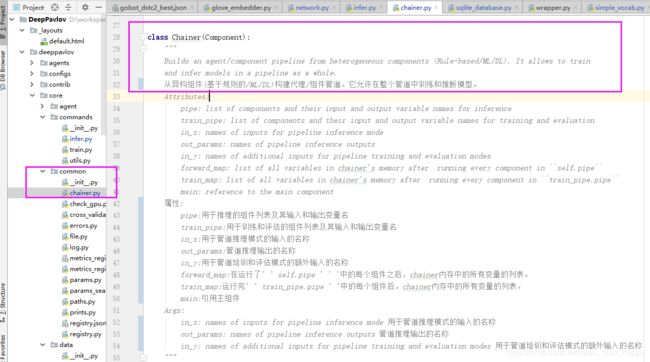
chainer是配置文件的核心,将数据预处理、模型选优和模型预测输出,通过pipeline(”pipe”字段内进行约束)的形式串联起来。
(这里我用了之前的旧图,是在gobot_dstc2_minimal.json中标注的,本篇文章分析的是gobot_dstc2,只在这里不同,就是save_path和load_path这里)

上面的几个路径中 word.dict,model也在我的c盘相应文件夹中
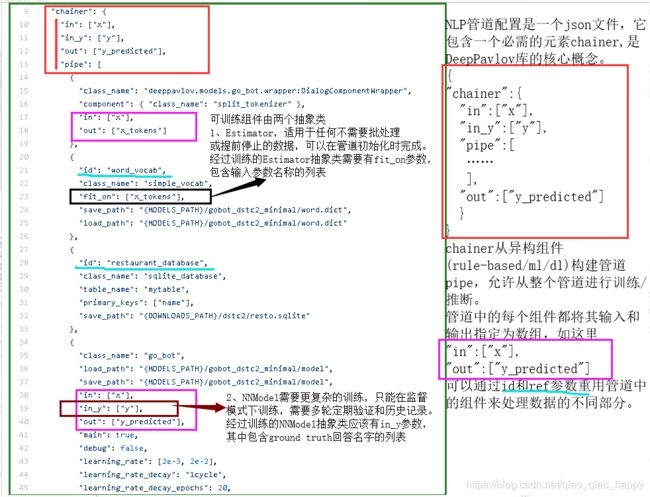
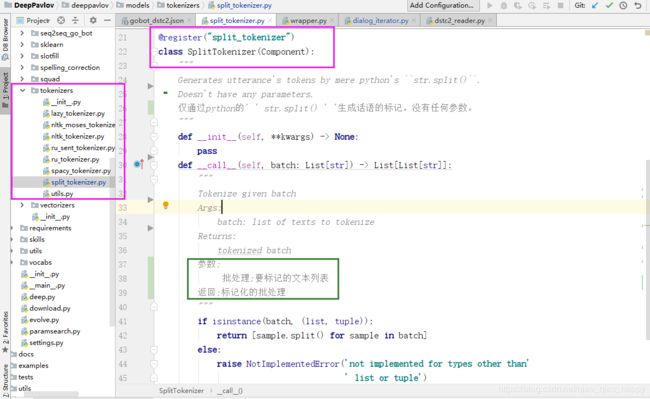
chainer-pipe中第一个类split_tokenizer 标记批处理
split_tokenizer类使用字符串方法spite进行标记,输入是x,输出是x_tokens(标记后的结果)。
{
"class_name": "deeppavlov.models.go_bot.wrapper:DialogComponentWrapper",
"component": { "class_name": "split_tokenizer" },
"in": ["x"],
"out": ["x_tokens"]
},
Tokenizer 是一个处理批处理样本的组件(每个样本都是一个文本字符串)

chainer-pipe中第二个类 simple_vocab 实现简单词汇表
**simple_vocab类实现简单词汇表,输入参数是x_tokens(split_tokenizer类标记批处理的结果),并且通过 “id” :“word_vocab” 参数标记,用于后面go_bot类的使用(见下图go_bot类中 “word_vocab”: “#word_vocab”)。
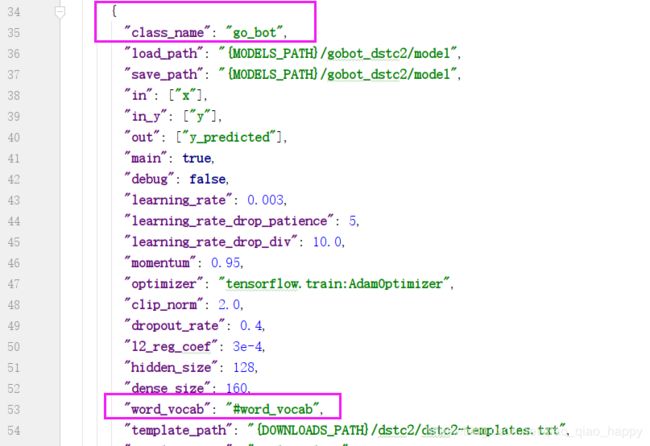
{
"id": "word_vocab",
"class_name": "simple_vocab",
"fit_on": ["x_tokens"],
"save_path": "{MODELS_PATH}/gobot_dstc2/word.dict",
"load_path": "{MODELS_PATH}/gobot_dstc2/word.dict"
},

