python充电时刻
十章、充电时刻
python安装包里包含一组模块,标准库(standard library)。本章就重点讲讲这些标准库。
10.1模块
import从外部模块引入函数。
>>> import math
>>> math.sin(0)
0.0
>>> math.cos(0.)
1.0
>>> math.tan(0.)
0.0
>>> math.ctan(0)
Traceback (most recent call last):
File "", line 1, in
math.ctan(0)
AttributeError: 'module' object has no attribute 'ctan'
>>> math.cotan(0)
Traceback (most recent call last):
File "", line 1, in
math.cotan(0)
AttributeError: 'module' object has no attribute 'cotan'
>>> math.cot(0)
Traceback (most recent call last):
File "", line 1, in
math.cot(0)
AttributeError: 'module' object has no attribute 'cot'
>>> math.sec(0)
Traceback (most recent call last):
File "", line 1, in
math.sec(0)
AttributeError: 'module' object has no attribute 'sec'
10.1.1模块是程序
导入自己编写的模块
>>> import sys
>>> sys.path.append('D:Python32')#告诉系统除了从默认目录地方寻找模块外
>#还从该路径地址寻找
>>> import hello
What is your name?heh
Hello,heh!
>>> import hello
>>>
再次导入模块并没有执行代码。
多次导入效果和导入一次效果相同。
python3之后没有reload函数重新导入操作了。
10.1.2模块用于定义
所谓模块就是编写的代码块被保存的名字。
1.在模块中定义函数
#模块保存为hello2.py
def hello():
print("Hello,world!")
#运行结果
>>> import hello2#导入模块
>>> hello2.hello()#访问模块中的hello()函数
Hello,world!
这样为代码的复用提供了可能。一个已经写好的代码模块中的某些函数,可以被引入到现在正在编写的代码中,通过前面例子的方法引用模块中的函数,避免了代码的重复编写。
2.在模块中增加测试代码
#带有问题测试代码的简单模块
#hello3.py
def hello():
print("Hello,world!")
#A test:
hello()
#运行结果
>>> import hello3#引入模块阶段,hello()函数就被执行了,这于前面hello2是不一样的,不是想要的
Hello,world!
>>> hello3.hello()
Hello,world!
怎么办?
就要告诉模块,是作为程序运行还是导入到其他程序。用到__name__变量
>>> __name__
'__main__'
>>> hello3.__name__
'hello3'
__name__变量的值是’__main__’。在导入模块时,这个变量被定义为模块的名字。
#带有问题测试代码的简单模块
#hello4.py
def hello():
print("Hello,world!")
def test():
hello()
if __name__=='__main__':test()#让模块被引入时,test函数不会执行。
#运行结果
>>> import hello4
>>> hello4.hello()
Hello,world!
>>> hello4.test()
Hello,world!
>>> hello4.__name__
'hello4'
if name == ‘main’ 如何正确理解?
10.1.3让自定义模块可用
两种方法:一是将模块放在正确的目录位置;二是引入时给出正确的路径。
1.将模块放在正确的位置
怎么做?
知道python解释器从哪里找模块就将自定义模块放在哪里就好了。一般放在
site-package目录下面
2.告诉解释器去哪里找
3.命名模块
.py命名后缀,或windows下.pyw后缀?没考证。
10.1.4包
把多个模块放在一组中,就是包。
例如你要建立一个drawing的包,其中包括shapes和colors的模块。就需要建立如下表所示的文件和目录。
简单的包布局
| 文件/目录 | 描述 |
|---|---|
| ~/python/ | PYTHONPATH中的目录 |
| ~/python/drawing/ | 包目录 |
| ~/python/drawing/__init__.py | 包代码 |
| ~/python/drawing/colors.py | colors模块 |
| ~/python/drawing/shapes.py | shapes模块 |
windows系统中用c:\python替换~/python
三种引入语句
import drawing
import drawing.colors
from drawing import shapes
都合法
10.2探究模块
1、dir函数
查看模块包含的所有特性
import copy
>>> dir(copy)
['Error', 'PyStringMap', '_EmptyClass', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__name__', '__package__', '_copy_dispatch', '_copy_immutable', '_copy_with_constructor', '_copy_with_copy_method', '_deepcopy_atomic', '_deepcopy_dict', '_deepcopy_dispatch', '_deepcopy_list', '_deepcopy_method', '_deepcopy_tuple', '_keep_alive', '_reconstruct', '_test', 'builtins', 'copy', 'deepcopy', 'dispatch_table', 'error', 'name', 't', 'weakref']
2、__all__变量
>>> copy.__all__
['Error', 'copy', 'deepcopy']
定义模块的公有接口。
10.2.2用help获取帮助
>>> help(copy.copy)
Help on function copy in module copy:
copy(x)
Shallow copy operation on arbitrary Python objects.
See the module's __doc__ string for more info.
>>> print(copy.copy.__doc__)
Shallow copy operation on arbitrary Python objects.
See the module's __doc__ string for more info.
查看某个模块除了help也可以直接看它的文档描述,如下例子所示。
>>> print(range.__doc__)
range([start,] stop[, step]) -> range object
Returns a virtual sequence of numbers from start to stop by step.
10.2.4查看模块的源代码
一种sys.path方法
一种查模块的__file__属性
>>> print(copy.__file__)
D:\Python32\lib\copy.py
就知道模块存储在哪个目录下。如果是.py就可以用python解释器直接打开。
10.3标准库
>>> import sys
>>> dir(sys)
['__displayhook__', '__doc__', '__excepthook__', '__name__', '__package__', '__stderr__', '__stdin__', '__stdout__', '_clear_type_cache', '_current_frames', '_getframe', '_mercurial', '_xoptions', 'api_version', 'argv', 'builtin_module_names', 'byteorder', 'call_tracing', 'callstats', 'copyright', 'displayhook', 'dllhandle', 'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info', 'float_repr_style', 'getcheckinterval', 'getdefaultencoding', 'getfilesystemencoding', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettrace', 'getwindowsversion', 'hash_info', 'hexversion', 'int_info', 'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'setcheckinterval', 'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout', 'subversion', 'version', 'version_info', 'warnoptions', 'winver']
>>> print(sys.__doc__)
This module provides access to some objects used or maintained by the
interpreter and to functions that interact strongly with the interpreter.
Dynamic objects:
argv -- command line arguments; argv[0] is the script pathname if known
path -- module search path; path[0] is the script directory, else ''
modules -- dictionary of loaded modules
displayhook -- called to show results in an interactive session
excepthook -- called to handle any uncaught exception other than SystemExit
To customize printing in an interactive session or to install a custom
top-level exception handler, assign other functions to replace these.
stdin -- standard input file object; used by input()
stdout -- standard output file object; used by print()
stderr -- standard error object; used for error messages
By assigning other file objects (or objects that behave like files)
to these, it is possible to redirect all of the interpreter's I/O.
last_type -- type of last uncaught exception
last_value -- value of last uncaught exception
last_traceback -- traceback of last uncaught exception
These three are only available in an interactive session after a
traceback has been printed.
Static objects:
float_info -- a dict with information about the float implementation.
int_info -- a struct sequence with information about the int implementation.
maxsize -- the largest supported length of containers.
maxunicode -- the largest supported character
builtin_module_names -- tuple of module names built into this interpreter
subversion -- subversion information of the build as tuple
version -- the version of this interpreter as a string
version_info -- version information as a named tuple
hexversion -- version information encoded as a single integer
copyright -- copyright notice pertaining to this interpreter
platform -- platform identifier
executable -- pathname of this Python interpreter
prefix -- prefix used to find the Python library
exec_prefix -- prefix used to find the machine-specific Python library
float_repr_style -- string indicating the style of repr() output for floats
dllhandle -- [Windows only] integer handle of the Python DLL
winver -- [Windows only] version number of the Python DLL
__stdin__ -- the original stdin; don't touch!
__stdout__ -- the original stdout; don't touch!
__stderr__ -- the original stderr; don't touch!
__displayhook__ -- the original displayhook; don't touch!
__excepthook__ -- the original excepthook; don't touch!
Functions:
displayhook() -- print an object to the screen, and save it in builtins._
excepthook() -- print an exception and its traceback to sys.stderr
exc_info() -- return thread-safe information about the current exception
exit() -- exit the interpreter by raising SystemExit
getdlopenflags() -- returns flags to be used for dlopen() calls
getprofile() -- get the global profiling function
getrefcount() -- return the reference count for an object (plus one :-)
getrecursionlimit() -- return the max recursion depth for the interpreter
getsizeof() -- return the size of an object in bytes
gettrace() -- get the global debug tracing function
setcheckinterval() -- control how often the interpreter checks for events
setdlopenflags() -- set the flags to be used for dlopen() calls
setprofile() -- set the global profiling function
setrecursionlimit() -- set the max recursion depth for the interpreter
settrace() -- set the global debug tracing function
#百度解释
此模块提供对由
解释器和与解释器强交互的函数。
动态对象:
argv—命令行参数;argv[0]是脚本路径名(如果已知)
path—模块搜索路径;路径[0]是脚本目录,否则为''
模块加载模块字典
displayhook——调用以在交互式会话中显示结果
ExceptHook——调用它来处理除SystemExit之外的任何未捕获异常
在交互式会话中自定义打印或安装自定义
顶级异常处理程序,分配其他函数来替换它们。
stdin——标准输入文件对象;由input()使用
stdout——标准输出文件对象;由print()使用
stderr——标准错误对象;用于错误消息
通过指定其他文件对象(或行为类似于文件的对象)
对于这些,可以重定向解释器的所有I/O。
last_type—最后一个未捕获异常的类型
last_value—最后一个未捕获异常的值
last_traceback—上次未捕获异常的跟踪
只有在
已打印回溯。
静态对象:
float_info——包含float实现信息的dict。
int_info——一个包含int实现信息的结构序列。
MaxSize——容器的最大支持长度。
maxUnicode——支持的最大字符
内置模块名——内置到这个解释器中的模块名元组
subversion——以元组形式生成的subversion信息
version——这个解释器作为字符串的版本
版本信息——作为命名元组的版本信息
hexversion—编码为单个整数的版本信息
版权——与本翻译相关的版权声明
平台——平台标识符
可执行文件——这个python解释器的路径名
prefix——用于查找python库的前缀
exec_prefix——用于查找特定于机器的python库的前缀
float_repr_style——表示float的repr()输出样式的字符串
dll handle--[windows only]python dll的整数句柄
winver--[windows only]python dll的版本号
_原版stdin;不要碰!
_原版stdout;不要碰!
_斯特德——原来的斯特德;不要碰!
_ displayhook——原来的displayhook;不要碰!
_ ExceptHook——原来的ExceptHook;不要碰!
