1.为什么写?
网上教程一抓一大把,有的能重复,有的不能重复不了,很多原因。别人能做的不代表你能复制,实践出真知。
不做搬运工,只写有用的,防止以后忘记。每个人理解不同,记录下来,供自己今后参考,顺便分享他人。
2.GSEA基本概念
Gene Set Enrichment Analysis
思路:
使用预定义的基因集(通常来自功能注释或先前实验的结果),将基因按照在两类样本中的差异表达程度排序,然后检验预先设定的基因集合是否在这个排序表的顶端或者底端富集。
基因集富集分析检测基因集合而不是单个基因的表达变化,因此可以包含这些细微的表达变化,预期得到更为理想的结果。
比较GO/KEGG等富集分析:
GO/KEGG差异基因的一刀切法——仅关注少数几个显著上调或下调的基因,容易遗漏部分差异表达不显著却有重要生物学意义的基因,忽略一些基因的生物特性、基因调控网络之间的关系及基因功能和意义等有价值的信息。
GSEA不需要指定明确的差异基因阈值,算法根据实际整体趋势分析。
3.MSigDB数据库
http://software.broadinstitute.org/gsea/msigdb
定义了已知基因集,包括H和C1-C7八个系列(Collection/cluster),每个系列内容为:
H: hallmark gene sets (效应)特征基因集合,共50组;
C1: positional gene sets 位置基因集合,根据染色体位置,共326个;
C2: curated gene sets:(专家)共识基因集合,基于通路、文献等(包括KEGG);
C3: motif gene sets:模式基因集合,主要包括microRNA和转录因子靶基因两部分;
C4: computational gene sets:计算基因集合,通过挖掘癌症相关芯片数据定义的基因集合;
C5: GO gene sets:Gene Ontology 基因本体论(包括BP/CC/MF);
C6: oncogenic signatures:癌症特征基因集合,大部分来源于NCBI GEO 未发表芯片数据;
C7: immunologic signatures: 免疫相关基因集合。
后续做分析时需要从中选择感兴趣的基因集。
4.分析过程
1)软件下载(需java环境)
http://software.broadinstitute.org/gsea/downloads.jsp
2)设置
a. 准备基因表达量矩阵文件:txt或gct(最好将基因名转换为symbol,后续参数不用chip来转化ID)

数据格式可参考:
http://www.broadinstitute.org/cancer/software/gsea/wiki/index.php/Data_formats
测试数据:
http://software.broadinstitute.org/gsea/datasets.jsp
b. 准备说明文件:cls

第一行:样本数/分组数/always1
第二行:分组名
第三行:分组信息(我这里28个上部位,21个下部位)
load data,成功会显示
c. 选择已知基因集(即以上8个cluster)
run GSEA,设置参数
Gene sets database:8个cluster及其分支,可多选
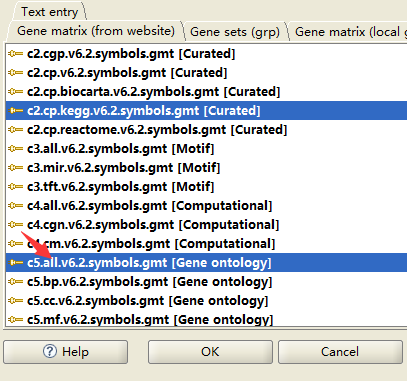
我这里选择kegg和all GO,若是想研究更多,可8个cluster全部选择all。
d. 设置参数:
Required fields
expression dataset:选择表达量文件
number of permutations:置换次数,越大越好,但对计算有要求,我选择500
phenotype labels:选择表型说明文件cls
collapse dataset to gene symbols:若是gene symbols编号,选择false(我这里已经提前转换),否则选择true,即用chip来对ID转换
permutation type:置换类型,#一般每组样本数目大于7个时,建议选择phenotype,否则选择gene sets,官方文档有说明#,我这里还是选择gene_set
chip platform:和上面gene symbols参数对应,不需转换不用选择,否则选择对应的芯片
Basic fields
analysis name:项目名
save results in this folder:结果保存路径
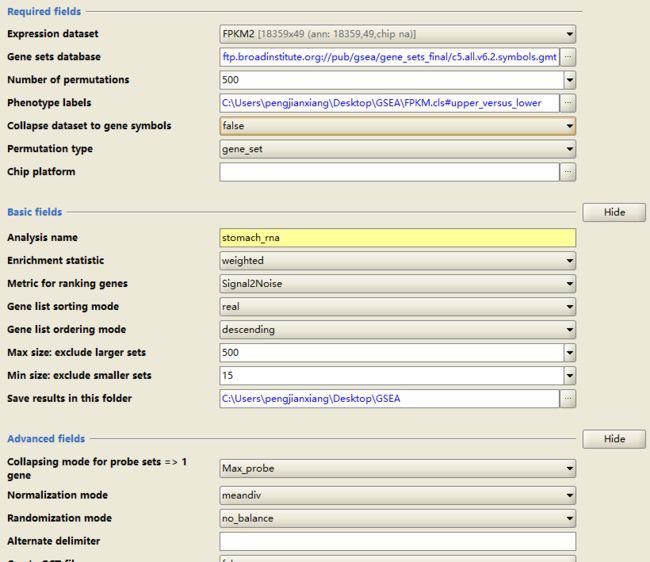
其他我都设置为默认,没有深加探索,可看官网,最后点run
GSEA运行的原理可分为三步:1) 计算富集分数(Enrichment Score,ES);2) 估计富集分数的显著性水平;3) 矫正多重假设检验。
完成后显示:
5.结果解读
保存文件路径中生成一堆文件:

最常看的是这种图:
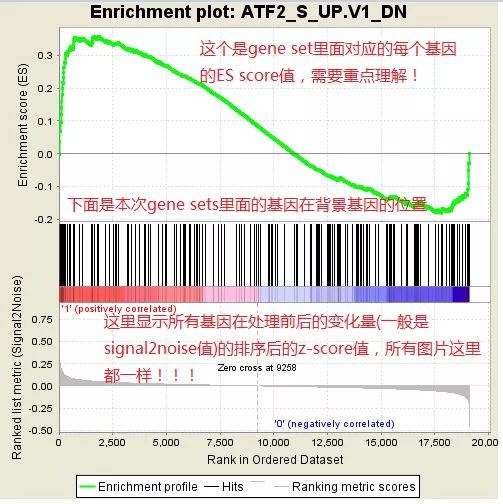
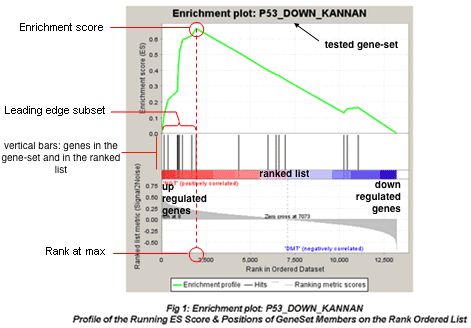
** 原理:**
根据所有基因在两组样本(case-control,我这里是upper-lower)的差异度量不同(共有六种差异度量,默认是signal 2 noise,GSEA官网有提供公式,也可以选择大家熟悉的foldchange),根据差异度量大小排序,并且Z-score标准化。图中间的竖杠,就是每个gene set里的基因在所有排序好基因的位置,如果gene set里的基因集中在所有基因的前部分,就是在case里面富集,如果集中在后面部分,就是在control里面富集着(结果中的热图就是竖杠的具象)。
我们一般关注ES值,峰出现在前端还是后端(ES值大于0在前端,小于0在后端)以及Leading-edge subset(即对富集贡献最大的部分,领头亚集);在ES图中出现领头亚集的形状,表明这个功能基因集在某处理条件下具有更显著的生物学意义。
ES算法:
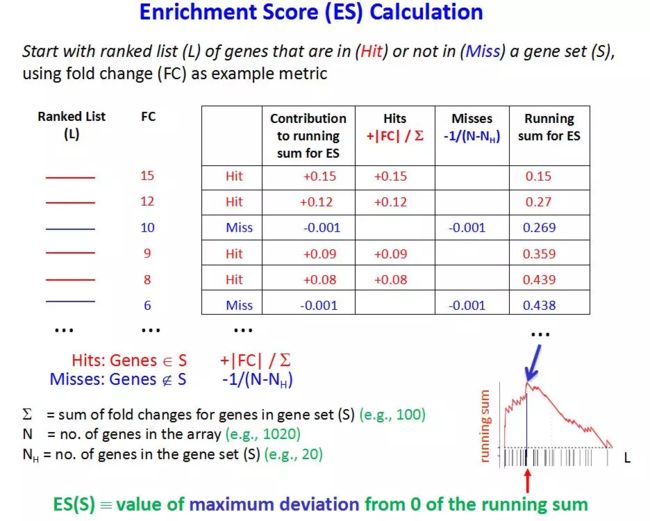
每个基因在gene set里的ES score取决于这个基因是否属于该gene set及其差异度量,上图的差异度量就是FC(foldchange),将每个gene set里的所有基因的ES score一个个加起来,叫running ES score,直到ES score达到最大值,就是这个gene set最终的ES score。
可以一一查看每个图,也可点击上面的GSEA reports查看success的网页报告:

gsea_report报告结果中会有一个类似下图的表格,主要关注这三个部分:
标准化富集分数(NES);
标准化显著性水平(NOM p-val);
矫正多重假设检验(FDR q-val);
一般认为NES绝对值≧ 1.0,NOM p-val ≦ 0.05,FDR q-val ≦ 0.25是有意义的基因集合,当然也要结合具体情况具体分析。

如果英语好,直接看官方文档,很详细:http://www.gsea-msigdb.org/gsea/doc/GSEAUserGuideFrame.html?_Interpreting_GSEA_Results
References:
https://mp.weixin.qq.com/s/NnRfeTLDb-42a8CV3kymZQ
http://www.bio-info-trainee.com/1282.html
http://www.bioinfo-scrounger.com/archives/557
https://mp.weixin.qq.com/s?src=11×tamp=1535510844&ver=1089&signature=2333yjeN-l1IB5KVYybBbDKOujytHQe8id7ztWsR0aSthe-uW2tNRlCloBh4TGFffss0ky9UrcuqEkmLBug2PC*LQN79FaHzZEe-c5eGtBQ-8UacB1NqZHTQcw0BuZIX&new=1
https://mp.weixin.qq.com/s?__biz=MzAwMzY4MTYxNw==&mid=2655754973&idx=1&sn=3b87d5cb8ddd2d5d77e413e9a87342da&chksm=808846e3b7ffcff5a6b41985b707f52170f20eabe15fc43264b3d14a3ccf4100263789eab856&mpshare=1&scene=21&srcid=1209nycSnM84dUY4eRL3cWBP#wechat_redirect
https://mp.weixin.qq.com/s?__biz=MzAwMzY4MTYxNw==&mid=2655753566&idx=2&sn=5b5b2c93a7618a69da2cbc6638f03da0&chksm=80884960b7ffc076af53ae74caadb5dbb25d240c31660792e8727964d0177d6a17af7ca5fc5c&mpshare=1&scene=21&srcid=1209df2mYAyd4WSClBsfwGwb#wechat_redirect
ES算法:http://www.baderlab.org/CancerStemCellProject/VeroniqueVoisin/AdditionalResources/GSEA