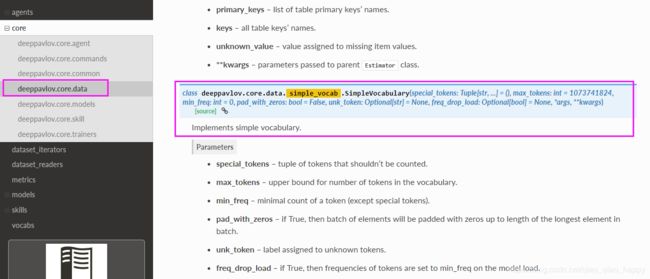

simple_vocab类属于可训练组件中的抽象类Estimator,有fit_on参数,输入参数名称为x_tokens(split_tokenizer类进行标记批处理后的结果);
(可训练组件中有两个类。其中一个是抽象类Estimator,适用于任何不需要批处理或者提前停止的数据,可以在管道初始化时完成,经过训练的Estimator类有fit_on参数,包含输入参数名称的列表)
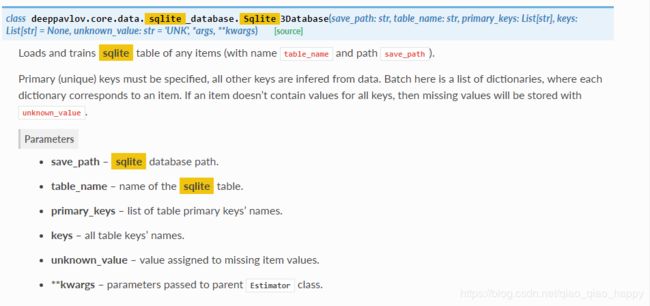
chainer-pipe中第三个类 sqlite_database 数据库表
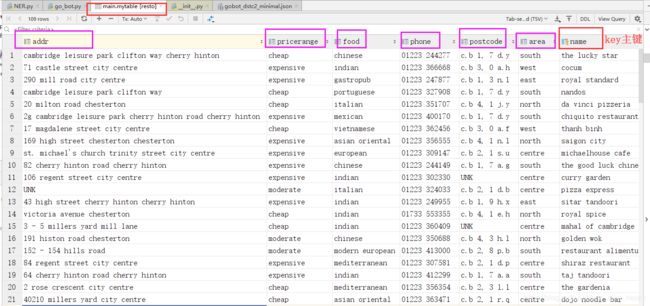
**sqlite_database类,加载数据库表,表名为mytable,主键是name
通过"id" :"restaurant_database"参数标记,用于后面go_bot类的使用(go_bot类中 “database”: “#restaurant_database”,)。

数据库本地存储路径如图:

查看resto.sqlite的数据库存储内容:
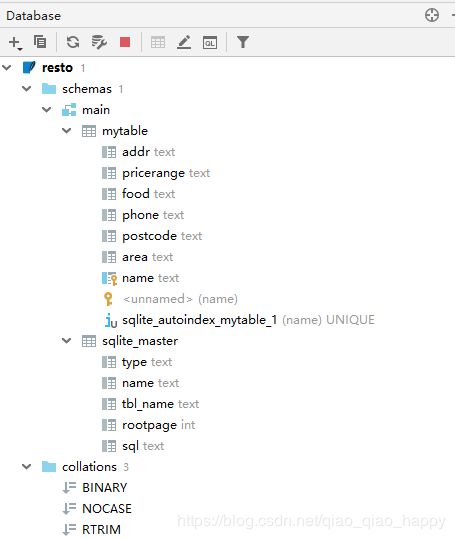
在main.mytable表中存储了109条restaurant信息,包括addr,pricerange,food,phone,postcode,area,name七项,以name为主键