功能:
displayHook()——将对象打印到屏幕上,并将其保存在内置文件中。_
excepthook()--打印异常及其对sys.stderr的回溯
exc_info()--返回当前异常的线程安全信息
exit()--通过提升systemexit退出解释器
getdlopenflags()--返回用于dlopen()调用的标志
getprofile()--获取全局分析函数
getRefCount()--返回对象的引用计数(加一:-)
getRecursionLimit()--返回解释器的最大递归深度
getsizeof()--返回对象的大小(字节)
gettrace()--获取全局调试跟踪函数
setcheckinterval()——控制解释器检查事件的频率
set dlopen flags()--设置用于dlopen()调用的标志
setprofile()--设置全局分析函数
setRecursionLimit()--设置解释器的最大递归深度
setTrace()--设置全局调试跟踪函数
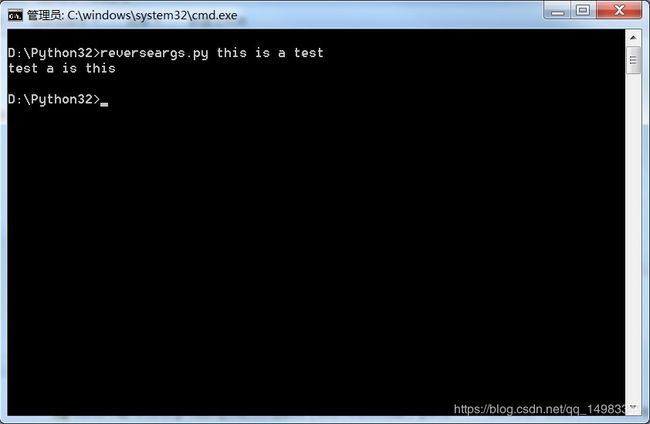
Python中 sys.argv[]的用法详解https://www.cnblogs.com/aland-1415/p/6613449.html
#reverseargs.py
import sys
args=sys.argv[1:]
args.reverse()
print(' '.join(args))
运行结果
10.3.2 os
os提供访问多个操作系统的服务
>>> import os
>>> print(os.__doc__)
OS routines for Mac, NT, or Posix depending on what system we're on.
This exports:
- all functions from posix, nt, os2, or ce, e.g. unlink, stat, etc.
- os.path is either posixpath or ntpath
- os.name is either 'posix', 'nt', 'os2' or 'ce'.
- os.curdir is a string representing the current directory ('.' or ':')
- os.pardir is a string representing the parent directory ('..' or '::')
- os.sep is the (or a most common) pathname separator ('/' or ':' or '\\')
- os.extsep is the extension separator (always '.')
- os.altsep is the alternate pathname separator (None or '/')
- os.pathsep is the component separator used in $PATH etc
- os.linesep is the line separator in text files ('\r' or '\n' or '\r\n')
- os.defpath is the default search path for executables
- os.devnull is the file path of the null device ('/dev/null', etc.)
Programs that import and use 'os' stand a better chance of being
portable between different platforms. Of course, they must then
only use functions that are defined by all platforms (e.g., unlink
and opendir), and leave all pathname manipulation to os.path
(e.g., split and join).
#百度解释
Mac、NT或POSIX的操作系统例程取决于我们所使用的系统。
此导出:
-来自POSIX、NT、OS2或CE的所有函数,例如unlink、stat等。
-os.path是posixpath或ntpath
-os.name可以是'posix'、'nt'、'os2'或'ce'。
-os.curdir是一个字符串,表示当前目录('.'或':')
-os.pardir是表示父目录(“..”或“::”)的字符串。
-os.sep是(或最常见的)路径名分隔符('/'或':'或'\')
-os.extsep是扩展分隔符(总是“.”)
-os.altsep是备用路径名分隔符(无或“/”)
-os.pathsep是$path etc中使用的组件分隔符
-os.linesep是文本文件中的行分隔符('\r'或'\n'或'\r\n')
-os.defpath是可执行文件的默认搜索路径
-os.dev null是空设备('/dev/null'等)的文件路径。
导入和使用“os”的程序更有可能
可在不同平台之间移动。当然,他们必须
仅使用所有平台定义的函数(例如,取消链接
和opendir),并将所有路径名操作留给os.path
(例如,拆分和连接)。
windows下调用以下代码
>>> import os
>>> os.system(r'D:\"Program Files"\"Thunder Network"\"Thunder"\"Program"\ThunderStart.exe')
0
#出现0,表示程序启动成功,实际情况也是迅雷被启动,启动之前会弹出dos窗口。
>>> os.system(r'D:\"Program Files"\"Thunder Network"\Thunder\Program\ThunderStart.exe')
0
#同样效果
>>> os.system(r'D:\"Program Files"\Thunder Network\Thunder\Program\ThunderStart.exe')
1
#失败的结果
Program Files
Thunder Network
必须放在引号中,不然dos会在空格处停下来。
使用另一种windows特有方法os.startfile能解决问题。
>>> os.startfile(r'D:\Program Files\Thunder Network\Thunder\Program\ThunderStart.exe')
#启动了迅雷,没有返回值0或1,也没有弹出dos窗口
这种方法就算有空格也不会有影响。
10.3.3 fileinput
>>> import fileinput
>>> dir(fileinput)
['DEFAULT_BUFSIZE', 'FileInput', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__name__', '__package__', '_state', '_test', 'close', 'filelineno', 'filename', 'fileno', 'hook_compressed', 'hook_encoded', 'input', 'isfirstline', 'isstdin', 'lineno', 'nextfile', 'os', 'sys']
>>> dir(fileinput.__all__)
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
>>> print(fileinput.__all__)
['FileInput', 'close', 'filelineno', 'filename', 'input', 'isfirstline', 'isstdin', 'lineno', 'nextfile']
>>> fileinput.__all__
['FileInput', 'close', 'filelineno', 'filename', 'input', 'isfirstline', 'isstdin', 'lineno', 'nextfile']
>>> help(fileinput)
Help on module fileinput:
NAME
fileinput - Helper class to quickly write a loop over all standard input files.
DESCRIPTION
Typical use is:
import fileinput
for line in fileinput.input():
process(line)
This iterates over the lines of all files listed in sys.argv[1:],
defaulting to sys.stdin if the list is empty. If a filename is '-' it
is also replaced by sys.stdin. To specify an alternative list of
filenames, pass it as the argument to input(). A single file name is
also allowed.
Functions filename(), lineno() return the filename and cumulative line
number of the line that has just been read; filelineno() returns its
line number in the current file; isfirstline() returns true iff the
line just read is the first line of its file; isstdin() returns true
iff the line was read from sys.stdin. Function nextfile() closes the
current file so that the next iteration will read the first line from
the next file (if any); lines not read from the file will not count
towards the cumulative line count; the filename is not changed until
after the first line of the next file has been read. Function close()
closes the sequence.
Before any lines have been read, filename() returns None and both line
numbers are zero; nextfile() has no effect. After all lines have been
read, filename() and the line number functions return the values
pertaining to the last line read; nextfile() has no effect.
All files are opened in text mode by default, you can override this by
setting the mode parameter to input() or FileInput.__init__().
If an I/O error occurs during opening or reading a file, the IOError
exception is raised.
If sys.stdin is used more than once, the second and further use will
return no lines, except perhaps for interactive use, or if it has been
explicitly reset (e.g. using sys.stdin.seek(0)).
Empty files are opened and immediately closed; the only time their
presence in the list of filenames is noticeable at all is when the
last file opened is empty.
It is possible that the last line of a file doesn't end in a newline
character; otherwise lines are returned including the trailing
newline.
Class FileInput is the implementation; its methods filename(),
lineno(), fileline(), isfirstline(), isstdin(), nextfile() and close()
correspond to the functions in the module. In addition it has a
readline() method which returns the next input line, and a
__getitem__() method which implements the sequence behavior. The
sequence must be accessed in strictly sequential order; sequence
access and readline() cannot be mixed.
Optional in-place filtering: if the keyword argument inplace=1 is
passed to input() or to the FileInput constructor, the file is moved
to a backup file and standard output is directed to the input file.
This makes it possible to write a filter that rewrites its input file
in place. If the keyword argument backup="." is also
given, it specifies the extension for the backup file, and the backup
file remains around; by default, the extension is ".bak" and it is
deleted when the output file is closed. In-place filtering is
disabled when standard input is read. XXX The current implementation
does not work for MS-DOS 8+3 filesystems.
Performance: this module is unfortunately one of the slower ways of
processing large numbers of input lines. Nevertheless, a significant
speed-up has been obtained by using readlines(bufsize) instead of
readline(). A new keyword argument, bufsize=N, is present on the
input() function and the FileInput() class to override the default
buffer size.
XXX Possible additions:
- optional getopt argument processing
- isatty()
- read(), read(size), even readlines()
CLASSES
builtins.object
FileInput
class FileInput(builtins.object)
| class FileInput([files[, inplace[, backup[, mode[, openhook]]]]])
|
| Class FileInput is the implementation of the module; its methods
| filename(), lineno(), fileline(), isfirstline(), isstdin(), fileno(),
| nextfile() and close() correspond to the functions of the same name
| in the module.
| In addition it has a readline() method which returns the next
| input line, and a __getitem__() method which implements the
| sequence behavior. The sequence must be accessed in strictly
| sequential order; random access and readline() cannot be mixed.
|
| Methods defined here:
|
| __del__(self)
|
| __enter__(self)
|
| __exit__(self, type, value, traceback)
|
| __getitem__(self, i)
|
| __init__(self, files=None, inplace=False, backup='', bufsize=0, mode='r', openhook=None)
|
| __iter__(self)
|
| __next__(self)
|
| close(self)
|
| filelineno(self)
|
| filename(self)
|
| fileno(self)
|
| isfirstline(self)
|
| isstdin(self)
|
| lineno(self)
|
| nextfile(self)
|
| readline(self)
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
FUNCTIONS
close()
Close the sequence.
filelineno()
Return the line number in the current file. Before the first line
has been read, returns 0. After the last line of the last file has
been read, returns the line number of that line within the file.
filename()
Return the name of the file currently being read.
Before the first line has been read, returns None.
input(files=None, inplace=False, backup='', bufsize=0, mode='r', openhook=None)
input(files=None, inplace=False, backup="", bufsize=0, mode="r", openhook=None)
Create an instance of the FileInput class. The instance will be used
as global state for the functions of this module, and is also returned
to use during iteration. The parameters to this function will be passed
along to the constructor of the FileInput class.
isfirstline()
Returns true the line just read is the first line of its file,
otherwise returns false.
isstdin()
Returns true if the last line was read from sys.stdin,
otherwise returns false.
lineno()
Return the cumulative line number of the line that has just been read.
Before the first line has been read, returns 0. After the last line
of the last file has been read, returns the line number of that line.
nextfile()
Close the current file so that the next iteration will read the first
line from the next file (if any); lines not read from the file will
not count towards the cumulative line count. The filename is not
changed until after the first line of the next file has been read.
Before the first line has been read, this function has no effect;
it cannot be used to skip the first file. After the last line of the
last file has been read, this function has no effect.
DATA
__all__ = ['FileInput', 'close', 'filelineno', 'filename', 'input', 'i...
FILE
d:\python32\lib\fileinput.py
>>> print(fileinput.__doc__)
Helper class to quickly write a loop over all standard input files.
Typical use is:
import fileinput
for line in fileinput.input():
process(line)
This iterates over the lines of all files listed in sys.argv[1:],
defaulting to sys.stdin if the list is empty. If a filename is '-' it
is also replaced by sys.stdin. To specify an alternative list of
filenames, pass it as the argument to input(). A single file name is
also allowed.
