解释性脚本语言与编译性语言的区别
Lua代码的执行流程
脚本语言通常都是解释执行的,每一门脚本语言都会有自己定义的OpCode(operation code, 也称为 bytecode,即操作码或字节码),即为这门程序定义的“汇编语言”。一般的编译型语言,比如C等,经过编译器编译之后,生成的都是与当前硬件环境相匹配的汇编代码。而脚本型语言经过编译器前端处理之后,生成的就是字节码,在将该字节码放在这门语言的虚拟机中逐个执行。
脚本语言没有像编译型语言那样直接编译为机器能识别的机器代码,这意味着解释性脚本语言与编译型语言的区别:
- 由于每个脚本语言都有自己的一套字节码,与具体的硬件平台无关,所以无需修改脚本代码,就能运行在各个平台上。硬件、软件平台的差异都由语言自身的虚拟机解决。
- 由于脚本语言的字节码需要由虚拟机执行,而不像机器代码那样能够直接执行,所以运行速度比编译型语言差不少。
有了虚拟机这个中间层,同样的代码可以不经修改就运行在不同的操作系统、硬件平台上。Java、Python都是基于虚拟机的编程语言,Lua同样也是这样。一般而言,一个语言的虚拟机需要完成以下工作。
- 将源代码编译成虚拟机可以识别执行的字节码
- 为函数调用准备调用栈
- 内部维持一个IP(指令指针,Instruction Pointer)来保护下一个将执行的指令地址。在Lua代码中,IP对应的是PC指针。
- 模拟一个CPU的运行:循环拿出由IP指向的字节码,根据字节码格式进行编码,然后执行字节码。
虚拟机有2种不同的实现方式:基于栈的虚拟机和基于寄存器的虚拟机(stack-based vs. register-based)。市面上常见的虚拟机如Java、.Net都是基于栈的虚拟机,Lua是已知的第一个使用基于寄存器虚拟机并被广泛是用的编程语言。
在基于栈的虚拟机中,字节码的操作数是从栈顶上弹出pop,在执行完操作之后再压入push栈顶的。
例如:以一个加法操作为例,在操作前后它的栈结构对比。
# 伪代码
POP 2
POP 1
ADD 2,1,result
PUSH result

基于栈的虚拟机
可以看到,执行一条加法操作需要执行4条字节码,其中前几条指令用于准备数据,将数据压栈,这是这种设计的缺点。但是优点是,指令中不需要关心操作数的地址,在执行操作之前已经将操作数准备栈顶上了。
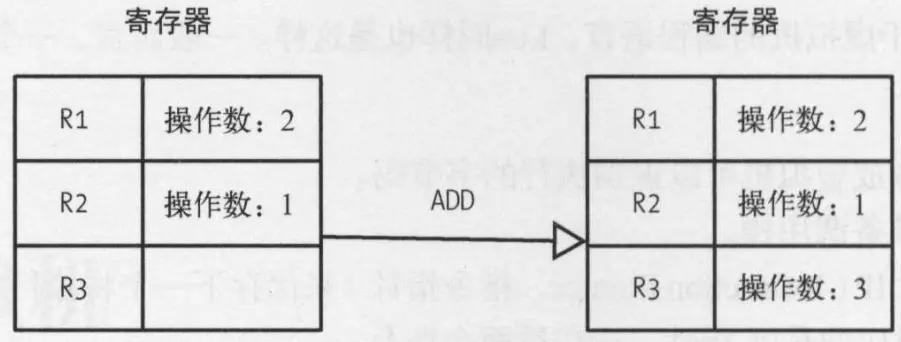
基于寄存器的虚拟机
与基于栈的虚拟机不同,在基于寄存器的指令中,操作数是放在“CPU的寄存器”中,因为并不是物理意义上的寄存器。因此,同样的操作不在需要PUSH、POP指令,取而代之的是在字节码中带上具体操作数所在的寄存器地址。
对比基于栈的寄存器,这里只需一条指令就可以完成加法操作,但缺点是成程序需要关注操作数所在的位置。
Lua使用的是基于寄存器的虚拟机实现方式,其中很大的原因是它的设计目标之一就是尽可能高效。

虚拟机工作流程
总结一下,实现一个脚本语言的解释器,其核心问题如下:
- 设计一套字节码,分析源代码文件生成字节码。
- 在虚拟机中执行字节码
- 如何在整个执行过程中保存整个执行环境

Lua代码执行流程
Lua源码可分为3部分:虚拟机核心、内嵌库、解释器和编译器
Lua解释器中,内部模块对外提供的接口、数据结构都以lua模块名简称_作为前缀,供外部调用的API则使用lua_作为前缀。
Lua虚拟机核心文件
lapi.clua_C语言接口lcode.cluaK_源码生成器ldebug.cluaG_调试库ldo.cluaD_函数调用及栈管理ldump.o序列化预编译的Lua字节码lfunc.cluaF_提供操作函数原型及闭包的辅助函数lgc.cluaC_GC垃圾收集llex.cluaX_词法分析lmem.cluaM_内存管理lobject.cluaO_对象管理lopcodes.cluaP_字节码操作lparser.cluaY_分析器lstate.cluaE_全局状态机lstring.cluaS_字符串操作ltable.cluaH_表操作lundump.cluaH_加载预编译字节码ltm.cluaT_tag方法lzio.cluaZ_缓存流接口
Lua虚拟机工作流程
Lua代码通过翻译成Lua虚拟机能识别的字节码运行,以此它主要分为两部分:
- 翻译代码并编译为字节码
负责将Lua代码进行词法分析、语法分析等,最终生成字节码。涉及这部分的代码文件包括:
llex.c用于词法分析lparser.c用于进行语法分析lcode.c最终生成代码
在lopcodes.h、lopcodes.c文件中,定义了Lua虚拟机相关的字节码指令的格式以及相关的API。
- Lua虚拟机相关部分
经过分析之后生成对应的字节码,此后就是将字节码装载到虚拟机中执行。
lvm.c
Lua虚拟机执行的主函数luaV_execute,主函数是一个大的循环,依次从字节码中取出指令并执行。Lua虚拟机对外看到的数据结构是lua_State,这个结构体将一直贯穿整个分析以及执行阶段。
ldo.c
除了虚拟机的执行之外,Lua的核心部分还包括进行函数调用和返回处理的相关代码,主要处理函数调用前后环境的准备和还原。
lgc.c
垃圾收回部分
lapi.c
Lua是一门嵌入式脚本语言,意味着其设计目标之一必须满足能够与宿主系统进行交互。
指令的解析与执行
Lua词法
学过编译原理的人都知道,对一门语言进行解析一般是2编遍历的过程。

2遍遍历扫描代码文件
第1遍:解析源代码并生成AST(Abstract Syntax Tree,抽象语法树)
第2遍:将AST翻译为对应的字节码
可以看出,AST仅进是分析过程中的中间产物,在实际输出中是不需要的。
Lua使用的是递归下降法(recursive descent method)进行解析,这个分析方式针对文法中的每一个非终结符(non-terminal symbol),建立一个子程序模拟语法树向下推导,在推导过程中遇到终结符(terminal symbol)则检查是否匹配,遇到非终结符则调用对应的相关子程序进行处理。