chainer-pipe中第四个类 go_bot bot模型
go_bot类,输入参数是x,输出参数是y_predicted,是NNmodel类,包含 “in_y”: [“y”]参数。
可训练组件中有两个类。其中一个是上文中提到的抽象类Estimator,另一个是NNModel ,其需要更复杂的训练。 它只能在监督模式下训练(相对于Estimator,Estimator可以在监督和非监督模式下训练)。 这个过程需要多轮的定期验证和日志记录。
必须为每个 NNModel 实现train_on_batch()方法。 NNModel 抽象类应该有 in_y 参数,其中包含ground truth-真值列表( ground truth在文献中翻译的意思是地面实况,放到机器学习里面,再抽象点可以把它理解为真值、真实的有效值或者是标准的答案)
在本餐厅例中 “in_y”: [“y”]就是真实的查找结果,用于对比"out": [“y_predicted”]的预测值。
{
"class_name": "go_bot",
"load_path": "{MODELS_PATH}/gobot_dstc2/model",
"save_path": "{MODELS_PATH}/gobot_dstc2/model",
"in": ["x"],
"in_y": ["y"],
"out": ["y_predicted"],
"main": true,
"debug": false,
"learning_rate": 0.003,
"learning_rate_drop_patience": 5,
"learning_rate_drop_div": 10.0,
"momentum": 0.95,
"optimizer": "tensorflow.train:AdamOptimizer",
"clip_norm": 2.0,
"dropout_rate": 0.4,
"l2_reg_coef": 3e-4,
"hidden_size": 128,
"dense_size": 160,
"word_vocab": "#word_vocab",
"template_path": "{DOWNLOADS_PATH}/dstc2/dstc2-templates.txt",
"template_type": "DualTemplate",
"database": "#restaurant_database",
"api_call_action": "api_call",
"use_action_mask": false,
"slot_filler": {
"config_path": "{CONFIGS_PATH}/ner/slotfill_dstc2.json"
},
"intent_classifier": null,
"embedder": {
"class_name": "glove",
"load_path": "{DOWNLOADS_PATH}/embeddings/glove.6B.100d.txt"
},
"bow_embedder": {
"class_name": "bow",
"depth": "#word_vocab.__len__()",
"with_counts": true
},
"tokenizer": {
"class_name": "stream_spacy_tokenizer",
"lowercase": false
},
"tracker": {
"class_name": "featurized_tracker",
"slot_names": ["pricerange", "this", "area", "food", "name"]
}
}

go_bot类是一个bot模型类。
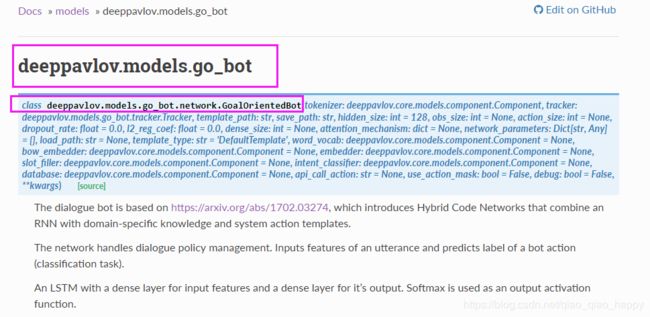
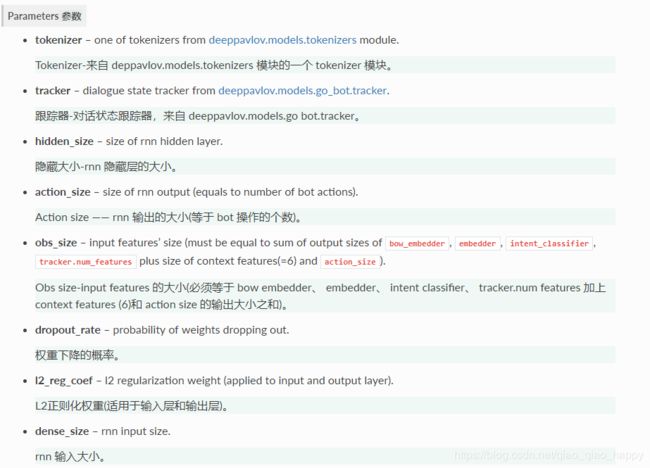
其参数主要有:
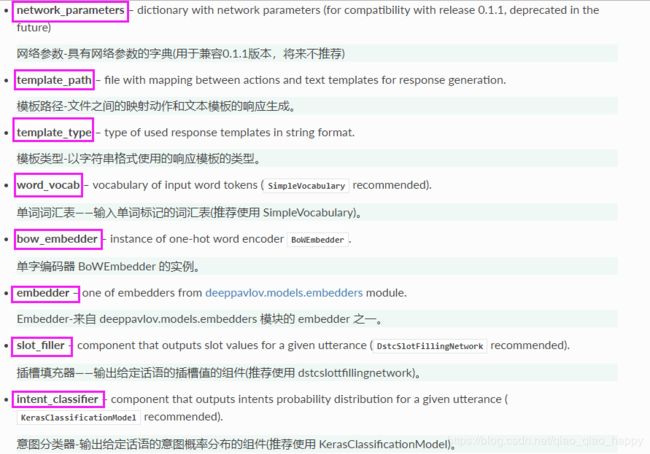