Functions filename(), lineno() return the filename and cumulative line
number of the line that has just been read; filelineno() returns its
line number in the current file; isfirstline() returns true iff the
line just read is the first line of its file; isstdin() returns true
iff the line was read from sys.stdin. Function nextfile() closes the
current file so that the next iteration will read the first line from
the next file (if any); lines not read from the file will not count
towards the cumulative line count; the filename is not changed until
after the first line of the next file has been read. Function close()
closes the sequence.
Before any lines have been read, filename() returns None and both line
numbers are zero; nextfile() has no effect. After all lines have been
read, filename() and the line number functions return the values
pertaining to the last line read; nextfile() has no effect.
All files are opened in text mode by default, you can override this by
setting the mode parameter to input() or FileInput.__init__().
If an I/O error occurs during opening or reading a file, the IOError
exception is raised.
If sys.stdin is used more than once, the second and further use will
return no lines, except perhaps for interactive use, or if it has been
explicitly reset (e.g. using sys.stdin.seek(0)).
Empty files are opened and immediately closed; the only time their
presence in the list of filenames is noticeable at all is when the
last file opened is empty.
It is possible that the last line of a file doesn't end in a newline
character; otherwise lines are returned including the trailing
newline.
Class FileInput is the implementation; its methods filename(),
lineno(), fileline(), isfirstline(), isstdin(), nextfile() and close()
correspond to the functions in the module. In addition it has a
readline() method which returns the next input line, and a
__getitem__() method which implements the sequence behavior. The
sequence must be accessed in strictly sequential order; sequence
access and readline() cannot be mixed.
Optional in-place filtering: if the keyword argument inplace=1 is
passed to input() or to the FileInput constructor, the file is moved
to a backup file and standard output is directed to the input file.
This makes it possible to write a filter that rewrites its input file
in place. If the keyword argument backup="." is also
given, it specifies the extension for the backup file, and the backup
file remains around; by default, the extension is ".bak" and it is
deleted when the output file is closed. In-place filtering is
disabled when standard input is read. XXX The current implementation
does not work for MS-DOS 8+3 filesystems.
Performance: this module is unfortunately one of the slower ways of
processing large numbers of input lines. Nevertheless, a significant
speed-up has been obtained by using readlines(bufsize) instead of
readline(). A new keyword argument, bufsize=N, is present on the
input() function and the FileInput() class to override the default
buffer size.
XXX Possible additions:
- optional getopt argument processing
- isatty()
- read(), read(size), even readlines()
具体实例
#numberlines.py
import fileinput
for line in fileinput.input('D:/Python32/numberlines.txt',inplace=True):
line=line.rstrip()
num=fileinput.lineno()
print('%-40s#%2i'%(line,num))
#运行两次结果
#numberlines.py # 1# 1
import fileinput # 2# 2
for line in fileinput.input('D:/Python32/numberlines.py',inplace=True):# 3# 3
line=line.rstrip() # 4# 4
num=fileinput.lineno() # 5# 5
print('%-40s#%2i'%(line,num)) # 6# 6
# 7# 7
# 8# 8
使用inplace要谨慎,很容易破坏文件。
fileinput.input(files=None, inplace=False, backup=’’, bufsize=0, mode=‘r’, openhook=None)
10.3.4 集合、堆和双端队列
1.集合
>>> set(range(10))
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
>>> set(['a','b','c'])
{'a', 'c', 'b'}
>>> set([0,1,2,3,4,5,6,0,1,2,3,5,6])
{0, 1, 2, 3, 4, 5, 6}#重复项合并
>>> set(['a','b','c','d','a','b'])
{'a', 'c', 'b', 'd'}
集合由序列(或其他可迭代对象)创建,类似于字典没有特定的顺序。另外,重复项会合并。主要用于检查成员资格。
>>> a=set([1,2,3])
>>> b=set([2,3,4])
>>> a.union(b)
{1, 2, 3, 4}
>>> a|b
{1, 2, 3, 4}
>>> c=a&b
>>> c
{2, 3}
>>> c.issubset
>>> c.isubset(a)
Traceback (most recent call last):
File "", line 1, in
c.isubset(a)
AttributeError: 'set' object has no attribute 'isubset'
>>> c.issubset(a)
True
>>> c<=a
True
>>> c.issuperset(a)
False
>>> c>=a
False
>>> a.intersection(b)
{2, 3}
>>> a&b
{2, 3}
>>> a.difference(b)
{1}
>>> a-b
{1}
>>> b.difference(a)
{4}
>>> b-a
{4}
>>> a.symmetric_difference(b)
{1, 4}
>>> a^b
{1, 4}
>>> a.copy()
{1, 2, 3}
>>> a.copy() is a
False
>>>
通过以上例子可以看出集合的一般运算。还可以用基本方法add和remove。
更多信息查看库参考
库参考
来看查找和打印两个集合的并集的例子
>>> mySets=[]
>>> for i in range(10):
mySets.append(set(range(i,i+5)))
>>> mySets
[{0, 1, 2, 3, 4}, {1, 2, 3, 4, 5}, {2, 3, 4, 5, 6}, {3, 4, 5, 6, 7}, {8, 4, 5, 6, 7}, {8, 9, 5, 6, 7}, {8, 9, 10, 6, 7}, {8, 9, 10, 11, 7}, {8, 9, 10, 11, 12}, {9, 10, 11, 12, 13}]
>>> from functools import reduce
>>> reduce(set.union,mySets)
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13}
help(reduce)
Help on built-in function reduce in module _functools:
reduce(...)
reduce(function, sequence[, initial]) -> value
Apply a function of two arguments cumulatively to the items of a sequence,
from left to right, so as to reduce the sequence to a single value.
For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates
((((1+2)+3)+4)+5). If initial is present, it is placed before the items
of the sequence in the calculation, and serves as a default when the
sequence is empty.
reduce函数是函数工具 functools的内建函数。
from functools import reduce
reduce函数,reduce函数会对参数序列中元素进行累积。
reduce函数的定义:
reduce(function, sequence [, initial] ) -> value
function参数是一个有两个参数的函数,reduce依次从sequence中取一个元素,和上一次调用function的结果做参数再次调用function。
第一次调用function时,如果提供initial参数,会以sequence中的第一个元素和initial作为参数调用function,否则会以序列sequence中的前两个元素做参数调用function。
lambda 表达式是 Python 中创建匿名函数的一个特殊语法。 它返回的函数可称之为 lambda 函数。
>>> from functools import reduce
>>> lst=[1,2,3,4]
>>> reduce(lambda x,y: x+y, lst)
10
上例中lambda x,y:x+y意思是什么呢?意思就是创造一个函数,这个函数有两个变量x和y,返回x+y的值。
集合因为可变,不能作为字典的键。另外一个问题集合本身只能包含不可变的值,所以不能包含其他集合,但是集合的集合是很常见的。这就成了问题。frozenset类型就变得很有用。代表不可变集合。
>>> a=set()
>>> b=set()
>>> a.add(b)
Traceback (most recent call last):
File "", line 1, in
a.add(b)
TypeError: unhashable type: 'set'
>>> a.add(frozenset(b))
>>> a
{frozenset()}
frozenset构造函数创建给定集合的副本,不管是将集合作为其他集合成员还是字典的键,都很有用。
2.堆
堆是优先队列的一种。是一种数据结构。使用优先队列可以任意顺序添加对象,并且能在任何时间(添加或移除)找到最小的元素。比列表方法min要有效的多。
python中没有独立的堆类型,只有一些堆操作函数的模块。这个模块叫heapq(q是queue的缩写,也就是队列)。包含六个函数。
>>> import heapq
>>>help(heapq)
Help on module heapq:
NAME
heapq - Heap queue algorithm (a.k.a. priority queue).
DESCRIPTION
Heaps are arrays for which a[k] <= a[2*k+1] and a[k] <= a[2*k+2] for
all k, counting elements from 0. For the sake of comparison,
non-existing elements are considered to be infinite. The interesting
property of a heap is that a[0] is always its smallest element.
#位置k的元素总是比2*k+1和2*k+2两个位置的元素小。位置0总是堆中的最小元素。
Usage:
heap = [] # creates an empty heap
heappush(heap, item) # pushes a new item on the heap
item = heappop(heap) # pops the smallest item from the heap
item = heap[0] # smallest item on the heap without popping it
heapify(x) # transforms list into a heap, in-place, in linear time
item = heapreplace(heap, item) # pops and returns smallest item, and adds
# new item; the heap size is unchanged
Our API differs from textbook heap algorithms as follows:
- We use 0-based indexing. This makes the relationship between the
index for a node and the indexes for its children slightly less
obvious, but is more suitable since Python uses 0-based indexing.
- Our heappop() method returns the smallest item, not the largest.
These two make it possible to view the heap as a regular Python list
without surprises: heap[0] is the smallest item, and heap.sort()
maintains the heap invariant!
FUNCTIONS
heapify(...)
Transform list into a heap, in-place, in O(len(heap)) time.
heappop(...)
Pop the smallest item off the heap, maintaining the heap invariant.
heappush(...)
Push item onto heap, maintaining the heap invariant.
heappushpop(...)
Push item on the heap, then pop and return the smallest item
from the heap. The combined action runs more efficiently than
heappush() followed by a separate call to heappop().
heapreplace(...)
Pop and return the current smallest value, and add the new item.
This is more efficient than heappop() followed by heappush(), and can be
more appropriate when using a fixed-size heap. Note that the value
returned may be larger than item! That constrains reasonable uses of
this routine unless written as part of a conditional replacement:
if item > heap[0]:
item = heapreplace(heap, item)
merge(*iterables)
Merge multiple sorted inputs into a single sorted output.
Similar to sorted(itertools.chain(*iterables)) but returns a generator,
does not pull the data into memory all at once, and assumes that each of
the input streams is already sorted (smallest to largest).
>>> list(merge([1,3,5,7], [0,2,4,8], [5,10,15,20], [], [25]))
[0, 1, 2, 3, 4, 5, 5, 7, 8, 10, 15, 20, 25]
nlargest(n, iterable, key=None)
Find the n largest elements in a dataset.
Equivalent to: sorted(iterable, key=key, reverse=True)[:n]
nsmallest(n, iterable, key=None)
Find the n smallest elements in a dataset.
Equivalent to: sorted(iterable, key=key)[:n]
DATA
__about__ = 'Heap queues\n\n[explanation by François Pinard]\n\nH... t...
__all__ = ['heappush', 'heappop', 'heapify', 'heapreplace', 'merge', '...
| 函数 | 描述 |
|---|---|
| heappush(heap,x) | 将x入堆 |
| heappop(heap) | 将堆中最小元素弹出 |
| heapify(heap) | 将heap属性强制应用到任意一个列表 |
| heapreplace(heap,x) | 将堆中最小元素弹出,同时x入堆 |
| nlagest(n,iter) | 返回iter中第n大的元素 |
| nsmallest(n,iter) | 返回iter中第n小的元素 |
>>> list1=list(range(0,10))
>>> list1
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> import heapq
>>> heapq.heapify(list1)#对列表进行强制堆转换
>>> list1
[0, 1, 4, 2, 7, 5, 6, 3, 9, 8]
>>> from heapq import *
>>> from random import shuffle
>>> data=range(10)
>>> shuffle(data)
Traceback (most recent call last):
File "", line 1, in
shuffle(data)
File "D:\Python32\lib\random.py", line 266, in shuffle
x[i], x[j] = x[j], x[i]
TypeError: 'range' object does not support item assignment
d
>>> data=list(range(10))
>>> data
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> shulfle(data)
Traceback (most recent call last):
File "", line 1, in
shulfle(data)
NameError: name 'shulfle' is not defined
>>> shuffle(data)
>>> data
[6, 4, 3, 5, 2, 1, 7, 8, 9, 0]
>>> heap=[]
>>> for n in data:
heappush(heap,n)
>>> heap
[0, 1, 2, 6, 3, 4, 7, 8, 9, 5]
>>> heappush(heap,0.5)
>>> heap
[0, 0.5, 2, 6, 1, 4, 7, 8, 9, 5, 3]
>>>
>>> heap
[0, 1, 2, 6, 3, 4, 7, 8, 9, 5]
>>> heappush(heap,0.5)
>>> heap
[0, 0.5, 2, 6, 1, 4, 7, 8, 9, 5, 3]
>>> heappop(heap)
0
>>> heap
[0.5, 1, 2, 6, 3, 4, 7, 8, 9, 5]
>>> heappop(heap)
0.5
>>> heap
[1, 3, 2, 6, 5, 4, 7, 8, 9]
>>> heappop(heap)
1
>>> heap
[2, 3, 4, 6, 5, 9, 7, 8]
>>>
>>> heapreplace(heap,0.5)
2
>>> heap
[0.5, 3, 4, 6, 5, 9, 7, 8]
>>> heapreplace(heap,10)
0.5
>>> heap
[3, 5, 4, 6, 10, 9, 7, 8]
nlargest(n,iter),nsmallest(n,iter)分别用来寻找任何可迭代对象iter中第n大的元素和第n小的元素。也可以用sorted函数和分片来完成这个工作,但堆算法更快更有效利用内存,更易用。
3.双端队列
双端队列在需要按元素添加的顺序移除元素时非常有用。类似于先入先出队列?
创建方法:通过可迭代对象创建,比如集合。
>>> from collections import deque
>>> help(deque)
Help on class deque in module collections:
class deque(builtins.object)
| deque(iterable[, maxlen]) --> deque object
|
| Build an ordered collection with optimized access from its endpoints.
|
| Methods defined here:
|
| __copy__(...)
| Return a shallow copy of a deque.
|
| __delitem__(...)
| x.__delitem__(y) <==> del x[y]
|
| __eq__(...)
| x.__eq__(y) <==> x==y
|
| __ge__(...)
| x.__ge__(y) <==> x>=y
|
| __getattribute__(...)
| x.__getattribute__('name') <==> x.name
|
| __getitem__(...)
| x.__getitem__(y) <==> x[y]
|
| __gt__(...)
| x.__gt__(y) <==> x>y
|
| __iadd__(...)
| x.__iadd__(y) <==> x+=y
|
| __init__(...)
| x.__init__(...) initializes x; see help(type(x)) for signature
|
| __iter__(...)
| x.__iter__() <==> iter(x)
|
| __le__(...)
| x.__le__(y) <==> x<=y
|
| __len__(...)
| x.__len__() <==> len(x)
|
| __lt__(...)
| x.__lt__(y) <==> x x!=y
|
| __reduce__(...)
| Return state information for pickling.
|
| __repr__(...)
| x.__repr__() <==> repr(x)
|
| __reversed__(...)
| D.__reversed__() -- return a reverse iterator over the deque
|
| __setitem__(...)
| x.__setitem__(i, y) <==> x[i]=y
|
| append(...)
| Add an element to the right side of the deque.
|
| appendleft(...)
| Add an element to the left side of the deque.
|
| clear(...)
| Remove all elements from the deque.
|
| count(...)
| D.count(value) -> integer -- return number of occurrences of value
|
| extend(...)
| Extend the right side of the deque with elements from the iterable
|
| extendleft(...)
| Extend the left side of the deque with elements from the iterable
|
| pop(...)
| Remove and return the rightmost element.
|
| popleft(...)
| Remove and return the leftmost element.
|
| remove(...)
| D.remove(value) -- remove first occurrence of value.
|
| reverse(...)
| D.reverse() -- reverse *IN PLACE*
|
| rotate(...)
| Rotate the deque n steps to the right (default n=1). If n is negative, rotates left.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| maxlen
| maximum size of a deque or None if unbounded
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __hash__ = None
|
| __new__ =
| T.__new__(S, ...) -> a new object with type S, a subtype of T
>>> from collections import deque
>>> q=deque(range(5))
>>> q.append(5)
>>> q.appendleft(6)
>>> q
deque([6, 0, 1, 2, 3, 4, 5])
>>> q.pop()
5
>>> q.popleft()
6
>>> q
deque([0, 1, 2, 3, 4])
>>> q.rotate(3)
>>> q
deque([2, 3, 4, 0, 1])
>>> q.rotate(-1)
>>> q
deque([3, 4, 0, 1, 2])
>>> list1=list(range(4,10))
>>> q.extend(list1)
>>> q
deque([2, 3, 4, 0, 1, 4, 5, 6, 7, 8, 9])
>>> q.extendleft(list1)
>>> q
deque([9, 8, 7, 6, 5, 4, 2, 3, 4, 0, 1, 4, 5, 6, 7, 8, 9])
双端队列的好处,能在队列两端添加元素和移除元素。能有效旋转元素,默认从右边第一个开始选择,也可以左旋。extend和extendleft可以将可迭代对象的元素从右或反序从左添加进队列。
10.3.5 time
time模块所包含的函数可以实现:获得当前时间、操作时间和日期、从字符串读取时间以及格式化时间为字符串。日期可以用实数(从“新纪元”1月1日0点开始计算到现在的秒数。新纪元是与平台相关的年份。)或包含9个整数的元组。
比如元组
(2019,9,16,17,44,20,0,232,0)
表示2019年9月16日17时44分20秒,星期一,当年的第232天,无夏令时。
整数的意义如下表
| 索引 | 字段 | 值 |
|---|---|---|
| 0 | 年 | 比如2019等 |
| 1 | 月 | 范围1~12 |
| 2 | 日 | 范围1~31 |
| 3 | 时 | 0~23 |
| 4 | 分 | 0~59 |
| 5 | 秒 | 0~61 |
| 6 | 周 | 当周一为0,范围0~6 |
| 7 | 儒历日 | 范围1~366 |
| 8 | 夏令时 | 0、1或-1 |
秒的范围0~61为了应付闰秒和双闰秒。夏令时是布尔类型(真或假)如果使用-1,mktime就会正常工作,该函数将这样的元组转换为时间戳,时间戳从新纪元开始以秒计算。
>>> import time
>>> time.asctime()
'Mon Sep 16 17:36:39 2019'
>>> help(time)
Help on built-in module time:
NAME
time - This module provides various functions to manipulate time values.
DESCRIPTION
There are two standard representations of time. One is the number
of seconds since the Epoch, in UTC (a.k.a. GMT). It may be an integer
or a floating point number (to represent fractions of seconds).
The Epoch is system-defined; on Unix, it is generally January 1st, 1970.
The actual value can be retrieved by calling gmtime(0).
The other representation is a tuple of 9 integers giving local time.
The tuple items are:
year (four digits, e.g. 1998)
month (1-12)
day (1-31)
hours (0-23)
minutes (0-59)
seconds (0-59)
weekday (0-6, Monday is 0)
Julian day (day in the year, 1-366)
DST (Daylight Savings Time) flag (-1, 0 or 1)
If the DST flag is 0, the time is given in the regular time zone;
if it is 1, the time is given in the DST time zone;
if it is -1, mktime() should guess based on the date and time.
Variables:
timezone -- difference in seconds between UTC and local standard time
altzone -- difference in seconds between UTC and local DST time
daylight -- whether local time should reflect DST
tzname -- tuple of (standard time zone name, DST time zone name)
Functions:
time() -- return current time in seconds since the Epoch as a float
clock() -- return CPU time since process start as a float
sleep() -- delay for a number of seconds given as a float
gmtime() -- convert seconds since Epoch to UTC tuple
localtime() -- convert seconds since Epoch to local time tuple
asctime() -- convert time tuple to string
ctime() -- convert time in seconds to string
mktime() -- convert local time tuple to seconds since Epoch
strftime() -- convert time tuple to string according to format specification
strptime() -- parse string to time tuple according to format specification
tzset() -- change the local timezone
CLASSES
builtins.tuple(builtins.object)
struct_time
class struct_time(builtins.tuple)
| The time value as returned by gmtime(), localtime(), and strptime(), and
| accepted by asctime(), mktime() and strftime(). May be considered as a
| sequence of 9 integers.
|
| Note that several fields' values are not the same as those defined by
| the C language standard for struct tm. For example, the value of the
| field tm_year is the actual year, not year - 1900. See individual
| fields' descriptions for details.
|
| Method resolution order:
| struct_time
| builtins.tuple
| builtins.object
|
| Methods defined here:
|
| __reduce__(...)
|
| __repr__(...)
| x.__repr__() <==> repr(x)
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| tm_hour
| hours, range [0, 23]
|
| tm_isdst
| 1 if summer time is in effect, 0 if not, and -1 if unknown
|
| tm_mday
| day of month, range [1, 31]
|
| tm_min
| minutes, range [0, 59]
|
| tm_mon
| month of year, range [1, 12]
|
| tm_sec
| seconds, range [0, 61])
|
| tm_wday
| day of week, range [0, 6], Monday is 0
|
| tm_yday
| day of year, range [1, 366]
|
| tm_year
| year, for example, 1993
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __new__ =
| T.__new__(S, ...) -> a new object with type S, a subtype of T
|
| n_fields = 9
|
| n_sequence_fields = 9
|
| n_unnamed_fields = 0
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.tuple:
|
| __add__(...)
| x.__add__(y) <==> x+y
|
| __contains__(...)
| x.__contains__(y) <==> y in x
|
| __eq__(...)
| x.__eq__(y) <==> x==y
|
| __ge__(...)
| x.__ge__(y) <==> x>=y
|
| __getattribute__(...)
| x.__getattribute__('name') <==> x.name
|
| __getitem__(...)
| x.__getitem__(y) <==> x[y]
|
| __getnewargs__(...)
|
| __gt__(...)
| x.__gt__(y) <==> x>y
|
| __hash__(...)
| x.__hash__() <==> hash(x)
|
| __iter__(...)
| x.__iter__() <==> iter(x)
|
| __le__(...)
| x.__le__(y) <==> x<=y
|
| __len__(...)
| x.__len__() <==> len(x)
|
| __lt__(...)
| x.__lt__(y) <==> x x*n
|
| __ne__(...)
| x.__ne__(y) <==> x!=y
|
| __rmul__(...)
| x.__rmul__(n) <==> n*x
|
| __sizeof__(...)
| T.__sizeof__() -- size of T in memory, in bytes
|
| count(...)
| T.count(value) -> integer -- return number of occurrences of value
|
| index(...)
| T.index(value, [start, [stop]]) -> integer -- return first index of value.
| Raises ValueError if the value is not present.