go_bot类定义在models-go_bot-network.py中
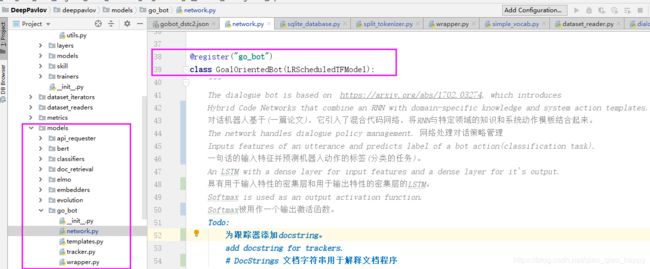
参数—模板路径 “template_path”: “{DOWNLOADS_PATH}/dstc2/dstc2-templates.txt”,
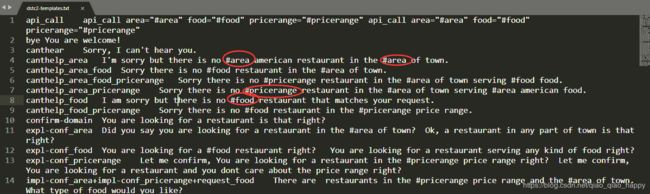
找到本地存储,template大致如下,模板中填充的插槽以#开头
根据其他参数,go_bot类使用前面介绍的restaurant_database数据库,不区分intent意图,slot包括有 “slot_names”: [“pricerange”, “this”, “area”, “food”, “name”]这五项。

词嵌入模型Embedder
通过GloveEmbedder为每个样本返回一个向量,通过BowEmbedder使用预构建词汇表(word_vocab)对标记进行one-hot编码

使用Stream_spacy_tokenzier进行文本分类标记

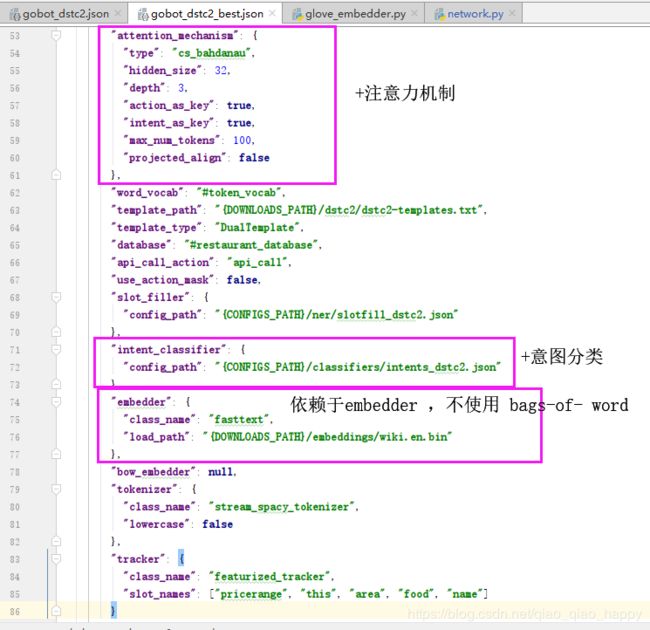
上面解析的是gobot_dstc2.json,而gobot_dstc2_best.json配置中chainer部分只有在一些训练数据的设定值上有所不同,以及具有attention注意力机制和intent意图检测,依赖于Embedder而不使用bags-of-words词袋模型。
词袋模型忽略掉文本的语法和语序等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的。词袋模型是最基础的文本表示模型,就是把每一篇文章看成一袋子单词,并忽略每个词出现的顺序。具体就是将整段文本以词为单位分开,每篇文章可以表示成一个长向量,向量中的每一维代表一个单词,而该维对应的权重代表这个词在文章中的重要程度

Train
模型训练、模型选优和评测配置。其中,“metric”字段中排在最前面的指标,作为模型选优的标准,衡量标准。


metadata
相关的常量配置

DeepPavlov模型配置
Each DeepPavlov model is determined by its configuration file. You can use existing config files or create yours. You can also choose a config file and modify preprocessors/tokenizers/embedders/vectorizers there. The components below have the same interface and are responsible for the same functions, therefore they can be used in the same parts of a config pipeline.
每个 DeepPavlov 模型由其配置文件确定。 可以使用现有的配置文件或者创建你的配置文件。 还可以选择一个配置文件,并在该文件中修改preprocessors/tokenizers/embedders/vectorizers (预处理器 / 标记器 / 嵌入器 / 向量器)。
参见另一篇