FUNCTIONS
asctime(...)
asctime([tuple]) -> string
Convert a time tuple to a string, e.g. 'Sat Jun 06 16:26:11 1998'.
When the time tuple is not present, current time as returned by localtime()
is used.
clock(...)
clock() -> floating point number
Return the CPU time or real time since the start of the process or since
the first call to clock(). This has as much precision as the system
records.
ctime(...)
ctime(seconds) -> string
Convert a time in seconds since the Epoch to a string in local time.
This is equivalent to asctime(localtime(seconds)). When the time tuple is
not present, current time as returned by localtime() is used.
gmtime(...)
gmtime([seconds]) -> (tm_year, tm_mon, tm_mday, tm_hour, tm_min,
tm_sec, tm_wday, tm_yday, tm_isdst)
Convert seconds since the Epoch to a time tuple expressing UTC (a.k.a.
GMT). When 'seconds' is not passed in, convert the current time instead.
localtime(...)
localtime([seconds]) -> (tm_year,tm_mon,tm_mday,tm_hour,tm_min,
tm_sec,tm_wday,tm_yday,tm_isdst)
Convert seconds since the Epoch to a time tuple expressing local time.
When 'seconds' is not passed in, convert the current time instead.
mktime(...)
mktime(tuple) -> floating point number
Convert a time tuple in local time to seconds since the Epoch.
sleep(...)
sleep(seconds)
Delay execution for a given number of seconds. The argument may be
a floating point number for subsecond precision.
strftime(...)
strftime(format[, tuple]) -> string
Convert a time tuple to a string according to a format specification.
See the library reference manual for formatting codes. When the time tuple
is not present, current time as returned by localtime() is used.
strptime(...)
strptime(string, format) -> struct_time
Parse a string to a time tuple according to a format specification.
See the library reference manual for formatting codes (same as strftime()).
time(...)
time() -> floating point number
Return the current time in seconds since the Epoch.
Fractions of a second may be present if the system clock provides them.
DATA
accept2dyear = 1
altzone = -32400
daylight = 0
timezone = -28800
tzname = ('中国标准时间', '中国夏令时')
FILE
(built-in)
time模块中重要函数
| 函数 | 描述 |
|---|---|
| asctime([tuple]) | 将时间元组转换为字符串 |
| localtime([secs]) | 把秒数转换为日期元组,以本地时间为准 |
| mktime(tuple) | 将时间元组转换为本地时间 |
| sleep(secs) | 休眠sec秒不做任何事 |
| strptime(string,format) | 将字符串解析为时间元组 |
| time() | 当前时间(新纪元开始后的秒数,以UTC为准) |
datetime(支持日期和世间的算法)和timeit(帮助开发人员对代码执行时间进行计时)
10.3.6 random
random模块包括返回随机数的函数,可以用于模拟或用于产生随机输出的程序。是伪随机数。
如果需要真的随机性,应该使用os模块的urandom函数。
random模块中的SystemRandom类也可以产生类似的功能,可以让数据接近真的随机性。
random模块中一些重要的函数
| 函数 | 描述 |
|---|---|
| random() | 返回0≤n<1之间随机实数n,其中0 |
| getrandbits(n) | 以长整型形式返回n个随机位 |
| uniform(a,b) | 返回随机实数n,a≤n |
| randrange([start],stop,[step]) | 返回range(start,stop,step)中的随机数 |
| choice(seq) | 从序列seq中返回任意元素 |
| shuffle(seq[,random]) | 将给定的可变seq元素进行随机移位 |
| sample(seq,n) | 从序列seq中选择n个随机且独立的元素 |
示例演示
>>> x=random.random()
>>> x
0.6478968573407358
>>> y=getrandbits(5)
Traceback (most recent call last):
File "", line 1, in
y=getrandbits(5)
NameError: name 'getrandbits' is not defined
>>> y=random.getrandbits(5)
>>> y
17
>>> y
17
>>> z=random.uniform(1,10)
>>> z
5.915657829093572
>>> a=random.randrange(0,10)
>>> a
1
>>> a=random.randrange(10)
>>> a
0
>>> a=random.randrange(10)
>>> a
7
>>> y=random.getrandbits(5)
>>> y
16
>>> y=random.getrandbits(5)
>>> y
24
random.getrandbits(n)以长整型返回给定位数(二进制数)。如果处理真正的随机事务(比如加密),这个函数尤其有用。怎么用?
>>> list1=[for n in range(10):return n]#用for循环构造列表,语法错误
SyntaxError: invalid syntax
>>> list1=[n for n in range(10)]#正确的构造语法
>>> list1
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> b=random.choice(list1)
>>> b
5
>>> b
5
>>> b=random.choice(list1)
>>> b
1
random.choice(seq)在序列seq中随机选择一个元素。
>>> c=random.sample(list1,4)
>>> c
[6, 5, 9, 1]
random.sample(seq,n)意思是从seq序列中随机抽样n个数。
random.shuffle(seq)对序列seq原地进行洗牌。
>>> from random import *
>>> from time import *
>>> date1=(2018,1,1,0,0,0,-1,-1,-1)#用-1表示一周中的某周,一年中的某天和夏令时
>>> time1=mktime(date1)
>>> date2=(2019,1,1,0,0,0,-1,-1,-1)
>>> times2=mktime(date2)
>>> random_time=uniform(time1,time2)
Traceback (most recent call last):
File "", line 1, in
random_time=uniform(time1,time2)
NameError: name 'time2' is not defined
>>> time2=mktime(date2)
>>> random_time=uniform(time1,time2)
>>> time1
1514736000.0
>>> time2
1546272000.0
>>> print(asctime(localtime(random_time)))
Sat Mar 17 21:15:51 2018
mktime()函数将元组转换成秒数,localtime()函数将秒数转换成元组,asctime()函数将元组转成可读的时间类型字符串。
#掷骰子
from random import randrange
num=int(input("How many dice?"))#input函数输入的字符串,如果要将输入的数字进行运算必须转换成int或float类型。
sides=int(input("How many sides per dice?"))
sum1=0
for i in range(num):
sum1+=randrange(sides)+1
print("The result is",sum1)
#运行结果
How many dice?3
How many sides per dice?6
The result is 13
#fortune.py,简单随机算命文件
import fileinput,random
fortunes=list(fileinput.input("D:/Python32/exercise/fortune.txt"))
print(random.choice(fortunes))
#运行结果
>>> ================================ RESTART
>>>
obscurity
>>> ================================ RESTART
>>>
obscurity
>>> ================================ RESTART
>>>
High-ranking official
>>> ================================ RESTART
>>>
poor
>>> ================================ RESTART
>>>
rich
#fortune.txt
rich
poor
famous
obscurity
High-ranking official
Civilian
#发牌
>>> values=list(range(1,11)).append('Jack Queen King'.split(' '))
>>> values
>>> print(values)
None
>>> list1=[1,2,3,4]
>>> list2=[5,6,7,8]
>>> list3=list1.append(list2)
>>> list3
>>> print(list3)
None
>>> list(list3)
Traceback (most recent call last):
File "", line 1, in
list(list3)
TypeError: 'NoneType' object is not iterable
>>> print(i for i in list3)
Traceback (most recent call last):
File "", line 1, in
print(i for i in list3)
TypeError: 'NoneType' object is not iterable
>>> list3=list1.extend(list2)
>>> list3
>>> print(i for i in list3)
Traceback (most recent call last):
File "", line 1, in
print(i for i in list3)
TypeError: 'NoneType' object is not iterable
>>> list(range(1,11))
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> 'Jack Queen King'.split(' ')
['Jack', 'Queen', 'King']
>>> list1=list(range(1,11))
>>> list1
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list2='Jack Queen King'.split(' ')
>>> list2
['Jack', 'Queen', 'King']
>>> list1.append(list2)
>>> list1
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, ['Jack', 'Queen', 'King']]
>>> list1.extend(list2)
>>> list1
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, ['Jack', 'Queen', 'King'], 'Jack', 'Queen', 'King']
>>> values=list(range(1,11)).extend('Jack Queen King'.split(' '))
>>> suits='diamonds clubs hearts spades'.split(' ')
>>> deck=['%s of %s'%(v,s)for v in values for s in suits]
Traceback (most recent call last):
File "", line 1, in
deck=['%s of %s'%(v,s)for v in values for s in suits]
TypeError: 'NoneType' object is not iterable
>>> values
>>> deck=['%s of %s'%(v,s)for v in list(range(1,11)).extend('Jack Queen King'.split(' ')) for s in 'diamonds clubs hearts spades'.split(' ')]
Traceback (most recent call last):
File "", line 1, in
deck=['%s of %s'%(v,s)for v in list(range(1,11)).extend('Jack Queen King'.split(' ')) for s in 'diamonds clubs hearts spades'.split(' ')]
TypeError: 'NoneType' object is not iterable
>>> list3=list1
>>> list3
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, ['Jack', 'Queen', 'King'], 'Jack', 'Queen', 'King']
>>> 'diamonds clubs hearts spades'.split(' ')
['diamonds', 'clubs', 'hearts', 'spades']
>>> deck1=[v for v in values]
Traceback (most recent call last):
File "", line 1, in
deck1=[v for v in values]
TypeError: 'NoneType' object is not iterable
>>> '%s of %s'%(v,s)for v in values for s in suits
SyntaxError: invalid syntax
>>> print('%s of %s'%(v,s)for v in values for s in suits)
Traceback (most recent call last):
File "", line 1, in
print('%s of %s'%(v,s)for v in values for s in suits)
TypeError: 'NoneType' object is not iterable
>>> print('%s of %s'%(v,s) for v in values for s in suits)
Traceback (most recent call last):
File "", line 1, in
print('%s of %s'%(v,s) for v in values for s in suits)
TypeError: 'NoneType' object is not iterable
>>> '%s of %s'%(v,s) for v in values for s in suits
SyntaxError: invalid syntax
>>> deck=[(v,s)for v in values for s in suits]
Traceback (most recent call last):
File "", line 1, in
deck=[(v,s)for v in values for s in suits]
TypeError: 'NoneType' object is not iterable
TypeError: ‘NoneType’ object is not iterable这个错误一直没弄明白。!!!
终于弄明白了!!!
append和extend就是独立使用的,特地为操作列表这种数据结构设计的,所以没有必要重新赋值。
python中append方法和extend方法的不同功能
>>> values=list(range(1,11))
>>> values
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> values.extend('Jack Queen King'.split(' '))
>>> values
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 'Jack', 'Queen', 'King']
>>> suits='diamonds clubs hearts spades'.split(' ')
>>> suits
['diamonds', 'clubs', 'hearts', 'spades']
>>> deck=['%s of %s'%((v,s)for v in values for s in suits)]
Traceback (most recent call last):
File "", line 1, in
deck=['%s of %s'%((v,s)for v in values for s in suits)]
TypeError: not enough arguments for format string
>>> deck=['%s of %s'%(v,s)for v in values for s in suits]
>>> deck
['1 of diamonds', '1 of clubs', '1 of hearts', '1 of spades', '2 of diamonds', '2 of clubs', '2 of hearts', '2 of spades', '3 of diamonds', '3 of clubs', '3 of hearts', '3 of spades', '4 of diamonds', '4 of clubs', '4 of hearts', '4 of spades', '5 of diamonds', '5 of clubs', '5 of hearts', '5 of spades', '6 of diamonds', '6 of clubs', '6 of hearts', '6 of spades', '7 of diamonds', '7 of clubs', '7 of hearts', '7 of spades', '8 of diamonds', '8 of clubs', '8 of hearts', '8 of spades', '9 of diamonds', '9 of clubs', '9 of hearts', '9 of spades', '10 of diamonds', '10 of clubs', '10 of hearts', '10 of spades', 'Jack of diamonds', 'Jack of clubs', 'Jack of hearts', 'Jack of spades', 'Queen of diamonds', 'Queen of clubs', 'Queen of hearts', 'Queen of spades', 'King of diamonds', 'King of clubs', 'King of hearts', 'King of spades']
>>> from random import shuffle
>>> shuffle(deck)
>>> pprint(deck[:12])
Traceback (most recent call last):
File "", line 1, in
pprint(deck[:12])
NameError: name 'pprint' is not defined
>>> import pprint
>>> pprint(deck[:12])
Traceback (most recent call last):
File "", line 1, in
pprint(deck[:12])
TypeError: 'module' object is not callable
>>> pprint
>>> help(pprint)
Help on module pprint:
NAME
pprint - Support to pretty-print lists, tuples, & dictionaries recursively.
DESCRIPTION
Very simple, but useful, especially in debugging data structures.
Classes
-------
PrettyPrinter()
Handle pretty-printing operations onto a stream using a configured
set of formatting parameters.
Functions
---------
pformat()
Format a Python object into a pretty-printed representation.
pprint()
Pretty-print a Python object to a stream [default is sys.stdout].
saferepr()
Generate a 'standard' repr()-like value, but protect against recursive
data structures.
CLASSES
builtins.object
PrettyPrinter
class PrettyPrinter(builtins.object)
| Methods defined here:
|
| __init__(self, indent=1, width=80, depth=None, stream=None)
| Handle pretty printing operations onto a stream using a set of
| configured parameters.
|
| indent
| Number of spaces to indent for each level of nesting.
|
| width
| Attempted maximum number of columns in the output.
|
| depth
| The maximum depth to print out nested structures.
|
| stream
| The desired output stream. If omitted (or false), the standard
| output stream available at construction will be used.
|
| format(self, object, context, maxlevels, level)
| Format object for a specific context, returning a string
| and flags indicating whether the representation is 'readable'
| and whether the object represents a recursive construct.
|
| isreadable(self, object)
|
| isrecursive(self, object)
|
| pformat(self, object)
|
| pprint(self, object)
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
FUNCTIONS
isreadable(object)
Determine if saferepr(object) is readable by eval().
isrecursive(object)
Determine if object requires a recursive representation.
pformat(object, indent=1, width=80, depth=None)
Format a Python object into a pretty-printed representation.
pprint(object, stream=None, indent=1, width=80, depth=None)
Pretty-print a Python object to a stream [default is sys.stdout].
saferepr(object)
Version of repr() which can handle recursive data structures.
DATA
__all__ = ['pprint', 'pformat', 'isreadable', 'isrecursive', 'saferepr...
FILE
d:\python32\lib\pprint.py
>>> pprint.pprint(deck[:12])
['3 of spades',
'Jack of clubs',
'5 of diamonds',
'3 of hearts',
'5 of clubs',
'King of diamonds',
'Queen of diamonds',
'8 of hearts',
'10 of hearts',
'9 of spades',
'Queen of hearts',
'4 of spades']
#定义一个按回车发牌函数,并计算发牌数
def deal_cards():
values=list(range(1,11))
values.extend('Jack Queen King'.split(' '))
suits='diamonds clubs hearts spades'.split(' ')
deck=['%s of %s'%(v,s)for v in values for s in suits]
from random import shuffle
shuffle(deck)
num=0
while deck:
num+=1
input(deck.pop())
print(num)
#运行结果
deal_cards()
7 of spades
1
4 of spades
2
9 of spades
3
8 of spades
4
4 of hearts
5
Jack of clubs
6
3 of diamonds
7
3 of hearts
8
Queen of clubs
9
Jack of hearts
10
2 of hearts
11
King of clubs
12
5 of diamonds
13
6 of hearts
14
King of hearts
15
5 of spades
16
10 of clubs
17
6 of spades
18
5 of hearts
19
10 of hearts
20
9 of diamonds
21
8 of clubs
22
Queen of diamonds
23
9 of clubs
24
7 of diamonds
25
10 of spades
26
4 of clubs
27
1 of hearts
28
Jack of diamonds
29
Queen of hearts
30
10 of diamonds
31
6 of clubs
32
King of diamonds
33
8 of hearts
34
1 of clubs
35
9 of hearts
36
Queen of spades
37
4 of diamonds
38
3 of clubs
39
7 of hearts
40
8 of diamonds
41
6 of diamonds
42
3 of spades
43
1 of spades
44
2 of spades
45
2 of diamonds
46
7 of clubs
47
5 of clubs
48
King of spades
49
2 of clubs
50
Jack of spades
51
1 of diamonds
52
10.3.7 shelve
shelve模块用于简单存储数据。只需要提供文件名就可以。shelve的英文翻译意思是搁置。shelve模块中唯一有趣的是open函数。调用它时返回一个shelf对象,可以用它存储内容。只需要把它当普通字典一样进行操作(键一定得是字符串),完成工作后,调用close方法。
import shelve
>>> help(shelve)
Help on module shelve:
NAME
shelve - Manage shelves of pickled objects.
DESCRIPTION
A "shelf" is a persistent, dictionary-like object. The difference
with dbm databases is that the values (not the keys!) in a shelf can
be essentially arbitrary Python objects -- anything that the "pickle"
module can handle. This includes most class instances, recursive data
types, and objects containing lots of shared sub-objects. The keys
are ordinary strings.
To summarize the interface (key is a string, data is an arbitrary
object):
#键是字符串,数据是任意对象
import shelve
d = shelve.open(filename) # open, with (g)dbm filename -- no suffix
d[key] = data # store data at key (overwrites old data if
# using an existing key)#在对应的键上存储数据,如果已经存在键则被覆盖
data = d[key] # retrieve a COPY of the data at key (raise#检索键处数据数据副本,如果不是该键,则报错。access返回的是条目的副本。
# KeyError if no such key) -- NOTE that this
# access returns a *copy* of the entry!
del d[key] # delete data stored at key (raises KeyError
# if no such key)#删除键处数据
flag = key in d # true if the key exists#检查键是否存在
list = d.keys() # a list of all existing keys (slow!)#列表显示所有存在的键。
d.close() # close it
Dependent on the implementation, closing a persistent dictionary may
or may not be necessary to flush changes to disk.
Normally, d[key] returns a COPY of the entry. This needs care when
mutable entries are mutated: for example, if d[key] is a list,
d[key].append(anitem)
does NOT modify the entry d[key] itself, as stored in the persistent
mapping -- it only modifies the copy, which is then immediately
discarded, so that the append has NO effect whatsoever. To append an
item to d[key] in a way that will affect the persistent mapping, use:
data = d[key]
data.append(anitem)
d[key] = data
To avoid the problem with mutable entries, you may pass the keyword
argument writeback=True in the call to shelve.open. When you use:
d = shelve.open(filename, writeback=True)
then d keeps a cache of all entries you access, and writes them all back
to the persistent mapping when you call d.close(). This ensures that
such usage as d[key].append(anitem) works as intended.
However, using keyword argument writeback=True may consume vast amount
of memory for the cache, and it may make d.close() very slow, if you
access many of d's entries after opening it in this way: d has no way to
check which of the entries you access are mutable and/or which ones you
actually mutate, so it must cache, and write back at close, all of the
entries that you access. You can call d.sync() to write back all the
entries in the cache, and empty the cache (d.sync() also synchronizes
the persistent dictionary on disk, if feasible).
CLASSES
_abcoll.MutableMapping(_abcoll.Mapping)
Shelf
BsdDbShelf
DbfilenameShelf
class BsdDbShelf(Shelf)
| Shelf implementation using the "BSD" db interface.
|
| This adds methods first(), next(), previous(), last() and
| set_location() that have no counterpart in [g]dbm databases.
|
| The actual database must be opened using one of the "bsddb"
| modules "open" routines (i.e. bsddb.hashopen, bsddb.btopen or
| bsddb.rnopen) and passed to the constructor.
|
| See the module's __doc__ string for an overview of the interface.
|
| Method resolution order:
| BsdDbShelf
| Shelf
| _abcoll.MutableMapping
| _abcoll.Mapping
| _abcoll.Sized
| _abcoll.Iterable
| _abcoll.Container
| builtins.object
|
| Methods defined here:
|
| __init__(self, dict, protocol=None, writeback=False, keyencoding='utf-8')
|
| first(self)
|
| last(self)
|
| next(self)
|
| previous(self)
|
| set_location(self, key)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __abstractmethods__ = frozenset([])
|
| ----------------------------------------------------------------------
| Methods inherited from Shelf:
|
| __contains__(self, key)
|
| __del__(self)
|
| __delitem__(self, key)
|
| __getitem__(self, key)
|
| __iter__(self)
|
| __len__(self)
|
| __setitem__(self, key, value)
|
| close(self)
|
| get(self, key, default=None)
|
| sync(self)
|
| ----------------------------------------------------------------------
| Methods inherited from _abcoll.MutableMapping:
|
| clear(self)
|
| pop(self, key, default=1.潜在的陷阱
shelve.open函数返回的对象并不是普通的映射对象。
>>> s=shelve.open('test.txt')
>>> s['x']=['a','b','c']
>>> s['x'].append('d')
>>> s['x']
['a', 'b', 'c']
#‘d’消失了,为什么?
当在shelve中查找元素的时候,这个对象会根据已经存储的版本进行重新构建,当将某个元素赋值给键时,它就被存储。
- 列表[‘a’,‘b’,‘c’]存储在键x下;
- 获得存储的表示,并且根据它来创建新的列表,而‘d’被添加到这个副本中。修改的版本还没有保存!
- 最终,再次获得原始版本——没有‘d’
用临时变量绑定副本,并且再它改变后重新存储这个副本。
>>> temp=s['x']
>>> temp.append('d')
>>> s['x']=temp
>>> s['x']
['a', 'b', 'c', 'd']
>>>
简单数据库应用程序示例
#database.py,简单数据库程序
import sys,shelve
def store_person(db):
"""
Query user for data and store it in the shelf object
"""
pid=input('Enter unique ID number:')
person={}
person['name']=input("Enter name:")
person['age']=input("Enter age:")
person['phone']=input("Enter phone number:")
db[pid]=person
def lookup_person(db):
"""
Query user for ID and desired field,and fetch the corresponding data from
the shelf object
"""
pid=input("Enter ID number:")
field=input("what would you like to know?(name,age,phone)")
field=field.strip().lower()
print(field.capitalize()+':',\
db[pid][field])
def print_help():
print("The available commands are:")
print("store :Stores information about a person")
print("lookup:通过ID数字查找一个人(Look up a person from ID number)。")
print("quit :Save changes and exit")
print("? :Prints this message")
def enter_command():
cmd=input("Enter command(? for help):")
cmd=cmd.strip().lower()
return cmd
def main():
database=shelve.open("D:\\Python32\\exercise\\testdata")#注意路径输入时"\\"
try:
while True:
cmd=enter_command()
if cmd=="store":
store_person(database)
elif cmd=="lookup":
lookup_person(database)
elif cmd=="?":
print_help()
elif cmd=="quit":
return
finally:
database.close()
if __name__=="__main__":main()
#运行结果
Enter command(? for help):store
Enter unique ID number:001
Enter name:jack
Enter age:42
Enter phone number:0502
Enter command(? for help):store
Enter unique ID number:002
Enter name:mary
Enter age:32
Enter phone number:0601
Enter command(? for help):store
Enter unique ID number:003
Enter name:lily
Enter age:18
Enter phone number:0702
Enter command(? for help):lookup
Enter ID number:003
what would you like to know?(name,age,phone)age
Age: 18
Enter command(? for help):?
The available commands are:
store :Stores information about a person
lookup:通过ID数字查找一个人(Look up a person from ID number)。
quit :Save changes and exit
? :Prints this message
Enter command(? for help):#按下enter键
Enter command(? for help):#按下enter键
Enter command(? for help):quit#退出程序
>>>
#第二天再加载程序
>>>
Enter command(? for help):lookup
Enter ID number:003
what would you like to know?(name,age,phone)name
Name: lily
Enter command(? for help):quit#数据库的数据还存在
>>>
- 将所有内容放在函数使程序更加结构化(可能的改进是将函数组织为类的方法);
- 主程序放在main函数中,if __name__=="__main__":main()才调用。意味着可以在其他程序中将这个程序作为模块引入,然后调用main函数;
- 在main函数打开数据库shelve,然后将其作为参数传给其他函数。
- 为避免数据库因异常的抛出导致不能正常关闭,引起数据库数据损坏,使用了try/finally,保证在即使有异常抛出的时候也能正常关闭数据库,避免因异常导致的数据库损坏。
10.3.8 re
re模块包含对**正则表达式(regular expression)**的支持。
学习正则表达式很困难。学习关键是每次只学一点——(文档中)查找满足特定任务需求的那部分内容。
必要时可以参考CSDN博客中的介绍
正则表达式基础语法例子
1.什么时正则表达式
正则表达式可以匹配文本片段的模式。最简单的正则表达式时普通字符串,可以匹配其自身。
-
通配符。匹配多于一个字符串,可以用特殊字符创建这类模式。比如(.)可以匹配任何字符(除了换行符\),点号就称为通配符。
-
对特殊字符进行转义。转义符号(\),也可以通过原始字符串,只需要一个反斜线,例如r’python.org’
-
字符集。中括号[]创建字符集,例如’[pj]ython’能匹配’python’和’jython’而非其他内容。还可以使用范围’[a-z]‘能匹配a到z的任意一个字符。还可以联合起来用,如’[a-zA-Z0-9]‘可以匹配a到z无论大小写和数字0到9的所有字符。只匹配一个字符,[]只是限定了匹配搜索范围。反转字符集,可以在开头用^字符,例如’[^abc]'可以匹配除了abc之外的字符。
-
选择符和子模式。选择符(|),子模式用()括起来,例如匹配’python’和’perl’,可以用’python|perl’,用()将需要用到运算符的部分括起来,例如’p(ython|erl)’
-
可选项和重复子模式。?就是可选项字符。r’(http://)?(www.)?python.org’意思是:只能匹配’http://www.python.org’,‘http://python.org’,‘www.python.org’,‘python.org’
对点号进行转义,使用原始字符串减少反斜线数,每个可选子模式用圆括号括起来。 -
(pattern)*:允许模式重复0次或多次
-
(pattern)+:允许模式重复1次或多次
-
(pattern){m,n}:允许模式重复m~n次
-
字符串开始和结尾:用脱字符(^)标记开始,用($)标记结尾
2.re模块的内容
只书写正则表达式不会用是没用的。re模块包含一些有用的操作正则表达式的函数。
>>> import re
>>> help(re)
Help on module re:
NAME
re - Support for regular expressions (RE).
DESCRIPTION
This module provides regular expression matching operations similar to
those found in Perl. It supports both 8-bit and Unicode strings; both
the pattern and the strings being processed can contain null bytes and
characters outside the US ASCII range.
Regular expressions can contain both special and ordinary characters.
Most ordinary characters, like "A", "a", or "0", are the simplest
regular expressions; they simply match themselves. You can
concatenate ordinary characters, so last matches the string 'last'.
The special characters are:
"." Matches any character except a newline.
"^" Matches the start of the string.
"$" Matches the end of the string or just before the newline at
the end of the string.
"*" Matches 0 or more (greedy) repetitions of the preceding RE.
Greedy means that it will match as many repetitions as possible.
"+" Matches 1 or more (greedy) repetitions of the preceding RE.
"?" Matches 0 or 1 (greedy) of the preceding RE.
*?,+?,?? Non-greedy versions of the previous three special characters.
{m,n} Matches from m to n repetitions of the preceding RE.
{m,n}? Non-greedy version of the above.
"\\" Either escapes special characters or signals a special sequence.
[] Indicates a set of characters.
A "^" as the first character indicates a complementing set.
"|" A|B, creates an RE that will match either A or B.
(...) Matches the RE inside the parentheses.
The contents can be retrieved or matched later in the string.
(?aiLmsux) Set the A, I, L, M, S, U, or X flag for the RE (see below).
(?:...) Non-grouping version of regular parentheses.
(?P...) The substring matched by the group is accessible by name.
(?P=name) Matches the text matched earlier by the group named name.
(?#...) A comment; ignored.
(?=...) Matches if ... matches next, but doesn't consume the string.
(?!...) Matches if ... doesn't match next.
(?<=...) Matches if preceded by ... (must be fixed length).
(?
| T.__new__(S, ...) -> a new object with type S, a subtype of T
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.BaseException:
|
| __delattr__(...)
| x.__delattr__('name') <==> del x.name
|
| __getattribute__(...)
| x.__getattribute__('name') <==> x.name
|
| __reduce__(...)
|
| __repr__(...)
| x.__repr__() <==> repr(x)
|
| __setattr__(...)
| x.__setattr__('name', value) <==> x.name = value
|
| __setstate__(...)
|
| __str__(...)
| x.__str__() <==> str(x)
|
| with_traceback(...)
| Exception.with_traceback(tb) --
| set self.__traceback__ to tb and return self.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from builtins.BaseException:
|
| __cause__
| exception cause
|
| __context__
| exception context
|
| __dict__
|
| __traceback__
|
| args
FUNCTIONS
compile(pattern, flags=0)
Compile a regular expression pattern, returning a pattern object.
escape(pattern)
Escape all non-alphanumeric characters in pattern.
findall(pattern, string, flags=0)
Return a list of all non-overlapping matches in the string.
If one or more groups are present in the pattern, return a
list of groups; this will be a list of tuples if the pattern
has more than one group.
Empty matches are included in the result.
finditer(pattern, string, flags=0)
Return an iterator over all non-overlapping matches in the
string. For each match, the iterator returns a match object.
Empty matches are included in the result.
match(pattern, string, flags=0)
Try to apply the pattern at the start of the string, returning
a match object, or None if no match was found.
purge()
Clear the regular expression caches
search(pattern, string, flags=0)
Scan through string looking for a match to the pattern, returning
a match object, or None if no match was found.
split(pattern, string, maxsplit=0, flags=0)
Split the source string by the occurrences of the pattern,
returning a list containing the resulting substrings.
sub(pattern, repl, string, count=0, flags=0)
Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the match object and must return
a replacement string to be used.
subn(pattern, repl, string, count=0, flags=0)
Return a 2-tuple containing (new_string, number).
new_string is the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in the source
string by the replacement repl. number is the number of
substitutions that were made. repl can be either a string or a
callable; if a string, backslash escapes in it are processed.
If it is a callable, it's passed the match object and must
return a replacement string to be used.
template(pattern, flags=0)
Compile a template pattern, returning a pattern object
DATA
A = 256
ASCII = 256
DOTALL = 16
I = 2
IGNORECASE = 2
L = 4
LOCALE = 4
M = 8
MULTILINE = 8
S = 16
U = 32
UNICODE = 32
VERBOSE = 64
X = 64
__all__ = ['match', 'search', 'sub', 'subn', 'split', 'findall', 'comp...
re.compile将正则表达式(用字符串书写)转换为模式对象。
>>> some_text='alpha,beta,,,,,gammma delta'
>>> re.split('[, ]+',some_text)#用正则表达式分割字符串
['alpha', 'beta', 'gammma', 'delta']
>>> some_text='alpha,beta,,,,,gammma delta'
>>> re.split('[,]+',some_text)
['alpha', 'beta', 'gammma delta']
>>> re.split('[, ]+',some_text)
['alpha', 'beta', 'gammma', 'delta']
>>> re.split('o(o)',foobar)
Traceback (most recent call last):
File "", line 1, in
re.split('o(o)',foobar)
NameError: name 'foobar' is not defined
>>> re.split('o(o)','foooobar')
['f', 'o', '', 'o', 'bar']
>>> re.split('o(o)','foobar')
['f', 'o', 'bar']
>>> re.split('o(o)+','foooobar')#用括号括起来的部分会散列在分割后的字符串之间
['f', 'o', 'bar']
>>> re.split('o(o)','foooobar')
['f', 'o', '', 'o', 'bar']
>>> re.split('[, ]+',some_text,maxsplit=2)#maxsplit最大可分割的部分数
['alpha', 'beta', 'gammma delta']
>>> re.split('[, ]+',some_text,maxsplit=1)
['alpha', 'beta,,,,,gammma delta']
>>> re.split('[, ]+',some_text,maxsplit=0)
['alpha', 'beta', 'gammma', 'delta']
>>> re.split('[, ]+',some_text,maxsplit=4)
['alpha', 'beta', 'gammma', 'delta']
>>> pat='[a-zA-Z]+'
>>> text='"Hm...Err--are you sure?"he said,sounding insecure.'
>>> re.findall(pat,text)#返回给定模式所有匹配项
['Hm', 'Err', 'are', 'you', 'sure', 'he', 'said', 'sounding', 'insecure']
>>> pat=r'[.?\-",]+'#查找标点符号(-)被转义,不会表示成字符范围
>>> re.findall(pat,text)
['"', '...', '--', '?"', ',', '.']
>>> pat='{name}'
>>> text='Dear {name}...'
>>> re.sub(pat,'Mr.Gumby',text)#用给定内容替换匹配项
'Dear Mr.Gumby...'
>>> pat='name'
>>> text='Dear name...'
>>> re.sub(pat,'Mr.Gumby',text)
'Dear Mr.Gumby...'
re.escape,对所有可能被解释为正则运算符的字符进行转义。非常有用。
>>> re.escape(input("Enter you like:"))
Enter you like:!#$%^^%~?//\'[][;;hehe
"\\!\\#\\$\\%\\^\\^\\%\\~\\?\\/\\/\\\\\\'\\[\\]\\[\\;\\;hehe"
re模块中的一些函数在调用时,有flag这个可选参数,用来改变解释正则表达式的方法,具体可以在网上找找看。
3.匹配对象和组
‘There (was a (wee) (cooper)) who (lived in Fyfe)’
组就是放在圆括号内的子模式。组的序号取决左侧的括号数。
0组——‘There was a wee cooper who lived in Fyfe’
1组——‘was a wee cooper’
2组——‘wee’
3组——‘cooper’
4组——‘lived in Fyfe’
r’www.(.+).com$’
组0包含整个字符串,组1包含位于’www.‘和’.com’之间的所有内容。
re模块匹配对象的重要方法
| 方法 | 描述 |
|---|---|
| group([group1,…]) | 获取给定子模式(组)的匹配项 |
| start([group]) | 返回给定组的匹配项的开始位置 |
| end([group]) | 返回给定组的匹配项的结束位置 |
| span([group]) | 返回一个组的开始和结束位置 |
除了0组,最多99组,1~99组
>>> import re
>>> m=re.match(r'www\.(.*)\..{3}','www.python.org')
>>> m.group(0)
'www.python.org'
>>> m.group(1)
'python'
>>> m.group(2)
Traceback (most recent call last):
File "", line 1, in
m.group(2)
IndexError: no such group
>>> m.start(0)#组0字符串开始位置的索引值
0
>>> m.start(1)#组1字符串开始位置的索引值
4
>>> m.end(0)#组0字符串结束位置的索引值
14
>>> m.end(1)#组1字符串结束位置的索引值
10
>>> m.span(0)#组0字符串开始和结束位置的索引值,以元组形式返回
(0, 14)
>>> m.span(1)#组1字符串开始和结束位置的索引值,以元组形式返回
(4, 10)
4.作为替换的组号和函数
假设把’*something*‘用’something'替换。
>>> emphasis_pattern=r'\*([^\*]+)\*'#正则表达式不易理解,可以用下面方法添加注释
>>> re.sub(emphasis_pattern,r'\1','Hello,*world*!')
'Hello,world!'
>>> emphasis_pattern=re.compile(r'''
\* #Beginning emphasis tag--an asterisk
( #Begin group for capturing phrase
[^\*]+ #Capture anyting except asterisks
) #End group
\* #Ending emphasis tag
''',re.VERBOSE)#在re函数中用VERBOSE标志,在冗长的正则表达式中添加注释
>>> re.sub(emphasis_pattern,r'\1','Hello,*world*!')
'Hello,world!'
>>> import re
>>> emphasis_pattern=r'\*(.+)\*'#(.+)匹配尽可能多的字符(贪婪模式)
>>> re.sub(emphasis_pattern,r'\1','*This* is *it*!')
'This* is *it!'
>>> emphasis_pattern=r'\*(.+?)\*'
>>> re.sub(emphasis_pattern,r'\1','*This* is *it*!')
'This is it!'
>>> re.sub(emphasis_pattern,r'\1','**This** is **it**!')
'*This is it*!'
>>> emphasis_pattern=r'\*(.+)\*'
>>> re.sub(emphasis_pattern,r'\1','**This** is **it**!')
'*This** is **it*!'
>>> emphasis_pattern=r'\*\*(.+)\*\*'
>>> re.sub(emphasis_pattern,r'\1','**This** is **it**!')
'This** is **it!'
>>> emphasis_pattern=r'\*\*(.+?)\*\*'#+?在到达下一个\*\*之前会尽可能少匹配字符(非贪婪模式)
>>> re.sub(emphasis_pattern,r'\1','**This** is **it**!')
'This is it!'
5.找出Email的发件人
Python——正则表达式特殊符号及用法
#find_sender.py
import fileinput,re,sys
pat=re.compile('From:(.*)<.*?>$')
for line in fileinput.input("D:\Python32\exercise\华为帐号邮件验证码_.eml"):
m=pat.match(line)
if m:
print(m.group(1))
#运行结果
>>>
=?UTF-8?B?5Y2O5Li65biQ5Y+3?= #输出结果是个utf-8编码,实际原文件是中文字符。
这里面临一个问题,中文邮件的解码问题。如何将utf-8编码转换成中文字符呢?
下一个例子找地址
#find_addresses.py
import fileinput,re,heapq
pat=re.compile(r'[a-z\-\.0-9]+@[a-z\-\.]+',re.IGNORECASE)
addresses=set()#用到了数据结构集合
for line in fileinput.input("D:\Python32\exercise\华为帐号邮件验证码_.eml"):
for address in pat.findall(line):
addresses.add(address)
for address in sorted(addresses):
print(address)
#运行结果
>>>
0805@qq
[email protected]
875483622.265962.1553326856519.JavaMail.mailproxy@ncn-mailproxy-mailproxy-
admin@mail
[email protected]
#find_addresses.py
import fileinput,re,heapq
pat=re.compile(r'[a-z\-\.0-9]+@[a-z\-\.]+',re.IGNORECASE)
addresses=set()
path=input("Enter path of the text:")#输入文件所在路径
for line in fileinput.input(path):#将路径传递给fileinput.input读取文件
for address in pat.findall(line):
addresses.add(address)
for address in sorted(addresses):
print(address)
#运行结果
>>>
Enter path of the text:D:\Python32\exercise\华为帐号邮件验证码_.eml
0805@qq
[email protected]
875483622.265962.1553326856519.JavaMail.mailproxy@ncn-mailproxy-mailproxy-
admin@mail
[email protected]
6.模块系统示例
模板是通过放入具体值得到某种已完成文本的文件。
实现方法:一是python本身高级模板机制:字符串格式化
二是用正则表达式。
>>> 'The sum of 7 and 9 is [7+9]'#想要的结果是The sum of 7 and 9 is 16
'The sum of 7 and 9 is [7+9]'
>>> '[name="Mr.Gumby"]Hello,[name]'#想要的结果是Hello,Mr.Gumby
'[name="Mr.Gumby"]Hello,[name]'
怎么做?
一,用正则表达式匹配字段
二,用eval运算字符串值
三,用exec执行字符串中的赋值语句
四,用re.sub将求值的结果替换为处理后的字符串。
#一个模板示例
#一个模板系统
#templates.py
import fileinput, re
#匹配中括号内的字段
field_pat=re.compile(r'\[(.+?)\]')
#变量收集
scope={}
#用于re.sub中
def replacement(match):
code=match.group(1)
try:
exec(str(code in scope))
return ''
except :
return str(eval(code))
#将所有文本以一个字符串形式获取
path=input("Enter path of the text:")
lines=[]
for line in fileinput.input(path):
lines.append(line)
text=''.join(lines)
#将field模式的所有匹配项都替换掉
print(re.sub(field_pat,replacement,text))
#运行结果
Enter path of the text:D:\Python32\exercise\test.txt
The sum of and is
#test.txt中内容
[x=2]
[y=3]
The sum of [x] and [y] is [x+y]
期望的结果
The sum of 2 and 3 is 5
运行结果不是想要的结果,原因一直没找到。这个问题还没有搞清楚。到底时re.sub这个函数用的不对,还是定义的replacement函数有问题。个人感觉这两块内容都没有搞清楚。
第一,re.sub()函数中的参数repl,既可以是字符串,也可以是函数,如果是函数又该如何用,如何定义?
第二,定义replacement函数怎么定义,其中eval和exec用的问题在哪?
第三,sope={}字典在其中作用在哪里,可以肯定是有作用,具体如何作用的没弄明白。
解答:
scope={}创建一个命名空间,用于放置exec和eval执行结果的地方。类似于一个看不见的字典。
eval和exec两个函数理解不到位,help来看这两个函数。
exec(...)
exec(object[, globals[, locals]])
Read and execute code from an object, which can be a string or a code
object.
The globals and locals are dictionaries, defaulting to the current
globals and locals. If only globals is given, locals defaults to it.
从一个对象读取并执行,可以是字符串或代码对象。
全局变量和局部变量必须是字典,默认为当前全局变量和局部变量,如果只给了全局变量,局部默认为全局。
exec函数主要用于动态地创建代码字符串。如果这种字符串来自其他地方,就几乎无法确定它将包含什么内容。因此为了安全起见,要提供一个字典以充当命名空间。
命名空间:可以视为一个放置变量的地方,类似于一个看不见的字典。因此,当你执行语句x=1时,将在当前命名空间存储键x和值1。当前命名空间通常是全局命名空间,但也并非必然如此。
eval(...)
eval(source[, globals[, locals]]) -> value
Evaluate the source in the context of globals and locals.
The source may be a string representing a Python expression
or a code object as returned by compile().
The globals must be a dictionary and locals can be any mapping,
defaulting to the current globals and locals.
If only globals is given, locals defaults to it.
计算全局变量和局部变量中的内容,源可以是字符串表达式或者compile()返回的代码对象。全局变量必须是字典,局部变量可以是任何映射。默认为当前全局变量和局部变量,如果只给全局变量,局部变量也默认为全局变量。
为了理解这两个函数,下面有个例子
>>> scope={}#创建一个字典类型全局变量
>>> exec('x,y=3,3',scope)#执行的赋值语句,被赋值的变量存储在scope字典中,不返回任何对象。
>>> eval('x+y',scope)#对字典scope中的变量执行运算。返回运算结果
6
更改后的模板
#一个模板系统
#templates.py
import fileinput, re
#匹配中括号内的字段
field_pat=re.compile(r'\[(.+?)\]')
#创造一个命名空间用于变量收集,主要是exec和eval要用到
scope={}
#用于re.sub中
def replacement(match):
code=match.group(1)
try:
return str(eval(code,scope))#改动的地方
except SyntaxError:
exec(code,scope)#改动地方,执行作用域内的语句
return ''#返回空字符串
#将所有文本以一个字符串形式获取
path=input("Enter path of the text:")
lines=[]
for line in fileinput.input(path):
lines.append(line)
text=''.join(lines)
#将field模式的所有匹配项都替换掉
print(re.sub(field_pat,replacement,text))
#运行结果
Enter path of the text:D:\Python32\exercise\test.txt
The sum of 2 and 3 is 5
简要介绍这个程序做的事情:
-
定义用于匹配字段的模式
-
创建充当模块作用域的字典
-
定义具有下列功能的替换函数。
将组1从匹配中取出,放入code中
通过作用域字典作为命名空间来对code求值,将结果作为字符串返回。如果成功,字段就是个表达式,一起正常。否则(引发SyntaxError异常),跳刀下一步
执行在相同命名空间的字段表达式,返回空字符串(赋值语句不对任何内容求值)。 -
使用fileinput读取所有行,放入列表,组成一个大的字符串
-
将所有field_pat匹配项用re.sub中的替换函数进行替换,并打印结果